Saat menggunakan instance Elastic Compute Service (ECS), Anda mungkin mengalami masalah terkait citra seperti startup lambat, beban sistem tinggi, atau memiliki pertanyaan seputar pengelolaan kernel. Halaman ini menjawab beberapa pertanyaan umum (FAQ) tentang citra yang sering muncul saat menggunakan instance ECS.
FAQ tentang citra Windows
Bagaimana cara memperbarui driver virtio pada instance Windows?
Bagaimana cara mengelola citra dan instance Windows Server Semi-Annual Channel?
Apa yang harus saya lakukan jika saya tidak dapat mengubah resolusi layar instance Windows yang menjalankan citra UEFI setelah saya terhubung ke instance menggunakan VNC?
Apa yang harus saya lakukan jika saya diberi tahu bahwa sistem operasi Windows Server instance saya tidak asli?
Anda perlu mengaktifkan sistem operasi. Untuk informasi lebih lanjut, lihat Bagaimana cara menggunakan nama domain KMS untuk mengaktifkan instance Windows dalam VPC?.
Apa yang harus saya lakukan jika terjadi kesalahan waktu sistem karena panggilan timeBeginPeriod yang sering di Windows?
Pada Windows Server 2008, panggilan timeBeginPeriod yang berulang dapat menyebabkan ketidakakuratan waktu sistem. Berikut adalah langkah-langkah untuk menyelesaikan masalah tersebut:
CatatanUntuk informasi lebih lanjut tentang fungsi sistem yang memengaruhi akurasi waktu, lihat Fungsi Tunggu.
Hubungkan ke instance.
Untuk detail lebih lanjut, lihat Hubungkan ke instance Windows menggunakan kata sandi atau kunci.
Unduh CheckTimeBeginPeriod.zip.
Ekstrak CheckTimeBeginPeriod.zip.
Ekstrak bin.zip, buka folder bin, lalu klik dua kali file .exe.
Untuk sistem operasi 64-bit, klik dua kali InjectDllx64.exe.
Untuk sistem operasi 32-bit, klik dua kali InjectDllx86.exe.
Proses yang memanggil fungsi timeBeginPeriod akan ditampilkan.
Hentikan atau perbarui proses yang memanggil fungsi timeBeginPeriod sesuai kebutuhan bisnis Anda.
Jika masalah tetap ada, ajukan tiket untuk menghubungi dukungan teknis Alibaba Cloud.
Apa yang harus saya lakukan jika pesan kesalahan "Konten dari situs web yang tercantum di bawah ini diblokir oleh Konfigurasi Keamanan Internet Explorer yang Ditingkatkan" muncul?
Saat mencoba membuka situs web di Internet Explorer pada instance ECS Windows atau server aplikasi sederhana Windows, pesan kesalahan berikut muncul: Konten dari situs web yang tercantum di bawah ini diblokir oleh Konfigurasi Keamanan Internet Explorer yang Ditingkatkan. Untuk informasi tentang cara menyelesaikan masalah ini, lihat Apa yang harus saya lakukan jika mendapat pesan kesalahan "Konten dari situs web yang tercantum di bawah ini diblokir oleh Konfigurasi Keamanan Internet Explorer yang Ditingkatkan"?.
Ketika saya mengganti disk sistem instance ECS Windows atau menginisialisasi ulang disk sistem, mengapa data pengguna tidak dieksekusi secara otomatis?
Penyebab
Setelah instance ECS Windows dimulai, file cache dibuat di direktori
C:\ProgramData\aliyun\vminit\INSTANCE_<Instance ID>\METASERVER. File cache digunakan untuk menandai apakah instance telah diinisialisasi. Jika Anda membuat citra kustom dari instance dan menggunakan citra tersebut untuk menginisialisasi ulang atau mengganti disk sistem instance, file cache dengan ID yang sama dengan ID instance disimpan di direktoriC:\ProgramData\aliyun\vminit\INSTANCE_<Instance ID>\METASERVER. Komponen Vminit menentukan apakah ini pertama kalinya instance ECS dimulai berdasarkan keberadaan file cache. Jika file cache dengan ID yang sama dengan ID instance ada, komponen Vminit menentukan bahwa ini bukan pertama kalinya instance ECS dimulai, sehingga skrip dalam data pengguna tidak dieksekusi secara otomatis.CatatanKomponen Vminit diinstal secara otomatis saat membuat instance Windows. Mirip dengan layanan cloud-init Linux, komponen Vminit menginisialisasi konfigurasi instance Windows selama fase boot. Untuk informasi lebih lanjut tentang komponen Vminit, lihat Komponen Vminit.
Solusi
Sebelum membuat citra kustom dari instance ECS, kami sarankan Anda memeriksa dan menghapus file cache di direktori
C:\ProgramData\aliyun\vminit\INSTANCE_<Instance ID>\METASERVER.
FAQ tentang citra CentOS dan Red Hat
Bagaimana cara menyelesaikan masalah timeout resolusi DNS CentOS?
