Topik ini menjelaskan masalah umum dan solusinya terkait kesalahan eksekusi job di Realtime Compute for Apache Flink.
Bagaimana cara melakukan troubleshooting job yang gagal dimulai?
Apa yang harus saya lakukan jika muncul error koneksi database?
Apa yang harus saya lakukan jika data dalam aliran data tidak dikonsumsi setelah job dimulai?
Apa yang harus saya lakukan jika job restart setelah berjalan selama periode tertentu?
Mengapa data terjebak di node LocalGroupAggregate dalam waktu lama tanpa output?
Bagaimana cara cepat mengidentifikasi penyebab kegagalan JobManager?
Error: Can not retract a non-existent record. This should never happen.
Error: RESOURCE_EXHAUSTED: gRPC message exceeds maximum size 41943040: 58384051
Bagaimana cara melakukan troubleshooting job yang gagal dimulai?
Deskripsi masalah
Setelah Anda mengklik tombol Start, status job berubah dari Starting menjadi Failed.
Solusi
Pada tab Events, klik ikon
 untuk memperluas detail dan mengidentifikasi penyebab pesan error.
untuk memperluas detail dan mengidentifikasi penyebab pesan error.Pada tab Logs, periksa log startup untuk menemukan exception dan lakukan troubleshooting berdasarkan informasi yang tersedia.
Jika JobManager berhasil dimulai, Anda dapat melihat log JobManager atau TaskManager secara rinci pada tab Logs.
Error umum
Detail error
Penyebab
Solusi
ERROR: exceeded quota: resourcequotaAntrian sumber daya memiliki sumber daya yang tidak mencukupi.
Upgrade atau downgrade sumber daya untuk antrian sumber daya, atau kurangi sumber daya yang dibutuhkan untuk memulai job.
ERROR:the vswitch ip is not enoughJumlah alamat IP yang tersedia dalam proyek lebih sedikit daripada jumlah TaskManager (TM) yang dibutuhkan oleh job.
Kurangi parallelism, konfigurasikan slot dengan benar, atau ubah virtual switch ruang kerja.
ERROR: pooler: ***: authentication failedAccessKey yang diberikan dalam kode tidak valid atau tidak memiliki izin yang diperlukan.
Berikan AccessKey yang valid dan memiliki izin yang diperlukan.
Apa yang harus saya lakukan jika muncul pop-up error koneksi database di sisi kanan halaman?
Detail
Penyebab
Catalog yang terdaftar tidak valid dan tidak dapat dihubungkan.
Solusi
Pada halaman Data Management, lihat semua catalog. Hapus catalog yang berwarna abu-abu, lalu daftarkan ulang.
Apa yang harus saya lakukan jika data dalam pipeline tidak dikonsumsi setelah job berjalan?
Periksa konektivitas jaringan
Jika komponen upstream dan downstream tidak menghasilkan atau mengonsumsi data, pertama-tama periksa halaman Startup Logs untuk mencari pesan error. Jika muncul error timeout, lakukan troubleshooting konektivitas jaringan untuk komponen tersebut.
Periksa status eksekusi task
Pada halaman Overview, periksa apakah source mengirim data dan sink menerima data untuk mengidentifikasi lokasi masalah.

Lakukan pemeriksaan tautan data secara menyeluruh
Tambahkan tabel sink print ke setiap aliran data untuk melakukan troubleshooting.
Apa yang harus saya lakukan jika job restart setelah berjalan?
Anda dapat melakukan troubleshooting pada tab Logs job:
Periksa exceptions.
Pada tab Exceptions, lihat exception yang dilemparkan dan lakukan troubleshooting berdasarkan informasi yang tersedia.
Lihat log JobManager dan TaskManager.
Lihat log failed TaskManagers.
Beberapa exception dapat menyebabkan TaskManager gagal. Log TaskManager yang baru dijadwalkan mungkin tidak lengkap. Anda dapat melihat log TaskManager yang sebelumnya gagal untuk troubleshooting.
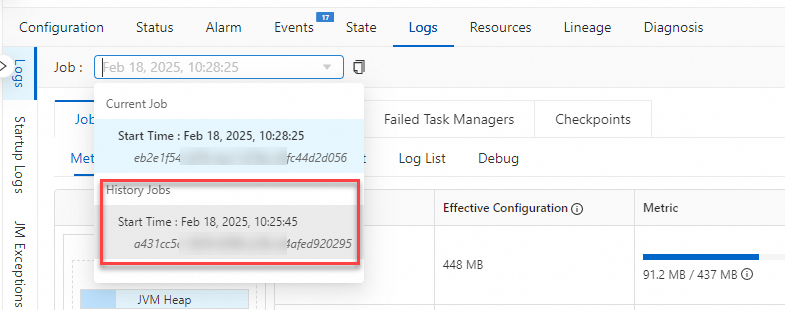
Lihat log historical job runs.
