Topik ini menjelaskan cara menggunakan node MaxCompute di DataWorks untuk memproses data dalam tabel ods_user_info_d_odps dan ods_raw_log_d_odps di MaxCompute. Tujuannya adalah untuk mendapatkan data profil pengguna setelah informasi dasar pengguna dan log akses situs web disinkronkan ke tabel. Topik ini juga mencakup cara menggunakan kombinasi produk DataWorks dan MaxCompute untuk menghitung dan menganalisis data yang telah disinkronkan guna menyelesaikan pemrosesan data sederhana dalam skenario gudang data.
Prasyarat
Data yang diperlukan telah disinkronkan. Untuk informasi lebih lanjut, lihat Sinkronisasi Data.
Informasi dasar pengguna yang tersimpan dalam tabel ApsaraDB RDS for MySQL
ods_user_info_ddisinkronkan ke tabel MaxComputeods_user_info_d_odpsmenggunakan Data Integration.Log akses situs web pengguna yang tersimpan dalam objek Object Storage Service (OSS)
user_log.txtdisinkronkan ke tabel MaxComputeods_raw_log_d_odpsmenggunakan Data Integration.
Tujuan
Tujuan utamanya adalah memproses tabel ods_user_info_d_odps dan ods_raw_log_d_odps untuk menghasilkan tabel profil pengguna dasar.
Pisahkan bidang informasi log di tabel
ods_raw_log_d_odpsmenjadi beberapa bidang dan hasilkan tabel faktadwd_log_info_di_odps.Gabungkan tabel fakta
dwd_log_info_di_odpsdengan tabelods_user_info_d_odpsberdasarkan bidang uid untuk menghasilkan tabel agregatdws_user_info_all_di_odps.Proses tabel
dws_user_info_all_di_odpsuntuk menghasilkan tabel bernama ads_user_info_1d_odps. Tabel dws_user_info_all_di_odps berisi sejumlah besar bidang dan jumlah data yang besar. Dalam kasus ini,konsumsi datamungkin memerlukan waktu lama untuk diselesaikan. Oleh karena itu, pemrosesan data lebih lanjut diperlukan.
Pergi ke halaman DataStudio
Masuk ke konsol DataWorks. Di bilah navigasi atas, pilih wilayah yang diinginkan. Di panel navigasi sisi kiri, pilih . Pada halaman yang muncul, pilih ruang kerja yang diinginkan dari daftar drop-down dan klik Go to Data Development.
Langkah 1: Desain alur kerja
Pada fase sinkronisasi data, data yang diperlukan telah disinkronkan ke tabel MaxCompute. Langkah selanjutnya adalah memproses data lebih lanjut untuk menghasilkan data profil pengguna dasar.
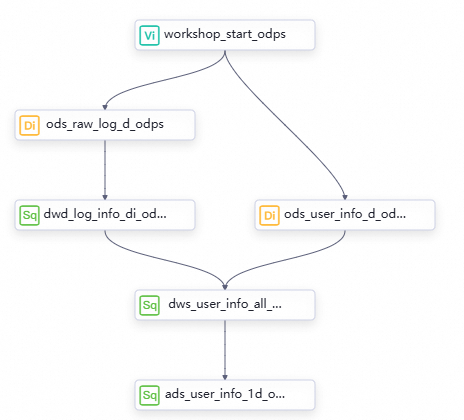
Node pada level yang berbeda dan logika kerja node tersebut
Di bagian atas kanvas alur kerja, klik Create Node untuk membuat node yang dijelaskan dalam tabel berikut guna pemrosesan data.
Kategori Node
Jenis Node
Nama Node
(Diberi nama berdasarkan tabel output)
Logika Kode
MaxCompute
ODPS SQL
dwd_log_info_di_odpsGunakan fungsi bawaan dan fungsi yang ditentukan pengguna (UDF) untuk memisahkan data di tabel
ods_raw_log_d_odpsdan tulis data ke beberapa bidang di tabeldwd_log_info_di_odps.MaxCompute
ODPS SQL
dws_user_info_all_di_odpsGabungkan tabel yang menyimpan informasi dasar pengguna dan tabel dwd_log_info_di_odps yang menyimpan data log yang diproses pendahuluan untuk menghasilkan tabel agregat.
MaxCompute
ODPS SQL
ads_user_info_1d_odpsProses lebih lanjut data untuk menghasilkan profil pengguna dasar.
Grafik asiklik terarah (DAG) dalam alur kerja
Seret node ke kanvas alur kerja, dan konfigurasikan dependensi antar node dengan menggambar garis untuk merancang alur kerja pemrosesan data.
Langkah 2: Konfigurasi alur kerja
Buat tabel MaxCompute
Buat tabel dwd_log_info_di_odps, dws_user_info_all_di_odps, dan ads_user_info_1d_odps untuk menyimpan data yang diproses di setiap lapisan. Dalam contoh ini, tabel dibuat dengan metode cepat. Untuk informasi lebih lanjut tentang operasi tabel terkait MaxCompute, lihat Buat dan Kelola Tabel MaxCompute.
Pergi ke titik masuk pembuatan tabel.
Di halaman DataStudio, buka alur kerja WorkShop yang Anda buat di fase sinkronisasi data. Klik kanan MaxCompute dan pilih Create Table.
Definisikan skema tabel MaxCompute.
Di kotak dialog Create Table, masukkan nama tabel dan klik Create. Sebagai contoh, Anda perlu membuat tiga tabel bernama
dwd_log_info_di_odps,dws_user_info_all_di_odps, danads_user_info_1d_odps. Lalu, pergi ke tab DDL dan jalankan pernyataan CREATE TABLE untuk membuat tabel. Anda dapat melihat pernyataan yang digunakan untuk membuat tabel-tabel tersebut di konten berikut.Komit tabel ke mesin komputasi.
Setelah Anda mendefinisikan skema tabel, klik Commit to Development Environment dan Commit to Production Environment secara berurutan di tab konfigurasi setiap tabel. Di proyek MaxCompute di lingkungan pengembangan dan produksi, sistem membuat tabel fisik terkait di proyek MaxCompute berdasarkan konfigurasi.
Jika Anda mengomitm tabel ke lingkungan pengembangan ruang kerja, tabel dibuat di proyek MaxCompute di lingkungan pengembangan.
Jika Anda mengomitm tabel ke lingkungan produksi ruang kerja, tabel dibuat di proyek MaxCompute di lingkungan produksi.
CatatanJika Anda menggunakan ruang kerja dalam mode dasar, Anda hanya perlu mengomitm tabel ke lingkungan produksi. Untuk informasi tentang ruang kerja dalam mode dasar dan ruang kerja dalam mode standar, lihat Perbedaan antara Ruang Kerja dalam Mode Dasar dan Ruang Kerja dalam Mode Standar.
