Saat menggunakan Notebook di Alibaba Cloud E-MapReduce (EMR) Serverless Spark, Anda dapat menjalankan perintah Hadoop untuk mengakses Object Storage Service (OSS) atau OSS-HDFS. Topik ini menjelaskan cara menjalankan perintah Hadoop di dalam notebook EMR Serverless Spark untuk melakukan operasi terkait OSS atau OSS-HDFS.
Prasyarat
EMR Serverless Spark:
Sesi Notebook telah dibuat. Contoh ini menggunakan notebook dengan versi mesin esr-4.1.1. Untuk informasi lebih lanjut, lihat Kelola sesi notebook.
Notebook telah dikembangkan. Untuk informasi lebih lanjut, lihat Kembangkan sebuah notebook.
OSS:
OSS telah diaktifkan dan bucket telah dibuat. Untuk informasi lebih lanjut, lihat Aktifkan OSS dan Buat sebuah bucket.
OSS-HDFS telah diaktifkan. Untuk informasi lebih lanjut, lihat Aktifkan OSS-HDFS.
Konfigurasi izin:
Izin yang diperlukan telah dikonfigurasi untuk mengakses sumber daya OSS atau OSS-HDFS lintas akun. Untuk informasi lebih lanjut, lihat Bagaimana cara menerapkan akses lintas akun ke sumber daya OSS?
CatatanDalam contoh ini, izin read and write pada OSS dikonfigurasi di konsol OSS. Anda dapat menyesuaikan izin berdasarkan kebutuhan bisnis Anda.
Batasan
Operasi yang dijelaskan dalam topik ini hanya didukung di versi mesin berikut:
esr-4.x: esr-4.1.1 atau yang lebih baru.
esr-3.x: esr-3.1.1 atau yang lebih baru.
esr-2.x: esr-2.5.1 atau yang lebih baru.
Operasi yang didukung
Berikut adalah beberapa operasi yang dapat Anda lakukan di dalam notebook dengan versi mesin esr-4.1.1:
ls: Menampilkan daftar file dan direktori di jalur OSS atau OSS-HDFS tertentu.mv: Memindahkan file atau direktori.cp: Menyalin file atau direktori.stat: Mendapatkan metadata dari file atau direktori tertentu.
Anda dapat menjalankan perintah !hadoop fs -help untuk melihat informasi bantuan.
Saat ini, semua perintah FS yang didukung oleh Jindo CLI dapat digunakan di Notebook. Untuk perintah rinci, contoh, dan skenario yang berlaku, lihat Panduan pengguna Jindo CLI. Saat menggunakan contoh di Notebook, ganti jindo dengan !hadoop.
Format jalur akses
Bagian ini menjelaskan format jalur akses OSS atau OSS-HDFS:
OSS:
oss://<bucketName>/<object-path>OSS-HDFS:
oss://<bucketName>.<region>.oss-dls.aliyuncs.com/<object-path>
Parameter dalam jalur:
<bucketName>: Nama Bucket OSS. Contoh:my-bucket.region: ID wilayah tempat Bucket OSS berada. Contoh:cn-hangzhou.<object-path>: Jalur objek di dalam Bucket OSS. Contoh:spark/file.txtataulogs/.
Penggunaan perintah
Saat mengembangkan sebuah notebook, jalankan perintah !hadoop fs untuk melakukan operasi berikut:
Menampilkan daftar file dan direktori di jalur tertentu (ls)
Jalankan perintah berikut untuk menampilkan daftar file dan direktori di jalur tertentu:
!hadoop fs -ls oss://<bucketName>/<object-path>Contoh 1: Menampilkan daftar file dan direktori di jalur spark.
!hadoop fs -ls oss://my-bucket/spark/Gambar berikut menunjukkan hasilnya.
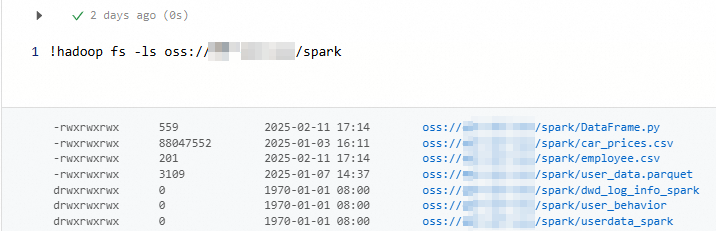
Contoh 2: Jalankan perintah
-lsdangrepbersama-sama untuk mencari file dan direktori yang namanya mencakup user:!hadoop fs -ls oss://my-bucket/spark/ | grep userGambar berikut menunjukkan hasilnya.
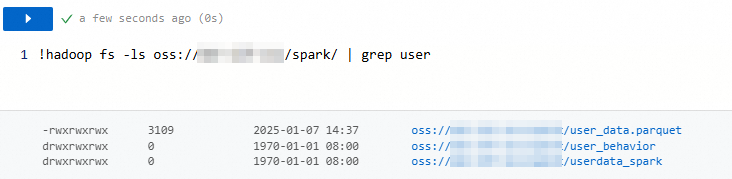
Memindahkan file atau direktori (mv)
Jalankan perintah berikut untuk memindahkan file atau direktori ke jalur tertentu:
!hadoop fs -mv oss://<bucketName>/<object-path>/source oss://<bucketName>/<object-path>/destinationSebagai contoh, jalankan perintah berikut untuk memindahkan file file.txt di jalur sr ke jalur user. Jika file file.txt sudah ada di jalur tujuan, file tersebut akan ditimpa.
!hadoop fs -mv oss://my-bucket/sr/file.txt oss://my-bucket/user/file.txtMenyalin file atau direktori (cp)
Jalankan perintah berikut untuk menyalin file atau direktori dari jalur sumber ke jalur tujuan:
!hadoop fs -cp oss://<bucketName>/<object-path>/source oss://<bucketName>/<object-path>/destinationSebagai contoh, jalankan perintah berikut untuk menyalin file file.txt dari jalur spark ke jalur spark2. Jika file file.txt sudah ada di jalur tujuan, file tersebut akan ditimpa.
!hadoop fs -cp oss://my-bucket/spark/file.txt oss://my-bucket/spark2/file.txtMelihat metadata dari file atau direktori (stat)
Jalankan perintah berikut untuk melihat detail file atau direktori tertentu:
!hadoop fs -stat oss://<bucketName>/<object-path>/to/fileSebagai contoh, jalankan perintah berikut untuk melihat metadata file file.txt:
!hadoop fs -stat oss://my-bucket/spark/file.txt