Pilih log dari jalannya job historis saat ini untuk menemukan penyebab kegagalan.
Mengapa data terjebak di node LocalGroupAggregate dalam waktu lama tanpa output?
Kode pekerjaan
CREATE TEMPORARY TABLE s1 ( a INT, b INT, ts as PROCTIME(), PRIMARY KEY (a) NOT ENFORCED ) WITH ( 'connector'='datagen', 'rows-per-second'='1', 'fields.b.kind'='random', 'fields.b.min'='0', 'fields.b.max'='10' ); CREATE TEMPORARY TABLE sink ( a BIGINT, b BIGINT ) WITH ( 'connector'='print' ); CREATE TEMPORARY VIEW window_view AS SELECT window_start, window_end, a, sum(b) as b_sum FROM TABLE(TUMBLE(TABLE s1, DESCRIPTOR(ts), INTERVAL '2' SECONDS)) GROUP BY window_start, window_end, a; INSERT INTO sink SELECT count(distinct a), b_sum FROM window_view GROUP BY b_sum;Deskripsi masalah
Data terjebak di node LocalGroupAggregate dalam waktu lama tanpa output, dan node MiniBatchAssigner tidak ada.

Penyebab
Jika job berisi WindowAggregate dan GroupAggregate, serta kolom waktu untuk WindowAggregate adalah processing time (proctime), mode pemrosesan MiniBatch menggunakan managed memory untuk menyimpan cache data jika parameter
table.exec.mini-batch.sizetidak dikonfigurasi atau diatur ke nilai negatif. Hal ini juga mencegah pembuatan node MiniBatchAssigner.Akibatnya, node komputasi tidak dapat menerima pesan watermark dari node MiniBatchAssigner untuk memicu perhitungan dan output. Perhitungan dan output hanya dipicu ketika salah satu dari tiga kondisi terpenuhi: managed memory penuh, checkpoint akan terjadi, atau job berhenti. Untuk informasi lebih lanjut, lihat table.exec.mini-batch.size. Jika interval checkpoint terlalu lama, data menumpuk di node LocalGroupAggregate dan tidak di-output dalam periode yang lama.
Solusi
Kurangi interval checkpoint. Ini memungkinkan node LocalGroupAggregate secara otomatis memicu output sebelum checkpoint terjadi. Untuk informasi lebih lanjut tentang cara mengatur interval checkpoint, lihat Tuning Checkpointing.
Gunakan heap memory untuk menyimpan cache data. Ini memungkinkan node LocalGroupAggregate secara otomatis memicu output ketika jumlah catatan data yang di-cache mencapai N. Untuk melakukannya, atur parameter
table.exec.mini-batch.sizeke nilai positif N. Untuk informasi lebih lanjut tentang konfigurasi parameter, lihat Bagaimana cara mengonfigurasi parameter custom job running?
Apa yang harus dilakukan jika partisi connector upstream tidak menerima data, menyebabkan watermark terhenti dan output window tertunda?
Sebagai contoh, pertimbangkan source Kafka dengan lima partisi. Dua catatan baru tiba setiap menit, tetapi tidak setiap partisi menerima data secara real-time. Jika source tidak menerima elemen apa pun dalam periode timeout, partisi tersebut ditandai sebagai idle sementara. Akibatnya, watermark tidak dapat maju, window tidak dapat ditutup tepat waktu, dan hasil tidak di-output secara real-time.
Dalam kasus ini, Anda dapat mengatur time-to-live (TTL) untuk menunjukkan bahwa partisi tidak memiliki data. Hal ini mengecualikan partisi dari perhitungan watermark. Ketika data tiba, partisi tersebut dimasukkan kembali ke dalam perhitungan. Untuk informasi lebih lanjut, lihat Configuration.
Pada bagian Additional Configurations, tambahkan kode berikut. Untuk informasi lebih lanjut, lihat Bagaimana cara mengonfigurasi parameter custom job running?.