Untuk informasi tentang hubungan antara DataWorks dan MaxCompute serta mesin komputasi MaxCompute di lingkungan yang berbeda, lihat Catatan Penggunaan untuk Pengembangan Node MaxCompute di DataWorks.
Buat tabel dwd_log_info_di_odps
Klik dua kali tabel dwd_log_info_di_odps. Di tab konfigurasi tabel yang muncul, klik DDL dan masukkan pernyataan CREATE TABLE berikut:
CREATE TABLE IF NOT EXISTS dwd_log_info_di_odps (
ip STRING COMMENT 'Alamat IP klien yang digunakan untuk mengirim permintaan',
uid STRING COMMENT 'ID pengguna',
time STRING COMMENT 'Waktu dalam format yyyymmddhh:mi:ss',
status STRING COMMENT 'Kode status yang dikembalikan oleh server',
bytes STRING COMMENT 'Jumlah byte yang dikembalikan ke klien',
region STRING COMMENT 'Wilayah, yang diperoleh berdasarkan alamat IP',
method STRING COMMENT 'Jenis permintaan HTTP',
url STRING COMMENT 'url',
protocol STRING COMMENT 'Nomor versi HTTP',
referer STRING COMMENT 'URL sumber',
device STRING COMMENT 'Jenis terminal',
identity STRING COMMENT 'Tipe akses, yang bisa berupa crawler, feed, user, atau unknown'
)
PARTITIONED BY (
dt STRING
)
LIFECYCLE 14;Buat tabel dws_user_info_all_di_odps
Klik dua kali tabel dws_user_info_all_di_odps. Di tab konfigurasi tabel yang muncul, klik DDL dan masukkan pernyataan CREATE TABLE berikut:
CREATE TABLE IF NOT EXISTS dws_user_info_all_di_odps (
uid STRING COMMENT 'ID pengguna',
gender STRING COMMENT 'Jenis kelamin',
age_range STRING COMMENT 'Rentang usia pengguna',
zodiac STRING COMMENT 'Zodiak',
region STRING COMMENT 'Wilayah, yang diperoleh berdasarkan alamat IP',
device STRING COMMENT 'Jenis terminal',
identity STRING COMMENT 'Tipe akses, yang bisa berupa crawler, feed, user, atau unknown',
method STRING COMMENT 'Jenis permintaan HTTP',
url STRING COMMENT 'url',
referer STRING COMMENT 'URL sumber',
time STRING COMMENT 'Waktu dalam format yyyymmddhh:mi:ss'
)
PARTITIONED BY (
dt STRING
)
LIFECYCLE 14;Buat tabel ads_user_info_1d_odps
Klik dua kali tabel ads_user_info_1d_odps. Di tab konfigurasi tabel yang muncul, klik DDL dan masukkan pernyataan CREATE TABLE berikut:
CREATE TABLE IF NOT EXISTS ads_user_info_1d_odps (
uid STRING COMMENT 'ID pengguna',
region STRING COMMENT 'Wilayah, yang diperoleh berdasarkan alamat IP',
device STRING COMMENT 'Jenis terminal',
pv BIGINT COMMENT 'pv',
gender STRING COMMENT 'Jenis kelamin',
age_range STRING COMMENT 'Rentang usia pengguna',
zodiac STRING COMMENT 'Zodiak'
)
PARTITIONED BY (
dt STRING
)
LIFECYCLE 14; Buat fungsi bernama getregion
Anda dapat menggunakan metode seperti fungsi untuk mengonversi struktur data log untuk eksperimen menjadi data dalam tabel. Dalam contoh ini, sumber daya yang diperlukan disediakan untuk fungsi yang digunakan untuk mengonversi alamat IP menjadi wilayah. Anda hanya perlu mengunduh sumber daya ke mesin lokal Anda dan mengunggah sumber daya ke ruang kerja Anda sebelum mendaftarkan fungsi di DataWorks.
Sumber daya alamat IP yang digunakan oleh fungsi ini hanya untuk keperluan tutorial ini. Jika Anda perlu mengimplementasikan pemetaan antara alamat IP dan lokasi geografis dalam skenario bisnis formal, Anda harus mencari layanan konversi alamat IP profesional dari situs web alamat IP khusus.
Unggah file sumber daya ip2region.jar
Unduh file ip2region.jar.
CatatanFile
ip2region.jarhanya untuk keperluan tutorial ini.Di halaman DataStudio, buka alur kerja WorkShop. Klik kanan MaxCompute dan pilih .
Klik Upload, pilih file ip2region.jar yang diunduh ke mesin lokal Anda, lalu klik Buka.
CatatanPilih Upload to MaxCompute.
Nama sumber daya dapat berbeda dari nama file yang diunggah.
Klik ikon
 di bilah alat atas untuk mengomitm sumber daya ke proyek MaxCompute di lingkungan pengembangan.
di bilah alat atas untuk mengomitm sumber daya ke proyek MaxCompute di lingkungan pengembangan.
Daftarkan fungsi getregion
Pergi ke halaman pendaftaran fungsi.
Di halaman DataStudio, buka alur kerja WorkShop, klik kanan MaxCompute, lalu pilih Create Function.
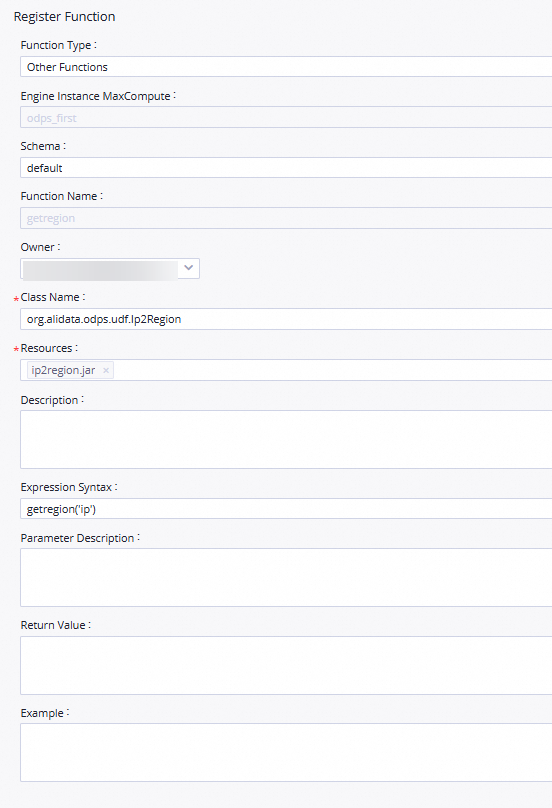
Masukkan nama fungsi.
