Topik ini menjawab pertanyaan yang sering diajukan (FAQ) mengenai EMR Serverless Spark.
Pertanyaan yang sering diajukan tentang EMR Serverless Spark diorganisasikan berdasarkan area kompatibilitas berikut.
Pertanyaan
Kompatibilitas DLF
Apa yang harus saya lakukan jika terjadi error java.net.UnknownHostException saat membaca data DLF?
Error ini terjadi di lingkungan Development ketika Anda menjalankan kueri SQL untuk membaca data dari tabel Data Lake Formation (DLF) 1.0, dan EMR Serverless Spark tidak dapat menyelesaikan host dalam path location tabel tersebut. Solusinya bergantung pada apakah kluster Hadoop Distributed File System (HDFS) menggunakan high availability (HA).
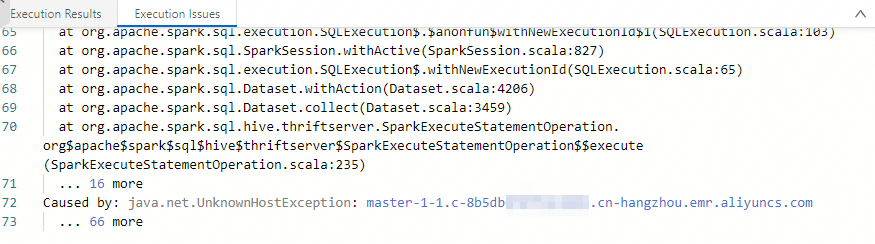
HDFS tanpa HA
Pastikan nama domain dalam path location tabel tersebut dapat diakses. Secara default, master-1-1.<cluster-id>.<region>.emr.aliyuncs.com dapat diakses secara langsung. Untuk nama domain lainnya, tambahkan pemetaan yang diperlukan. Lihat Manage Domain Names.
HDFS dengan HA
Konfigurasikan pemetaan nama domain. Lihat Manage Domain Names.
Buat file bernama
hdfs-site.xmldi/etc/spark/conf. Dasarkan isinya pada filehdfs-site.xmldari kluster EMR on ECS Anda. Lihat Manage custom configurations untuk petunjuk cara mengunggah file tersebut. Berikut adalah contoh filehdfs-site.xml. Ganti alamat NameNode dan nomor port dengan nilai dari kluster Anda.<?xml version="1.0"?> <configuration> <property> <name>dfs.nameservices</name> <value>hdfs-cluster</value> </property> <property> <name>dfs.ha.namenodes.hdfs-cluster</name> <value>nn1,nn2,nn3</value> </property> <property> <name>dfs.namenode.rpc-address.hdfs-cluster.nn1</name> <value>master-1-1.<cluster-id>.<region-id>.emr.aliyuncs.com:<port></value> </property> <property> <name>dfs.namenode.rpc-address.hdfs-cluster.nn2</name> <value>master-1-2.<cluster-id>.<region-id>.emr.aliyuncs.com:<port></value> </property> <property> <name>dfs.namenode.rpc-address.hdfs-cluster.nn3</name> <value>master-1-3.<cluster-id>.<region-id>.emr.aliyuncs.com:<port></value> </property> <property> <name>dfs.client.failover.proxy.provider.hdfs-cluster</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> </configuration>Setelah file tersebut tersedia, Java Runtime atau Fusion Runtime dapat menyelesaikan kluster HA dan mengakses data.
Kompatibilitas OSS
Bagaimana cara mengakses sumber daya OSS lintas akun?
Tersedia dua metode. Pilih berdasarkan cakupan akses yang diperlukan:
| Metode | Lingkup | Kapan digunakan |
|---|---|---|
| Tingkat ruang kerja | Semua pekerjaan di ruang kerja | Ruang kerja menjalankan banyak pekerjaan yang memerlukan akses ke bucket yang sama, dan Anda menginginkan konfigurasi tunggal yang persisten. |
| Tingkat tugas dan sesi | Tugas atau sesi tertentu | Akses bersifat sementara atau spesifik untuk tugas tertentu, atau Anda tidak memiliki izin untuk mengubah konfigurasi ruang kerja. |
Tingkat ruang kerja
Konfigurasikan kebijakan bucket dari bucket Object Storage Service (OSS) target untuk memberikan role eksekusi ruang kerja akses baca dan tulis.