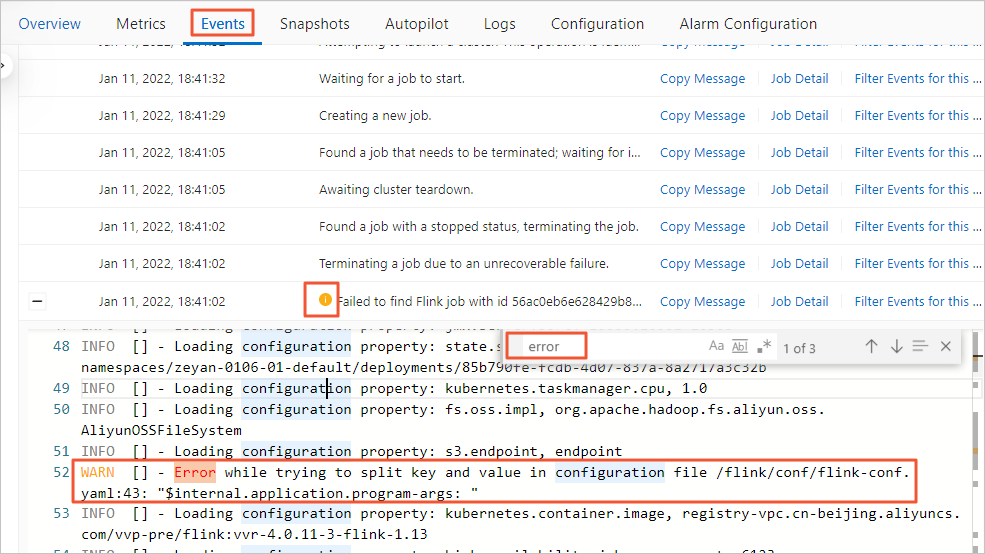
table.exec.source.idle-timeout: 1sBagaimana cara cepat menemukan masalah jika JobManager tidak berjalan?
Jika JobManager tidak berjalan, Anda tidak dapat mengakses halaman Flink UI. Dalam kasus ini, Anda dapat mengidentifikasi penyebab kegagalan dengan langkah-langkah berikut:
Pada halaman , klik nama job target.
Klik tab Events.
Gunakan pintasan keyboard untuk mencari "error" dan mengambil informasi exception.
Windows: Ctrl+F
macOS: Command+F
INFO: org.apache.flink.fs.osshadoop.shaded.com.aliyun.oss
Detail error

Penyebab
Kelas penyimpanan adalah OSS Bucket. Saat OSS membuat folder baru, OSS terlebih dahulu memeriksa apakah folder tersebut sudah ada. Jika folder tidak ada, pesan INFO ini dilaporkan. Pesan ini tidak memengaruhi job Flink.
Solusi
Tambahkan
<Logger level="ERROR" name="org.apache.flink.fs.osshadoop.shaded.com.aliyun.oss"/>ke templat log. Untuk informasi lebih lanjut, lihat Konfigurasi output log job.
Error: akka.pattern.AskTimeoutException
Penyebab
Pengumpulan sampah (GC) berkelanjutan terjadi karena memori JobManager atau TaskManager tidak mencukupi. Hal ini menyebabkan heartbeat dan permintaan Remote Procedure Call (RPC) antara JobManager dan TaskManager timeout.
Job berukuran besar, artinya volume permintaan RPC tinggi. Namun, sumber daya JobManager tidak mencukupi, menyebabkan penumpukan permintaan RPC. Hal ini menyebabkan timeout untuk heartbeat dan permintaan RPC antara JobManager dan TaskManager.
Parameter timeout job diatur ke nilai kecil. Ketika koneksi ke produk pihak ketiga gagal, sistem mencoba menghubungkan kembali beberapa kali. Hal ini mencegah error kegagalan koneksi dilemparkan sebelum timeout tercapai.
Solusi
Jika error disebabkan oleh GC berkelanjutan, periksa waktu yang dikonsumsi dan frekuensi GC berdasarkan penggunaan memori job dan log GC. Jika ditemukan GC berfrekuensi tinggi atau waktu GC yang lama, tingkatkan memori JobManager dan TaskManager.
Jika error disebabkan oleh job besar, tingkatkan sumber daya CPU dan memori JobManager. Anda juga dapat meningkatkan nilai parameter
akka.ask.timeoutdanheartbeat.timeout.PentingKami merekomendasikan Anda hanya menyesuaikan dua parameter ini untuk job berskala besar. Untuk job skala kecil, error ini biasanya bukan disebabkan oleh nilai parameter yang kecil.
Atur parameter ini sesuai kebutuhan. Jika nilainya terlalu besar, waktu pemulihan job meningkat jika TaskManager keluar secara tak terduga.