Di kotak dialog Create Function, atur parameter Name ke
getregiondan klik Create.Di bagian Daftarkan Fungsi tab konfigurasi yang muncul, konfigurasikan parameter yang dijelaskan dalam tabel berikut.
Parameter
Deskripsi
Function Type
Jenis fungsi.
MaxCompute Engine Instance
Mesin komputasi MaxCompute. Nilai parameter ini tidak dapat diubah.
Function Name
Nama fungsi.
Owner
Pemilik fungsi.
Class Name
Atur parameter ini ke
org.alidata.odps.udf.Ip2Region.Resources
Atur parameter ini ke
ip2region.jar.Description
Atur parameter ini ke Konversi wilayah berdasarkan alamat IP.
Expression Syntax
Atur parameter ini ke
getregion('ip').Parameter Description
Atur parameter ini ke Alamat IP.
Klik ikon
di bilah alat atas untuk mengomitm fungsi ke mesin komputasi di lingkungan pengembangan.
Konfigurasi node MaxCompute
Dalam contoh ini, Anda perlu menggunakan node ODPS SQL untuk mengimplementasikan logika pemrosesan data di setiap lapisan. Terdapat hubungan garis keturunan data yang kuat antara node ODPS SQL di lapisan yang berbeda. Dalam fase sinkronisasi data, tabel output dari node sinkronisasi telah ditambahkan secara manual ke bagian Output pada tab Properties untuk node sinkronisasi. Oleh karena itu, dependensi penjadwalan node ODPS SQL yang digunakan untuk memproses data dalam contoh ini dapat dikonfigurasi secara otomatis berdasarkan garis keturunan data dengan menggunakan fitur penguraian otomatis.
Konfigurasi node dwd_log_info_di_odps
Di tab konfigurasi alur kerja, klik dua kali node dwd_log_info_di_odps. Di tab konfigurasi node, masukkan kode SQL yang memproses bidang di tabel leluhur ods_raw_log_d_odps dengan menggunakan fungsi yang dibuat dan menulis data yang diproses ke tabel dwd_log_info_di_odps. Untuk informasi lebih lanjut tentang cara memproses data, lihat Lampiran: Contoh Pemrosesan Data.
Edit kode node.
-- Skenario: Pernyataan SQL berikut menggunakan fungsi getregion untuk mengurai alamat IP dalam data log mentah, menggunakan metode seperti ekspresi reguler untuk memisahkan data yang diurai menjadi bidang yang dapat dianalisis, lalu menulis bidang tersebut ke tabel dwd_log_info_di_odps. -- Dalam contoh ini, fungsi getregion yang digunakan untuk mengonversi alamat IP menjadi wilayah telah disiapkan. -- Catatan: -- 1. Sebelum Anda dapat menggunakan fungsi di node DataWorks, Anda harus mengunggah sumber daya yang diperlukan untuk mendaftarkan fungsi ke DataWorks, lalu mendaftarkan fungsi tersebut secara visual menggunakan sumber daya tersebut. -- Dalam contoh ini, sumber daya yang digunakan untuk mendaftarkan fungsi getregion adalah ip2region.jar. -- 2. Anda dapat mengonfigurasi parameter penjadwalan untuk node di DataWorks untuk menulis data tambahan ke partisi terkait di tabel yang diinginkan setiap hari dalam skenario penjadwalan. -- Dalam skenario pengembangan aktual, Anda dapat mendefinisikan variabel dalam kode node dalam format ${Nama Variabel} dan menetapkan parameter penjadwalan ke variabel pada tab Properties dari tab konfigurasi node. Dengan cara ini, nilai parameter penjadwalan dapat diganti secara dinamis dalam kode node berdasarkan konfigurasi parameter penjadwalan. INSERT OVERWRITE TABLE dwd_log_info_di_odps PARTITION (dt='${bizdate}') SELECT ip , uid , time , status , bytes , getregion(ip) AS region -- Mendapatkan wilayah berdasarkan alamat IP menggunakan UDF. , regexp_substr(request, '(^[^ ]+ )') AS method -- Gunakan ekspresi reguler untuk mengekstrak tiga bidang dari permintaan. , regexp_extract(request, '^[^ ]+ (.*) [^ ]+$') AS url , regexp_substr(request, '([^ ]+$)') AS protocol , regexp_extract(referer, '^[^/]+://([^/]+){1}') AS referer -- Gunakan ekspresi reguler untuk memperjelas referrer untuk mendapatkan URL yang lebih akurat. , CASE WHEN TOLOWER(agent) RLIKE 'android' THEN 'android' -- Mendapatkan informasi terminal dan tipe akses berdasarkan parameter agent. WHEN TOLOWER(agent) RLIKE 'iphone' THEN 'iphone' WHEN TOLOWER(agent) RLIKE 'ipad' THEN 'ipad' WHEN TOLOWER(agent) RLIKE 'macintosh' THEN 'macintosh' WHEN TOLOWER(agent) RLIKE 'windows phone' THEN 'windows_phone' WHEN TOLOWER(agent) RLIKE 'windows' THEN 'windows_pc' ELSE 'unknown' END AS device , CASE WHEN TOLOWER(agent) RLIKE '(bot|spider|crawler|slurp)' THEN 'crawler' WHEN TOLOWER(agent) RLIKE 'feed' OR regexp_extract(request, '^[^ ]+ (.*) [^ ]+$') RLIKE 'feed' THEN 'feed' WHEN TOLOWER(agent) NOT RLIKE '(bot|spider|crawler|feed|slurp)' AND agent RLIKE '^[Mozilla|Opera]' AND regexp_extract(request, '^[^ ]+ (.*) [^ ]+$') NOT RLIKE 'feed' THEN 'user' ELSE 'unknown' END AS identity FROM ( SELECT SPLIT(col, '##@@')[0] AS ip , SPLIT(col, '##@@')[1] AS uid , SPLIT(col, '##@@')[2] AS time , SPLIT(col, '##@@')[3] AS request , SPLIT(col, '##@@')[4] AS status , SPLIT(col, '##@@')[5] AS bytes , SPLIT(col, '##@@')[6] AS referer , SPLIT(col, '##@@')[7] AS agent FROM ods_raw_log_d_odps WHERE dt ='${bizdate}' ) a;Konfigurasikan properti penjadwalan.
Di tab konfigurasi node, klik Properties di panel navigasi sisi kanan. Di tab Properties, konfigurasikan properti penjadwalan dan informasi dasar untuk node. Untuk informasi lebih lanjut, lihat Properti Penjadwalan Sebuah Node. Tabel berikut menjelaskan parameter.