Penyebab
Mekanisme resolusi DNS CentOS 6 dan CentOS 7 telah berubah. Kesalahan timeout resolusi DNS dapat terjadi pada instance CentOS 6 atau CentOS 7 yang dibuat sebelum 22 Februari 2017 atau yang menggunakan citra kustom yang dibuat sebelum tanggal tersebut.
Solusi
Untuk menyelesaikan masalah ini, ikuti langkah-langkah berikut:
Unduh skrip fix_dns.sh.
Letakkan skrip yang diunduh di direktori /tmp sistem operasi CentOS.
Jalankan perintah bash /tmp/fix_dns.sh untuk mengeksekusi skrip.
Catat hal-hal berikut yang berkaitan dengan skrip:
Skrip menentukan apakah sistem operasi instance adalah CentOS.
Jika sistem operasi bukan CentOS, seperti ketika sistem operasi adalah Ubuntu atau Debian, skrip berhenti berjalan.
Jika sistem operasi adalah CentOS, skrip terus berjalan.
Skrip memeriksa file /etc/resolv.conf untuk konfigurasi
options.Jika konfigurasi
optionstidak tersedia, skrip melakukan operasi berikut:Gunakan konfigurasi
optionsAlibaba Cloud (options timeout:2 attempts:3 rotate single-request-reopen).
Jika konfigurasi
optionstersedia, skrip memeriksa apakah opsi single-request-reopen ada.Jika opsi
single-request-reopentidak ada, skrip menambahkan opsi ini ke konfigurasioptions.Jika opsi
single-request-reopenada, skrip berhenti berjalan dan tidak mengubah konfigurasi nameserver DNS.
Setelah saya menggunakan instance CentOS 7 atau Windows untuk waktu yang lama tanpa me-restart instance, instance terputus dari jaringan, jaringan tidak tersedia, atau alamat IP publik atau pribadi instance tidak dapat diping. Apa yang harus saya lakukan?
Untuk informasi tentang penyebab dan solusi masalah ini, lihat Periksa dan perbaiki masalah hilangnya alamat IP instance CentOS 7 dan instance Windows.
Apa yang harus saya lakukan jika sistem operasi CentOS 7.9 for Arm gagal menghasilkan file dump?
Deskripsi Masalah
Ketika sistem operasi CentOS 7.9 for Arm down dan Anda menjalankan perintah
ls /var/crashuntuk menanyakan file dump, tidak ada filevmcoreyang dihasilkan.
Penyebab
Sistem operasi CentOS 7.9 for Arm memiliki kernel di mana opsi
CONFIG_ARM64_USER_VA_BITS_52diatur ke y untuk mengaktifkan pengalamatan virtual 52-bit untuk userspace. Versi perangkat lunak makedumpfile yang datang dengan sistem operasi tidak cocok dengan versi kernel. Akibatnya, file dump tidak dapat dihasilkan.Solusi
PentingSolusi ini hanya berlaku untuk sistem operasi yang memiliki layanan kdump diaktifkan. Jika layanan kdump dinonaktifkan dan Anda menyelesaikan masalah sebelumnya seperti yang dijelaskan dalam topik ini, konfigurasikan parameter
crashkerneldalam fileproc/cmdline.Jalankan perintah berikut untuk mengunduh paket kexec-tools:
wget http://mirrors.aliyun.com/centos-vault/7.9.2009/os/Source/SPackages/kexec-tools-2.0.15-51.el7.src.rpmJalankan perintah berikut untuk menginstal paket Manajer Paket RPM (RPM):
rpm -ivh kexec-tools-2.0.15-51.el7.src.rpmJalankan perintah berikut untuk mengunduh file patch:
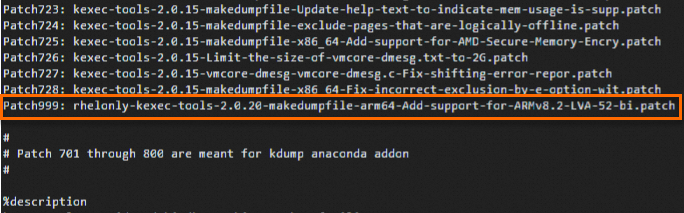
cd /root/rpmbuild/SOURCES wget https://ecs-image-tools.oss-cn-hangzhou.aliyuncs.com/patch/rhelonly-kexec-tools-2.0.20-makedumpfile-arm64-Add-support-for-ARMv8.2-LVA-52-bi.patchModifikasi file kexec-tools.spec.
Jalankan perintah berikut untuk membuka file kexec-tools.spec:
cd /root/rpmbuild/SPECS/ vi kexec-tools.specTekan tombol
Iuntuk masuk ke mode Sisip dan tambahkan baris berikut ke posisi yang sesuai dalam file:Patch999: rhelonly-kexec-tools-2.0.20-makedumpfile-arm64-Add-support-for-ARMv8.2-LVA-52-bi.patch %patch999 -p1Tambahkan baris seperti yang ditunjukkan pada gambar berikut.
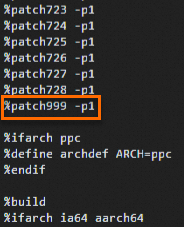
Tekan tombol
Escuntuk keluar dari mode Sisip dan masukkan:wquntuk menyimpan dan menutup file.