Jika timeout disebabkan oleh kegagalan koneksi ke produk pihak ketiga, pertama-tama tingkatkan nilai empat parameter berikut agar error pihak ketiga dapat dilemparkan. Setelah itu, Anda dapat menyelesaikan error pihak ketiga tersebut.
client.timeout: Default: 60 s. Direkomendasikan: 600 s.akka.ask.timeout: Default: 10 s. Direkomendasikan: 600 s.client.heartbeat.timeout: Default: 180000 s. Direkomendasikan: 600000 s. Saat memasukkan nilai, jangan sertakan unitnya. Jika tidak, error startup dapat terjadi. Misalnya, Anda dapat memasukkanclient.heartbeat.timeout: 600000.heartbeat.timeout: Default: 50000 ms. Direkomendasikan: 600000 ms. Saat memasukkan nilai, jangan sertakan unitnya. Jika tidak, error startup dapat terjadi. Misalnya, Anda dapat memasukkanheartbeat.timeout: 600000.
Sebagai contoh, error
Caused by: java.sql.SQLTransientConnectionException: connection-pool-xxx.mysql.rds.aliyuncs.com:3306 - Connection is not available, request timed out after 30000msmenunjukkan bahwa kolam koneksi MySQL penuh. Anda harus meningkatkan nilai parameterconnection.pool.sizedalam opsi WITH MySQL. Nilai default-nya adalah 20.CatatanAnda dapat menentukan nilai minimum untuk parameter di atas berdasarkan pesan error timeout. Sebagai contoh, dalam
pattern.AskTimeoutException: Ask timed out on [Actor[akka://flink/user/rpc/dispatcher_1#1064915964]] after [60000 ms]., 60000 ms adalah nilai saat ini dariclient.timeout.
Error: Task did not exit gracefully within 180 + seconds.
Detail error
Task did not exit gracefully within 180 + seconds. 2022-04-22T17:32:25.852861506+08:00 stdout F org.apache.flink.util.FlinkRuntimeException: Task did not exit gracefully within 180 + seconds. 2022-04-22T17:32:25.852865065+08:00 stdout F at org.apache.flink.runtime.taskmanager.Task$TaskCancelerWatchDog.run(Task.java:1709) [flink-dist_2.11-1.12-vvr-3.0.4-SNAPSHOT.jar:1.12-vvr-3.0.4-SNAPSHOT] 2022-04-22T17:32:25.852867996+08:00 stdout F at java.lang.Thread.run(Thread.java:834) [?:1.8.0_102] log_level:ERRORPenyebab
Error ini bukan penyebab utama exception job. Nilai default parameter
task.cancellation.timeout, yang menentukan timeout untuk task keluar, adalah 180 detik. Selama proses failover atau keluar job, keluar task mungkin diblokir karena suatu alasan. Ketika waktu pemblokiran mencapai timeout, Flink menentukan bahwa task macet dan tidak dapat dipulihkan. Flink kemudian secara aktif menghentikan TaskManager tempat task tersebut berada agar proses failover atau keluar dapat berlanjut. Inilah mengapa error ini muncul dalam log.Penyebab sebenarnya mungkin masalah pada implementasi user-defined function (UDF) Anda, seperti blok yang berjalan lama di metode close atau metode perhitungan yang tidak mengembalikan hasil dalam waktu lama.
Solusi
Atur parameter
task.cancellation.timeoutke 0. Untuk informasi lebih lanjut tentang cara mengonfigurasi parameter ini, lihat Bagaimana cara mengonfigurasi parameter custom job running? Saat nilainya 0, keluar task yang diblokir tidak akan timeout, dan task akan menunggu tanpa batas hingga proses keluar selesai. Setelah Anda me-restart job, jika menemukan bahwa job kembali terblokir dalam waktu lama selama failover atau keluar, temukan task yang berada dalam status Cancelling. Periksa stack task tersebut untuk menyelidiki penyebab utama, lalu selesaikan masalah tersebut.PentingParameter
task.cancellation.timeoutdigunakan untuk debugging job. Jangan atur parameter ini ke 0 untuk job produksi.
Error: Can not retract a non-existent record. This should never happen.
