Tinjau kerentanan keamanan dan masalah konfigurasi yang dikenal pada gambar publik, lalu terapkan perbaikan yang direkomendasikan.
-
Masalah Dikenal untuk Windows
-
Masalah Dikenal untuk Linux
-
Masalah CentOS
-
Masalah Ubuntu
-
Masalah Fedora CoreOS
-
Masalah OpenSUSE
OpenSUSE 15: Pembaruan Kernel Dapat Menyebabkan Hang Saat Startup
-
Masalah Red Hat Enterprise Linux
Red Hat Enterprise Linux 8: Kegagalan Pembaruan Kernel dengan yum
-
Masalah SUSE Linux Enterprise Server
-
Masalah AnolisOS
-
Masalah Lainnya
-
Isu yang Diketahui untuk Windows
Kegagalan fitur pada instans Windows 512 MB
-
Gejala
Jika Anda menggunakan image edisi Tiongkok Windows Server Version 2004 Datacenter 64-bit (tanpa GUI) pada tipe instans dengan memori 512 MB, Anda mungkin mengalami beberapa masalah. Misalnya, kata sandi yang ditetapkan saat pembuatan instans tidak diterapkan, Anda tidak dapat mengubah kata sandi selama waktu proses, dan perintah gagal.
-
Penyebab
File paging dinonaktifkan, sehingga alokasi memori virtual tidak dapat dilakukan dan dapat menyebabkan error program secara intermiten.
-
Solusi
Memori yang terbatas mencegah pemasangan disk Pre-installation Environment (PE). Karena kata sandi tidak diterapkan, Anda tidak dapat login secara normal. Gunakan Cloud Assistant untuk mengonfigurasi file paging.
-
Jalankan perintah melalui Cloud Assistant dengan salah satu metode berikut.
-
Gunakan Session Manager untuk terhubung tanpa kata sandi dan menjalankan perintah.
-
Gunakan Cloud Assistant untuk mengirim perintah remote.
-
-
Aktifkan manajemen otomatis file paging.
Wmic ComputerSystem set AutomaticManagedPagefile=TrueCatatan-
Jika perintah ini gagal, jalankan kembali hingga berhasil.
-
Anda juga dapat menjalankan perintah
Wmic ComputerSystem get AutomaticManagedPagefileuntuk memeriksa apakah file paging telah diaktifkan. Jika output berikut dikembalikan, berarti file paging telah diaktifkan.AutomaticManagedPagefile TRUE
-
-
Restart instans untuk menerapkan konfigurasi.
-
Windows Server 2016 hang selama instalasi perangkat lunak
-
Gejala
Saat Anda menjalankan paket perangkat lunak yang diunduh pada Windows Server 2016, sistem hang.
-
Penyebab
-
Untuk alasan keamanan, Windows mengaktifkan konfigurasi "Protect your PC" selama fase Sysprep startup. Ini memulai proses Windows SmartScreen untuk melindungi dari situs web berbahaya dan unduhan yang tidak aman.
-
Saat Anda menjalankan paket perangkat lunak yang diunduh, paket tersebut ditandai dengan pengenal web. SmartScreen dapat memblokir perangkat lunak tersebut karena berasal dari internet dan belum memiliki reputasi.
-
-
Solusi
Gunakan salah satu metode berikut:
Buka blokir paket perangkat lunak
-
Pada properti paket perangkat lunak, pilih Unblock.
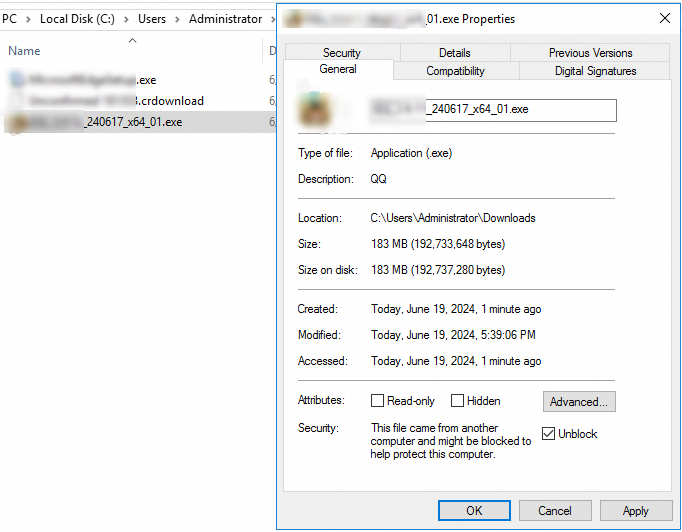
-
Jalankan kembali paket perangkat lunak tersebut.
Nonaktifkan SmartScreen
-
Buka direktori
C:\Windows\System32. -
Klik ganda file
SmartScreenSettings.exe. -
Pada kotak dialog Windows SmartScreen, pilih Don't do anything (turn off Windows SmartScreen), lalu klik OK.
-
Jalankan kembali paket perangkat lunak tersebut.
Ubah kebijakan grup
-
Buka jendela Run dan masukkan
gpedit.msc. -
Pada Local Group Policy Editor, navigasikan ke Computer Configuration > Windows Settings > Security Settings > Local Policies > Security Options.
-
Temukan dan klik kanan kebijakan User Account Control: Admin Approval Mode For The Built-in Administrator Account, lalu pilih Properties.
-
Pada tab Local Security Setting, pilih Enabled dan klik OK.
-
Restart sistem untuk menerapkan konfigurasi.
-
Jalankan kembali paket perangkat lunak tersebut.
-
Windows Server 2022: Kegagalan instalasi Patch KB5034439
-
Gejala
Patch KB5034439 gagal diinstal pada Windows Server 2022.
-
Penyebab
KB5034439 adalah pembaruan Windows Recovery Environment yang dirilis Microsoft pada Januari 2024. Jika sumber pembaruan Anda menggunakan layanan Windows Update resmi Microsoft, sistem mungkin mencoba menginstal patch ini, yang dapat gagal. Secara default, image Alibaba Cloud menggunakan server pembaruan WSUS internal dan tidak menerima patch ini. Hal ini tidak memengaruhi operasi sistem secara normal. Lihat KB5034439: Windows Recovery Environment update for Windows Server 2022: January 9, 2024.
Patch Juni 2022 menyebabkan masalah NAT dan RRAS
-
Gejala: Menurut Microsoft (23 Juni 2022), menginstal patch keamanan Juni 2022 dapat menyebabkan masalah. Misalnya, server RRAS dengan NAT yang diaktifkan mungkin kehilangan konektivitas, dan perangkat yang terhubung ke server tidak dapat mengakses internet.
-
Versi yang Terpengaruh:
-
Windows Server 2022
-
Windows Server 2019
-
Windows Server 2016
-
Windows Server 2012 R2
-
Windows Server 2012
Saat Anda memeriksa pembaruan sistem pada Windows Server 2012 R2 dan Windows Server 2012, pastikan untuk memilih opsi Check for updates yang ditandai dengan ①. Sumber pembaruan yang terhubung ke ① adalah server pembaruan WSUS Windows internal Alibaba Cloud. Sumber pembaruan yang terhubung ke ② adalah server Windows Update resmi Microsoft di internet. Dalam kasus langka, pembaruan keamanan dapat menyebabkan potensi masalah. Untuk mencegah hal tersebut, kami meninjau pembaruan keamanan Windows dari Microsoft dan merilis pembaruan yang telah disetujui ke server pembaruan WSUS internal kami.
