Tutorial ini menggunakan tugas sinkronisasi batch Data Integration untuk menyinkronkan informasi dasar pengguna dari tabel MySQL ods_user_info_d dan log akses website dari file Object Storage Service (OSS) user_log.txt ke tabel MaxCompute ods_user_info_d_odps dan ods_raw_log_d_odps, masing-masing. Contoh ini menunjukkan cara Data Integration menyinkronkan data antara sumber data heterogen untuk gudang data.
Prasyarat
Pastikan Anda telah membaca pengenalan eksperimen.
Pastikan Anda telah menyiapkan lingkungan yang diperlukan seperti yang dijelaskan dalam menyiapkan lingkungan.
Tujuan
Sinkronkan data dari sumber data publik yang disediakan ke MaxCompute. Ini menyelesaikan langkah sinkronisasi data dalam alur kerja bisnis.
Jenis sumber | Data sumber | Skema tabel sumber | Jenis tujuan | Tabel tujuan | Skema tabel tujuan |
MySQL | Tabel: ods_user_info_d Informasi dasar pengguna |
| MaxCompute |
|
|
HttpFile | object: user_log.txt Log akses website pengguna | Setiap baris berisi catatan akses pengguna. | MaxCompute |
|
|
Platform menyediakan data uji dan sumber data untuk tutorial ini. Anda harus menambahkan sumber data ke ruang kerja Anda untuk mengakses data uji tersebut.
Tutorial ini menyediakan data tiruan untuk latihan langsung di DataWorks. Anda hanya dapat membaca data ini di modul Data Integration.
DataStudio
Masuk ke Konsol DataWorks. Di wilayah target, klik di panel navigasi sebelah kiri. Pilih ruang kerja dari daftar drop-down dan klik Go to Data Development.
Langkah 1: Rancang alur kerja
Rancang alur kerja
Buat alur kerja.
Di DataWorks, pengembangan data dilakukan menggunakan komponen dalam alur kerja. Sebelum membuat node, Anda harus terlebih dahulu membuat alur kerja. Untuk petunjuknya, lihat Buat alur kerja.
Beri nama alur kerja
user_profile_analysis_MaxCompute.
Rancang alur kerja.
Setelah alur kerja dibuat, kanvas-nya akan terbuka secara otomatis. Di kanvas, klik New Node. Rancang alur kerja sinkronisasi data dengan menyeret node ke kanvas dan menghubungkannya untuk menentukan dependensi. Untuk informasi lebih lanjut, lihat Desain alur kerja.
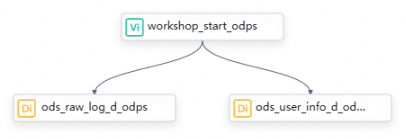
Dalam tutorial ini, tidak ada alur data antara node zero-load dan node sinkronisasi batch. Oleh karena itu, tentukan dependensinya dengan menggambar garis di kanvas alur kerja. Untuk informasi lebih lanjut tentang cara mengonfigurasi dependensi, lihat Panduan mengonfigurasi dependensi penjadwalan. Tabel berikut menjelaskan jenis, nama, dan fungsi setiap node.
Kategori
Jenis
Nama
(Dinamai sesuai tabel output akhir)
Deskripsi
Umum
zero-load node
workshop_start_odpsMengoordinasikan alur kerja analisis profil pengguna, misalnya dengan mengatur waktu mulainya. Ini memperjelas jalur alur data dalam alur kerja kompleks. Node ini merupakan tugas dry-run dan tidak memerlukan pengeditan kode.
Data integration
batch synchronization
ods_user_info_d_odpsMenyinkronkan informasi dasar pengguna dari MySQL ke tabel MaxCompute
ods_user_info_d_odps.Data integration
batch synchronization
ods_raw_log_d_odpsMenyinkronkan log akses website pengguna dari OSS ke tabel MaxCompute
ods_raw_log_d_odps.
Konfigurasi logika penjadwalan
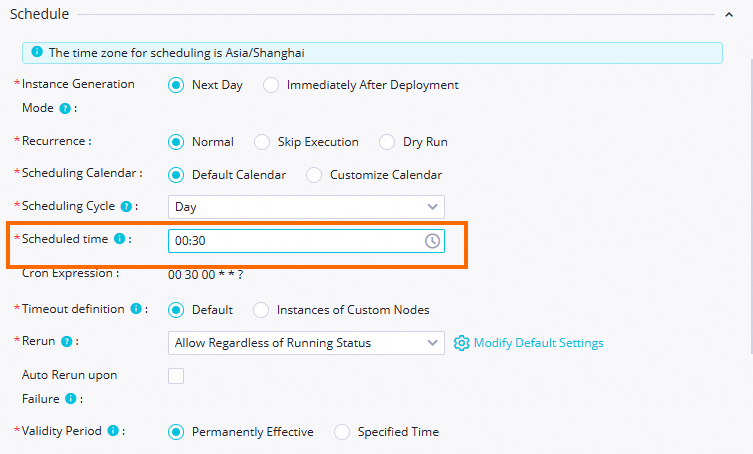
Dalam tutorial ini, node zero-load workshop_start_odps memicu alur kerja untuk berjalan setiap hari pukul 00.30. Tabel berikut merinci konfigurasi penjadwalan utama untuk node ini. Anda tidak perlu mengubah pengaturan penjadwalan untuk node lainnya. Untuk detail implementasi, lihat Konfigurasi properti waktu lanjutan. Untuk informasi lebih lanjut tentang konfigurasi penjadwalan lainnya, lihat Ikhtisar konfigurasi properti penjadwalan tugas.
Konfigurasi | Cuplikan layar | Deskripsi |
Konfigurasi waktu penjadwalan |
| Waktu penjadwalan untuk node zero-load diatur ke 00:30. Node ini memicu alur kerja untuk berjalan setiap hari pukul 00:30. |
Konfigurasi dependensi penjadwalan |
| Karena node zero-load |
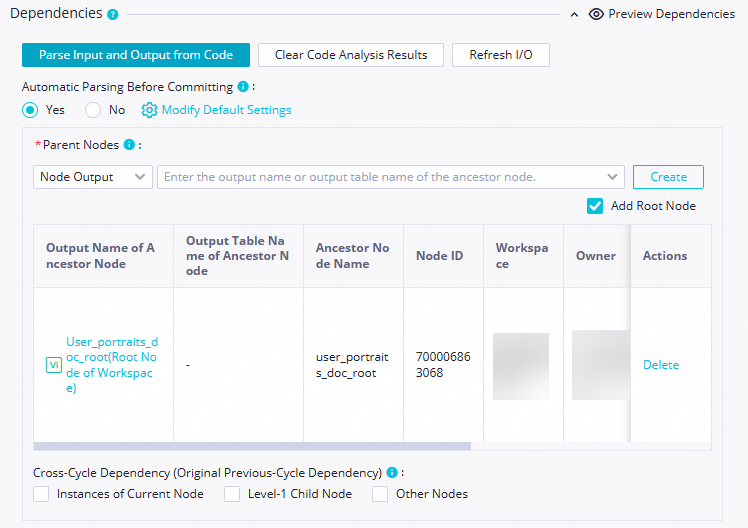
Semua node di DataWorks harus bergantung pada node hulu. Semua tugas dalam tahap sinkronisasi data bergantung pada node zero-load workshop_start_odps. Dengan kata lain, node workshop_start_odps memicu alur kerja sinkronisasi data.