Detail error
java.lang.RuntimeException: Can not retract a non-existent record. This should never happen. at org.apache.flink.table.runtime.operators.rank.RetractableTopNFunction.processElement(RetractableTopNFunction.java:196) at org.apache.flink.table.runtime.operators.rank.RetractableTopNFunction.processElement(RetractableTopNFunction.java:55) at org.apache.flink.streaming.api.operators.KeyedProcessOperator.processElement(KeyedProcessOperator.java:83) at org.apache.flink.streaming.runtime.tasks.OneInputStreamTask$StreamTaskNetworkOutput.emitRecord(OneInputStreamTask.java:205) at org.apache.flink.streaming.runtime.io.AbstractStreamTaskNetworkInput.processElement(AbstractStreamTaskNetworkInput.java:135) at org.apache.flink.streaming.runtime.io.AbstractStreamTaskNetworkInput.emitNext(AbstractStreamTaskNetworkInput.java:106) at org.apache.flink.streaming.runtime.io.StreamOneInputProcessor.processInput(StreamOneInputProcessor.java:66) at org.apache.flink.streaming.runtime.tasks.StreamTask.processInput(StreamTask.java:424) at org.apache.flink.streaming.runtime.tasks.mailbox.MailboxProcessor.runMailboxLoop(MailboxProcessor.java:204) at org.apache.flink.streaming.runtime.tasks.StreamTask.runMailboxLoop(StreamTask.java:685) at org.apache.flink.streaming.runtime.tasks.StreamTask.executeInvoke(StreamTask.java:640) at org.apache.flink.streaming.runtime.tasks.StreamTask.runWithCleanUpOnFail(StreamTask.java:651) at org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:624) at org.apache.flink.runtime.taskmanager.Task.doRun(Task.java:799) at org.apache.flink.runtime.taskmanager.Task.run(Task.java:586) at java.lang.Thread.run(Thread.java:877)Penyebab dan solusi
Skenario
Penyebab
Solusi
Skenario 1
Disebabkan oleh fungsi
now()dalam kode.TopN tidak mendukung bidang non-deterministik dalam klausa ORDER BY atau PARTITION BY. Fungsi
now()mengembalikan nilai berbeda setiap kali dipanggil, sehingga retraction tidak dapat menemukan nilai sebelumnya.Gunakan bidang dari tabel sumber yang hanya menghasilkan nilai deterministik untuk klausa ORDER BY dan PARTITION BY.
Skenario 2
Nilai parameter
table.exec.state.ttlterlalu kecil. State dihapus setelah kedaluwarsa, dan keystate yang sesuai tidak dapat ditemukan selama retraction.Tingkatkan nilai parameter
table.exec.state.ttl. Untuk informasi lebih lanjut tentang cara mengonfigurasi parameter ini, lihat Bagaimana cara mengonfigurasi parameter custom job running?.
Error: The GRPC call timed out in sqlserver
Detail error
org.apache.flink.table.sqlserver.utils.ExecutionTimeoutException: The GRPC call timed out in sqlserver, please check the thread stacktrace for root cause: Thread name: sqlserver-operation-pool-thread-4, thread state: TIMED_WAITING, thread stacktrace: at java.lang.Thread.sleep0(Native Method) at java.lang.Thread.sleep(Thread.java:360) at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.processWaitTimeAndRetryInfo(RetryInvocationHandler.java:130) at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invokeOnce(RetryInvocationHandler.java:107) at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:359) at com.sun.proxy.$Proxy195.getFileInfo(Unknown Source) at org.apache.hadoop.hdfs.DFSClient.getFileInfo(DFSClient.java:1661) at org.apache.hadoop.hdfs.DistributedFileSystem$29.doCall(DistributedFileSystem.java:1577) at org.apache.hadoop.hdfs.DistributedFileSystem$29.doCall(DistributedFileSystem.java:1574) at org.apache.hadoop.fs.FileSystemLinkResolver.resolve(FileSystemLinkResolver.java:81) at org.apache.hadoop.hdfs.DistributedFileSystem.getFileStatus(DistributedFileSystem.java:1589) at org.apache.hadoop.fs.FileSystem.exists(FileSystem.java:1683) at org.apache.flink.connectors.hive.HiveSourceFileEnumerator.getNumFiles(HiveSourceFileEnumerator.java:118) at org.apache.flink.connectors.hive.HiveTableSource.lambda$getDataStream$0(HiveTableSource.java:209) at org.apache.flink.connectors.hive.HiveTableSource$$Lambda$972/1139330351.get(Unknown Source) at org.apache.flink.connectors.hive.HiveParallelismInference.logRunningTime(HiveParallelismInference.java:118) at org.apache.flink.connectors.hive.HiveParallelismInference.infer(HiveParallelismInference.java:100) at