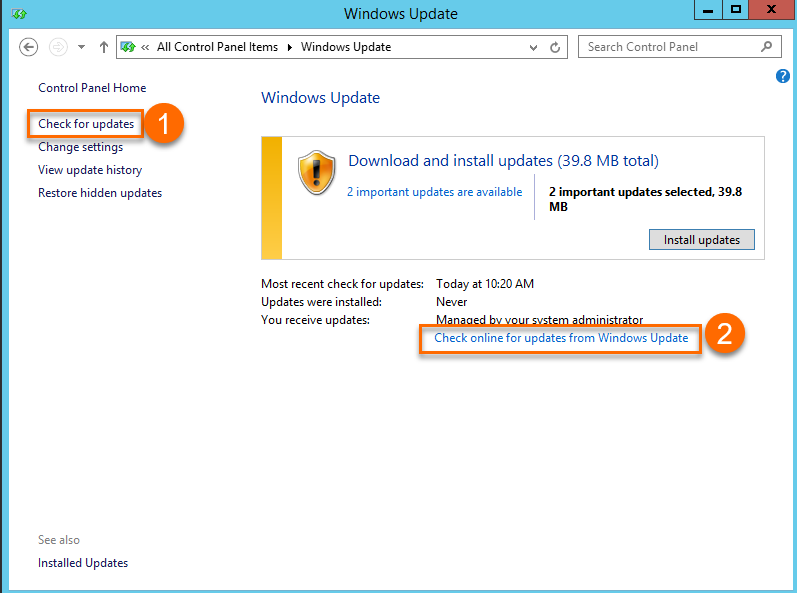
-
-
Solusi: Patch bermasalah telah dihapus dari layanan WSUS Alibaba Cloud. Jalankan perintah sesuai versi Windows Server Anda untuk memeriksa apakah patch tersebut terinstal.
Windows Server 2012 R2: wmic qfe get hotfixid | find "5014738" Windows Server 2019: wmic qfe get hotfixid | find "5014692" Windows Server 2016: wmic qfe get hotfixid | find "5014702" Windows Server 2012: wmic qfe get hotfixid | find "5014747" Windows Server 2022: wmic qfe get hotfixid | find "5014678"Jika patch bermasalah menyebabkan masalah NAT atau RRAS, uninstal dengan perintah yang sesuai.
Windows Server 2012 R2: wusa /uninstall /kb:5014738 Windows Server 2019: wusa /uninstall /kb:5014692 Windows Server 2016: wusa /uninstall /kb:5014702 Windows Server 2012: wusa /uninstall /kb:5014747 Windows Server 2022: wusa /uninstall /kb:5014678CatatanUntuk informasi terbaru mengenai isu ini, lihat RRAS Servers can lose connectivity if NAT is enabled on the public interface.
Isu patch Januari 2022 pada domain controller
-
Gejala: Menurut Microsoft (13 Januari 2022), menginstal patch keamanan Januari 2022 pada perangkat Windows dapat menyebabkan masalah. Misalnya, domain controller mungkin gagal restart atau masuk ke loop restart, mesin virtual Hyper-V mungkin gagal start, atau koneksi VPN IPsec mungkin gagal.
-
Versi yang Terpengaruh:
-
Windows Server 2022
-
Windows Server, version 20H2
-
Windows Server 2019
-
Windows Server 2016
-
Windows Server 2012 R2
-
Windows Server 2012
Saat Anda memeriksa pembaruan sistem pada Windows Server 2012 R2 dan Windows Server 2012, pastikan untuk memilih opsi Check for updates yang ditandai dengan ①. Sumber pembaruan yang terhubung ke ① adalah server pembaruan WSUS Windows internal Alibaba Cloud. Sumber pembaruan yang terhubung ke ② adalah server Windows Update resmi Microsoft di internet. Dalam kasus langka, pembaruan keamanan dapat menyebabkan potensi masalah. Untuk mencegah hal tersebut, kami meninjau pembaruan keamanan Windows dari Microsoft dan merilis pembaruan yang telah disetujui ke server pembaruan WSUS internal kami.
-
-
Solusi: Patch bermasalah telah dihapus dari layanan WSUS Alibaba Cloud. Jalankan perintah sesuai versi Windows Server Anda untuk memeriksa apakah patch tersebut terinstal.
Windows Server 2012 R2: wmic qfe get hotfixid | find "5009624" Windows Server 2019: wmic qfe get hotfixid | find "5009557" Windows Server 2016: wmic qfe get hotfixid | find "5009546" Windows Server 2012: wmic qfe get hotfixid | find "5009586" Windows Server 2022: wmic qfe get hotfixid | find "5009555"Jika patch bermasalah menyebabkan kegagalan domain controller atau mencegah mesin virtual start, uninstal dengan perintah yang sesuai.
Windows Server 2012 R2: wusa /uninstall /kb:5009624 Windows Server 2019: wusa /uninstall /kb:5009557 Windows Server 2016: wusa /uninstall /kb:5009546 Windows Server 2012: wusa /uninstall /kb:5009586 Windows Server 2022: wusa /uninstall /kb:5009555CatatanUntuk informasi terbaru mengenai isu ini, lihat dokumentasi Microsoft terkait.
Windows Server 2012 R2: Kegagalan instalasi .NET Framework 3.5
-
Deskripsi Masalah: Pada Windows Server 2012 R2 dengan versi image berikut, instalasi .NET Framework 3.5 mungkin gagal karena patch Juni 2023 KB5027141, patch Juli KB5028872, patch Agustus KB5028970, atau patch September KB5029915 telah dipra-instal.
PentingJika Anda perlu terus menggunakan Windows Server 2012 R2, buat instance ECS dari gambar komunitas dengan .NET Framework 3.5 yang telah dipra-instal di Konsol ECS. Image tersebut adalah win2012r2_9600_x64_dtc_zh-cn_40G_.Net3.5_alibase_20231204.vhd dan win2012r2_9600_x64_dtc_en-us_40G_.Net3.5_alibase_20231204.vhd. Untuk menemukan image ini, lihat Temukan image.
-
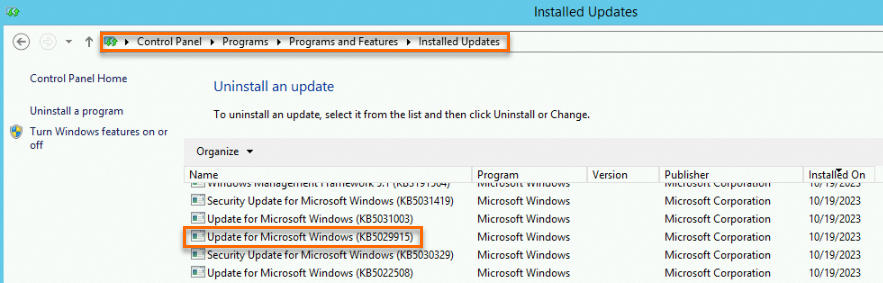
Solusi:
-
Di Control Panel, temukan patch KB5027141, KB5028872, KB5028970, atau KB5029915. Klik kanan dan pilih Uninstall.