Jalankan perintah berikut untuk memeriksa dependensi instalasi:
yum-builddep kexec-tools.specJalankan perintah berikut untuk membangun paket RPM:
yum -y install rpm-build rpmbuild -ba kexec-tools.specJalankan perintah berikut untuk menginstal paket RPM yang dimodifikasi:
cd /root/rpmbuild/RPMS/aarch64 rpm -ivh kexec-tools-2.0.15-51.el7.aarch64.rpm
Jika downtime terjadi lagi, Anda dapat menanyakan file dump dengan menjalankan perintah
ls -lh /var/crash. Jika Anda menemukan bahwa filevmcoredihasilkan, ini menunjukkan bahwa masalah telah diselesaikan.
Bagaimana cara mengonversi CentOS 7 ke RHEL 7?
CentOS 7 akan mencapai akhir masa pakai (EOL) pada 30 Juni 2024. Alibaba Cloud tidak akan lagi menyediakan dukungan untuk sistem operasi mulai tanggal tersebut. Untuk mencegah dampak dari CentOS 7 EOL, Anda dapat mengonversi CentOS 7 ke RHEL 7. Bagian berikut menjelaskan cara mengonversi CentOS 7 ke RHEL 7 di Alibaba Cloud. Untuk informasi lebih lanjut, lihat Mengonversi dari distribusi Linux berbasis RPM ke RHEL.
PentingUntuk mencegah kehilangan data atau pengecualian yang disebabkan oleh operasi yang tidak disengaja, kami sarankan Anda menghentikan aplikasi penting, layanan basis data, dan layanan penyimpanan data serta buat snapshot disk untuk mencadangkan data penting sebelum konversi.
(Secara kondisional diperlukan) Jika Anda menggunakan instance ECS dan menginstal Server Guard pada instance tersebut, uninstall Server Guard terlebih dahulu.
Untuk informasi lebih lanjut, lihat Uninstall agen Security Center.
CatatanServer Guard adalah alat penguatan keamanan default untuk CentOS. RHEL 7 menggunakan alat penguatan keamanan yang disediakan oleh Red Hat. Server Guard mungkin tidak kompatibel dan bertentangan dengan alat di RHEL 7. Uninstall Server Guard selama proses konversi untuk memastikan stabilitas dan kompatibilitas sistem.
Jalankan perintah berikut untuk meningkatkan paket perangkat lunak sistem ke versi terbaru:
sudo wget -O /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-7.repo sudo wget -O /etc/yum.repos.d/epel.repo https://mirrors.aliyun.com/repo/epel-7.repoJalankan perintah berikut untuk memperbarui paket perangkat lunak sistem dan me-restart sistem:
sudo yum -y update sudo rebootJalankan perintah berikut untuk mengunduh alat convert2rhel dari situs resmi Red Hat dan menginstal alat tersebut:
sudo curl -o /etc/pki/rpm-gpg/RPM-GPG-KEY-redhat-release https://www.redhat.com/security/data/fd431d51.txt sudo curl --create-dirs -o /etc/rhsm/ca/redhat-uep.pem https://ftp.redhat.com/redhat/convert2rhel/redhat-uep.pem sudo curl -o /etc/yum.repos.d/convert2rhel.repo https://ftp.redhat.com/redhat/convert2rhel/7/convert2rhel.repo sudo yum -y install convert2rhelBeli langganan RHEL di Alibaba Cloud dan dapatkan alamat repositori RPM RHEL 7.
Untuk informasi lebih lanjut, ajukan tiket.
Jalankan perintah berikut untuk menginstal repositori RPM RHEL 7:
sudo rpm -ivh --replacefiles <Alamat repositori RPM> sudo sed -i 's/enabled=1/enabled=0/g' /etc/yum.repos.d/rh-cloud.repoGanti
<Alamat repositori RPM>dengan alamat repositori RPM RHEL 7 yang sebenarnya. Anda bisa mendapatkan alamat tersebut saat Anda membeli langganan RHEL.Jalankan perintah berikut untuk mengonversi CentOS 7 ke RHEL 7:
sudo convert2rhel -y --no-rhsm --enablerepo rhui-rhel-7-server-rhui-rpms --enablerepo rhui-rhel-7-server-rhui-extras-rpms --enablerepo rhui-rhel-7-server-rhui-optional-rpmsProses konversi membutuhkan waktu. Keluaran perintah berikut menunjukkan bahwa konversi selesai.

Jalankan perintah berikut untuk me-restart sistem:
Setelah konversi selesai, pesan ditampilkan untuk meminta Anda me-restart sistem. Restart sistem untuk mem-boot kernel RHEL baru. Kemudian, periksa apakah konversi sistem operasi berhasil.
sudo rebootCatatanSetelah Anda mengonversi CentOS 7 ke RHEL 7, jika Anda ingin meningkatkan RHEL 7 ke RHEL 8, lihat Bagaimana cara meningkatkan Red Hat Enterprise Linux (RHEL) 7 ke RHEL 8?