org.apache.flink.connectors.hive.HiveTableSource.getDataStream(HiveTableSource.java:207) at org.apache.flink.connectors.hive.HiveTableSource$1.produceDataStream(HiveTableSource.java:123) at org.apache.flink.table.planner.plan.nodes.exec.common.CommonExecTableSourceScan.translateToPlanInternal(CommonExecTableSourceScan.java:127) at org.apache.flink.table.planner.plan.nodes.exec.ExecNodeBase.translateToPlan(ExecNodeBase.java:226) at org.apache.flink.table.planner.plan.nodes.exec.ExecEdge.translateToPlan(ExecEdge.java:290) at org.apache.flink.table.planner.plan.nodes.exec.ExecNodeBase.lambda$translateInputToPlan$5(ExecNodeBase.java:267) at org.apache.flink.table.planner.plan.nodes.exec.ExecNodeBase$$Lambda$949/77002396.apply(Unknown Source) at java.util.stream.ReferencePipeline$3$1.accept(ReferencePipeline.java:193) at java.util.stream.ReferencePipeline$2$1.accept(ReferencePipeline.java:175) at java.util.ArrayList$ArrayListSpliterator.forEachRemaining(ArrayList.java:1374) at java.util.stream.AbstractPipeline.copyInto(AbstractPipeline.java:481) at java.util.stream.AbstractPipeline.wrapAndCopyInto(AbstractPipeline.java:471) at java.util.stream.ReduceOps$ReduceOp.evaluateSequential(ReduceOps.java:708) at java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:234) at java.util.stream.ReferencePipeline.collect(ReferencePipeline.java:499) at org.apache.flink.table.planner.plan.nodes.exec.ExecNodeBase.translateInputToPlan(ExecNodeBase.java:268) at org.apache.flink.table.planner.plan.nodes.exec.ExecNodeBase.translateInputToPlan(ExecNodeBase.java:241) at org.apache.flink.table.planner.plan.nodes.exec.stream.StreamExecExchange.translateToPlanInternal(StreamExecExchange.java:87) at org.apache.flink.table.planner.plan.nodes.exec.ExecNodeBase.translateToPlan(ExecNodeBase.java:226) at org.apache.flink.table.planner.plan.nodes.exec.ExecEdge.translateToPlan(ExecEdge.java:290) at org.apache.flink.table.planner.plan.nodes.exec.ExecNodeBase.lambda$translateInputToPlan$5(ExecNodeBase.java:267) at org.apache.flink.table.planner.plan.nodes.exec.ExecNodeBase$$Lambda$949/77002396.apply(Unknown Source) at java.util.stream.ReferencePipeline$3$1.accept(ReferencePipeline.java:193) at java.util.stream.ReferencePipeline$2$1.accept(ReferencePipeline.java:175) at java.util.ArrayList$ArrayListSpliterator.forEachRemaining(ArrayList.java:1374) at java.util.stream.AbstractPipeline.copyInto(AbstractPipeline.java:481) at java.util.stream.AbstractPipeline.wrapAndCopyInto(AbstractPipeline.java:471) at java.util.stream.ReduceOps$ReduceOp.evaluateSequential(ReduceOps.java:708) at java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:234) at java.util.stream.ReferencePipeline.collect(ReferencePipeline.java:499) at org.apache.flink.table.planner.plan.nodes.exec.ExecNodeBase.translateInputToPlan(ExecNodeBase.java:268) at org.apache.flink.table.planner.plan.nodes.exec.ExecNodeBase.translateInputToPlan(ExecNodeBase.java:241) at org.apache.flink.table.planner.plan.nodes.exec.stream.StreamExecGroupAggregate.translateToPlanInternal(StreamExecGroupAggregate.java:148) at org.apache.flink.table.planner.plan.nodes.exec.ExecNodeBase.translateToPlan(ExecNodeBase.java:226) at org.apache.flink.table.planner.plan.nodes.exec.ExecEdge.translateToPlan(ExecEdge.java:290) at org.apache.flink.table.planner.plan.nodes.exec.ExecNodeBase.lambda$translateInputToPlan$5(ExecNodeBase.java:267) at org.apache.flink.table.planner.plan.nodes.exec.ExecNodeBase$$Lambda$949/77002396.apply(Unknown Source) at java.util.stream.ReferencePipeline$3$1.accept(ReferencePipeline.java:193) at java.util.stream.ReferencePipeline$2$1.accept(ReferencePipeline.java:175) at java.util.ArrayList$ArrayListSpliterator.forEachRemaining(ArrayList.java:1374) at java.util.stream.AbstractPipeline.copyInto(AbstractPipeline.java:481) at java.util.stream.AbstractPipeline.wrapAndCopyInto(AbstractPipeline.java:471) at java.util.stream.ReduceOps$ReduceOp.evaluateSequential(ReduceOps.java:708) at java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:234) at java.util.stream.ReferencePipeline.collect(ReferencePipeline.java:499) at