-
Restart instance ECS.
Lihat Restart sebuah instans.
-
Instal .NET Framework 3.5 dengan salah satu metode berikut.
Antarmuka Server Manager
-
Di Server Manager, klik Add Roles and Features.
-
Ikuti wizard dengan pengaturan default. Pada halaman Features, pilih .NET Framework 3.5 Features.
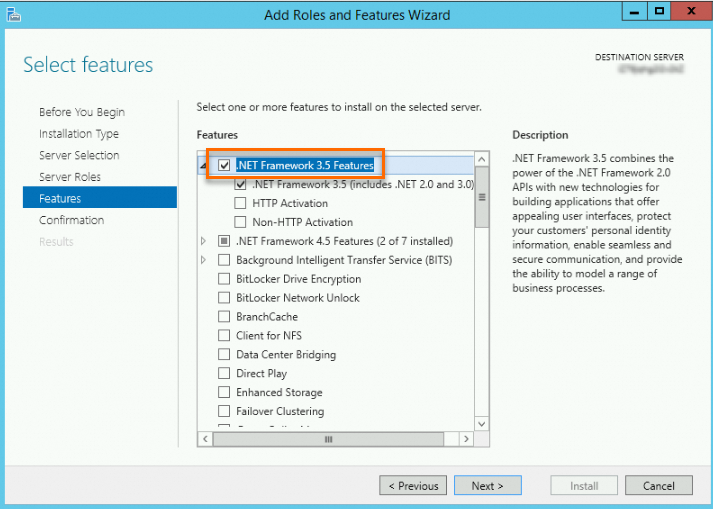
Ikuti wizard untuk mengonfirmasi dan menyelesaikan instalasi.
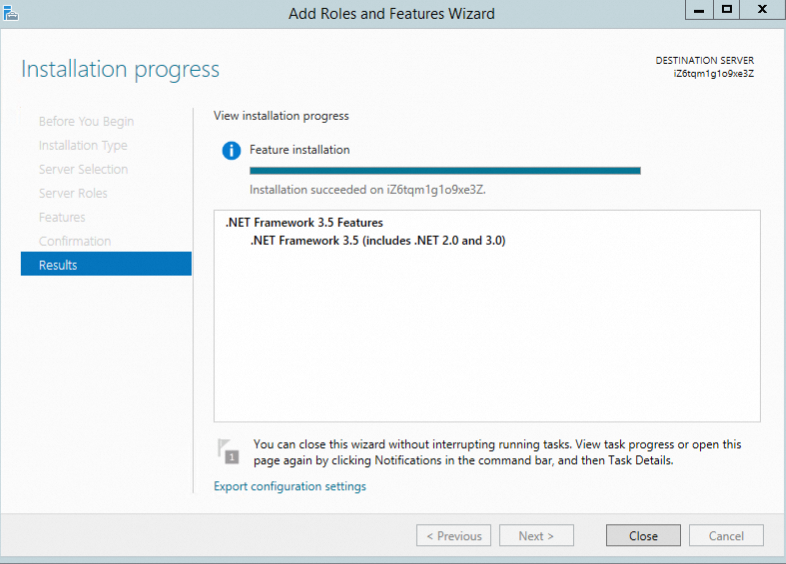
Perintah PowerShell
Jalankan salah satu perintah berikut:
-
Dism /Online /Enable-Feature /FeatureName:NetFX3 /All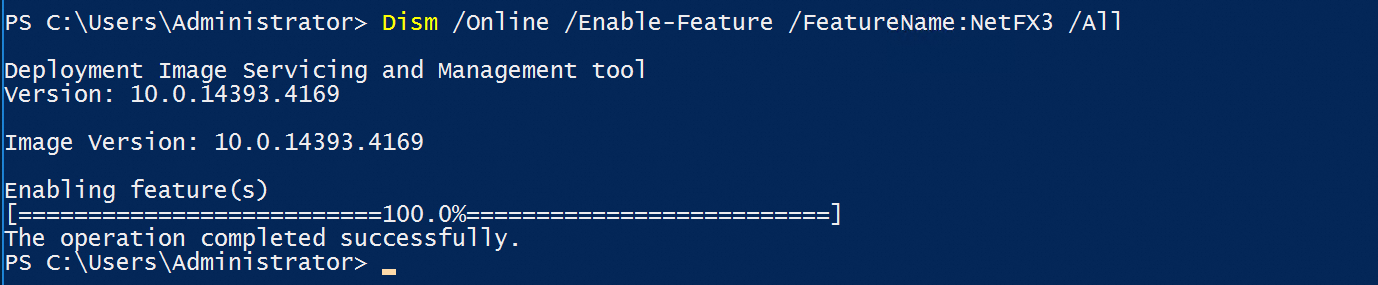
-
Install-WindowsFeature -Name NET-Framework-Features
-
-
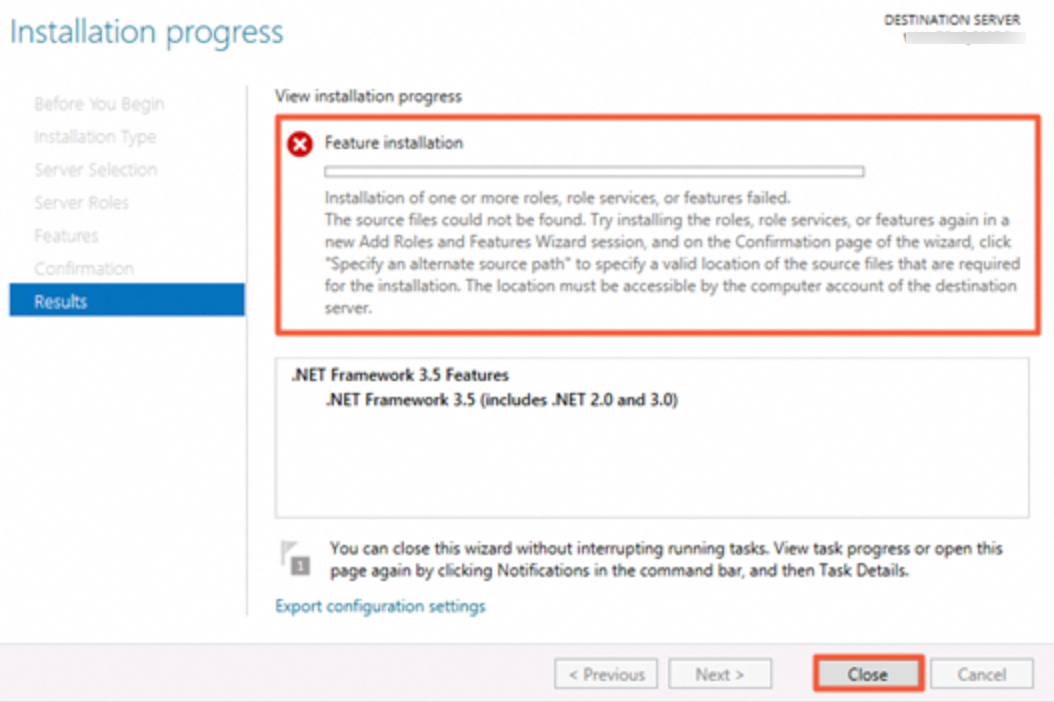
Windows Server 2025: Kegagalan instalasi .NET Framework 3.5
-
Gejala: Instalasi .NET Framework 3.5 gagal pada Windows Server 2025.