Red Hat 8.1 dan Red Hat 8.2 citra memulai lambat pada instance bare metal ECS. Apa yang harus saya lakukan?
Saat citra Red Hat 8.1 atau Red Hat 8.2 digunakan pada instance bare metal ECS, citra tersebut membutuhkan waktu hingga 2 menit lebih lama untuk memulai dibandingkan dengan citra Red Hat 7. Untuk menyelesaikan masalah ini, Anda dapat mengubah pengaturan parameter startup kernel dari console=ttyS0 console=ttyS0,115200n8 menjadi
console=tty0 console=ttyS0,115200n8di file/boot/grub2/grubenvdari citra Red Hat 8.1 atau Red Hat 8.2, dan restart instance agar perubahan berlaku.
FAQ tentang citra Ubuntu
Setelah proses Server Guard (AliYunDun) dimulai pada instance ECS yang menjalankan sistem operasi Ubuntu versi tertentu, beban rata-rata instance meningkat. Mengapa?
Setelah proses Server Guard dimulai pada instance ECS yang menjalankan sistem operasi Ubuntu versi tertentu, seperti Ubuntu 18.04, beban rata-rata instance meningkat.
FAQ tentang citra FreeBSD
Bagaimana cara menginstal patch dan mengompilasi kernel pada FreeBSD?
Kernels dalam citra publik FreeBSD Alibaba Cloud sudah diperbaiki untuk memenuhi persyaratan startup untuk keluarga instance seri-V atau yang lebih baru. Anda dapat memanggil operasi DescribeInstanceTypeFamilies dengan parameter
Generationyang ditentukan untuk menanyakan keluarga instance.Dalam skenario berikut, Anda dapat menggunakan kode sumber kernel FreeBSD untuk menginstal patch dan mengompilasi kernel untuk menyelesaikan dan mencegah masalah bahwa instance tidak dapat memulai:
Jika Anda menggunakan citra FreeBSD yang tidak disediakan oleh Alibaba Cloud atau citra kustom yang berasal dari citra FreeBSD yang tidak disediakan oleh Alibaba Cloud untuk membuat instance dari keluarga instance seri-V atau yang lebih baru, instance mungkin tidak dapat memulai.
Jika Anda menggunakan citra publik FreeBSD untuk membuat instance dari keluarga instance seri-V atau yang lebih baru dan menggunakan freebsd-update untuk memperbarui kernel dengan patch baru, instance mungkin tidak dapat memulai.
Anda tidak perlu menginstal patch untuk FreeBSD 13 atau yang lebih baru. Dalam contoh ini, FreeBSD 12.3 digunakan untuk menjelaskan cara menggunakan kode sumber kernel FreeBSD untuk menginstal patch kernel dan mengompilasi kernel.
Unduh dan ekstrak paket kode sumber kernel FreeBSD.
wget https://mirrors.aliyun.com/freebsd/releases/amd64/12.3-RELEASE/src.txz -O /src.txz cd / tar -zxvf /src.txzUnduh patch.
Dalam contoh ini, patch
0001-virtio.patchdiunduh.cd /usr/src/sys/dev/virtio/ wget https://ecs-image-tools.oss-cn-hangzhou.aliyuncs.com/0001-virtio.patch patch -p4 < 0001-virtio.patchSalin file kernel, dan kompilasi serta instal kernel.
N dalam perintah
make -j<N>menunjukkan jumlah pekerjaan yang berjalan secara paralel. Atur N berdasarkan lingkungan kompilasi Anda. Misalnya, untuk lingkungan single-vCPU, kami sarankan Anda mengatur -j<N> ke-j2. Ini menunjukkan bahwa rasio jumlah vCPU terhadap nilai N adalah1:2.cd /usr/src/ cp ./sys/amd64/conf/GENERIC . make -j2 buildworld KERNCONF=GENERIC make -j2 buildkernel KERNCONF=GENERIC make -j2 installkernel KERNCONF=GENERICSetelah kernel dikompilasi, hapus kode sumber.
rm -rf /usr/src/* rm -rf /usr/src/.*
Disk sistem instance ECS yang menjalankan sistem operasi FreeBSD tidak dapat ditemukan di lingkungan KVM. Apa yang harus saya lakukan?
Deskripsi Masalah
Saat Anda masuk ke instance ECS yang menjalankan sistem operasi FreeBSD di lingkungan Kernel-based Virtual Machine (KVM) menggunakan Virtual Network Computing (VNC), disk sistem instance tidak dapat ditemukan dan login gagal, seperti yang ditunjukkan pada gambar berikut.