org.apache.flink.table.planner.plan.nodes.exec.ExecNodeBase.translateInputToPlan(ExecNodeBase.java:268) at org.apache.flink.table.planner.plan.nodes.exec.ExecNodeBase.translateInputToPlan(ExecNodeBase.java:241) at org.apache.flink.table.planner.plan.nodes.exec.stream.StreamExecSink.translateToPlanInternal(StreamExecSink.java:108) at org.apache.flink.table.planner.plan.nodes.exec.ExecNodeBase.translateToPlan(ExecNodeBase.java:226) at org.apache.flink.table.planner.delegation.StreamPlanner$$anonfun$1.apply(StreamPlanner.scala:74) at org.apache.flink.table.planner.delegation.StreamPlanner$$anonfun$1.apply(StreamPlanner.scala:73) at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:234) at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:234) at scala.collection.Iterator$class.foreach(Iterator.scala:891) at scala.collection.AbstractIterator.foreach(Iterator.scala:1334) at scala.collection.IterableLike$class.foreach(IterableLike.scala:72) at scala.collection.AbstractIterable.foreach(Iterable.scala:54) at scala.collection.TraversableLike$class.map(TraversableLike.scala:234) at scala.collection.AbstractTraversable.map(Traversable.scala:104) at org.apache.flink.table.planner.delegation.StreamPlanner.translateToPlan(StreamPlanner.scala:73) at org.apache.flink.table.planner.delegation.StreamExecutor.createStreamGraph(StreamExecutor.java:52) at org.apache.flink.table.planner.delegation.PlannerBase.createStreamGraph(PlannerBase.scala:610) at org.apache.flink.table.planner.delegation.StreamPlanner.explainExecNodeGraphInternal(StreamPlanner.scala:166) at org.apache.flink.table.planner.delegation.StreamPlanner.explainExecNodeGraph(StreamPlanner.scala:159) at org.apache.flink.table.sqlserver.execution.OperationExecutorImpl.validate(OperationExecutorImpl.java:304) at org.apache.flink.table.sqlserver.execution.OperationExecutorImpl.validate(OperationExecutorImpl.java:288) at org.apache.flink.table.sqlserver.execution.DelegateOperationExecutor.lambda$validate$22(DelegateOperationExecutor.java:211) at org.apache.flink.table.sqlserver.execution.DelegateOperationExecutor$$Lambda$394/1626790418.run(Unknown Source) at org.apache.flink.table.sqlserver.execution.DelegateOperationExecutor.wrapClassLoader(DelegateOperationExecutor.java:250) at org.apache.flink.table.sqlserver.execution.DelegateOperationExecutor.lambda$wrapExecutor$26(DelegateOperationExecutor.java:275) at org.apache.flink.table.sqlserver.execution.DelegateOperationExecutor$$Lambda$395/1157752141.run(Unknown Source) at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) at java.util.concurrent.FutureTask.run(FutureTask.java:266) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1147) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:622) at java.lang.Thread.run(Thread.java:834) at org.apache.flink.table.sqlserver.execution.DelegateOperationExecutor.wrapExecutor(DelegateOperationExecutor.java:281) at org.apache.flink.table.sqlserver.execution.DelegateOperationExecutor.validate(DelegateOperationExecutor.java:211) at org.apache.flink.table.sqlserver.FlinkSqlServiceImpl.validate(FlinkSqlServiceImpl.java:786) at org.apache.flink.table.sqlserver.proto.FlinkSqlServiceGrpc$MethodHandlers.invoke(FlinkSqlServiceGrpc.java:2522) at io.grpc.stub.ServerCalls$UnaryServerCallHandler$UnaryServerCallListener.onHalfClose(ServerCalls.java:172) at io.grpc.internal.ServerCallImpl$ServerStreamListenerImpl.halfClosed(ServerCallImpl.java:331) at io.grpc.internal.ServerImpl$JumpToApplicationThreadServerStreamListener$1HalfClosed.runInContext(ServerImpl.java:820) at io.grpc.internal.ContextRunnable.run(ContextRunnable.java:37) at io.grpc.internal.SerializingExecutor.run(SerializingExecutor.java:123) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1147) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:622) at java.lang.Thread.run(Thread.java:834) Caused by: java.util.concurrent.TimeoutException at java.util.concurrent.FutureTask.get(FutureTask.java:205) at org.apache.flink.table.sqlserver.execution.DelegateOperationExecutor.wrapExecutor(DelegateOperationExecutor.java:277) ... 11 morePenyebab
Pernyataan SQL yang terlalu kompleks dapat menyebabkan exception timeout.