-
Solusi: Windows Server 2025 menggunakan sumber pembaruan WSUS Alibaba Cloud, yang tidak mendukung pembaruan fitur untuk versi OS ini. Lihat Bagaimana cara mengatasi masalah ketika .NET Framework 3.5 atau paket bahasa gagal diinstal pada instans yang menjalankan Windows Server 2012 R2 atau versi lebih baru?.
Windows menampilkan SSD sebagai HDD
Gejala:
Anda membeli instans Windows dan menyambungkan disk cloud SSD. Di Task Manager, SSD ditampilkan sebagai HDD.
Penyebab:
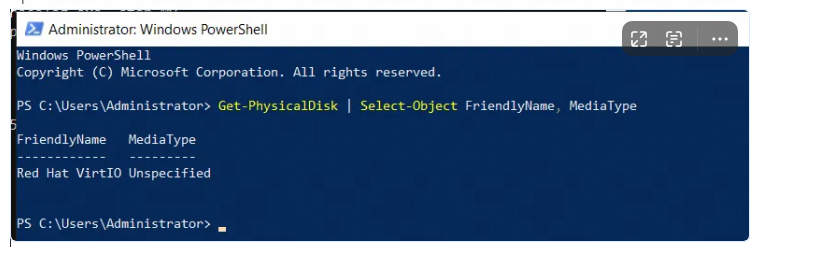
Windows menentukan tipe disk berdasarkan nilai MEDIUM ROTATION RATE dari perintah INQUIRY. Jika MEDIUM ROTATION RATE tidak dilaporkan, sistem akan menggunakan nilai default "Unspecified", yang ditampilkan sebagai HDD. Ini merupakan isu tampilan yang sudah diketahui.
Solusi:
Driver virtio-blk tidak dapat membedakan SSD dari HDD, sehingga OS menggunakan default HDD. Instans menggunakan disk cloud SSD — isu tampilan ini tidak memengaruhi performa.
Isu yang diketahui untuk Linux
Isu CentOS
CentOS 8.0: Masalah penamaan gambar publik
-
Gejala: Setelah Anda membuat instans CentOS menggunakan gambar publik centos_8_0_x64_20G_alibase_20200218.vhd, koneksi jarak jauh menampilkan versi sistem sebagai CentOS 8.1.
testuser@ecshost:~$ lsb_release -a LSB Version: :core-4.1-amd64:core-4.1-noarch Distributor ID: CentOS Description: CentOS Linux release 8.1.1911 (Core) Release: 8.1.1911 Codename: Core -
Penyebab: Gambar publik ini telah diperbarui dengan paket komunitas terbaru, yang meningkatkan versinya menjadi 8.1.
-
ID gambar yang terdampak: centos_8_0_x64_20G_alibase_20200218.vhd.
-
Resolusi: Jika Anda memerlukan CentOS 8.0, panggil operasi API RunInstances dan atur parameter ImageId ke
centos_8_0_x64_20G_alibase_20191225.vhd.
CentOS 7: Isu akibat perubahan ID gambar
-
Gejala: ID gambar dari beberapa gambar publik CentOS 7 telah berubah. Hal ini dapat memengaruhi proses O&M otomatis yang bergantung pada ID gambar tertentu.
-
Gambar yang Terdampak: CentOS 7.5 dan CentOS 7.6
-
Penyebab: Versi terbaru dari gambar publik CentOS 7.5 dan CentOS 7.6 menggunakan format ID gambar
%OS_Type%_%Major_Version%_%Minor_Version%_%Special_Field%_alibase_%Date%.%Format%. Sebagai contoh, awalan ID gambar untuk CentOS 7.5 diperbarui daricentos_7_05_64menjadicentos_7_5_x64. Anda perlu menyesuaikan kebijakan O&M otomatis Anda sesuai dengan perubahan ini. Untuk informasi lebih lanjut tentang ID gambar, lihat Catatan rilis untuk 2023.
CentOS 7: Perubahan kapitalisasi hostname setelah restart
-
Gejala: Pada beberapa instans CentOS 7, huruf kapital dalam hostname berubah menjadi huruf kecil setelah restart pertama.
Contoh hostname
Contoh setelah restart pertama
Tetap huruf kecil
iZm5e1qe*****sxx1ps5zX
izm5e1qe*****sxx1ps5zx
Ya
ZZHost
zzhost
Ya
NetworkNode
networknode
Ya
-
Gambar yang Terdampak: Gambar publik CentOS berikut dan gambar kustom yang dibuat darinya.
-
centos_7_2_64_40G_base_20170222.vhd
-
centos_7_3_64_40G_base_20170322.vhd
-
centos_7_03_64_40G_alibase_20170503.vhd
-
centos_7_03_64_40G_alibase_20170523.vhd
-
centos_7_03_64_40G_alibase_20170625.vhd
-
centos_7_03_64_40G_alibase_20170710.vhd
-
centos_7_02_64_20G_alibase_20170818.vhd
-
centos_7_03_64_20G_alibase_20170818.vhd
-
centos_7_04_64_20G_alibase_201701015.vhd
-
-
Jenis Hostname yang Terdampak: Jika aplikasi Anda peka terhadap kapitalisasi, layanan mungkin terganggu setelah restart.
Jenis hostname
Terkena dampak
Kapan terdampak
Tindakan yang diperlukan
Hostname berisi huruf kapital saat instans dibuat di Konsol atau menggunakan API.
Ya
Pada restart instans pertama
Ya
Hostname hanya berisi huruf kecil saat instans dibuat di Konsol atau menggunakan API.
Tidak
Tidak berlaku
Tidak
Hostname berisi huruf kapital, dan Anda mengubah hostname setelah login ke instans.
Tidak
Tidak berlaku
Ya
-
Resolusi: Untuk mempertahankan huruf kapital dalam hostname setelah restart:
-
Lakukan koneksi jarak jauh ke instans.
Lihat Pilih tool koneksi.
-
Lihat hostname saat ini.
[testuser@izbp193*****3i161uynzzx ~]# hostname izbp193*****3i161uynzzx -
Atur hostname statis.
hostnamectl set-hostname --static iZbp193*****3i161uynzzX -
Lihat hostname yang telah diperbarui.
[testuser@izbp193*****3i161uynzzx ~]# hostname iZbp193*****3i161uynzzX
-
-
Langkah Selanjutnya: Jika Anda menggunakan gambar kustom, perbarui cloud-init ke versi terbaru dan buat gambar kustom baru untuk mencegah isu ini pada instans mendatang. Lihat Instal cloud-init dan Buat gambar kustom dari instans.
CentOS 6.8: Crash client NFS
-
Gejala: Instans CentOS 6.8 dengan klien NFS yang dimuat mungkin hang, sehingga memerlukan restart.