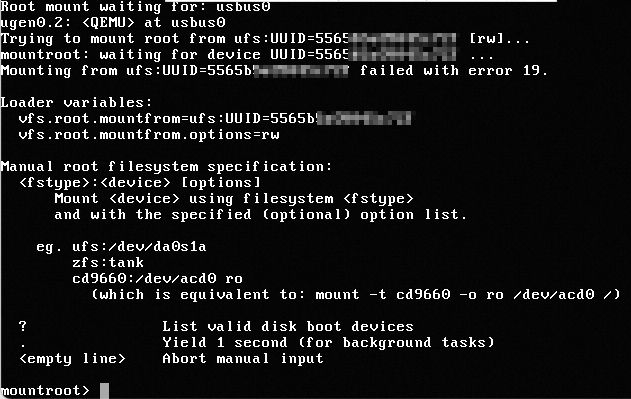
Solusi
Masukkan tanda tanya (?) di antarmuka VNC untuk melihat ufsid dari sistem file root.
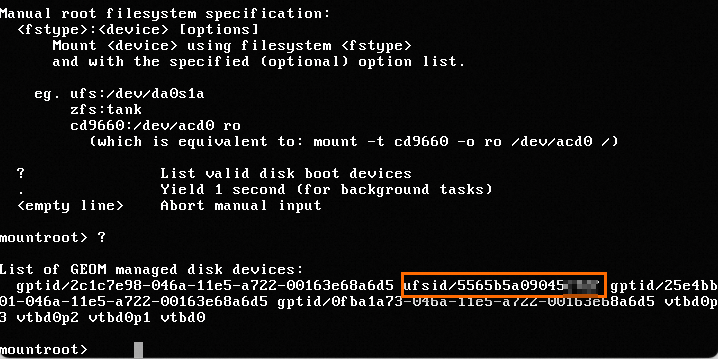
Masukkan
ufs:/dev/ufsid/5565b5a09045****dan tekan tombol Enter untuk mengakses sistem operasi.Masukkan nama pengguna dan kata sandi untuk masuk ke sistem.
Jalankan perintah berikut untuk memeriksa konfigurasi dalam file
/etc/fstab:cat /etc/fstabKeluaran perintah yang ditunjukkan pada gambar berikut menunjukkan bahwa sistem file root dikonfigurasikan untuk dipasang berdasarkan UUID dalam file
/etc/fstab. Namun, sistem operasi FreeBSD tidak mendukung pemasangan perangkat berdasarkan UUID. Anda harus mengonfigurasi sistem file root untuk dipasang berdasarkan ufsid.
Konfigurasikan sistem file root untuk dipasang berdasarkan ufsid.
Jalankan perintah berikut untuk membuka file
/etc/fstab:vi /etc/fstabTekan tombol I untuk masuk ke mode Sisip.
Ubah
UUID=5565b5a09045****menjadi/dev/ufsid/5565b5a09045****.Tekan tombol Esc, masukkan
:wq, dan kemudian tekan tombol Enter untuk menyimpan perubahan dan keluar.
Jalankan perintah berikut untuk me-restart sistem agar perubahan berlaku:
reboot
FAQ tentang citra Fedora
Mengapa saya tidak dapat menggunakan pasangan kunci SSH yang menggunakan algoritma tanda tangan ssh-rsa untuk terhubung ke instance ECS yang menjalankan Fedora 33 64-bit?
Jika Anda menggunakan pasangan kunci SSH dengan algoritma tanda tangan ssh-rsa untuk terhubung ke instance ECS yang menjalankan Fedora 33 64-bit, kemungkinan besar Anda tidak akan berhasil. Berikut adalah beberapa metode untuk menyelesaikan masalah ini:
Ganti pasangan kunci SSH yang menggunakan algoritma tanda tangan ssh-rsa dengan pasangan kunci SSH yang menggunakan algoritma lain, seperti Algoritma Tanda Tangan Digital Kurva Eliptik (ECDSA).
Jalankan perintah update-crypto-policies --set LEGACY di sistem untuk mengubah
POLICYmenjadiLEGACY. Dengan perubahan ini, Anda tetap dapat menggunakan pasangan kunci SSH dengan algoritma tanda tangan ssh-rsa.
Setelah saya menggunakan citra Fedora CoreOS untuk membuat instance dari keluarga instance tertentu, saya menemukan bahwa jumlah CPU dalam keluaran perintah lscpu hanya setengah dari jumlah vCPU dari tipe instance yang dipilih. Mengapa?
Setelah menggunakan citra Fedora CoreOS untuk membuat instance dari keluarga instance tertentu, seperti g5, Anda menjalankan perintah lscpu pada instance untuk melihat informasi CPU. Dalam keluaran perintah, jumlah total vCPU yang ditunjukkan oleh nilai
On-line CPU(s) listhanya setengah dari jumlah vCPU dari tipe instance yang dipilih. Sebagai contoh, jika tipe instance dengan dua vCPU digunakan untuk membuat instance, nilaiOn-line CPU(s) listhanya menunjukkan satu vCPU, seperti yang terlihat pada gambar berikut.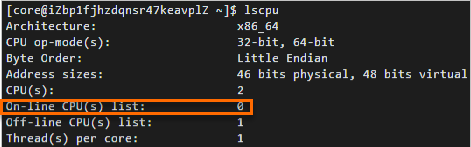 Catatan
CatatanNilai
On-line CPU(s) listmenunjukkan nomor seri vCPU. Pada gambar sebelumnya, hanya ada satu vCPU dengan nomor seri 0 yang tersedia.Hal ini disebabkan oleh pengaturan default parameter boot mitigations di kernel Fedora CoreOS ke
auto,nosmt, yang menonaktifkan pemrosesan multithreading simultan (SMT) untuk sistem yang rentan. Untuk memeriksa parameter mitigations yang diatur keauto,nosmt, Anda dapat menjalankan perintah cat /proc/cmdline.Untuk informasi lebih lanjut tentang SMT, lihat Nonaktifkan SMT secara otomatis saat diperlukan untuk menangani kerentanan dan Kebijakan untuk menonaktifkan SMT.
