Seiring semakin meluasnya penggunaan model bahasa besar (LLM), tantangan utama bagi bisnis adalah menerapkan dan mengelolanya secara efisien, andal, dan dalam skala besar di lingkungan produksi. Cloud-native AI Serving Stack merupakan solusi end-to-end yang dibangun di atas Container Service for Kubernetes dan dirancang khusus untuk inferensi AI berbasis cloud-native. Stack ini mencakup seluruh siklus hidup inferensi LLM serta menyediakan fitur terintegrasi seperti manajemen penerapan, perutean pintar, penskalaan otomatis, dan observabilitas mendalam. Cloud-native AI Serving Stack membantu Anda mengelola skenario inferensi AI berbasis cloud-native yang kompleks, baik saat memulai maupun menjalankan operasi AI berskala besar.
Fitur inti
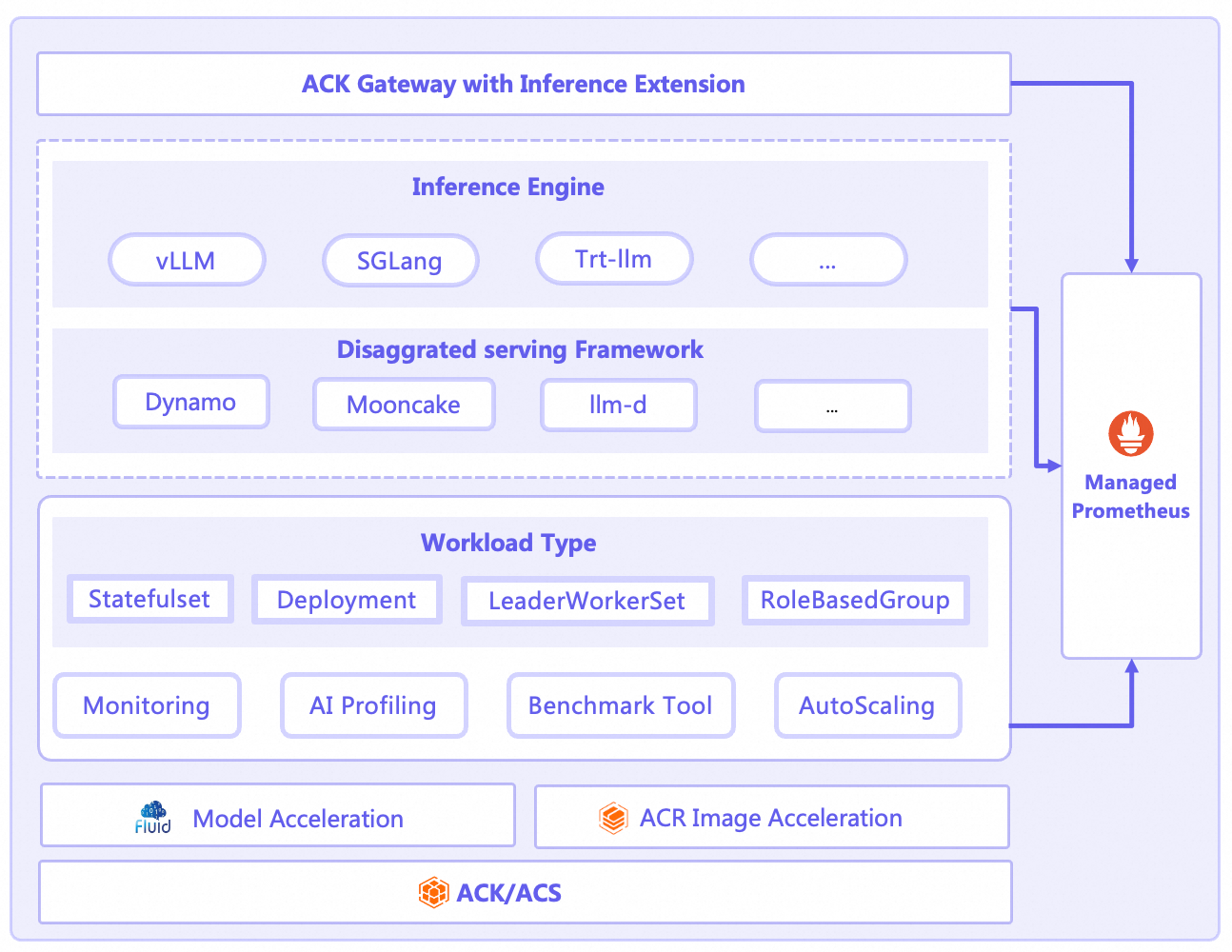
Cloud-native AI Serving Stack menyederhanakan dan meningkatkan efisiensi layanan inferensi LLM di Kubernetes melalui desain beban kerja inovatif, skalabilitas detail halus, observabilitas mendalam, serta mekanisme ekstensi yang kuat. Berikut fitur-fitur inti AI Serving Stack.