-
Penyebab: Saat Anda menggunakan layanan NFS dengan versi kernel dari 2.6.32-696 hingga 2.6.32-696.10, nfsclient kernel secara proaktif memutus koneksi TCP jika terjadi gangguan latensi komunikasi. Jika server NFS merespons lambat, koneksi yang dimulai oleh nfsclient mungkin terjebak dalam status FIN_WAIT2. Biasanya, koneksi dalam status FIN_WAIT2 akan timeout dan diklaim ulang setelah satu menit, memungkinkan nfsclient memulai ulang koneksi. Namun, karena cacat dalam implementasi TCP pada versi kernel tersebut, koneksi dalam status FIN_WAIT2 tidak pernah timeout. Akibatnya, koneksi TCP nfsclient tidak pernah ditutup, yang memblokir koneksi baru dan menyebabkan permintaan pengguna hang tanpa batas.
-
ID gambar yang terdampak: centos_6_08_32_40G_alibase_20170710.vhd dan centos_6_08_64_20G_alibase_20170824.vhd.
-
Resolusi: Jalankan perintah yum update untuk meningkatkan kernel ke versi 2.6.32-696.11 atau yang lebih baru.
PentingSebelum melakukan perubahan, buat snapshot untuk backup data Anda.
Isu Ubuntu
Kernel Ubuntu 5.15: Hot-unplug disk memicu hung task
-
Gejala: Saat Anda melakukan hot-unplug disk pada instans yang menjalankan kernel Ubuntu versi 5.15.0-144-generic, Anda mungkin secara intermiten memicu hung task dengan timeout sekitar 120 detik. Proses yang umumnya terjebak meliputi:
-
kworker(thread hot-plug ACPI) -
udev-worker(proses penanganan event perangkat)
-
-
Penyebab: Isu ini disebabkan oleh kelemahan logis dalam fungsi kernel
del_gendisk().
Kondisi race antara pembekuan antrian dan pelepasan referensi sysfs menyebabkan deadlock ABBA:-
Proses
kworkermemegang lock freeze antrian dan menunggu referensi sysfs dilepaskan. -
Proses
udev-workermemegang referensi sysfs dan menunggu antrian dibuka atau keluar.
Karena kernel tidak mengatur flag
QUEUE_FLAG_DYING,blk_queue_enter()tidak dapat keluar, yang mengakibatkan deadlock. -
-
Resolusi:
-
Opsi 1: Tingkatkan kernel (Direkomendasikan)
Tingkatkan ke versi kernel yang mencakup perbaikan (versi 5.19 atau yang lebih baru, atau kernel distribusi yang mencakup patch tersebut).
-
Opsi 2: Terapkan patch (Perbaikan sementara)
Pada kernel 5.15, modifikasi fungsi
del_gendisk()dengan menggantiblk_queue_start_drain(q);denganblk_set_queue_dying(q);. Perubahan ini mengatur flagQUEUE_FLAG_DYING, yang memungkinkan permintaan I/O yang tertunda keluar dengan cepat dan mencegah deadlock.
-
Isu Fedora CoreOS
Fedora CoreOS: Hostname tidak diterapkan pada gambar kustom
-
Gejala: Saat Anda membuat instans ECS (Instance B) dari gambar kustom instans Fedora CoreOS lain (Instance A), Instance B mempertahankan hostname Instance A alih-alih menerapkan hostname baru.
Sebagai contoh, Anda memiliki instans ECS (
Instance A) yang menjalankan sistem operasi Fedora CoreOS dan memiliki hostnametest001. Anda kemudian menggunakan gambar kustom dari instans ini untuk membuat instans ECS baru (Instance B) dan mengatur hostnameInstance Bketest002selama proses pembuatan. Setelah Anda membuat dan melakukan koneksi jarak jauh keInstance B, hostnameInstance Btetaptest001. -
Penyebab: Gambar publik Fedora CoreOS yang disediakan oleh Alibaba Cloud menggunakan layanan Ignition resmi sistem operasi untuk inisialisasi instans. Ignition adalah utilitas yang digunakan oleh Fedora CoreOS dan Red Hat Enterprise Linux CoreOS untuk memanipulasi disk selama fase initramfs dari startup sistem. Saat instans ECS pertama kali dijalankan,
coreos-ignition-firstboot-complete.servicedalam Ignition menentukan apakah akan menginisialisasi instans dengan memeriksa keberadaan file /boot/ignition.firstboot (yang merupakan file kosong). Jika file tersebut ada, Ignition melanjutkan inisialisasi, yang mencakup konfigurasi hostname, lalu menghapus file /boot/ignition.firstboot.Karena instans Fedora CoreOS asli telah dijalankan setidaknya sekali, file /boot/ignition.firstboot dalam gambar kustom yang sesuai telah dihapus. Saat Anda menggunakan gambar kustom ini untuk membuat instans ECS baru, Ignition tidak menginisialisasi instans pada startup pertamanya, sehingga hostname baru tidak berlaku.
-
Resolusi:
CatatanUntuk memastikan keamanan data, buat snapshot sebelum operasi ini. Jika terjadi kesalahan data, Anda dapat memulihkan disk dari snapshot tersebut.
Sebelum membuat gambar kustom dari instans Fedora CoreOS, gunakan izin
rootuntuk membuat file /ignition.firstboot di direktori /boot:-
Remount /boot dalam mode read-write.
sudo mount /boot -o rw,remount -
Buat file /ignition.firstboot.
sudo touch /boot/ignition.firstboot -
Remount /boot dalam mode read-only.
sudo mount /boot -o ro,remount
-
Isu OpenSUSE
OpenSUSE 15: Hang startup setelah pembaruan kernel
-
Gejala: Setelah meningkatkan kernel OpenSUSE ke
4.12.14-lp151.28.52-default, sebuah instans mungkin hang saat startup pada tipe instans tertentu. Jenis CPU yang diketahui terdampak:Intel® Xeon® CPU E5-2682 v4 @ 2.50GHz. Jejak panggilan (call trace):[ 0.901281] CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033 [ 0.901281] CR2: ffffc90000d68000 CR3: 000000000200a001 CR4: 00000000003606e0 [ 0.901281] DR0: 0000000000000000 DR1: 0000000000000000 DR2: 0000000000000000 [ 0.901281] DR3: 0000000000000000 DR6: 00000000fffe0ff0 DR7: 0000000000000400 [ 0.901281] Call Trace: [ 0.901281] cpuidle_enter_state+0x6f/0x2e0 [ 0.901281] do_idle+0x183/0x1e0 [ 0.901281] cpu_startup_entry+0x5d/0x60 [ 0.901281] start_secondary+0x1b0/0x200 [ 0.901281] secondary_startup_64+0xa5/0xb0 [ 0.901281] Code: 6c 01 00 0f ae 38 0f ae f0 0f 1f 84 00 00 00 00 00 0f 1f 84 00 00 00 00 00 90 31 d2 65 48 8b 34 25 40 6c 01 00 48 89 d1 48 89 f0 <0f> 01 c8 0f 1f 84 00 00 00 00 00 0f 1f 84 00 00 00 00 00 ** ** -
Penyebab: Versi kernel baru tidak kompatibel dengan Microcode CPU. Lihat Isu hang startup.