Lainnya
FAQ tentang waktu dan zona waktu Linux
Bagaimana cara menyesuaikan citra kustom Linux untuk disk sistem berbasis NVMe?
Bagaimana cara menyelesaikan masalah downtime yang terjadi pada instance yang dipindahkan?
Bagaimana cara menginstal GRand Unified Bootloader (GRUB) pada server Linux?
Apa yang harus saya lakukan jika saya tidak dapat terhubung ke instance menggunakan kunci RSA?
Bagaimana cara mengumpulkan informasi kdump setelah sistem operasi instance gagal?
Bagaimana cara menyelesaikan ketidaksesuaian antara frekuensi CPU dalam file /proc/cpuinfo dan frekuensi yang ditentukan untuk instance?
Apa yang harus saya lakukan jika layanan kdump tidak dapat menghasilkan file dump crash pada instance bare metal ECS?
Untuk informasi tentang penyebab dan solusi masalah ini, lihat Apa yang harus dilakukan jika file dump crash gagal dihasilkan pada beberapa instance ECS?
Kesalahan softlockup terjadi selama proses writeback kernel sistem operasi Linux. Apa yang harus saya lakukan?
Kesalahan softlockup terjadi ketika beberapa versi kernel Linux yang lebih lama menulis data kembali ke cache file. Untuk informasi tentang cara menyelesaikan masalah ini, lihat Solusi untuk masalah bahwa softlockup terjadi selama proses writeback kernel sistem operasi Linux.
Kesalahan softlockup terjadi saat saya menghapus cgroups dari instance ECS. Apa yang harus saya lakukan?
Untuk informasi tentang cara menyelesaikan masalah ini, lihat Kesalahan softlockup terjadi saat menghapus cgroups dalam instance ECS. Apa yang harus dilakukan?
Instance ECS down. Apa yang harus saya lakukan?
Apakah layanan FTP disertakan dalam citra publik?
Tidak, layanan FTP tidak disertakan dalam citra publik. Anda harus mengonfigurasi layanan FTP sendiri. Untuk informasi lebih lanjut, lihat Membuat situs FTP secara manual pada instance Windows dan Membuat situs FTP secara manual pada instance CentOS 7.
Mengapa ECS menonaktifkan memori virtual dan tidak mengonfigurasi partisi swap secara default?
Saat memori fisik tidak mencukupi, manajer memori menyimpan data memori yang tidak aktif untuk waktu yang lama ke partisi swap atau file memori virtual. Mekanisme ini membantu meningkatkan jumlah memori yang tersedia.
Namun, jika penggunaan memori sudah tinggi dan kinerja I/O buruk, mekanisme ini justru mengurangi jumlah memori yang tersedia. Disk cloud ECS Alibaba Cloud menggunakan sistem file terdistribusi untuk penyimpanan dan menyediakan beberapa replika kuat untuk setiap data. Mekanisme ini memastikan keamanan data pengguna tetapi memperburuk kinerja penyimpanan dan I/O disk lokal dengan melipatgandakan jumlah operasi I/O sebanyak tiga kali.
Oleh karena itu, memori virtual dinonaktifkan untuk Windows dan partisi swap tidak dikonfigurasi untuk Linux secara default untuk mencegah kinerja I/O semakin menurun ketika sumber daya sistem tidak mencukupi.
Bagaimana cara mengaktifkan layanan kdump dalam citra publik?
Secara default, layanan kdump dinonaktifkan dalam citra publik. Jika Anda ingin instance menghasilkan file core saat instance down sehingga Anda dapat menggunakan file tersebut untuk menganalisis penyebab kesalahan, Anda dapat melakukan langkah-langkah berikut untuk mengaktifkan layanan kdump. Dalam contoh berikut, citra publik CentOS 7.2 digunakan. Operasi mungkin berbeda berdasarkan versi sistem operasi Anda.
Konfigurasikan direktori tempat file core akan dihasilkan.
Jalankan perintah vim /etc/kdump.conf untuk membuka file konfigurasi kdump.
Jalankan perintah path untuk mengonfigurasi direktori tempat file core akan dihasilkan. Dalam contoh ini, direktorinya adalah /var/crash, dan perintah path berikut digunakan:
path /var/crashSimpan dan tutup file /etc/kdump.conf.
Aktifkan layanan kdump.