Bagian
Deskripsi
Ilustrasi
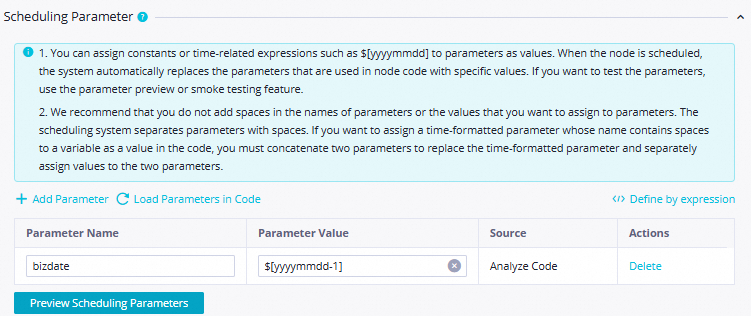
Scheduling Parameter
Konfigurasikan parameter berikut di bagian Scheduling Parameter:
Parameter Name: Atur nilainya ke
bizdate.Parameter Value: Atur nilainya ke
$[yyyymmdd-1].
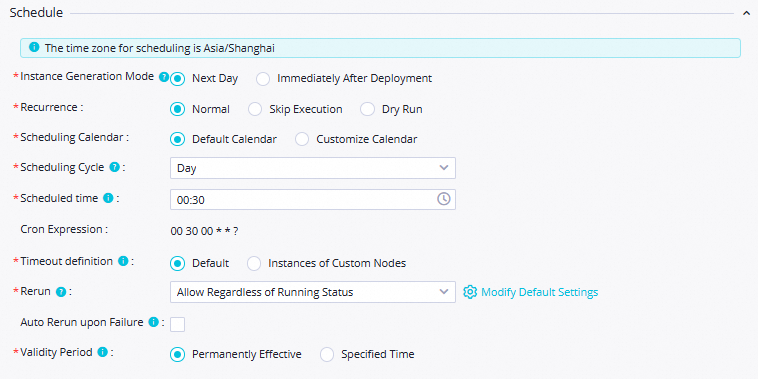
Schedule
Scheduling Cycle: Atur nilainya ke
Hari.Scheduled time: Atur nilai menjadi
00:30.Rerun: Atur nilainya ke Izinkan Tanpa Memedulikan Status Berjalan.
Gunakan nilai default untuk parameter lainnya.
CatatanWaktu ketika node saat ini dijadwalkan untuk dijalankan setiap hari ditentukan oleh waktu penjadwalan node beban nol workshop_start dari alur kerja. Node saat ini dijadwalkan untuk dijalankan setelah pukul 00:30 setiap hari.
Resource Group
Pilih grup sumber daya serverless yang Anda beli di fase persiapan lingkungan.

Dependencies
Atur Automatic Parsing From Code Before Node Committing ke Ya untuk mengizinkan sistem mengonfigurasi node
ods_raw_log_d_odpsyang menghasilkan tabelods_raw_log_d_odpssebagai node leluhur dari nodedwd_log_info_di_odps. Tabeldwd_log_info_di_odpsdigunakan sebagai output dari node dwd_log_info_di_odps. Dengan cara ini, node dwd_log_info_di_odps dapat dikonfigurasi secara otomatis sebagai node leluhur dari node lain ketika node tersebut menanyakan data tabel yang dihasilkan oleh node dwd_log_info_di_odps.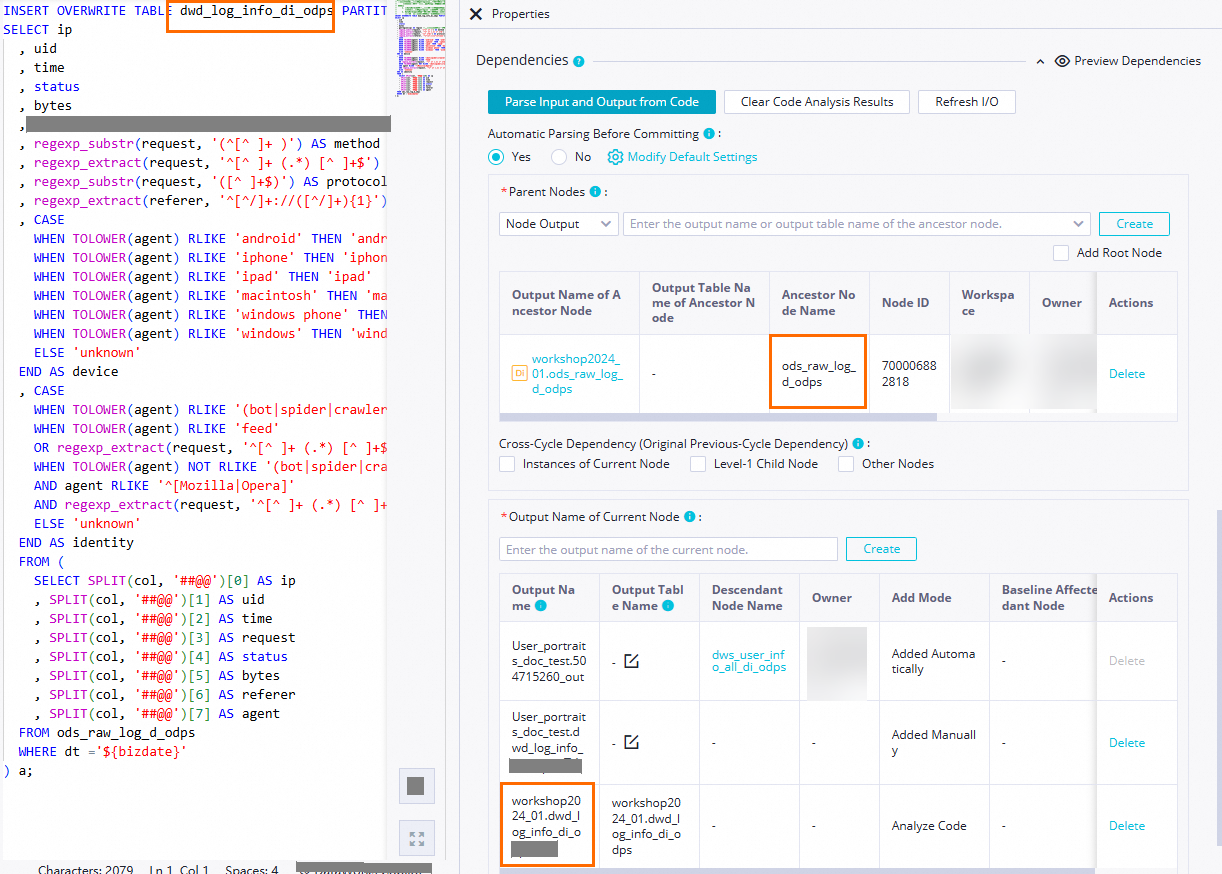 Catatan
CatatanTentukan node leluhur dari node saat ini: Klik Parse Input and Output from Code, nama tabel dalam kode diurai ke node output bernama dalam format
Nama proyek MaxCompute di lingkungan produksi.Nama tabel. Nama node output digunakan sebagai name of the output of an ancestor node.Tentukan output dari node saat ini: Klik Parse Input and Output from Code, nama tabel dalam kode diurai ke node output bernama dalam format
Nama proyek MaxCompute di lingkungan produksi.Nama tabel, yang di-output ke node hilir.Dalam contoh ini, item konfigurasi lain yang diperlukan dapat dikonfigurasi berdasarkan kebutuhan bisnis Anda. Setelah konfigurasi selesai, klik ikon
 di bilah alat atas pada tab konfigurasi node untuk menyimpan konfigurasi node.