-
Gambar yang Terdampak: opensuse_15_1_x64_20G_alibase_20200520.vhd.
-
Resolusi: Di /boot/grub2/grub.cfg, tambahkan parameter kernel
idle=nomwaitpada baris yang dimulai denganlinux. Contoh:menuentry 'openSUSE Leap 15.1' --class opensuse --class gnu-linux --class gnu --class os $menuentry_id_option 'gnulinux-simple-20f5f35a-fbab-4c9c-8532-bb6c66ce****' { load_video set gfxpayload=keep insmod gzio insmod part_msdos insmod ext2 set root='hd0,msdos1' if [ x$feature_platform_search_hint = xy ]; then search --no-floppy --fs-uuid --set=root --hint='hd0,msdos1' 20f5f35a-fbab-4c9c-8532-bb6c66ce**** else search --no-floppy --fs-uuid --set=root 20f5f35a-fbab-4c9c-8532-bb6c66ce**** fi echo 'Loading Linux 4.12.14-lp151.28.52-default ...' linux /boot/vmlinuz-4.12.14-lp151.28.52-default root=UUID=20f5f35a-fbab-4c9c-8532-bb6c66ce**** net.ifnames=0 console=tty0 console=ttyS0,115200n8 splash=silent mitigations=auto quiet idle=nomwait echo 'Loading initial ramdisk ...' initrd /boot/initrd-4.12.14-lp151.28.52-default }
Red Hat Enterprise Linux issues
Red Hat Enterprise Linux 8: Kegagalan pembaruan kernel dengan yum
-
Gejala: Pada instans Red Hat Enterprise Linux 8 64-bit, setelah menjalankan yum update untuk memperbarui kernel dan melakukan restart, kernel tetap pada versi lama.
-
Penyebab: Pada RHEL 8 64-bit, ukuran file /boot/grub2/grubenv bukan 1.024 byte standar, sehingga menyebabkan pembaruan versi kernel gagal.
-
Resolusi: Setelah memperbarui kernel, atur versi baru sebagai versi startup default:
-
Perbarui versi kernel.
yum update kernel -y -
Dapatkan parameter startup kernel dari sistem operasi saat ini.
grub2-editenv list | grep kernelopts -
Backup file /grubenv lama.
mv /boot/grub2/grubenv /home/grubenv.bak -
Buat file /grubenv baru.
grub2-editenv /boot/grub2/grubenv create -
Atur versi kernel baru sebagai versi startup default.
Dalam contoh ini, versi kernel yang diperbarui adalah
/boot/vmlinuz-4.18.0-305.19.1.el8_4.x86_64.grubby --set-default /boot/vmlinuz-4.18.0-305.19.1.el8_4.x86_64 -
Atur parameter startup kernel.
Atur nilai
kerneloptske parameter startup yang diperoleh pada langkah 2.grub2-editenv - set kernelopts="root=UUID=0dd6268d-9bde-40e1-b010-0d3574b4**** ro crashkernel=auto net.ifnames=0 vga=792 console=tty0 console=ttyS0,115200n8 noibrs nosmt" -
Restart instans ECS dengan versi kernel baru.
rebootPeringatanOperasi restart menghentikan instans untuk periode waktu singkat dan dapat mengganggu layanan yang sedang berjalan di instans tersebut. Kami merekomendasikan agar Anda melakukan restart instans selama jam sepi.
-
Isu SUSE Linux Enterprise Server
SUSE Linux Enterprise Server: Kegagalan koneksi ke server SMT
-
Gejala: Saat Anda menggunakan gambar berbayar SUSE Linux Enterprise Server atau SUSE Linux Enterprise Server for SAP, Anda mungkin mengalami timeout koneksi dengan server Subscription Management Tool (SMT). Pesan error yang mirip dengan salah satu berikut dikembalikan:
-
Registration server returned 'This server could not verify that you are authorized to access this service.' (500)
-
Problem retrieving the repository index file for service 'SMT-http_mirrors_cloud_aliyuncs_com' location ****
-
-
Gambar yang Terdampak: SUSE Linux Enterprise Server dan SUSE Linux Enterprise Server for SAP
-
Resolusi: Daftar ulang dan aktifkan layanan SMT.
-
Daftar ulang dan aktifkan layanan SMT.
SUSEConnect -d SUSEConnect --cleanup systemctl restart guestregister -
Verifikasi status aktivasi layanan SMT.
SUSEConnect -sOutput yang mirip dengan berikut menunjukkan layanan SMT aktif.
[{"identifier":"SLES_SAP","version":"12.5","arch":"x86_64","status":"Registered"}]
-
SUSE 12 SP5: Hang startup setelah pembaruan kernel
-
Gejala: Setelah meningkatkan kernel yang lebih lama dari SLES 12 SP5 ke SLES 12 SP5, atau setelah memperbarui kernel internal SLES 12 SP5, sebuah instans mungkin hang saat startup pada tipe instans tertentu. Jenis CPU yang diketahui terdampak:
Intel® Xeon® CPU E5-2682 v4 @ 2.50GHzdanIntel® Xeon® CPU E7-8880 v4 @ 2.20GHz. Jejak panggilan (call trace):[ 0.901281] CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033 [ 0.901281] CR2: ffffc90000d68000 CR3: 000000000200a001 CR4: 00000000003606e0 [ 0.901281] DR0: 0000000000000000 DR1: 0000000000000000 DR2: 0000000000000000 [ 0.901281] DR3: 0000000000000000 DR6: 00000000fffe0ff0 DR7: 0000000000000400 [ 0.901281] Call Trace: [ 0.901281] cpuidle_enter_state+0x6f/0x2e0 [ 0.901281] do_idle+0x183/0x1e0 [ 0.901281] cpu_startup_entry+0x5d/0x60 [ 0.901281] start_secondary+0x1b0/0x200 [ 0.901281] secondary_startup_64+0xa5/0xb0 [ 0.901281] Code: 6c 01 00 0f ae 38 0f ae f0 0f 1f 84 00 00 00 00 00 0f 1f 84 00 00 00 00 00 90 31 d2 65 48 8b 34 25 40 6c 01 00 48 89 d1 48 89 f0 <0f> 01 c8 0f 1f 84 00 00 00 00 00 0f 1f 84 00 00 00 00 00 ** ** -
Penyebab: Versi kernel baru tidak kompatibel dengan Microcode CPU.