Gunakan salah satu metode berikut berdasarkan sistem operasi untuk mengaktifkan layanan kdump:
Metode 1: Jalankan perintah berikut untuk mengaktifkan layanan kdump:
systemctl enable kdump.servicesystemctlstartkdump.serviceMetode 2: Jalankan perintah berikut untuk mengaktifkan layanan kdump:
chkconfig kdump onservice kdump startMetode 3: Jika Cloud Assistant diinstal pada instance Anda, aktifkan layanan kdump berdasarkan instruksi dalam Bagaimana cara menyelesaikan masalah downtime pada instance yang dipindahkan? Aktifkan layanan kdump.
Setelah alamat IPv6 diberikan ke instance Linux tempat layanan NTP diinstal, waktu instance tidak dapat disinkronkan dengan waktu UTC. Apa yang harus saya lakukan?
Deskripsi masalah
Setelah Anda menjalankan perintah
ntpq -ppada instance Linux untuk menyinkronkan waktu, terjadi kesalahan timeout, seperti yang ditunjukkan pada gambar berikut.
Solusi
CatatanSolusi ini berlaku untuk instance yang menjalankan sistem operasi berikut: CentOS 7 dan sebelumnya, Ubuntu 20.04 dan sebelumnya, Anolis OS RHCK, Anolis OS ANCK, Alibaba Cloud Linux, dan Debian.
Hubungkan ke instance Linux.
Untuk informasi lebih lanjut, lihat Hubungkan ke instance Linux menggunakan kata sandi atau kunci.
Jalankan perintah berikut untuk memodifikasi file konfigurasi /etc/ntp.conf:
vi /etc/ntp.confTekan tombol I untuk masuk ke mode Sisip.
Tambahkan
restrict -6 ::1ke dalam file, seperti yang ditunjukkan pada gambar berikut.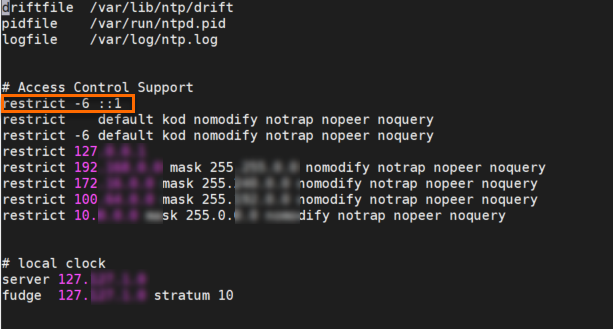
Tekan tombol Esc. Kemudian, masukkan
:wqdan tekan tombol Enter untuk menyimpan modifikasi dan keluar.Jalankan perintah berikut untuk me-restart layanan NTP:
systemctl restart ntp
Saya tidak dapat melakukan hot-swap disk atau ENI untuk instance yang sedang berjalan yang menggunakan citra kustom. Mengapa?
Deskripsi masalah
Hot swapping disk atau elastic network interfaces (ENI) melibatkan tindakan menempelkan disk ke, melepas disk dari, mengikat ENI ke, dan melepas ENI dari instance yang berada dalam status Running. Anda tidak dapat melakukan hot-swap disk atau ENI untuk instance Running yang menggunakan citra kustom.
Anda dapat melakukan hot-swap disk dan ENI untuk instance di Alibaba Cloud. Namun, operasi hot swapping mungkin gagal jika kernel sistem operasi instance tidak mendukung operasi tersebut. Jika kernel sistem operasi instance tidak mendukung operasi tersebut, masalah berikut mungkin terjadi:
Setelah Anda menempelkan disk ke atau mengikat ENI ke instance, disk atau ENI tidak dapat ditemukan dalam sistem operasi.
Anda tidak dapat melepas disk atau melepas ENI dari instance.
Solusi
Kernels sistem operasi instance ECS dan instance bare metal ECS mendukung fitur yang berbeda untuk memungkinkan hot swapping. Kami sarankan Anda mengaktifkan fitur hot swapping Peripheral Component Interconnect (PCI) dan hot swapping Advanced Configuration and Power Management Interface (ACPI) dalam kernels sistem operasi semua instance Anda. Secara default, hot swapping PCI dan hot swapping ACPI diaktifkan di semua sistem operasi, kecuali versi awal, seperti CentOS 5. Lakukan langkah-langkah berikut untuk memeriksa apakah hot swapping PCI atau hot swapping ACPI diaktifkan dalam kernel:
Hubungkan ke instance Linux.
Untuk informasi lebih lanjut, lihat Hubungkan ke instance Linux menggunakan kata sandi atau kunci.
Jalankan perintah berikut untuk melihat versi kernel instance:
uname -rKeluaran perintah yang ditunjukkan pada gambar berikut menunjukkan bahwa versi kernel adalah
3.10.0-1127.19.1.el7.x86_64.