di bilah alat atas pada tab konfigurasi node untuk menyimpan konfigurasi node.
Konfigurasi node dws_user_info_all_di_odps
Di tab konfigurasi alur kerja, klik dua kali node dws_user_info_all_di_odps. Di tab konfigurasi node, masukkan kode SQL yang menggabungkan tabel leluhur dwd_log_info_di_odps dan ods_user_info_d_odps, lalu tulis data gabungan ke tabel dws_user_info_all_di_odps.
Edit kode node.
-- Skenario: Agregasikan data log yang diproses di tabel dwd_log_info_di_odps dan informasi dasar pengguna di tabel ods_user_info_d_odps dan tulis data agregat ke tabel dws_user_info_all_di_odps. -- Catatan: Anda dapat mengonfigurasi parameter penjadwalan untuk node di DataWorks untuk menulis data tambahan ke partisi terkait di tabel yang diinginkan setiap hari dalam skenario penjadwalan. -- Dalam skenario pengembangan aktual, Anda dapat mendefinisikan variabel dalam kode node dalam format ${Nama Variabel} dan menetapkan parameter penjadwalan ke variabel pada tab Properties dari tab konfigurasi node. Dengan cara ini, nilai parameter penjadwalan dapat diganti secara dinamis dalam kode node berdasarkan konfigurasi parameter penjadwalan. INSERT OVERWRITE TABLE dws_user_info_all_di_odps PARTITION (dt='${bizdate}') SELECT COALESCE(a.uid, b.uid) AS uid , b.gender , b.age_range , b.zodiac , a.region , a.device , a.identity , a.method , a.url , a.referer , a.time FROM ( SELECT * FROM dwd_log_info_di_odps WHERE dt = '${bizdate}' ) a LEFT OUTER JOIN ( SELECT * FROM ods_user_info_d_odps WHERE dt = '${bizdate}' ) b ON a.uid = b.uid;Konfigurasikan properti penjadwalan.
Di tab konfigurasi node, klik Properties di panel navigasi sisi kanan. Di tab Properties, konfigurasikan properti penjadwalan dan informasi dasar untuk node. Untuk informasi lebih lanjut, lihat Properti Penjadwalan Sebuah Node. Tabel berikut menjelaskan parameter.
Bagian
Deskripsi
Ilustrasi
Scheduling Parameter
Konfigurasikan parameter berikut di bagian Scheduling Parameter:
Parameter Name: Atur nilainya ke
bizdate.Parameter Value: Atur nilainya ke
$[yyyymmdd-1].
Schedule
Scheduling Cycle: Atur nilainya ke
Hari.Scheduled time: Atur nilainya ke
00:30.Rerun: Atur nilainya ke Izinkan Tanpa Memedulikan Status Berjalan.
Gunakan nilai default untuk parameter lainnya.
CatatanWaktu ketika node saat ini dijadwalkan untuk dijalankan setiap hari ditentukan oleh waktu penjadwalan node beban nol workshop_start dari alur kerja. Node saat ini dijadwalkan untuk dijalankan setelah pukul 00:30 setiap hari.
Resource Group
Pilih grup sumber daya serverless yang Anda beli di fase persiapan lingkungan.
Dependencies
Atur Penguraian Otomatis Dari Kode Sebelum Mengomitm Node ke Ya untuk mengizinkan sistem mengonfigurasi node
dwd_log_info_di_odpsdanods_user_info_d_odpsyang menghasilkan tabeldwd_log_info_di_odpsdanods_user_info_d_odpssebagai node leluhur dari nodedws_user_info_all_di_odps. Tabeldws_user_info_all_di_odpsdigunakan sebagai output dari node dws_user_info_all_di_odps. Dengan cara ini, node dws_user_info_all_di_odps dapat dikonfigurasi secara otomatis sebagai node leluhur dari node lain ketika node tersebut menanyakan data tabel yang dihasilkan oleh node dws_user_info_all_di_odps.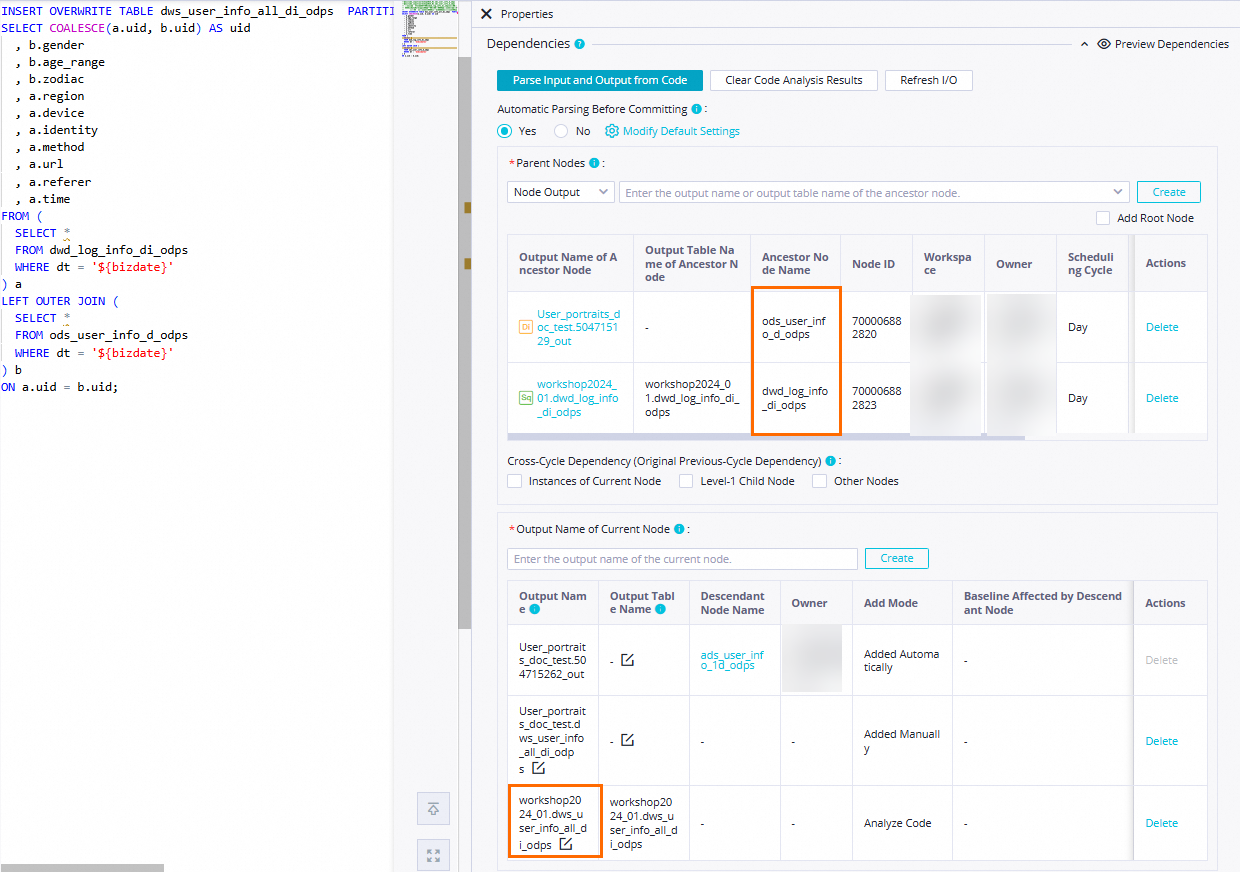 Catatan