Masuk ke Konsol OSS. Di panel navigasi kiri, klik Buckets, lalu klik bucket target.
Di panel navigasi kiri, pilih Permission Control > Bucket Policy.
Di halaman Bucket Policy, klik tab Add in GUI, lalu klik Authorize.
Di panel Authorize, atur parameter berikut dan klik OK. Untuk parameter lainnya, lihat Configure a bucket policy using the GUI.
Parameter Nilai Applied To Whole Bucket Authorized User Other Accounts. Atur Principal menjadi arn:sts::<uid>:assumed-role/<role-name>/*. Ganti<uid>dengan ID akun Alibaba Cloud dan<role-name>dengan nama role eksekusi (case-sensitive). Role default adalah AliyunEMRSparkJobRunDefaultRole. Untuk menemukan role eksekusi, buka halaman daftar ruang kerja dan klik Details di kolom Actions.
Tingkat tugas dan sesi
Saat membuat tugas atau sesi, tambahkan properti berikut di bagian Spark Configurations. Ganti placeholder dengan detail bucket Anda.
spark.hadoop.fs.oss.bucket.<bucketName>.endpoint <endpoint>
spark.hadoop.fs.oss.bucket.<bucketName>.credentials.provider com.aliyun.jindodata.oss.auth.SimpleCredentialsProvider
spark.hadoop.fs.oss.bucket.<bucketName>.accessKeyId <accessID>
spark.hadoop.fs.oss.bucket.<bucketName>.accessKeySecret <accessKey>| Placeholder | Deskripsi |
|---|---|
<bucketName> | Nama bucket OSS |
<endpoint> | Titik akhir OSS |
<accessID> | ID AccessKey akun Alibaba Cloud yang digunakan untuk mengakses data OSS |
<accessKey> | Rahasia AccessKey akun Alibaba Cloud yang digunakan untuk mengakses data OSS |
Kompatibilitas S3
Bagaimana cara mengakses S3?
Saat membuat tugas atau sesi, tambahkan properti berikut di bagian Spark Configurations. Ganti placeholder dengan detail bucket Anda.
spark.hadoop.fs.s3.impl com.aliyun.jindodata.s3.JindoS3FileSystem
spark.hadoop.fs.AbstractFileSystem.s3.impl com.aliyun.jindodata.s3.S3
spark.hadoop.fs.s3.bucket.<bucketName>.accessKeyId <accessID>
spark.hadoop.fs.s3.bucket.<bucketName>.accessKeySecret <accessKey>
spark.hadoop.fs.s3.bucket.<bucketName>.endpoint <endpoint>
spark.hadoop.fs.s3.credentials.provider com.aliyun.jindodata.s3.auth.SimpleCredentialsProvider| Placeholder | Deskripsi |
|---|---|
<bucketName> | Nama bucket S3 |
<endpoint> | Titik akhir S3 |
<accessID> | ID AccessKey akun yang digunakan untuk mengakses S3 |
<accessKey> | Rahasia AccessKey akun yang digunakan untuk mengakses S3 |
Kompatibilitas OBS
Bagaimana cara mengakses OBS?
Saat membuat tugas atau sesi, tambahkan properti berikut di bagian Spark Configurations. Ganti placeholder dengan detail bucket Anda.
spark.hadoop.fs.obs.impl com.aliyun.jindodata.obs.JindoObsFileSystem
spark.hadoop.fs.AbstractFileSystem.obs.impl com.aliyun.jindodata.obs.OBS
spark.hadoop.fs.obs.bucket.<bucketName>.accessKeyId <accessID>
spark.hadoop.fs.obs.bucket.<bucketName>.accessKeySecret <accessKey>
spark.hadoop.fs.obs.bucket.<bucketName>.endpoint <endpoint>
spark.hadoop.fs.obs.credentials.provider com.aliyun.jindodata.obs.auth.SimpleCredentialsProvider| Placeholder | Deskripsi |
|---|---|
<bucketName> | Nama bucket OBS |
<endpoint> | Titik akhir OBS |
<accessID> | ID AccessKey akun yang digunakan untuk mengakses OBS |
<accessKey> | Rahasia AccessKey akun yang digunakan untuk mengakses OBS |