Fitur | Deskripsi | Referensi |
Mendukung inferensi LLM single-node | Anda dapat menggunakan StatefulSet untuk menerapkan layanan inferensi LLM, baik dalam konfigurasi single-node dengan satu GPU maupun single-node dengan multi-GPU. | |
Mendukung inferensi LLM terdistribusi multi-node | Anda dapat menggunakan LeaderWorkerSet untuk menerapkan layanan inferensi terdistribusi multi-node dan multi-GPU. | |
Mendukung penerapan pemisahan PD untuk berbagai mesin inferensi | Mesin inferensi yang berbeda menerapkan pemisahan PD menggunakan berbagai arsitektur dan metode penerapan. AI Serving Stack menggunakan RoleBasedGroup sebagai beban kerja terpadu untuk menerapkan arsitektur pemisahan PD tersebut. | |
Skalabilitas elastis | Menyeimbangkan biaya dan kinerja sangat penting untuk layanan LLM. AI Serving Stack menyediakan kemampuan penskalaan otomatis multi-dimensi dan multi-lapis yang terdepan di industri.
| |
Observabilitas | Sifat kotak hitam dari proses inferensi menjadi hambatan utama dalam optimasi kinerja. AI Serving Stack menyediakan solusi observabilitas siap pakai dan mendalam.
| |
Gerbang inferensi | Komponen ACK Gateway with Inference Extension merupakan komponen yang ditingkatkan berdasarkan Kubernetes Gateway API dan spesifikasi Inference Extension-nya. Komponen ini mendukung layanan perutean Lapisan 4 dan Lapisan 7 Kubernetes serta menyediakan serangkaian kemampuan tambahan untuk skenario inferensi AI generatif. Komponen ini menyederhanakan manajemen layanan inferensi AI generatif dan mengoptimalkan kinerja penyeimbangan beban di berbagai beban kerja layanan inferensi. | Konfigurasikan perutean pintar dengan gerbang inferensi untuk layanan inferensi LLM |
Akselerasi model | Dalam skenario inferensi AI, pemuatan model LLM yang lambat menyebabkan berbagai masalah, seperti waktu cold-start aplikasi yang tinggi dan terhambatnya skalabilitas elastis. Fluid membangun cache terdistribusi untuk menyimpan file model jarak jauh pada node lokal. Hal ini memungkinkan startup cepat, tanpa redundansi, dan elastisitas ekstrem. | |
Profil kinerja | Untuk analisis kinerja yang lebih mendalam, Anda dapat menggunakan alat AI Profiling. Alat ini memungkinkan pengembang mengumpulkan data dari proses kontainer GPU untuk mengamati dan menganalisis kinerja layanan pelatihan dan inferensi online tanpa mengganggu layanan atau memodifikasi kode.
|
Penafian
AI Serving Stack menyediakan kemampuan penerapan dan manajemen untuk mesin inferensi open-source dan kerangka kerja pemisahan PD-nya. Alibaba Cloud menyediakan dukungan teknis untuk AI Serving Stack. Namun, Alibaba Cloud tidak memberikan kompensasi atau layanan komersial lainnya atas kerugian bisnis yang disebabkan oleh cacat pada mesin open-source atau kerangka kerja pemisahan PD open-source.