CatatanTentukan node leluhur dari node saat ini: Klik Parse Input and Output from Code, nama tabel dalam kode diurai ke node output bernama dalam format
Nama proyek MaxCompute di lingkungan produksi.Nama tabel. Nama node output digunakan sebagai name of the output of an ancestor node.Tentukan output dari node saat ini: Klik Parse Input and Output from Code, nama tabel dalam kode diurai ke node output bernama dalam format
Nama proyek MaxCompute di lingkungan produksi.Nama tabel, yang di-output ke node hilir.Dalam contoh ini, item konfigurasi lain yang diperlukan dapat dikonfigurasi berdasarkan kebutuhan bisnis Anda. Setelah konfigurasi selesai, klik ikon
di bilah alat atas pada tab konfigurasi node untuk menyimpan konfigurasi node.
Konfigurasi node ads_user_info_1d_odps
Di tab konfigurasi alur kerja, klik dua kali node ads_user_info_1d_odps. Di tab konfigurasi node, masukkan kode SQL yang memproses tabel leluhur dws_user_info_all_di_odps dan menulis data yang diproses ke tabel ads_user_info_1d_odps.
Edit kode node.
-- Skenario: Pernyataan SQL berikut digunakan untuk memproses lebih lanjut tabel lebar dws_user_info_all_di_odps yang digunakan untuk menyimpan informasi akses pengguna ke tabel ads_user_info_1d_odps yang digunakan untuk menyimpan data profil pengguna dasar. -- Catatan: Anda dapat mengonfigurasi parameter penjadwalan untuk node di DataWorks untuk menulis data tambahan ke partisi terkait di tabel yang diinginkan setiap hari dalam skenario penjadwalan. -- Dalam skenario pengembangan aktual, Anda dapat mendefinisikan variabel dalam kode node dalam format ${Nama Variabel} dan menetapkan parameter penjadwalan ke variabel pada tab Properties dari tab konfigurasi node. Dengan cara ini, nilai parameter penjadwalan dapat diganti secara dinamis dalam kode node berdasarkan konfigurasi parameter penjadwalan. INSERT OVERWRITE TABLE ads_user_info_1d_odps PARTITION (dt='${bizdate}') SELECT uid , MAX(region) , MAX(device) , COUNT(0) AS pv , MAX(gender) , MAX(age_range) , MAX(zodiac) FROM dws_user_info_all_di_odps WHERE dt = '${bizdate}' GROUP BY uid;Konfigurasikan properti penjadwalan.
Di tab konfigurasi node, klik Properties di panel navigasi sisi kanan. Di tab Properties, konfigurasikan properti penjadwalan dan informasi dasar untuk node. Untuk informasi lebih lanjut, lihat Properti Penjadwalan Sebuah Node. Tabel berikut menjelaskan parameter.
Bagian
Deskripsi
Ilustrasi
Scheduling Parameter
Konfigurasikan parameter berikut di bagian Scheduling Parameter:
Parameter Name: Atur nilainya ke
bizdate.Parameter Value: Atur nilainya ke
$[yyyymmdd-1].
Schedule
Scheduling Cycle: Atur nilainya ke
Hari.Scheduled time: Atur nilainya ke
00:30.Rerun: Atur nilainya ke Izinkan Tanpa Memedulikan Status Berjalan.
Gunakan nilai default untuk parameter lainnya.
CatatanWaktu ketika node saat ini dijadwalkan untuk dijalankan setiap hari ditentukan oleh waktu penjadwalan node beban nol workshop_start dari alur kerja. Node saat ini dijadwalkan untuk dijalankan setelah pukul 00:30 setiap hari.
Resource Group
Pilih grup sumber daya serverless yang Anda beli di fase persiapan lingkungan.