Jalankan perintah berikut untuk memeriksa file di direktori
/boot:ll /bootInformasi
config-3.10.0-1127.19.1.el7.x86_64yang ditampilkan dalam keluaran perintah menunjukkan bahwa file config-3.10.0-1127.19.1.el7.x86_64 adalah file konfigurasi untuk kernel sistem.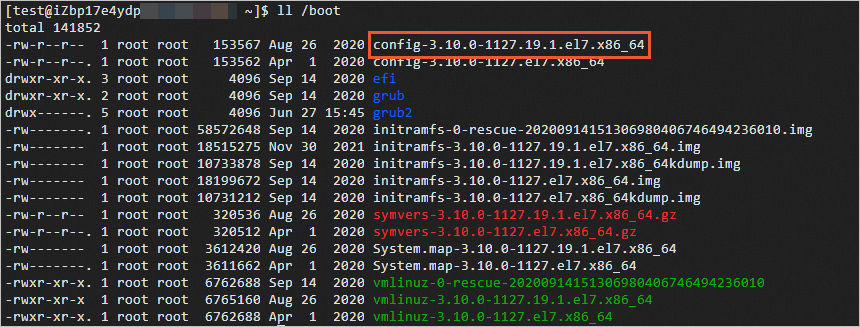
Jalankan perintah berikut untuk memeriksa konfigurasi kernel sistem:
cat /boot/config-3.10.0-1127.19.1.el7.x86_64Jika item konfigurasi berikut diatur ke
y, sistem operasi mendukung fitur hot swapping:CONFIG_HOTPLUG_PCI_PCIE=y CONFIG_HOTPLUG_PCI=y CONFIG_HOTPLUG_PCI_ACPI=yJika salah satu item konfigurasi berikut diatur ke
is not set, fitur hot swapping yang sesuai tidak didukung oleh kernel dan Anda harus memodifikasi konfigurasi kernel.Jika salah satu item konfigurasi berikut diatur ke m, item konfigurasi dikompilasi menjadi modul. Misalnya, item konfigurasi CONFIG_HOTPLUG_PCI_ACPI diatur ke
m, seperti yang ditunjukkan pada gambar berikut. Ini menunjukkan bahwaCONFIG_HOTPLUG_PCI_ACPIdikompilasi menjadi modul. Anda harus memuat modul untuk menggunakan fitur yang sesuai.CONFIG_HOTPLUG_PCI_PCIE=y CONFIG_HOTPLUG_PCI=y CONFIG_HOTPLUG_PCI_ACPI=mSebagai contoh, jika Anda menggunakan sistem operasi CentOS 5.x dengan versi kernel 2.6, modul yang sesuai dengan item konfigurasi CONFIG_HOTPLUG_PCI_ACPI adalah
acpiphp.ko. Untuk memuat modul, jalankan perintahmodprobe acpiphp. Jika modul gagal dimuat, tingkatkan ke versi kernel yang lebih baru atau hentikan instance, lalu lakukan operasi hot swapping.PentingKami sarankan Anda tidak sembarangan meningkatkan versi kernel atau versi sistem operasi instance. Untuk informasi tentang cara meningkatkan versi kernel, lihat Cara menghindari kegagalan boot selama peningkatan kernel instance Linux.
Apa yang harus saya lakukan jika instance dimatikan setelah terjadi kesalahan kernel sistem operasi?
Deskripsi masalah
Saat terjadi kesalahan kernel tak terduga (kernel panic) dalam sistem operasi instance, kernel kedua (capture kernel) dimuat untuk melakukan dump memori dan menghasilkan file log Kdump. Karena masalah kompatibilitas dengan jenis instance ECS Bare Metal, identifikasi disk gagal selama startup kernel kedua. Akibatnya, pengumpulan log Kdump gagal dan kernel kedua gagal memulai. Instance berada dalam status Dihentikan. Anda harus me-restart instance di konsol ECS.
Untuk informasi lebih lanjut tentang jenis instance ECS Bare Metal, lihat Ikhtisar keluarga instance.
Penyebab
Instance bare metal ECS mungkin gagal menghasilkan file dump menggunakan layanan Kdump yang disertakan dengan sistem operasi.
Masalah ini terjadi saat Anda menggunakan citra berikut untuk instance bare metal ECS generasi ke-6:
CentOS 8.3 atau lebih lama
Ubuntu 16 atau 18
Debian 10
Alibaba Cloud Linux 2 dengan versi kernel lebih lama dari
4.19.91-24.al7(Masalah ini diperbaiki di Alibaba Cloud Linux 2 mulai versi kernel4.19.91-24.al7.)
Masalah ini terjadi saat Anda memilih citra Debian 10 untuk instance bare metal ECS generasi ke-7.
Solusi
Citra CentOS
Kami sarankan Anda mengganti sistem operasi dengan versi yang lebih baru. Untuk informasi lebih lanjut, lihat Ganti sistem operasi (disk sistem) instance.
Citra Alibaba Cloud Linux 2
Kami sarankan Anda melakukan langkah-langkah berikut untuk meningkatkan versi kernel ke
4.19.91-24.al7atau lebih baru:Hubungkan ke instance.
Untuk informasi lebih lanjut, lihat Hubungkan ke instance Linux menggunakan kata sandi atau kunci.
Jalankan perintah berikut untuk menanyakan versi kernel:
uname -rJalankan perintah berikut untuk meningkatkan versi kernel:
sudo yum update kernelJalankan perintah berikut untuk me-restart instance ECS agar versi kernel baru berlaku:
sudo reboot