-
Resolusi: Di
/boot/grub2/grub.cfg, tambahkan parameter kernelidle=nomwaitpada baris yang dimulai denganlinux. Contoh:menuentry 'SLES 12-SP5' --class sles --class gnu-linux --class gnu --class os $menuentry_id_option 'gnulinux-simple-fd7bda55-42d3-4fe9-a2b0-45efdced****' { load_video set gfxpayload=keep insmod gzio insmod part_msdos insmod ext2 set root='hd0,msdos1' if [ x$feature_platform_search_hint = xy ]; then search --no-floppy --fs-uuid --set=root --hint='hd0,msdos1' fd7bda55-42d3-4fe9-a2b0-45efdced**** else search --no-floppy --fs-uuid --set=root fd7bda55-42d3-4fe9-a2b0-45efdced**** fi echo 'Loading Linux 4.12.14-122.26-default ...' linux /boot/vmlinuz-4.12.14-122.26-default root=UUID=fd7bda55-42d3-4fe9-a2b0-45efdced**** net.ifnames=0 console=tty0 console=ttyS0,115200n8 mitigations=auto splash=silent quiet showopts idle=nomwait echo 'Loading initial ramdisk ...' initrd /boot/initrd-4.12.14-122.26-default }
Isu AnolisOS
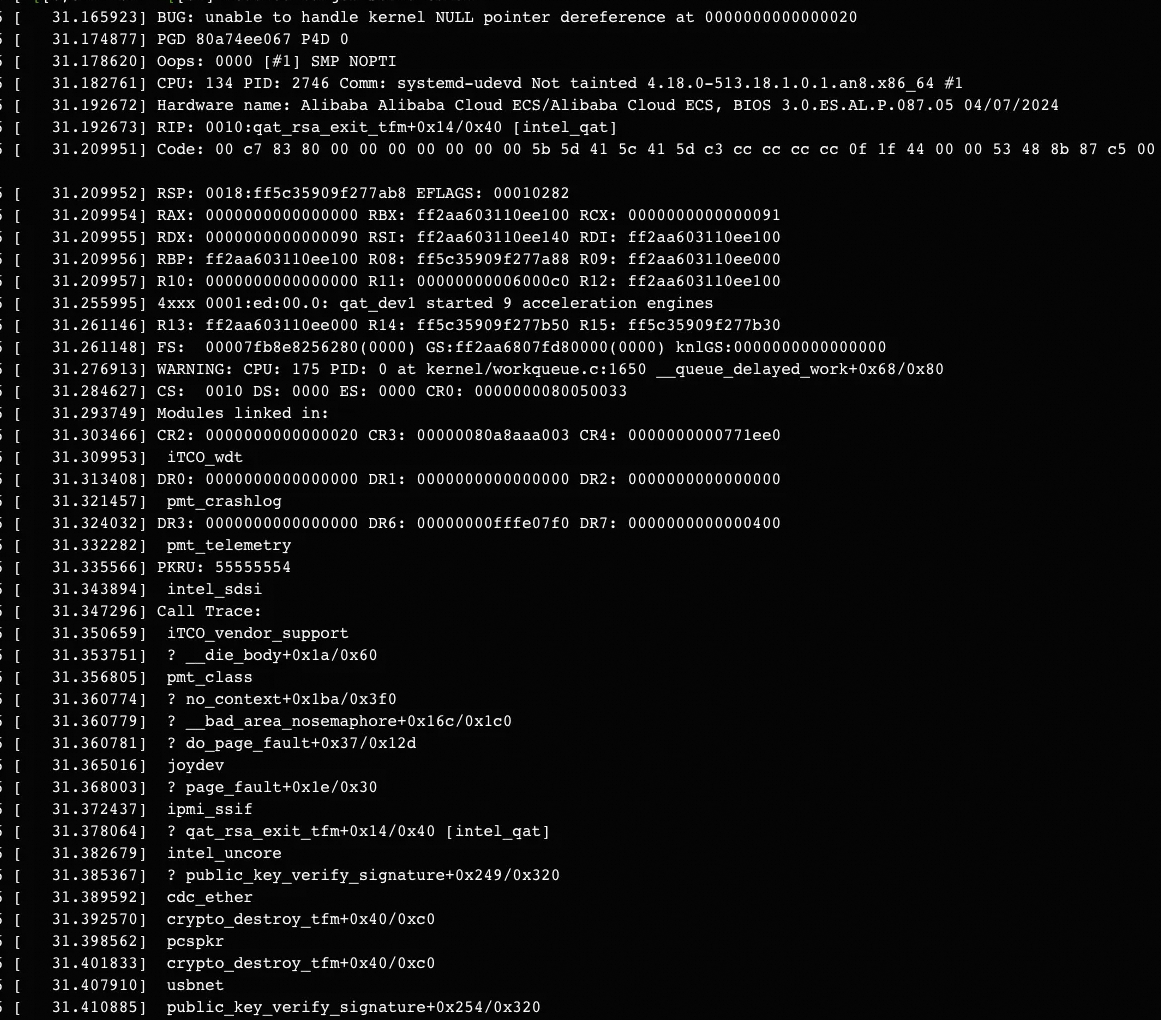
AnolisOS 8.9 RHCK: Kegagalan startup pada ebmc8i dan ebmg8i
Karena isu kompatibilitas antara AnolisOS 8.9 RHCK dan Intel QAT, sistem crash selama startup. Gunakan AnolisOS 8.10 RHCK sebagai gantinya pada tipe instans ini.
Isu lainnya
Call trace startup pada kernel yang lebih baru
-
Gejala: Call trace mungkin terjadi saat Anda menjalankan instans tipe tertentu, seperti ecs.i2.4xlarge, yang menjalankan sistem dengan kernel terbaru, seperti RHEL 8.3 atau CentOS 8.3 dengan kernel
4.18.0-240.1.1.el8_3.x86_64. Contoh call trace:Dec 28 17:43:45 localhost SELinux: Initializing. Dec 28 17:43:45 localhost kernel: Dentry cache hash table entries: 8388608 (order: 14, 67108864 bytes) Dec 28 17:43:45 localhost kernel: Inode-cache hash table entries: 4194304 (order: 13, 33554432 bytes) Dec 28 17:43:45 localhost kernel: Mount-cache hash table entries: 131072 (order: 8, 1048576 bytes) Dec 28 17:43:45 localhost kernel: Mountpoint-cache hash table entries: 131072 (order: 8, 1048576 bytes) Dec 28 17:43:45 localhost kernel: unchecked MSR access error: WRMSR to 0x3a (tried to write 0x000000000000****) at rIP: 0xffffffff8f26**** (native_write_msr+0x4/0x20) Dec 28 17:43:45 localhost kernel: Call Trace: Dec 28 17:43:45 localhost kernel: init_ia32_feat_ctl+0x73/0x28b Dec 28 17:43:45 localhost kernel: init_intel+0xdf/0x400 Dec 28 17:43:45 localhost kernel: identify_cpu+0x1f1/0x510 Dec 28 17:43:45 localhost kernel: identify_boot_cpu+0xc/0x77 Dec 28 17:43:45 localhost kernel: check_bugs+0x28/0xa9a Dec 28 17:43:45 localhost kernel: ? __slab_alloc+0x29/0x30 Dec 28 17:43:45 localhost kernel: ? kmem_cache_alloc+0x1aa/0x1b0 Dec 28 17:43:45 localhost kernel: start_kernel+0x4fa/0x53e Dec 28 17:43:45 localhost kernel: secondary_startup_64+0xb7/0xc0 Dec 28 17:43:45 localhost kernel: Last level iTLB entries: 4KB 64, 2MB 8, 4MB 8 Dec 28 17:43:45 localhost kernel: Last level dTLB entries: 4KB 64, 2MB 0, 4MB 0, 1GB 4 Dec 28 17:43:45 localhost kernel: FEATURE SPEC_CTRL Present Dec 28 17:43:45 localhost kernel: FEATURE IBPB_SUPPORT Present -
Penyebab: Pembaruan kernel komunitas mencakup patch yang menulis ke Model-Specific Registers (MSR). Beberapa tipe instans, seperti ecs.i2.4xlarge, tidak mendukung penulisan MSR karena versi virtualisasinya, sehingga menyebabkan call trace.