Langkah 2: Buat tautan sinkronisasi
Buat tabel MaxCompute
Sebelum memulai, buat tabel MaxCompute tujuan yang akan menyimpan data mentah yang disinkronkan oleh Data Integration. Tutorial ini menjelaskan cara membuatnya dengan cepat. Untuk petunjuk lebih rinci, lihat Kelola tabel MaxCompute.
Navigasi ke halaman pembuatan tabel.
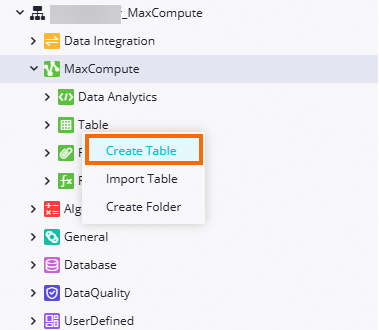
Buat tabel ods_raw_log_d_odps.
Di kotak dialog Create Table, masukkan
ods_raw_log_d_odpsdi kolom Name. Di halaman editor tabel, klik DDL, masukkan pernyataan berikut, lalu klik Generate Table Schema. Klik Confirm untuk menimpa skema saat ini.CREATE TABLE IF NOT EXISTS ods_raw_log_d_odps ( col STRING ) PARTITIONED BY ( dt STRING ) LIFECYCLE 7;Buat tabel ods_user_info_d_odps.
Di kotak dialog Create Table, masukkan
ods_user_info_d_odpsdi kolom Name. Di halaman editor tabel, klik DDL, masukkan pernyataan berikut, lalu klik Generate Table Schema. Klik Confirm untuk menimpa skema saat ini.CREATE TABLE IF NOT EXISTS ods_user_info_d_odps ( uid STRING COMMENT 'User ID', gender STRING COMMENT 'Gender', age_range STRING COMMENT 'Age range', zodiac STRING COMMENT 'Zodiac' ) PARTITIONED BY ( dt STRING ) LIFECYCLE 7;Komit dan publikasikan tabel.
Setelah memverifikasi bahwa informasi tabel sudah benar, untuk masing-masing tabel
ods_user_info_d_odpsdanods_raw_log_d_odps, klik Commit to Development Environment lalu Commit to Production Environment. Operasi ini membuat tabel fisik di proyek mesin komputasi untuk lingkungan pengembangan dan produksi, sesuai definisi dalam konfigurasi node Anda.CatatanSetelah menetapkan skema tabel, Anda perlu mengirimkannya ke lingkungan pengembangan dan produksi. Setelah pengiriman berhasil, tabel tersebut dapat dilihat di Proyek Mesin komputasi yang sesuai.
Komit tabel ke lingkungan pengembangan DataWorks untuk membuat tabel di mesin MaxCompute yang terkait dengan lingkungan pengembangan.
Komit tabel ke lingkungan produksi DataWorks untuk membuat tabel di mesin MaxCompute yang terkait dengan lingkungan produksi.
Buat sumber data
Tutorial ini menggunakan data uji dari instans ApsaraDB for RDS (MySQL) dan OSS. Anda harus membuat sumber data MySQL bernama user_behavior_analysis_mysql dan sumber data HttpFile bernama user_behavior_analysis_httpfile di ruang kerja Anda untuk mengakses data uji yang disediakan. Informasi dasar yang diperlukan untuk sumber data telah disediakan.
Sebelum mengonfigurasi tugas sinkronisasi Data Integration, Anda dapat mengonfigurasi database atau gudang data sumber dan tujuan di halaman Data Source di DataWorks. Hal ini memungkinkan Anda memilih sumber data berdasarkan nama saat mengonfigurasi tugas untuk menentukan lokasi pembacaan dan penulisan data.
Data yang disediakan dalam tutorial ini adalah data tiruan untuk latihan langsung di DataWorks dan hanya dapat dibaca di modul Data Integration.
Data uji untuk sumber data HttpFile dan MySQL yang Anda buat pada langkah ini dapat diakses publik. Pastikan Anda telah mengonfigurasi Internet NAT Gateway untuk kelompok sumber daya DataWorks Anda seperti yang dijelaskan dalam Langkah 2. Jika tidak, Anda akan menerima error berikut saat menguji konektivitas jaringan:
HttpFile:
ErrorMessage:[Connect to dataworks-workshop-2024.oss-cn-shanghai.aliyuncs.com:443 [dataworks-workshop-2024.oss-cn-shanghai.aliyuncs.com/106.14.XX.XX] failed: connect timed out].MySQL:
ErrorMessage:[Exception:Communications link failure The last packet sent successfully to the server was 0 milliseconds ago. The driver has not received any packets from the server.<br><br>ExtraInfo:Resource Group IP:****,detail version info:mysql_all],Root Cause:[connect timed out].
Sumber data MySQL
Buat sumber data MySQL di ruang kerja Anda untuk membaca informasi pengguna yang disimpan di instans MySQL yang disediakan. Kemudian, uji konektivitas jaringan antara sumber data dan kelompok sumber daya untuk sinkronisasi data.
Masuk ke Konsol DataWorks. Di wilayah target, klik di panel navigasi sebelah kiri. Pilih ruang kerja dari daftar drop-down dan klik Go to Management Center.
Di halaman Workspace Management, klik Data Sources di panel navigasi sebelah kiri untuk membuka halaman sumber data.
Buat sumber data MySQL.
Di Management Center, buka halaman lalu klik Add Connection.
Di kotak dialog Add Data Source, cari dan pilih MySQL.
Di kotak dialog Create MySQL Data Source, konfigurasikan parameter.