Dependencies
Atur Automatic Parsing From Code Before Node Committing ke Ya untuk mengizinkan sistem mengonfigurasi node
dws_user_info_all_1d_odpsyang menghasilkan tabeldws_user_info_all_1d_odpssebagai node leluhur dari nodeads_user_info_1d_odps. Tabel ads_user_info_1d digunakan sebagai output dari node ads_user_info_1d. Dengan cara ini, node ads_user_info_1d dapat dikonfigurasi secara otomatis sebagai node leluhur dari node lain ketika node tersebut menanyakan data tabel yang dihasilkan oleh node ads_user_info_1d.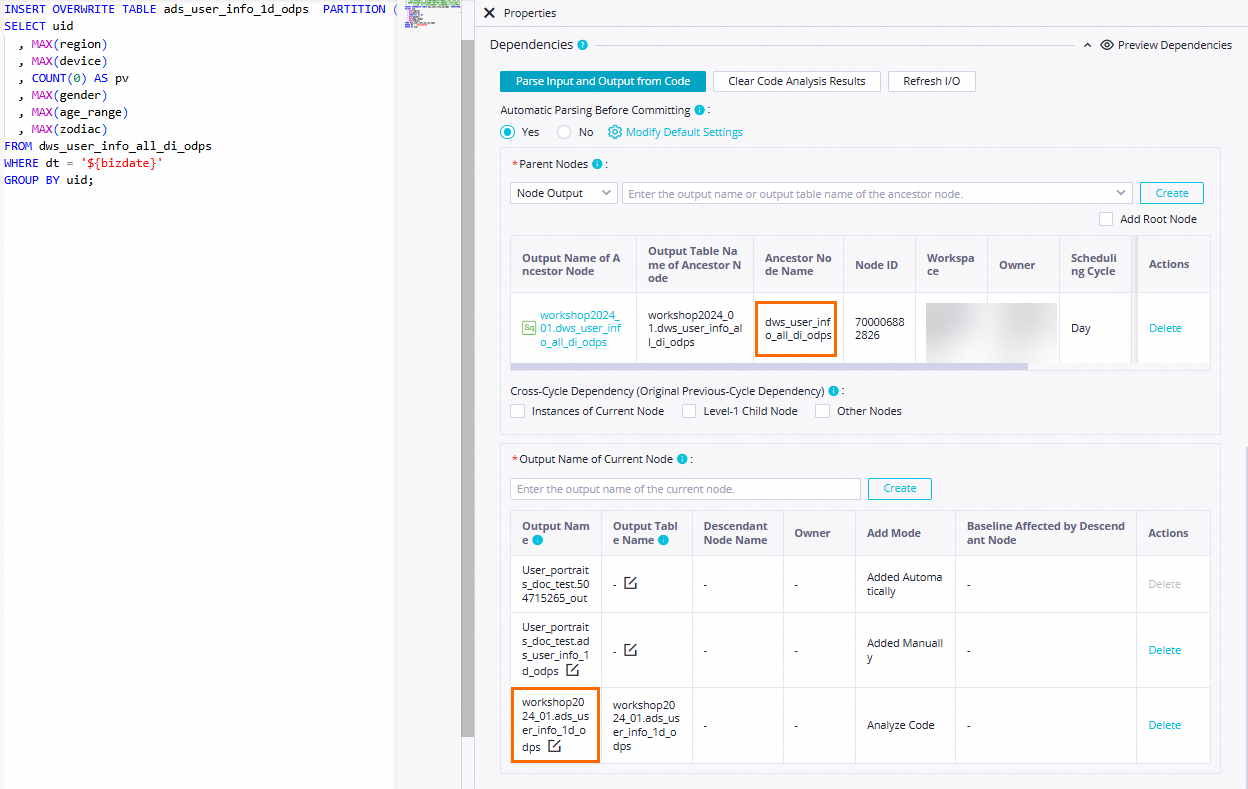 Catatan
CatatanTentukan node leluhur dari node saat ini: Klik Parse Input and Output from Code, nama tabel dalam kode diurai ke node output bernama dalam format
Nama proyek MaxCompute di lingkungan produksi.Nama tabel. Nama node output digunakan sebagai name of the output of an ancestor node.Tentukan output dari node saat ini: Klik Parse Input and Output from Code, nama tabel dalam kode diurai ke node output bernama dalam format
Nama proyek MaxCompute di lingkungan produksi.Nama tabel, yang di-output ke node hilir.Dalam contoh ini, item konfigurasi lain yang diperlukan dapat dikonfigurasi berdasarkan kebutuhan bisnis Anda. Setelah konfigurasi selesai, klik ikon
di bilah alat atas pada tab konfigurasi node untuk menyimpan konfigurasi node.
Langkah 3: Jalankan alur kerja
Jalankan alur kerja
Di halaman DataStudio, klik dua kali alur kerja
User profile analysis_MaxComputedi bawah Business Flow. Di tab konfigurasi alur kerja, klik ikon di bilah alat atas untuk menjalankan node dalam alur kerja berdasarkan dependensi penjadwalan antar node.
di bilah alat atas untuk menjalankan node dalam alur kerja berdasarkan dependensi penjadwalan antar node.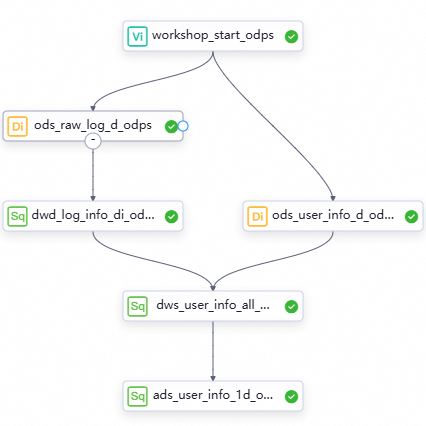
Konfirmasi status.
Periksa status node: Jika node berada dalam keadaan
 , proses sinkronisasi berjalan normal.
, proses sinkronisasi berjalan normal.Lihat log node yang sedang berjalan: Klik kanan node dan pilih Lihat Log untuk melihat log setiap node dalam seluruh proses analisis profil pengguna di lingkungan pengembangan.
Lihat hasil sinkronisasi
Setelah semua node dalam alur kerja memasuki keadaan ![]() , Anda dapat menanyakan tabel hasil akhir yang diproses.
, Anda dapat menanyakan tabel hasil akhir yang diproses.
Di panel navigasi sisi kiri halaman DataStudio, klik
 .
.Di panel Ad Hoc Query, klik kanan Ad Hoc Query dan pilih Create Node > ODPS SQL.
Jalankan pernyataan SQL berikut di node ODPS SQL untuk mengonfirmasi tabel hasil akhir dalam contoh ini.
// Anda harus menentukan cap waktu data dari data yang Anda lakukan operasi baca dan tulis sebagai kondisi filter untuk partisi. Sebagai contoh, jika sebuah node dijadwalkan untuk berjalan pada 22 Februari 2023, cap waktu data dari node tersebut adalah 20230221, yang satu hari lebih awal dari waktu penjadwalan node. select count(*) from ads_user_info_1d_odps where dt='Cap waktu Data';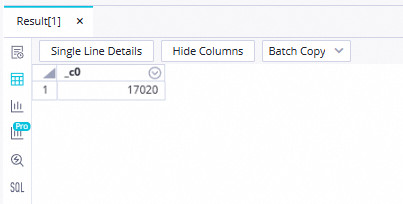 Catatan
CatatanDalam contoh ini, node dijalankan di DataStudio, yaitu lingkungan pengembangan. Oleh karena itu, data ditulis ke tabel yang ditentukan di proyek MaxCompute workshop2024_01_dev yang terkait dengan ruang kerja di lingkungan pengembangan secara default.