Solusi
Pada bagian Additional Configurations, tambahkan kode berikut untuk meningkatkan batas timeout default 120 detik. Untuk informasi lebih lanjut, lihat Bagaimana cara mengonfigurasi parameter custom job running?.
flink.sqlserver.rpc.execution.timeout: 600s
Error: RESOURCE_EXHAUSTED: gRPC message exceeds maximum size 41943040: 58384051
Detail error
Caused by: io.grpc.StatusRuntimeException: RESOURCE_EXHAUSTED: gRPC message exceeds maximum size 41943040: 58384051 at io.grpc.stub.ClientCalls.toStatusRuntimeException(ClientCalls.java:244) at io.grpc.stub.ClientCalls.getUnchecked(ClientCalls.java:225) at io.grpc.stub.ClientCalls.blockingUnaryCall(ClientCalls.java:142) at org.apache.flink.table.sqlserver.proto.FlinkSqlServiceGrpc$FlinkSqlServiceBlockingStub.generateJobGraph(FlinkSqlServiceGrpc.java:2478) at org.apache.flink.table.sqlserver.api.client.FlinkSqlServerProtoClientImpl.generateJobGraph(FlinkSqlServerProtoClientImpl.java:456) at org.apache.flink.table.sqlserver.api.client.ErrorHandlingProtoClient.lambda$generateJobGraph$25(ErrorHandlingProtoClient.java:251) at org.apache.flink.table.sqlserver.api.client.ErrorHandlingProtoClient.invokeRequest(ErrorHandlingProtoClient.java:335) ... 6 more Cause: RESOURCE_EXHAUSTED: gRPC message exceeds maximum size 41943040: 58384051)Penyebab
Logika job sangat kompleks, sehingga JobGraph yang dihasilkan terlalu besar. Hal ini dapat menyebabkan error validasi atau job macet selama startup atau shutdown.
Solusi
Pada bagian Additional Configurations, tambahkan kode berikut. Untuk informasi lebih lanjut, lihat Bagaimana cara mengonfigurasi parameter custom job running?.
table.exec.operator-name.max-length: 1000
Error: Caused by: java.lang.NoSuchMethodError
Detail error
Error: Caused by: java.lang.NoSuchMethodError: org.apache.flink.table.planner.plan.metadata.FlinkRelMetadataQuery.getUpsertKeysInKeyGroupRange(Lorg/apache/calcite/rel/RelNode;[I)Ljava/util/SetPenyebab
Jika Anda bergantung pada API internal dari komunitas, dan versi API ini di Alibaba Cloud telah dioptimalkan, exception seperti konflik package dapat terjadi.
Solusi
Dalam kode sumber Flink, hanya metode yang secara eksplisit dianotasi dengan @Public atau @PublicEvolving yang merupakan API publik yang dapat Anda panggil. Alibaba Cloud hanya menjamin kompatibilitas untuk metode-metode tersebut.
Error: java.lang.ClassCastException: org.codehaus.janino.CompilerFactory cannot be cast to org.codehaus.commons.compiler.ICompilerFactory
Detail error
Causedby:java.lang.ClassCastException:org.codehaus.janino.CompilerFactorycannotbecasttoorg.codehaus.commons.compiler.ICompilerFactory atorg.codehaus.commons.compiler.CompilerFactoryFactory.getCompilerFactory(CompilerFactoryFactory.java:129) atorg.codehaus.commons.compiler.CompilerFactoryFactory.getDefaultCompilerFactory(CompilerFactoryFactory.java:79) atorg.apache.calcite.rel.metadata.JaninoRelMetadataProvider.compile(JaninoRelMetadataProvider.java:426) ...66morePenyebab
Paket JAR mencakup dependensi janino yang konflik.
Paket JAR user-defined function (UDF) atau connector JAR mencakup JAR yang diawali dengan
flink-, seperti flink-table-planner dan flink-table-runtime.
Solusi
Analisis apakah paket JAR berisi org.codehaus.janino.CompilerFactory. Konflik kelas dapat terjadi karena urutan pemuatan kelas berbeda di mesin yang berbeda. Untuk mengatasi masalah ini, lakukan langkah-langkah berikut:
Pada halaman , klik nama job target.
Pada tab Deployment Details, klik Edit di sebelah kanan bagian Running Parameter Configuration.
Pada kotak teks Additional Configurations, masukkan parameter berikut dan klik Save.
classloader.parent-first-patterns.additional: org.codehaus.janinoGanti nilai parameter dengan kelas yang konflik.
Atur cakupan untuk dependensi terkait Flink ke `provided` dengan menambahkan
<scope>provided</scope>. Hal ini terutama berlaku untuk dependensi non-Connector dalam gruporg.apache.flinkyang diawali denganflink-.