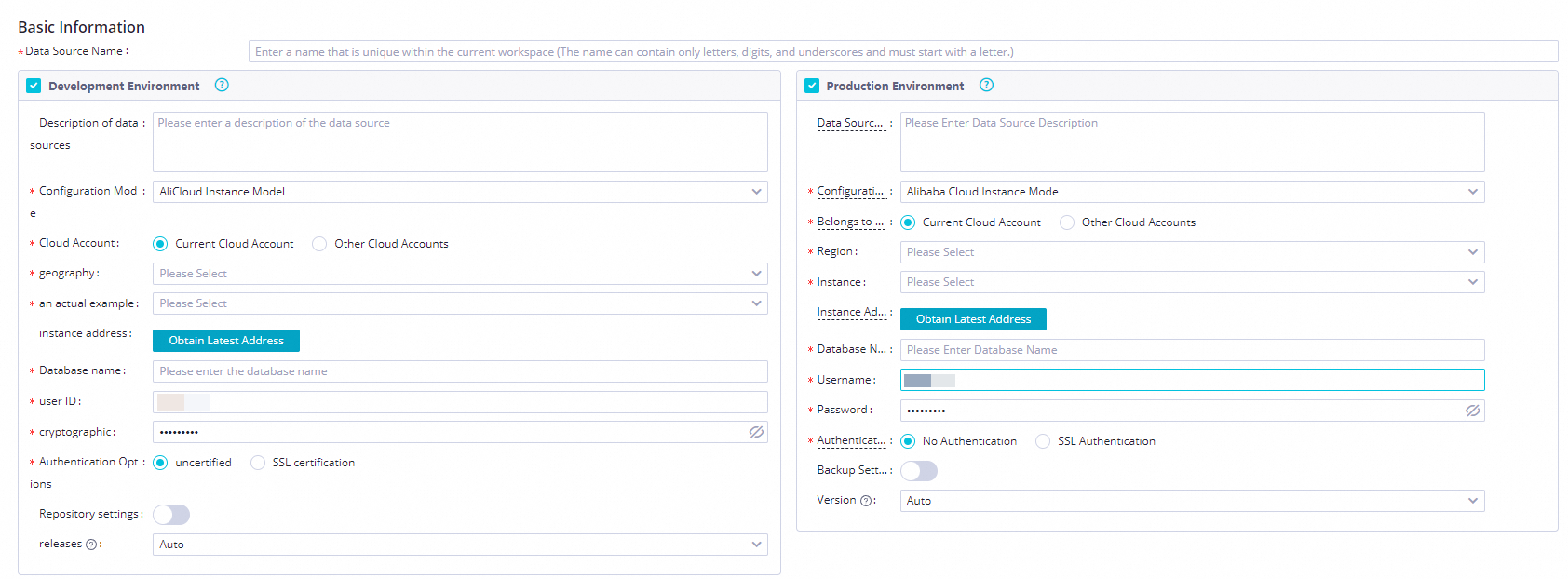
Parameter
Deskripsi
Data source name
Masukkan user_behavior_analysis_mysql.
Data source description
Sumber data khusus untuk tutorial DataWorks. Memungkinkan Anda mengakses data uji yang disediakan saat mengonfigurasi tugas sinkronisasi batch. Sumber data ini hanya dapat dibaca di Data Integration dan tidak didukung di modul lain.
Configuration mode
Pilih Connection String Mode.
Environment
Pilih Development, Production.
CatatanAnda harus membuat sumber data di lingkungan pengembangan dan lingkungan produksi. Jika tidak, terjadi error saat tugas berjalan di lingkungan produksi.
Connection address
Host IP address
rm-bp1z69dodhh85z9qa.mysql.rds.aliyuncs.comPort number
3306Database name
workshopUsername
workshopPassword
workshop#2017Authentication method
Tidak ada autentikasi.
Connection configuration
Di bagian Connection Configuration, temukan kelompok sumber daya arsitektur tanpa server. Di kolom Connected state, klik Test Connectivity untuk menguji koneksi jaringan untuk lingkungan pengembangan dan produksi. Tunggu hingga pengujian selesai dan status berubah menjadi Connectable.
PentingData uji untuk sumber data MySQL yang Anda buat pada langkah ini dapat diakses publik. Pastikan Anda telah mengonfigurasi Internet NAT Gateway untuk kelompok sumber daya DataWorks Anda seperti yang dijelaskan dalam Langkah 2. Jika tidak, Anda akan menerima error berikut saat menguji konektivitas jaringan:
ErrorMessage:[Exception:Communications link failure The last packet sent successfully to the server was 0 milliseconds ago. The driver has not received any packets from the server.<br><br>ExtraInfo:Resource Group IP:****,detail version info:mysql_all],Root Cause:[connect timed out].
Sumber data HttpFile
Buat sumber data HttpFile di ruang kerja Anda untuk membaca data uji akses website pengguna yang disimpan di OSS. Kemudian, uji konektivitas jaringan antara sumber data dan kelompok sumber daya untuk sinkronisasi data.
Masuk ke Konsol DataWorks. Di wilayah target, klik di panel navigasi sebelah kiri. Pilih ruang kerja dari daftar drop-down dan klik Go to Management Center.
Di halaman Workspace Management, klik Data Sources di panel navigasi sebelah kiri untuk membuka halaman sumber data.
Buat sumber data HttpFile.
Di Management Center, buka halaman lalu klik Add Connection.
Di kotak dialog Add Connection, cari dan pilih HttpFile.
Di kotak dialog Create HttpFile Data Source, konfigurasikan parameter. Tabel berikut menjelaskan parameter utama.
Parameter
Deskripsi
Data source name
Nama sumber data di ruang kerja Anda. Untuk tutorial ini, masukkan user_behavior_analysis_httpfile.
Data source description
Sumber data khusus untuk tutorial DataWorks. Memungkinkan Anda mengakses data uji yang disediakan saat mengonfigurasi tugas sinkronisasi batch. Sumber data ini hanya dapat dibaca di Data Integration dan tidak didukung di modul lain.
Environment
Pilih Development, Production.
CatatanAnda harus membuat sumber data di lingkungan pengembangan dan lingkungan produksi. Jika tidak, terjadi error saat tugas berjalan di lingkungan produksi.
URL domain
Masukkan
https://dataworks-workshop-2024.oss-cn-shanghai.aliyuncs.com.Connection configuration
Di bagian Connection Configuration, temukan kelompok sumber daya arsitektur tanpa server. Di kolom Connected state, klik Test Connectivity untuk menguji koneksi jaringan untuk lingkungan pengembangan dan produksi. Tunggu hingga pengujian selesai dan status berubah menjadi Connectable.
PentingData uji untuk sumber data HttpFile yang Anda buat pada langkah ini dapat diakses publik. Pastikan Anda telah mengonfigurasi Internet NAT Gateway untuk kelompok sumber daya DataWorks Anda seperti yang dijelaskan dalam Langkah 2. Jika tidak, Anda akan menerima error berikut saat menguji konektivitas jaringan:
ErrorMessage:[Connect to dataworks-workshop-2024.oss-cn-shanghai.aliyuncs.com:443 [dataworks-workshop-2024.oss-cn-shanghai.aliyuncs.com/106.14.XX.XX] failed: connect timed out].