Langkah 4: Terapkan alur kerja
Node hanya dapat dijadwalkan dan dijalankan secara otomatis setelah diterapkan ke lingkungan produksi. Untuk informasi lebih lanjut, lihat konten berikut.
Komit alur kerja ke lingkungan pengembangan
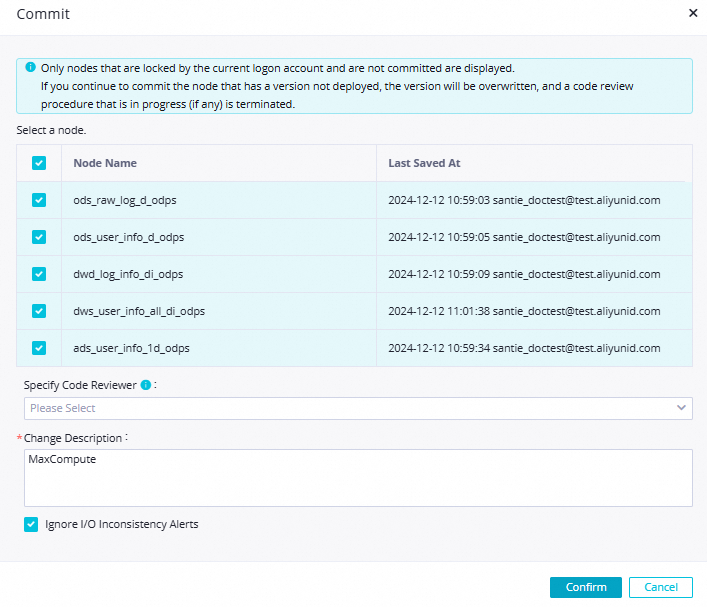
Di bilah alat atas tab konfigurasi alur kerja, klik ikon  untuk mengomitm semua node dalam alur kerja. Di kotak dialog Commit, konfigurasikan parameter seperti yang ditunjukkan pada gambar berikut, lalu klik Confirm.
untuk mengomitm semua node dalam alur kerja. Di kotak dialog Commit, konfigurasikan parameter seperti yang ditunjukkan pada gambar berikut, lalu klik Confirm.
Komit alur kerja ke lingkungan produksi
Setelah Anda mengomitm alur kerja, node dalam alur kerja masuk ke lingkungan pengembangan. Anda harus menerapkan node yang telah dikonfigurasi ke lingkungan produksi karena node di lingkungan pengembangan tidak dapat dijadwalkan secara otomatis.
Di bilah alat atas tab konfigurasi alur kerja, klik ikon
 . Atau, pergi ke tab konfigurasi salah satu node di DataStudio dan klik ikon Deploy di pojok kanan atas untuk pergi ke halaman Create Deploy Task.
. Atau, pergi ke tab konfigurasi salah satu node di DataStudio dan klik ikon Deploy di pojok kanan atas untuk pergi ke halaman Create Deploy Task.Terapkan node yang diinginkan secara bersamaan. Konten yang diterapkan mencakup sumber daya dan fungsi yang terlibat dalam alur kerja.
Langkah 5: Lakukan O&M dan operasi penjadwalan pada alur kerja
Dalam skenario pengembangan aktual, Anda dapat menggunakan fitur backfill data di lingkungan produksi untuk mengisi ulang data dari periode waktu historis atau masa depan. Bagian ini menjelaskan cara melakukan operasi O&M dan penjadwalan pada contoh backfill data. Untuk informasi lebih lanjut tentang kemampuan di Operation Center, lihat Operation Center.
Buka halaman Operation Center.
Setelah node diterapkan, klik Operation Center di pojok kanan atas tab konfigurasi node.
Anda juga dapat mengklik Operation Center di bagian atas halaman DataStudio untuk membuka halaman Operation Center.
Isi ulang data untuk tugas yang dipicu otomatis.
Di panel navigasi sisi kiri, pilih . Pada halaman yang muncul, klik node root dari alur kerja
workshop_start_odps.Klik kanan node
workshop_start_odpsdan pilih .Pilih semua node turunan dari node
workshop_start_odps, masukkan cap waktu data, lalu klik OK. Halaman Patch Data akan muncul.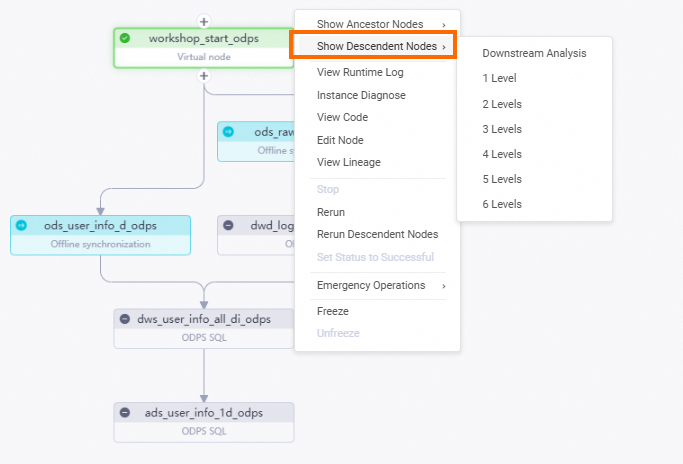
Klik Refresh hingga semua node SQL berhasil dijalankan.
Setelah pengujian selesai, Anda dapat mengonfigurasi parameter Validity Period untuk node atau freeze node root dari alur kerja tempat node tersebut berada untuk mencegah biaya penjadwalan node jangka panjang. Node root adalah node beban nol bernama workshop_start_odps.
Apa yang Harus Dilakukan Selanjutnya
Setelah menerapkan node, alur kerja selesai. Anda dapat melihat detail tabel yang dibuat, menggunakan data dari tabel terkait, dan mengonfigurasi pemantauan kualitas data. Untuk informasi lebih lanjut, lihat Kelola data, Gunakan API untuk menyediakan layanan data, Visualisasikan data pada dasbor, dan Pantau kualitas data.
Lampiran: Contoh Pemrosesan Data
Sebelum pemrosesan data:
58.246.10.82##@@2d24d94f14784##@@2014-02-12 13:12:25##@@GET /wp-content/themes/inove/img/feeds.gif HTTP/1.1##@@200##@@2572##@@http://coolshell.cn/articles/10975.html##@@Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/32.0.1700.107 Safari/537.36Setelah pemrosesan data:
