Data Integration memungkinkan Anda melakukan sinkronisasi penuh dan inkremental seluruh database dari sumber seperti ApsaraDB for OceanBase, MySQL, Oracle, dan PolarDB ke MaxCompute. Proses ini menggabungkan migrasi data penuh awal dengan sinkronisasi real-time berkelanjutan untuk data inkremental, yang kemudian digabungkan ke tujuan setiap hari (T+1). Topik ini menggunakan contoh sinkronisasi dari MySQL ke MaxCompute untuk menunjukkan cara membuat tugas sinkronisasi penuh dan inkremental.
Cara kerja
Tugas sinkronisasi penuh dan inkremental menggunakan proses terpadu untuk melakukan muatan penuh awal data historis, lalu terus-menerus menyinkronkan data inkremental. Setelah tugas dimulai, sistem secara otomatis membuat dan mengoordinasikan subtask offline dan real-time untuk menggabungkan data ke tabel tujuan, yang disebut tabel dasar (base table).
Proses intinya terdiri dari tiga fase:
Muatan penuh awal: Saat tugas dimulai, tugas sinkronisasi batch dijalankan terlebih dahulu untuk memigrasikan struktur tabel dan data historis dari semua tabel di database sumber ke tabel dasar tujuan di MaxCompute. Setelah muatan penuh awal selesai, tugas sinkronisasi batch ini dihentikan sementara.
Sinkronisasi data inkremental: Setelah migrasi penuh, sistem menjalankan tugas sinkronisasi real-time yang terus-menerus menangkap perubahan data inkremental (operasi Insert, Update, dan Delete) dari database sumber—misalnya, dari binary log (binlog) MySQL—dan menuliskannya ke tabel log sementara di MaxCompute dalam waktu nyaris real-time.
Penggabungan berkala: Sistem secara otomatis menjalankan tugas Merge setiap hari (T+1) untuk menggabungkan data inkremental yang terakumulasi di tabel log dari hari sebelumnya (T) dengan data penuh di tabel dasar. Proses ini menghasilkan snapshot lengkap terbaru dari data untuk hari T dan menuliskannya ke partisi baru di tabel dasar. Tugas merge dijalankan sekali per hari.
Diagram berikut menggambarkan alur data saat menulis ke tabel partisi:

Tugas ini memiliki fitur-fitur berikut:
Pemetaan tabel many-to-many atau many-to-one: Anda dapat menyinkronkan beberapa tabel sumber ke tabel tujuan masing-masing atau menggabungkan data dari beberapa tabel sumber ke satu tabel tujuan menggunakan aturan pemetaan.
Komposisi tugas: Tugas sinkronisasi penuh dan inkremental terdiri dari subtask sinkronisasi batch untuk muatan penuh awal, subtask sinkronisasi real-time untuk data inkremental, dan tugas Merge untuk konsolidasi data.
Dukungan tabel tujuan: Anda dapat menulis data ke tabel partisi maupun non-partisi di MaxCompute.
Batasan
Persyaratan resource: Tugas ini memerlukan Serverless resource group. Untuk sinkronisasi berbasis instans, spesifikasi resource minimum adalah grup sumber daya eksklusif untuk Data Integration dengan 8-core dan 16 GB serta 2 CU untuk Serverless resource group.
Konektivitas jaringan: Pastikan konektivitas jaringan antara resource group Data Integration dan kedua sumber data (misalnya, MySQL dan MaxCompute). Untuk informasi lebih lanjut, lihat Solusi konektivitas jaringan.
Batasan wilayah: Sinkronisasi hanya didukung ke sumber data MaxCompute buatan pengguna yang berada di Wilayah yang sama dengan ruang kerja DataWorks saat ini. Saat menggunakan sumber data MaxCompute buatan pengguna, Anda tetap harus menyambungkan resource komputasi MaxCompute di bagian Data Development ruang kerja DataWorks Anda. Jika tidak, Anda tidak dapat membuat node SQL MaxCompute, dan pembuatan node 'done' sinkronisasi penuh akan gagal.
Batasan resource group penjadwalan: Tugas ini menggunakan Serverless resource group yang dikonfigurasi sebagai resource group penjadwalan.
Batasan jenis tabel tujuan: Anda tidak dapat menyinkronkan data ke tabel eksternal MaxCompute.
Penting
Persyaratan primary key: Tabel tanpa primary key tidak dapat disinkronkan. Untuk tabel yang tidak memiliki primary key, Anda harus secara manual menentukan satu atau beberapa kolom sebagai primary key bisnis menggunakan opsi Specify Primary Key selama konfigurasi.
Penundaan visibilitas data: Setelah Anda mengonfigurasi tugas sinkronisasi penuh dan inkremental ke MaxCompute, hanya data historis yang tersedia untuk kueri pada hari yang sama. Data inkremental baru dapat dikueri di MaxCompute setelah tugas Merge selesai pada hari berikutnya. Untuk informasi lebih lanjut, lihat deskripsi penggabungan berkala di bagian Cara kerja.
Penyimpanan dan siklus hidup: Tugas sinkronisasi penuh dan inkremental membuat partisi penuh baru setiap hari. Untuk mencegah konsumsi penyimpanan berlebihan, tabel MaxCompute yang dibuat otomatis oleh tugas sinkronisasi memiliki siklus hidup default 30 hari. Jika durasi ini tidak sesuai dengan kebutuhan bisnis Anda, Anda dapat mengubah siklus hidup dengan mengklik nama tabel MaxCompute yang sesuai selama konfigurasi tugas. Untuk informasi lebih lanjut, lihat Edit struktur tabel tujuan (opsional).
SLA: Data Integration menggunakan saluran data MaxCompute untuk unggah dan unduh data. Untuk informasi lebih lanjut tentang perjanjian tingkat layanan (SLA) saluran data sinkronisasi, lihat Skenario dan alat untuk Data Transfer Service (Upload). Evaluasi pilihan teknis Anda berdasarkan SLA saluran data MaxCompute.
Kebijakan retensi binlog: Sinkronisasi real-time bergantung pada binary log (binlog) database sumber MySQL. Pastikan periode retensi binlog cukup untuk mencegah kegagalan sinkronisasi. Jika tugas dijeda lama atau mencoba ulang setelah kegagalan, tugas tersebut mungkin gagal menemukan posisi awal jika binlog yang diperlukan telah dipurge.
Penagihan
Tugas sinkronisasi penuh dan inkremental mencakup tugas sinkronisasi batch untuk fase muatan penuh, tugas sinkronisasi real-time untuk fase inkremental, dan tugas berkala untuk fase penggabungan berkala. Ketiga tugas ini ditagih secara terpisah dan mengonsumsi CU dari resource group. Untuk informasi lebih lanjut tentang penagihan, lihat Penagihan Serverless resource groups. Tugas berkala juga dikenakan biaya penjadwalan. Untuk informasi lebih lanjut, lihat Biaya instans penjadwalan.
Selain itu, proses sinkronisasi ke MaxCompute memerlukan penggabungan berkala data penuh dan inkremental, yang mengonsumsi resource komputasi MaxCompute. Biaya ini ditagih langsung oleh MaxCompute dan sebanding dengan ukuran dataset penuh serta frekuensi penggabungan. Untuk informasi lebih lanjut, lihat Item penagihan dan harga.
Prosedur
Langkah 1: Pilih jenis tugas sinkronisasi
Buka halaman Data Integration.
Masuk ke Konsol DataWorks. Di bilah navigasi atas, pilih wilayah yang diinginkan. Di panel navigasi kiri, pilih . Di halaman yang muncul, pilih ruang kerja yang diinginkan dari daftar drop-down dan klik Go to Data Integration.
Di panel navigasi kiri, klik Synchronization Task. Di bagian atas halaman, klik Create Synchronization Task dan konfigurasikan parameter berikut:
Source Type:
MySQL.Destination Type:
MaxCompute.Specific Type:
Full and Incremental for Entire Database.Sync Procedure: Schema Migration, Incremental Sync, Full Synchronization, dan Periodic Merge.
Langkah 2: Mengonfigurasi sumber data dan kelompok sumber daya
Untuk Source Information, pilih sumber data
MySQL. Untuk Destination, pilih sumber dataMaxCompute.Di bagian Running Resources, pilih Resource Group untuk tugas sinkronisasi dan alokasikan Resource Group untuk CU. Anda dapat mengatur CU secara terpisah untuk sinkronisasi penuh dan inkremental guna mengontrol resource secara tepat dan mencegah pemborosan.
CatatanDataWorks mengirimkan tugas sinkronisasi batch ke resource group eksekusi Data Integration melalui resource group penjadwalan. Akibatnya, tugas offline mengonsumsi resource dari kedua resource group tersebut, dengan resource group penjadwalan dikenakan biaya penjadwalan.
Pastikan kedua sumber data (sumber dan tujuan) lulus pemeriksaan Connectivity Check.
Langkah 3: Pilih tabel sumber
Di area Source Table, pilih tabel yang akan disinkronkan dari sumber data. Klik ikon ![]() untuk memindahkan tabel ke daftar Selected Tables.
untuk memindahkan tabel ke daftar Selected Tables.
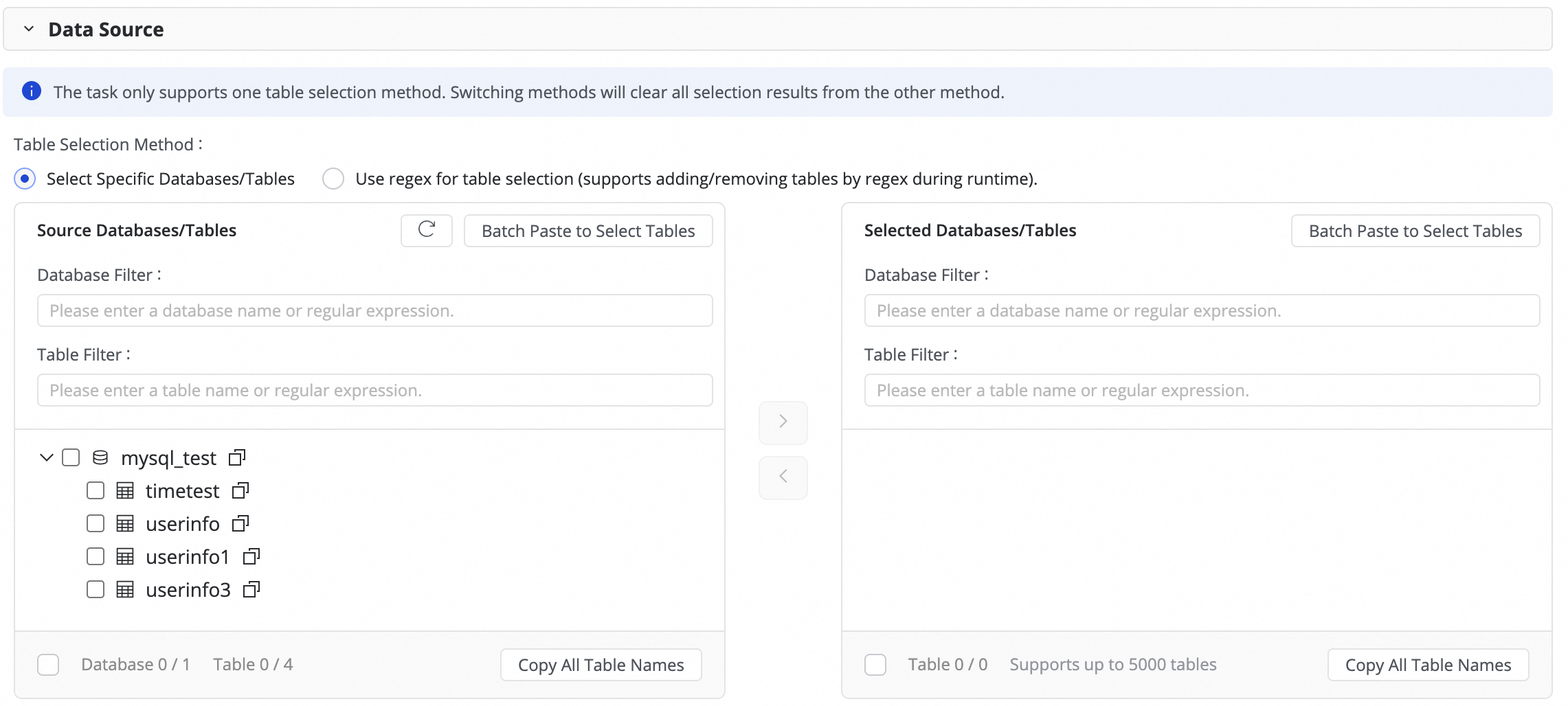
Jika Anda memiliki banyak tabel, Anda dapat menggunakan Database Filtering, Search for Tables, atau mengonfigurasi ekspresi reguler untuk memilih tabel yang diperlukan.
Langkah 4: Konfigurasikan pengaturan tugas
Log table time range: Parameter ini menentukan rentang waktu untuk mengkueri data dari tabel log agar digabungkan ke partisi tujuan.
Untuk mencegah kesalahan partisi lintas hari akibat latensi data, perluas rentang ini sedikit. Hal ini memastikan bahwa semua data untuk partisi digabungkan dengan benar.
Merge task scheduling: Atur jadwal untuk tugas Merge harian. Untuk informasi lebih lanjut tentang cara mengonfigurasi penjadwalan, lihat Scheduling configuration.
Periodic scheduling parameters: Atur parameter penjadwalan yang nantinya dapat digunakan untuk memberikan nilai ke partisi. Hal ini memungkinkan Anda membuat partisi secara otomatis berdasarkan tanggal.
Table partition settings: Konfigurasikan partisi untuk tabel tujuan. Anda dapat mengatur parameter utama seperti nama kolom partisi dan metode pemberian nilai. Untuk kolom pemberian nilai, Anda dapat menggunakan parameter penjadwalan untuk menghasilkan partisi secara otomatis berdasarkan tanggal.
Langkah 5: Konfigurasikan pemetaan tabel tujuan
Pada langkah ini, Anda menentukan aturan pemetaan antara tabel sumber dan tujuan. Anda juga menentukan aturan untuk primary key, partisi dinamis, dan konfigurasi DDL/DML untuk menentukan cara penulisan data.
Aksi | Deskripsi | ||||||||||||
Refresh | Sistem secara otomatis mencantumkan tabel sumber yang Anda pilih. Namun, Anda harus merefresh pemetaan agar properti tabel tujuan berlaku.
| ||||||||||||
Customize Mapping Rules for Destination Table Names (Opsional) | Sistem memiliki aturan penamaan tabel default:
Fitur ini mendukung skenario berikut:
| ||||||||||||
Edit Mapping of Field Data Types (Opsional) | Sistem menyediakan pemetaan default antara tipe data field sumber dan tujuan. Anda dapat mengklik Edit Mapping of Field Data Types di pojok kanan atas tabel untuk menyesuaikan pemetaan. Setelah dikonfigurasi, klik Apply and Refresh Mapping. Saat mengedit pemetaan tipe data, pastikan aturan konversinya benar. Aturan yang salah dapat menyebabkan kegagalan konversi tipe, menghasilkan data kotor, dan mengganggu eksekusi tugas. | ||||||||||||
Edit Destination Table Structure (Opsional) | Sistem secara otomatis membuat tabel tujuan jika belum ada, atau menggunakan tabel yang sudah ada dengan nama yang sama, berdasarkan aturan pemetaan nama tabel kustom Anda. DataWorks secara otomatis menghasilkan struktur tabel tujuan berdasarkan struktur tabel sumber. Dalam kebanyakan kasus, tidak diperlukan intervensi manual. Anda juga dapat memodifikasi struktur tabel dengan cara berikut:
Untuk tabel yang sudah ada, Anda hanya dapat menambahkan field. Untuk tabel baru, Anda dapat menambahkan field, field partisi, serta mengatur tipe atau properti tabel. Untuk informasi lebih lanjut, lihat bagian yang dapat diedit di UI. | ||||||||||||
Value assignment | Field native dipetakan secara otomatis berdasarkan kecocokan nama field antara tabel sumber dan tujuan. Anda harus secara manual memberikan nilai untuk field baru yang ditambahkan pada langkah sebelumnya. Untuk melakukannya:
Anda dapat memberikan konstanta atau variabel. Alihkan tipe di daftar drop-down Value Type. Metode berikut didukung:
| ||||||||||||
Source Split PK | Dari daftar drop-down Source Split PK, Anda dapat memilih field dari tabel sumber atau memilih Not Split. Saat tugas sinkronisasi dijalankan, tugas tersebut akan dibagi menjadi beberapa subtask berdasarkan field ini untuk membaca data secara konkuren. Gunakan field dengan distribusi data merata, seperti primary key, sebagai kolom split. Tipe string, float, dan date tidak didukung. Saat ini, fitur Source Split PK hanya didukung ketika sumbernya adalah MySQL. | ||||||||||||
Execute Full Synchronization | Jika Anda telah mengonfigurasi sinkronisasi data penuh di langkah 3, Anda dapat menghapus centang opsi ini untuk melewati sinkronisasi data penuh untuk tabel tertentu. Ini berguna jika Anda telah menyinkronkan dataset penuh ke tujuan menggunakan metode lain. | ||||||||||||
Full condition | Terapkan kondisi filter ke sumber selama fase muatan penuh. Masukkan hanya konten klausa WHERE, tanpa kata kunci | ||||||||||||
Configure DML Rule | Gunakan pemrosesan pesan DML untuk memfilter dan mengontrol perubahan data yang ditangkap ( | ||||||||||||
Full Data Merge Cycle | Saat ini, hanya penggabungan harian yang didukung. Anda dapat mengonfigurasi waktu penjadwalan spesifik untuk tugas penggabungan di pengaturan Custom merge time. | ||||||||||||
Merge Primary Key | Anda dapat menentukan primary key dengan memilih satu atau beberapa kolom dari tabel.
|
 dan menggabungkan opsi dari Manual Input dan Built-in Variable. Variabel tersebut mencakup nama sumber data sumber, nama database sumber, dan nama tabel sumber.
dan menggabungkan opsi dari Manual Input dan Built-in Variable. Variabel tersebut mencakup nama sumber data sumber, nama database sumber, dan nama tabel sumber.

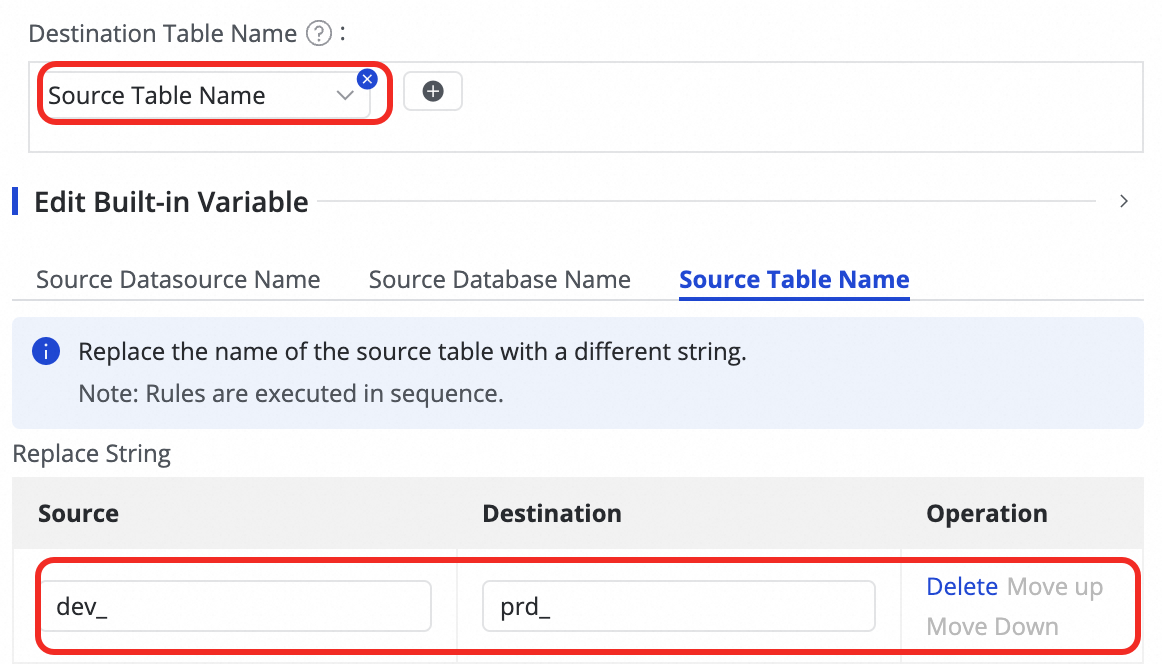


 di kolom Destination Table Name untuk menambahkan field.
di kolom Destination Table Name untuk menambahkan field.Langkah 6: Konfigurasikan pengaturan lanjutan
Konfigurasi parameter lanjutan
Untuk menyesuaikan tugas secara detail dan memenuhi kebutuhan sinkronisasi kustom, buka tab Advanced Parameters untuk memodifikasi parameter lanjutan.
Di pojok kanan atas halaman, klik Advanced configuration untuk membuka halaman konfigurasi parameter lanjutan.
Ubah nilai parameter berdasarkan tooltip. Penjelasan untuk setiap parameter ditampilkan di sebelah namanya.
Anda juga dapat menggunakan konfigurasi berbasis AI. Masukkan perintah dalam bahasa alami, seperti menyesuaikan konkurensi tugas, dan model AI akan menghasilkan rekomendasi nilai parameter. Anda kemudian dapat memilih apakah akan menerima parameter yang dihasilkan AI tersebut.
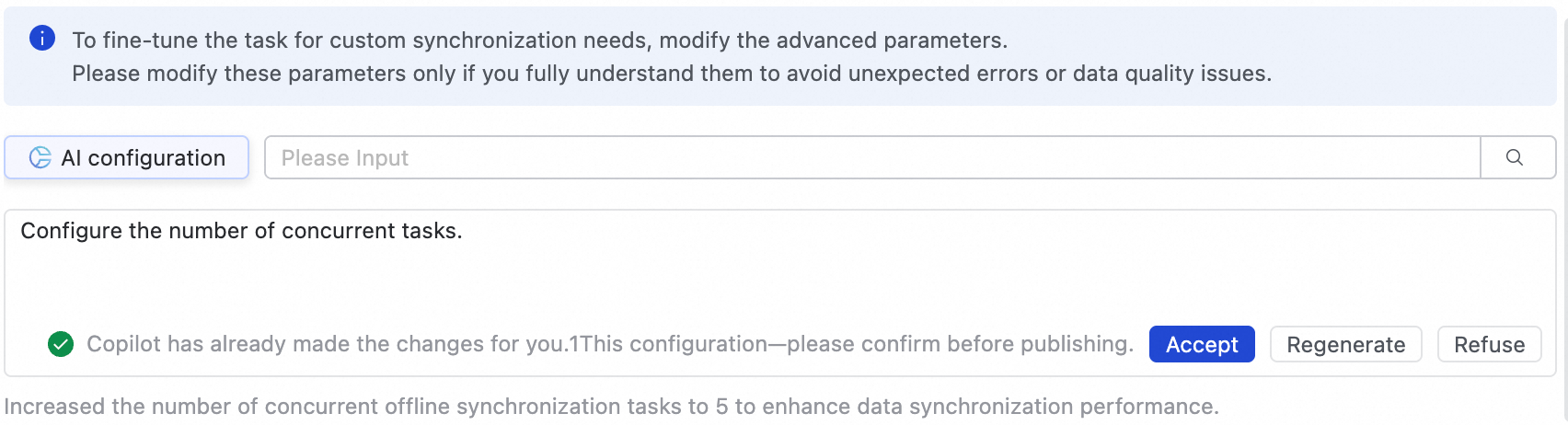
Modifikasi parameter ini hanya jika Anda benar-benar memahami tujuannya. Perubahan yang salah dapat menyebabkan masalah tak terduga seperti penundaan tugas, konsumsi resource berlebihan yang menghambat tugas lain, atau kehilangan data.
Konfigurasi kemampuan DDL
Beberapa pipeline sinkronisasi real-time dapat mendeteksi perubahan metadata pada struktur tabel sumber dan memberi tahu tujuan. Tujuan kemudian dapat memperbarui dirinya sesuai atau mengambil tindakan lain, seperti mengirim peringatan, mengabaikan perubahan, atau menghentikan tugas.
Di pojok kanan atas halaman, klik Configure DDL Capability untuk mengatur kebijakan penanganan untuk setiap jenis perubahan. Kebijakan yang didukung bervariasi tergantung pada saluran.
Normal: Tujuan memproses perubahan DDL dari sumber.
Ignore: Pesan perubahan diabaikan, dan tujuan tidak dimodifikasi.
Error: Tugas sinkronisasi real-time untuk seluruh database dihentikan, dan statusnya diatur ke Error.
Alert: Peringatan dikirim ke pengguna saat jenis perubahan ini terjadi di sumber. Anda harus mengonfigurasi aturan notifikasi DDL di pengaturan Configure Alert Rule.
Saat kolom baru ditambahkan di sumber dan juga dibuat di tujuan melalui sinkronisasi DDL, sistem tidak melakukan pengisian ulang data untuk baris yang sudah ada di tabel tujuan.
Langkah 7: Jalankan tugas sinkronisasi
Setelah konfigurasi tugas sinkronisasi selesai, klik Complete di bagian bawah halaman.
Di bagian Synchronization Task halaman Data Integration, temukan tugas sinkronisasi yang telah dibuat dan klik Deploy di kolom Operation. Jika Anda memilih Start immediately after deployment, tugas akan berjalan segera setelah Anda mengklik Confirm; jika tidak, Anda perlu menjalankannya secara manual.
CatatanTugas Data Integration harus diterapkan ke lingkungan produksi agar dapat dijalankan, sehingga tugas yang baru dibuat atau diedit hanya akan berlaku setelah diterapkan.
Klik Name/ID tugas sinkronisasi di bagian Tasks dan lihat proses berjalan rinci dari tugas sinkronisasi tersebut.
Langkah selanjutnya
Setelah mengonfigurasi tugas, Anda dapat mengelolanya, menambah atau menghapus tabel, mengonfigurasi pemantauan dan peringatan, serta melihat metrik operasional utama. Untuk informasi lebih lanjut, lihat O&M untuk tugas sinkronisasi penuh dan inkremental.
FAQ
Q: Mengapa data di tabel dasar tidak diperbarui seperti yang diharapkan?
A: Hal ini dapat terjadi karena beberapa alasan. Lihat tabel di bawah untuk penyebab umum dan solusinya.

Gejala | Penyebab | Solusi |
Pemeriksaan output data untuk partisi T-1 di tabel log inkremental gagal. | Kegagalan tugas sinkronisasi real-time mencegah pembuatan data untuk partisi T-1 di tabel log inkremental. |
|
Pemeriksaan output data untuk partisi T-2 di tabel dasar tujuan gagal. |
|
|