Konfigurasi sinkronisasi data pengguna
Node sinkronisasi batch ini menyinkronkan data informasi dasar pengguna dari tabel MySQL ods_user_info_d yang disediakan dalam studi kasus ke tabel MaxCompute ods_user_info_d_odps.
Klik dua kali node sinkronisasi batch
ods_user_info_d_odpsuntuk membuka halaman pengeditan node.Konfigurasi jaringan dan sumber daya.
Konfigurasikan Data source, My Resource Group, dan Data going, lalu klik The next Step. Lakukan pengujian konektivitas sesuai permintaan. Tabel berikut menjelaskan pengaturan ini.
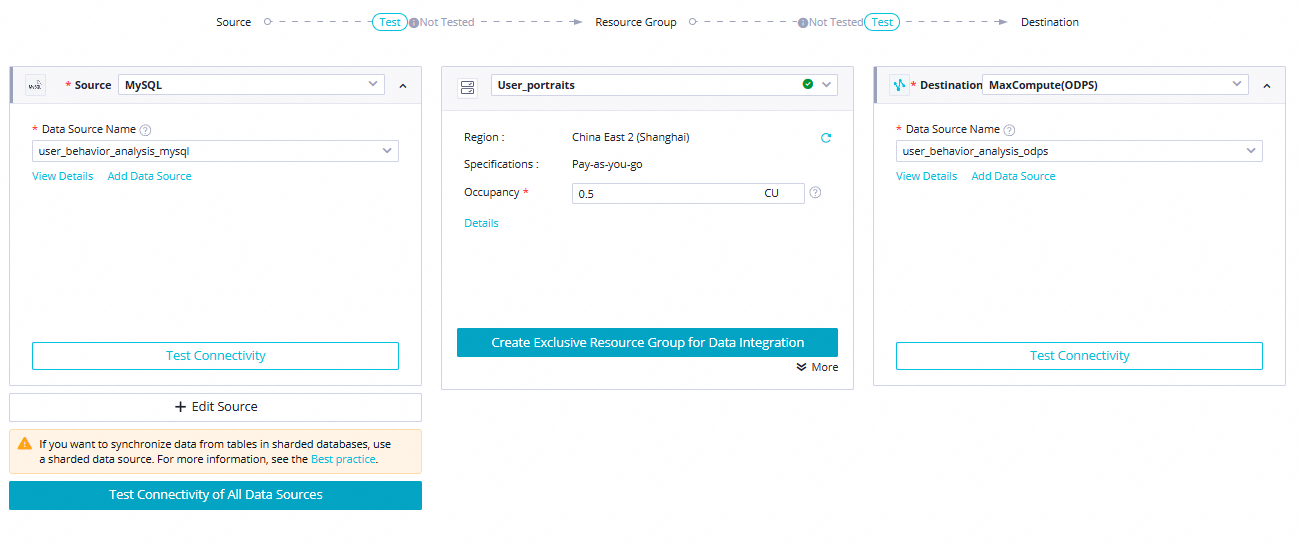
Parameter
Deskripsi
Data source
Data source:
MySQLData Source Name:
user_behavior_analysis_mysql
My Resource Group
Pilih kelompok sumber daya arsitektur tanpa server yang Anda beli pada langkah Menyiapkan lingkungan.
Data going
Data going:
MaxComputeData Source Name:
user_behavior_analysis_odps
Konfigurasi tugas.
Konfigurasikan sumber dan tujuan.
Modul
Parameter
Deskripsi
Ilustrasi
Data source
Table
Pilih tabel MySQL
ods_user_info_d.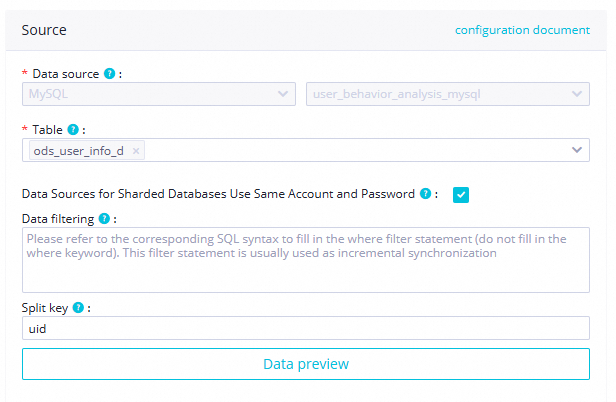
Shard Key
Gunakan primary key atau kolom terindeks sebagai split key. Split key harus berupa bidang integer.
Di sini, split key diatur ke bidang
uid.Data going
Tunnel Resource Group
Tutorial ini menggunakan Common transmission resources secara default. Jika Anda memiliki kuota tunnel eksklusif, Anda dapat memilihnya dari daftar drop-down.
CatatanUntuk informasi lebih lanjut tentang sumber daya transmisi data MaxCompute, lihat Beli dan gunakan kelompok sumber daya transmisi data eksklusif. Jika kuota tunnel eksklusif Anda tidak tersedia karena pembayaran tertunda atau kedaluwarsa, tugas secara otomatis beralih ke common transmission resources selama waktu proses.
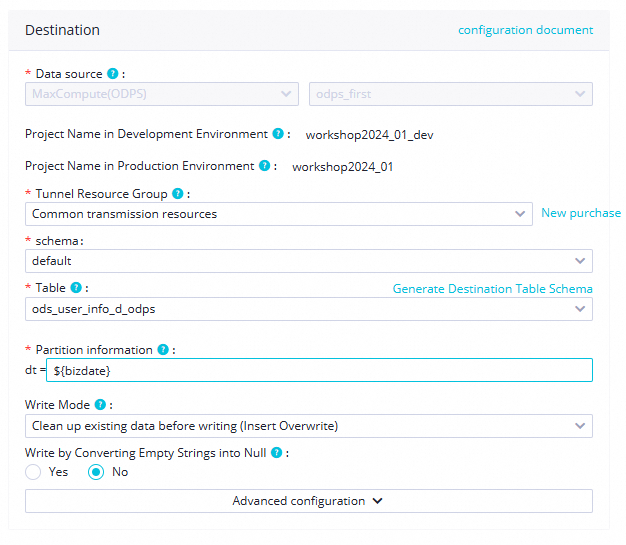
schema
Dalam tutorial ini, pilih
default. Jika proyek MaxCompute Anda memiliki skema lain, Anda dapat memilihnya dari daftar drop-down.Table
Pilih tabel
ods_user_info_d_odpsyang dibuat dalam kueri ad hoc.Partition Information
Tutorial ini menggunakan parameter
${bizdate}.Write Method
Untuk tutorial ini, pilih "Clean up existing data before writing" dari daftar drop-down.
Dua mode penulisan tersedia:
insert into: Langsung memasukkan data ke tabel atau partisi statis.insert overwrite: Menghapus data yang ada dari tabel atau partisi statis sebelum memasukkan data baru.
Write by Converting Empty Strings into Null
Untuk tutorial ini, pilih No.
Konfirmasi pemetaan bidang dan pengaturan umum.
DataWorks memungkinkan Anda memetakan bidang antara sumber dan tujuan. Anda juga dapat mengonfigurasi pengaturan untuk konkurensi baca/tulis, pembatasan laju untuk menghindari dampak pada database, penanganan data kotor, dan eksekusi tugas terdistribusi. Tutorial ini menggunakan pengaturan default. Untuk informasi lebih lanjut tentang opsi konfigurasi lainnya, lihat Konfigurasi Mode Wizard.
Properti Penjadwalan.
Di halaman konfigurasi node, klik Properties di panel navigasi sebelah kanan untuk membuka panel Scheduling Configuration. Di panel ini, konfigurasikan penjadwalan dan informasi node. Untuk informasi lebih lanjut, lihat Konfigurasi Penjadwalan Node. Tabel berikut menjelaskan konfigurasi tersebut.
Parameter
Description
Illustration
Scheduling Parameters
Anda dapat membiarkan nilai parameter penjadwalan tetap sebagai default
$bizdate.Catatanbizdate=$bizdate mengembalikan tanggal hari sebelumnya dalam format
yyyymmdd.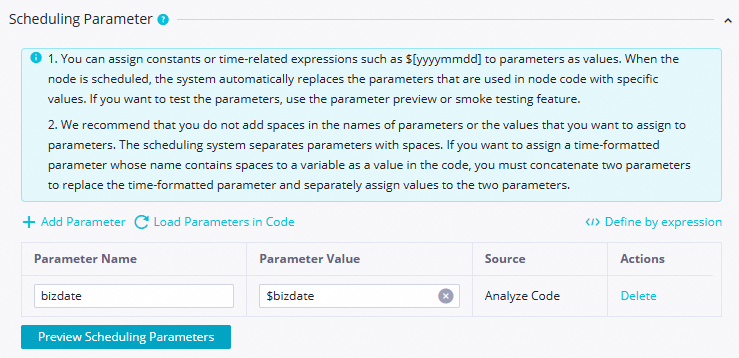
Time attribute
Scheduling period:
Day.Scheduling Time:
00:30.RUN Attribute: Allow Regardless of Running Status.
Pertahankan nilai default untuk parameter lainnya.
CatatanWaktu mulai harian node ini bergantung pada waktu terjadwal dari node virtual workshop_start. Node ini hanya berjalan setelah pukul 00:30 setiap hari.
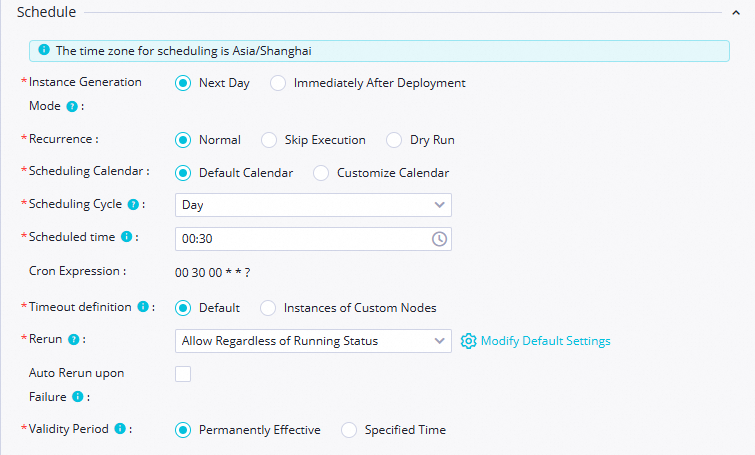
Resource Group
Pilih kelompok sumber daya serverless yang telah Anda buat pada langkah Prepare environment.

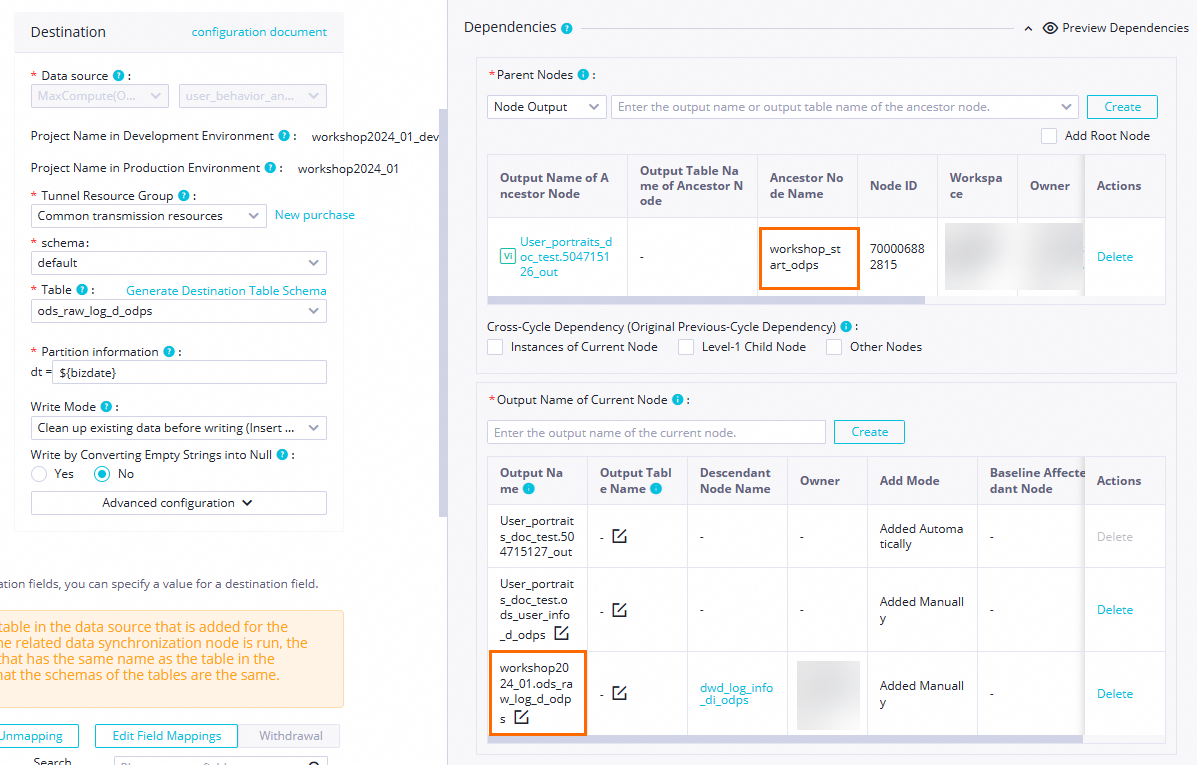
Scheduling Dependency
Konfirmasi Parent Nodes: Pastikan node
workshop_startditampilkan sebagai upstream node dari node saat ini. Dependensi hulu yang Anda konfigurasikan dengan menggambar garis akan ditampilkan di sini. Jika nodeworkshop_starttidak muncul, pastikan Anda telah menyelesaikan desain alur bisnis untuk tahap sinkronisasi data seperti yang dijelaskan dalam Design the business flow.Dalam contoh ini, node saat ini akan dipicu untuk berjalan setelah waktu terjadwal untuk node
workshop_starttercapai dan node tersebut menyelesaikan eksekusinya.Konfirmasi this node's output: periksa apakah terdapat output node bernama
MaxCompute_production_project_name.ods_user_info_d_odps. Jika output node ini tidak ada, tambahkan secara manual Node Output.
CatatanDataWorks menetapkan dependensi antar-node menggunakan output node. Untuk mempermudah tugas SQL hilir dalam memproses tabel output dari tugas sinkronisasi, Anda dapat menggunakan mekanisme automatic parsing guna menambahkan dependensi dengan cepat berdasarkan lineage tabel. Dalam kasus ini, Anda harus memastikan bahwa terdapat node output dengan nama yang sama seperti tabel output sinkronisasi, misalnya
MaxCompute_production_project_name.ods_user_info_d_odps.
Konfigurasi pipeline log pengguna
Node sinkronisasi batch ini digunakan untuk mengonfigurasi tugas sinkronisasi guna menyinkronkan informasi akses website pengguna dari objek HttpFile publik user_log.txt ke tabel MaxCompute ods_raw_log_d_odps.
Klik dua kali node sinkronisasi batch
ods_raw_log_d_odpsuntuk membuka halaman pengeditan node.Konfigurasi jaringan dan sumber daya.
Konfigurasikan Data source, My Resource Group, dan Data going. Lalu, klik The next Step dan jalankan pengujian konektivitas sesuai permintaan. Tabel berikut menjelaskan konfigurasi tersebut.
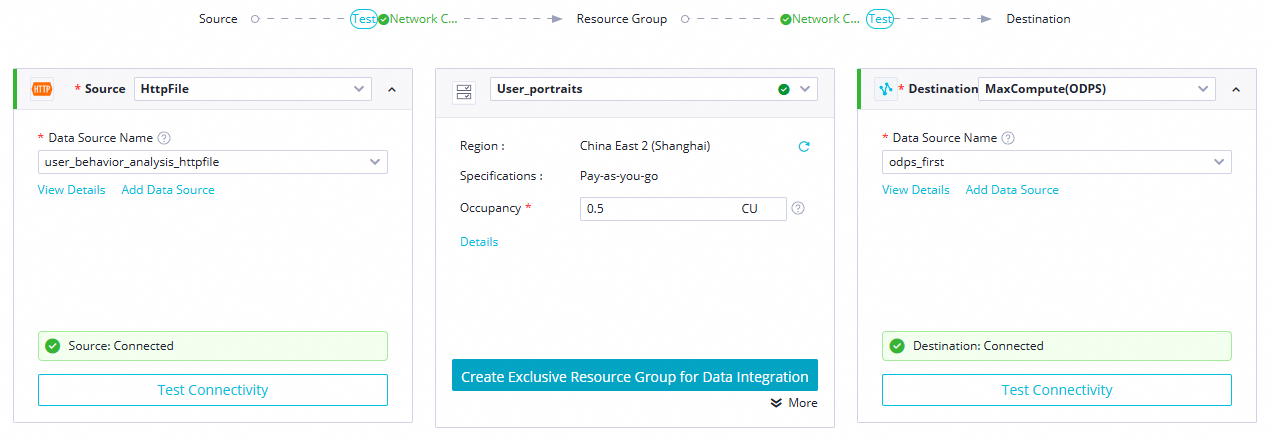
Parameter
Deskripsi
Data source
Data source:
HttpFileData Source Name:
user_behavior_analysis_HttpFile
My Resource Group
Pilih kelompok sumber daya arsitektur tanpa server yang Anda beli pada langkah Menyiapkan lingkungan.
Data going
Data going:
MaxComputeData Source Name:
user_behavior_analysis_odps
Konfigurasi tugas.
Konfigurasikan sumber dan tujuan.
Modul
Parameter
Deskripsi
Ilustrasi
Data source
File Path
Dalam tutorial ini, masukkan
/user_log.txt.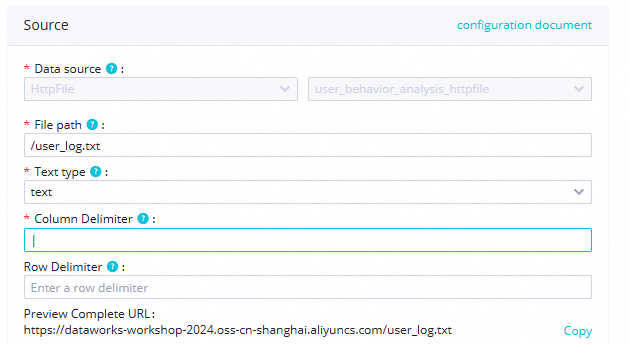
File Type
Pilih tipe
text.Field Delimiter
Dalam tutorial ini, masukkan:
|.Advanced Configuration
Encoding
Pilih format encoding
UTF-8.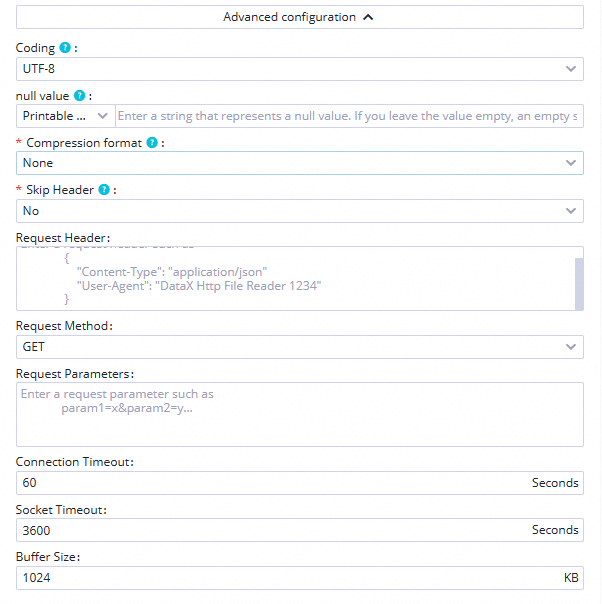
Compression Format
Pilih format
None.Skip Header
Pilih
Nountuk tidak melewatkan header tabel.Data going
Tunnel Resource Group
Tutorial ini menggunakan common transmission resources secara default. Jika Anda memiliki kuota Tunnel eksklusif, Anda dapat memilihnya dari daftar drop-down.
CatatanUntuk informasi tentang memilih sumber daya transmisi data untuk MaxCompute, lihat Beli dan gunakan kelompok sumber daya layanan transmisi data eksklusif. Jika kuota Tunnel eksklusif tidak tersedia karena pembayaran tertunda atau kedaluwarsa, tugas secara otomatis beralih ke common transmission resources selama berjalan.
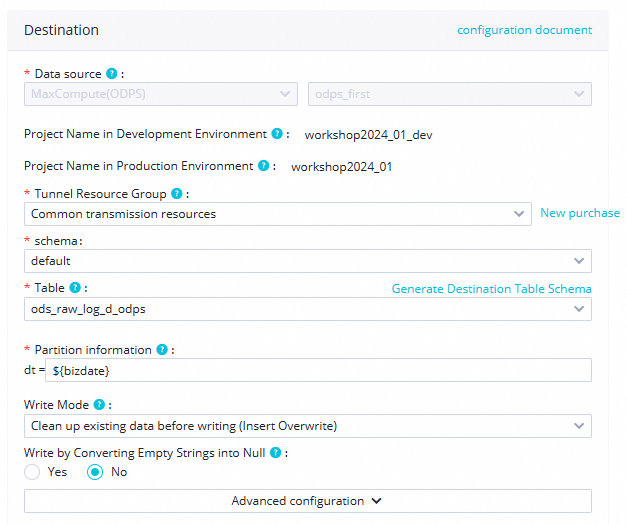
Schema
Untuk tutorial ini, pilih skema default. Jika proyek DataWorks Anda memiliki skema lain, Anda dapat memilihnya dari daftar drop-down.
Table
Dari daftar drop-down, pilih tabel
ods_raw_log_d_odpsyang dibuat dalam kueri ad-hoc.Partition Information
Tutorial ini menggunakan parameter
${bizdate}.Write Method
Untuk tutorial ini, pilih Clean up existing data before writing.
Mode penulisan berikut didukung:
insert into: Langsung memasukkan data ke tabel atau partisi statis.insert overwrite: Menghapus data yang ada dari tabel atau partisi statis sebelum memasukkan data baru.
Write by Converting Empty Strings into Null
Untuk tutorial ini, pilih No.
Setelah mengonfigurasi sumber, klik Confirm Data Structure untuk memverifikasi bahwa DataWorks dapat membaca file log dengan benar.
Konfirmasi pemetaan bidang dan pengaturan umum.
DataWorks memungkinkan Anda memetakan bidang sumber ke bidang tujuan. Fitur-fitur seperti paralelisme, pembatasan laju (untuk menghindari dampak pada database Anda), penanganan data kotor, dan eksekusi tugas terdistribusi juga tersedia. Untuk tutorial ini, gunakan pengaturan default. Untuk informasi lebih lanjut tentang opsi konfigurasi lainnya, lihat Konfigurasi tugas sinkronisasi batch dalam mode wizard.
Konfigurasi properti penjadwalan.
Di halaman konfigurasi, klik Scheduling configuration di panel sisi kanan. Pada panel Scheduling Configuration, atur penjadwalan dan informasi node. Untuk informasi selengkapnya, lihat Konfigurasikan properti penjadwalan untuk sebuah node. Tabel berikut menjelaskan konfigurasi tersebut.
Parameter
Deskripsi
Ilustrasi
Scheduling Parameters
Anda dapat membiarkan nilai parameter penjadwalan sebagai default
$bizdate.Catatanbizdate=$bizdate mengembalikan tanggal hari sebelumnya dalam format
yyyymmdd.Time attribute
Scheduling period:
Day.Scheduling Time:
00:30.RUN Attribute: Allow Regardless of Running Status.
Pertahankan nilai default untuk parameter lainnya.
CatatanWaktu mulai harian node ini bergantung pada waktu terjadwal node virtual workshop_start. Node ini hanya berjalan setelah pukul 00:30 setiap hari.
Resource Group
Pilih kelompok sumber daya arsitektur tanpa server yang Anda buat pada tahap Menyiapkan lingkungan.
Scheduling Dependency
Konfirmasi Parent Nodes: Verifikasi bahwa node
workshop_startditampilkan sebagai upstream node dari node saat ini. Dependensi hulu yang dikonfigurasi dengan menghubungkan node akan ditampilkan di bagian ini. Jika nodeworkshop_starttidak ditampilkan, pastikan Anda telah menyelesaikan desain alur bisnis untuk tahap sinkronisasi data bisnis seperti yang dijelaskan dalam Rancang alur bisnis.Dalam contoh ini, ketika waktu terjadwal untuk node
workshop_starttercapai dan eksekusinya selesai, node saat ini dipicu untuk berjalan.Konfirmasi the node output: Periksa apakah ada output node bernama
YourMaxComputeProjectName.ods_raw_log_d_odps. Jika output node tidak ada, Anda harus menambahkan secara manual Node Output.
CatatanDataWorks menggunakan output node untuk menetapkan dependensi node. Saat tugas SQL hilir memproses tabel output dari tugas sinkronisasi, mekanisme penguraian otomatis menggunakan lineage tabel untuk menambahkan tugas sinkronisasi sebagai dependensi untuk node SQL dengan cepat. Agar mekanisme ini berfungsi, Anda harus memastikan bahwa node output ada dengan nama yang sama seperti tabel output sinkronisasi:
MaxCompute production project name.ods_raw_log_d_odps.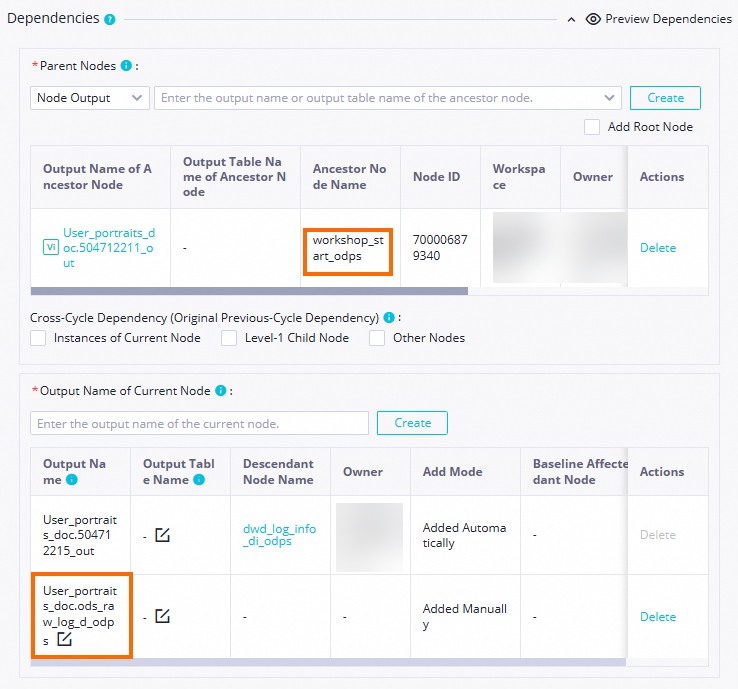
Langkah 3: Jalankan dan lihat hasil
Jalankan alur bisnis
Di halaman DataStudio, klik dua kali
user_profile_analysis_MaxComputedi bawah Workflow untuk membuka panel Workflow, lalu klik ikon di bilah alat untuk menjalankan alur kerja sesuai dependensi hulu dan hilirnya.
di bilah alat untuk menjalankan alur kerja sesuai dependensi hulu dan hilirnya.Periksa status eksekusi:
Periksa status node: Status
 menunjukkan bahwa proses eksekusi sinkron tidak memiliki masalah.
menunjukkan bahwa proses eksekusi sinkron tidak memiliki masalah.Untuk melihat log eksekusi tugas, klik kanan node
ods_user_info_d_odpsatauods_raw_log_d_odpsdan pilih View Logs. Ketika teks berikut muncul di log, itu menunjukkan bahwa node sinkronisasi berhasil dijalankan dan data berhasil disinkronkan.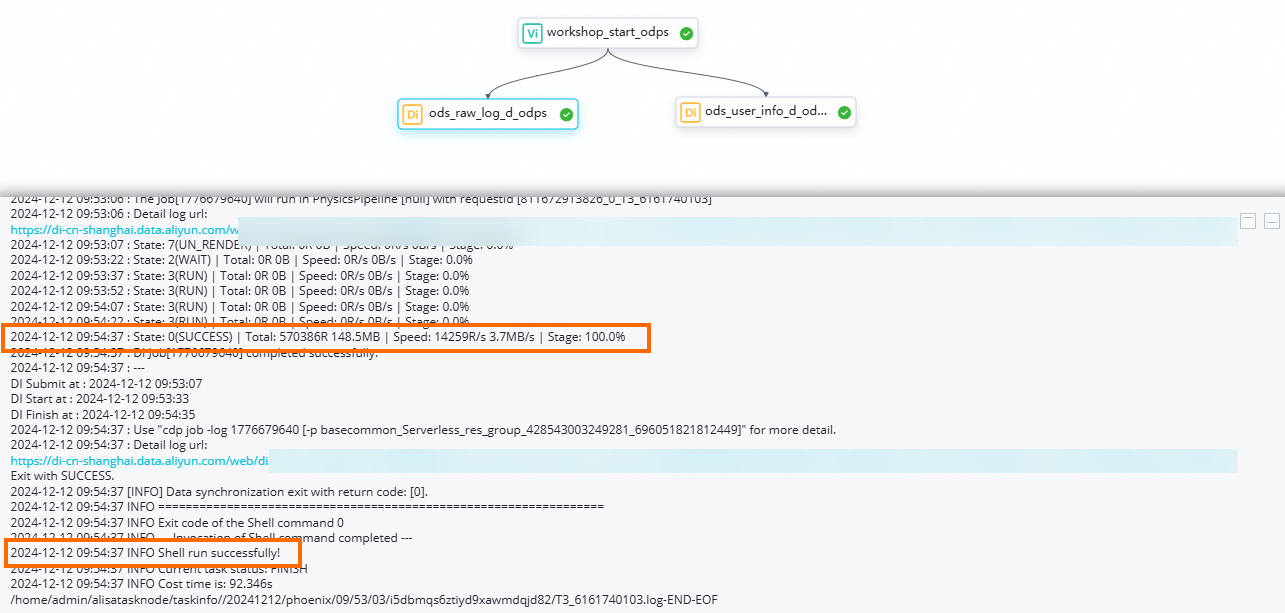
Lihat hasil sinkronisasi
Menjalankan alur kerja bisnis diharapkan dapat menyinkronkan sepenuhnya data dari tabel informasi dasar pengguna ods_user_info_d di MySQL ke partisi kemarin dari tabel workshop2024_01_dev.ods_user_info_d_odps, dan log akses website pengguna dari file user_log.txt di OSS ke partisi kemarin dari tabel workshop2024_01_dev.ods_raw_log_d_odps. Karena kueri SQL tidak perlu dijalankan di lingkungan produksi, Anda dapat membuat file kueri ad hoc untuk memverifikasi hasilnya.
Buat file kueri ad hoc.
Di panel navigasi sebelah kiri halaman DataStudio, klik ikon
 untuk membuka panel Ad Hoc Query. Klik kanan Ad Hoc Query dan pilih .
untuk membuka panel Ad Hoc Query. Klik kanan Ad Hoc Query dan pilih .Kueri tabel hasil sinkronisasi.
Jalankan pernyataan SQL berikut untuk memverifikasi hasil sinkronisasi data. Periksa jumlah catatan yang diimpor ke
ods_raw_log_d_odpsdanods_user_info_d_odps.// Ganti 'your_data_timestamp' dengan timestamp data aktual, yaitu hari sebelum tanggal eksekusi tugas (misalnya, gunakan 20230620 jika tugas dijalankan pada 20230621). select count(*) from ods_user_info_d_odps where dt='your_data_timestamp'; select count(*) from ods_raw_log_d_odps where dt='your_data_timestamp';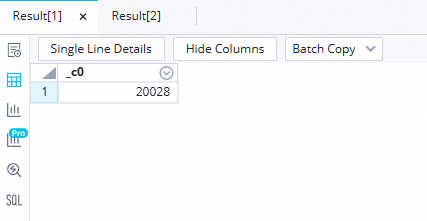 Catatan
CatatanDalam tutorial ini, Anda menjalankan node di DataStudio, yaitu lingkungan pengembangan. Oleh karena itu, data secara default ditulis ke tabel di proyek
workshop2024_01_dev, yaitu proyek mesin komputasi untuk lingkungan ini.
Langkah selanjutnya
Sekarang Anda telah menyelesaikan sinkronisasi data, tutorial berikutnya menunjukkan cara memproses informasi dasar pengguna dan log akses website pengguna di MaxCompute. Untuk informasi lebih lanjut, lihat Proses data.