-
Resolusi: Call trace ini tidak memengaruhi operasi atau stabilitas sistem. Abaikan error ini.
Instans hfg6: Ketidakcocokan kernel menyebabkan panic
-
Gejala: Untuk beberapa distribusi Linux, seperti CentOS 8, SUSE Linux Enterprise Server 15 SP2, dan OpenSUSE 15.2, peningkatan kernel pada instans hfg6 dapat menyebabkan kernel panic.
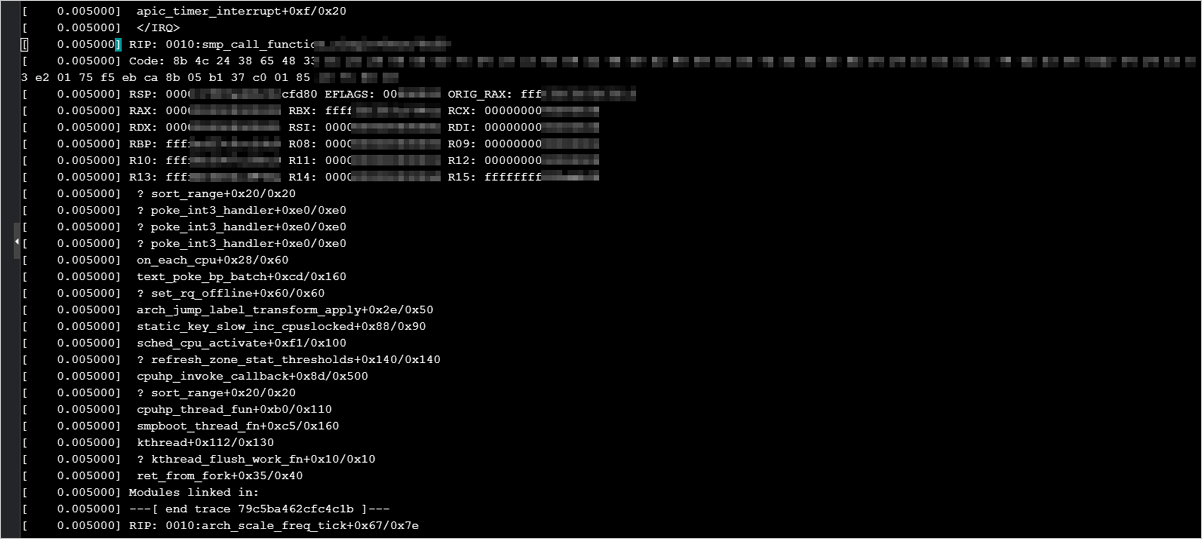
-
Penyebab: Terdapat isu kompatibilitas antara keluarga instans hfg6 dan beberapa versi kernel Linux.
-
Resolusi:
-
Kernel terbaru untuk SUSE Linux Enterprise Server 15 SP2 dan OpenSUSE 15.2 memperbaiki isu ini. Jika kernel Anda mencakup commit berikut, maka kernel tersebut kompatibel dengan keluarga instans hfg6.
commit 1e33d5975b49472e286bd7002ad0f689af33fab8 Author: Giovanni Gherdovich <ggherdovich@suse.cz> Date: Thu Sep 24 16:51:09 2020 +0200 x86, sched: Bail out of frequency invariance if turbo_freq/base_freq gives 0 (bsc#1176925). suse-commit: a66109f44265ff3f3278fb34646152bc2b3224a5 commit dafb858aa4c0e6b0ce6a7ebec5e206f4b3cfc11c Author: Giovanni Gherdovich <ggherdovich@suse.cz> Date: Thu Sep 24 16:16:50 2020 +0200 x86, sched: Bail out of frequency invariance if turbo frequency is unknown (bsc#1176925). suse-commit: 53cd83ab2b10e7a524cb5a287cd61f38ce06aab7 commit 22d60a7b159c7851c33c45ada126be8139d68b87 Author: Giovanni Gherdovich <ggherdovich@suse.cz> Date: Thu Sep 24 16:10:30 2020 +0200 x86, sched: check for counters overflow in frequency invariant accounting (bsc#1176925). -
Jika Anda meningkatkan sistem CentOS 8 ke kernel
kernel-4.18.0-240atau yang lebih baru pada instans hfg6, kernel panic mungkin terjadi. Jika hal ini terjadi, kembalikan ke versi kernel sebelumnya.
-
Timeout permintaan pip
-
Gejala: Permintaan pip kadang-kadang mengalami timeout atau gagal.
-
Gambar yang Terdampak: CentOS, Debian, Ubuntu, SUSE, OpenSUSE, dan Alibaba Cloud Linux.
-
Penyebab: Alibaba Cloud menyediakan tiga titik akhir sumber pip. Default-nya adalah mirrors.aliyun.com, yang memerlukan akses internet publik. Jika instans Anda tidak memiliki alamat IP publik, permintaan pip mungkin mengalami timeout.
-
(Default) Publik: mirrors.aliyun.com
-
Jaringan internal VPC: mirrors.cloud.aliyuncs.com
-
-
Resolusi: Gunakan salah satu metode berikut.
-
Metode 1
Asosiasikan EIP dengan instans Anda untuk memberikan alamat IP publik.
Untuk instans subscription, Anda juga dapat menetapkan ulang alamat IP publik saat Anda melakukan peningkatan atau penurunan tipe instans.
-
Metode 2
Jika respons pip tertunda, jalankan skrip fix_pypi.sh pada instans ECS dan coba lagi.
-
Lakukan koneksi jarak jauh ke instans.
-
Unduh file skrip.
wget http://image-offline.oss-cn-hangzhou.aliyuncs.com/fix/fix_pypi.sh -
Jalankan skrip.
Instans VPC: Jalankan perintah
bash fix_pypi.sh "mirrors.cloud.aliyuncs.com". -
Coba lagi operasi pip.
Isi skrip fix_pypi.sh:
#!/bin/bash function config_pip() { pypi_source=$1 if [[ ! -f ~/.pydistutils.cfg ]]; then cat > ~/.pydistutils.cfg << EOF [easy_install] index-url=http://$pypi_source/pypi/simple/ EOF else sed -i "s#index-url.*#index-url=http://$pypi_source/pypi/simple/#" ~/.pydistutils.cfg fi if [[ ! -f ~/.pip/pip.conf ]]; then mkdir -p ~/.pip cat > ~/.pip/pip.conf << EOF [global] index-url=http://$pypi_source/pypi/simple/ [install] trusted-host=$pypi_source EOF else sed -i "s#index-url.*#index-url=http://$pypi_source/pypi/simple/#" ~/.pip/pip.conf sed -i "s#trusted-host.*#trusted-host=$pypi_source#" ~/.pip/pip.conf fi } config_pip $1 -
-