Dokumen ini menjelaskan praktik terbaik untuk menerapkan model DeepSeek-R1-671B di beberapa node dalam Container Service for Kubernetes (ACK). Untuk mengatasi keterbatasan memori GPU tunggal pada model 671B, strategi paralelisme hibrida (Pipeline Parallelism = 2 + Tensor Parallelism = 8) diusulkan. Dengan Arena, penerapan terdistribusi yang efisien dapat dilakukan pada dua node ecs.ebmgn8v.48xlarge (8 × 96GB). Dokumen ini juga menjelaskan cara mengintegrasikan DeepSeek-R1 yang diterapkan di ACK ke dalam platform Dify untuk membangun sistem Q&A cerdas tingkat perusahaan yang mendukung pemahaman teks panjang.
Informasi latar belakang
DeepSeek
DeepSeek-R1 adalah model inferensi generasi pertama yang disediakan oleh DeepSeek untuk meningkatkan kinerja inferensi model bahasa besar (LLMs) menggunakan pembelajaran yang ditingkatkan secara besar-besaran. Statistik menunjukkan bahwa DeepSeek-R1 lebih unggul dibandingkan model sumber tertutup lainnya dalam inferensi matematika dan kinerja pemrograman. Kinerja model ini mencapai atau melampaui seri OpenAI-o1 di sektor tertentu. DeepSeek-R1 juga unggul di sektor terkait pengetahuan seperti penciptaan, penulisan, dan Q&A. DeepSeek menyuling kemampuan inferensi ke model yang lebih kecil, seperti Qwen dan Llama, untuk menyesuaikan kinerja inferensi model tersebut. Model 14B yang disuling dari DeepSeek melampaui model QwQ-32B sumber terbuka. Model 32B dan 70B yang disuling dari DeepSeek juga menetapkan rekor baru. Untuk informasi lebih lanjut tentang DeepSeek, lihat Repositori GitHub DeepSeek AI.
vLLM
vLLM adalah kerangka layanan inferensi LLM berkinerja tinggi dan mudah digunakan. vLLM mendukung sebagian besar LLM yang paling umum digunakan, termasuk model Qwen. vLLM didukung oleh teknologi seperti optimasi PagedAttention, penggabungan batch berkelanjutan, dan kuantifikasi model untuk secara signifikan meningkatkan efisiensi inferensi LLM. Untuk informasi lebih lanjut tentang kerangka vLLM, lihat Repositori GitHub vLLM.
Arena
Prasyarat
Kluster ACK yang berisi node dengan akselerasi GPU telah dibuat. Untuk informasi lebih lanjut, lihat Tambahkan node dengan akselerasi GPU atau ASIC ke kluster ACK. Model yang direkomendasikan:
ecs.ebmgn8v.48xlarge (8 × 96GB).PentingGunakan versi driver 550.x atau lebih baru. Anda bisa menentukan versi driver dengan menambahkan label ke pool node. Sebagai contoh, tambahkan label berikut ke pool node GPU untuk menentukan versi driver 550.144.03:
ack.aliyun.com/nvidia-driver-version: 550.144.03.Kluster ACK menjalankan Kubernetes 1.28 atau lebih baru.
(Opsional) Suite AI cloud-native telah diinstal. Untuk informasi lebih lanjut, lihat Instal suite AI cloud-native.
(Opsional) Klien Arena versi 0.14.0 atau lebih baru telah diinstal. Untuk informasi lebih lanjut, lihat Konfigurasikan klien Arena.
1. Penyebaran lintas beberapa node
1.1 Pisahkan model
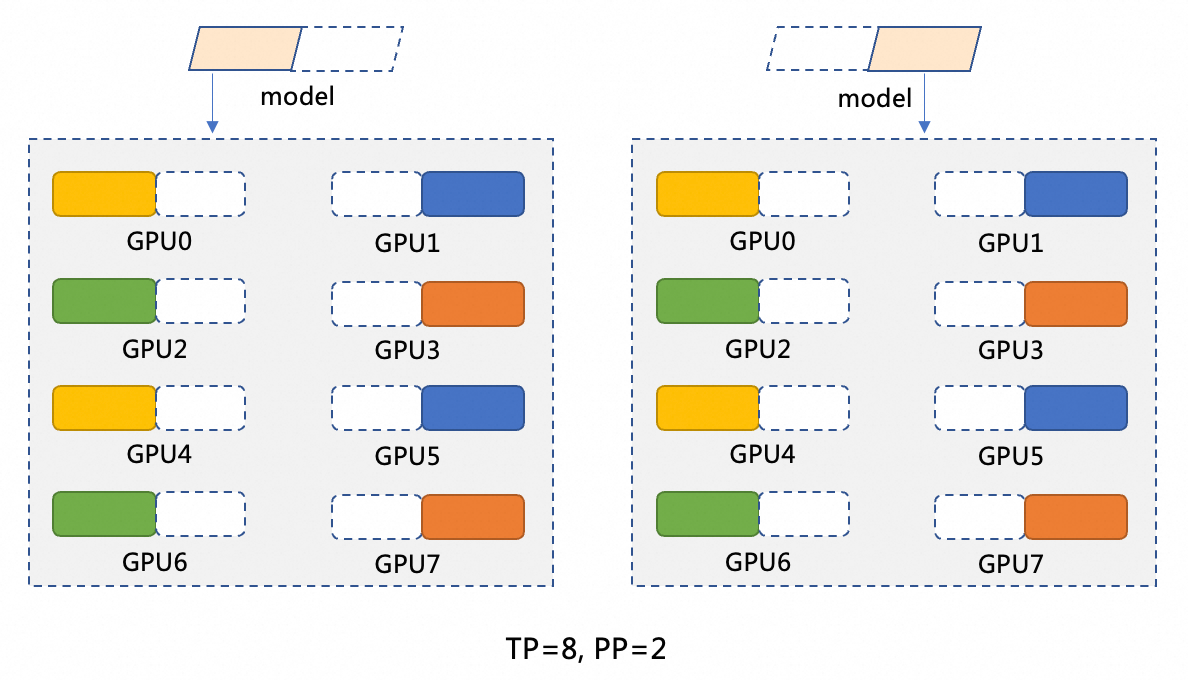
DeepSeek-R1 menyediakan 671 miliar parameter. Setiap GPU dapat menyediakan hingga 96 GB memori, yang tidak cukup untuk memuat seluruh model. Untuk menyelesaikan masalah ini, Anda harus memisahkan model. Dalam dokumen ini, metode pemisahan TP=8 dan PP=2 digunakan. Gambar berikut menunjukkan metode pemisahan. Paralelisme model (PP=2) memisahkan model menjadi dua fase. Setiap fase berjalan pada node yang dipercepat GPU. Sebagai contoh, Model M dipisahkan menjadi M1 dan M2. M1 berjalan pada node pertama yang dipercepat GPU dan meneruskan hasil ke M2 yang berjalan pada node kedua yang dipercepat GPU. Paralelisme data (TP=8) melakukan operasi komputasi pada delapan GPU di setiap fase (M1 atau M2). Dalam fase M1, data masukan dipisahkan menjadi delapan bagian dan diproses pada delapan GPU. Setiap GPU memproses satu bagian dan kemudian sistem menggabungkan hasil komputasi dari delapan GPU.
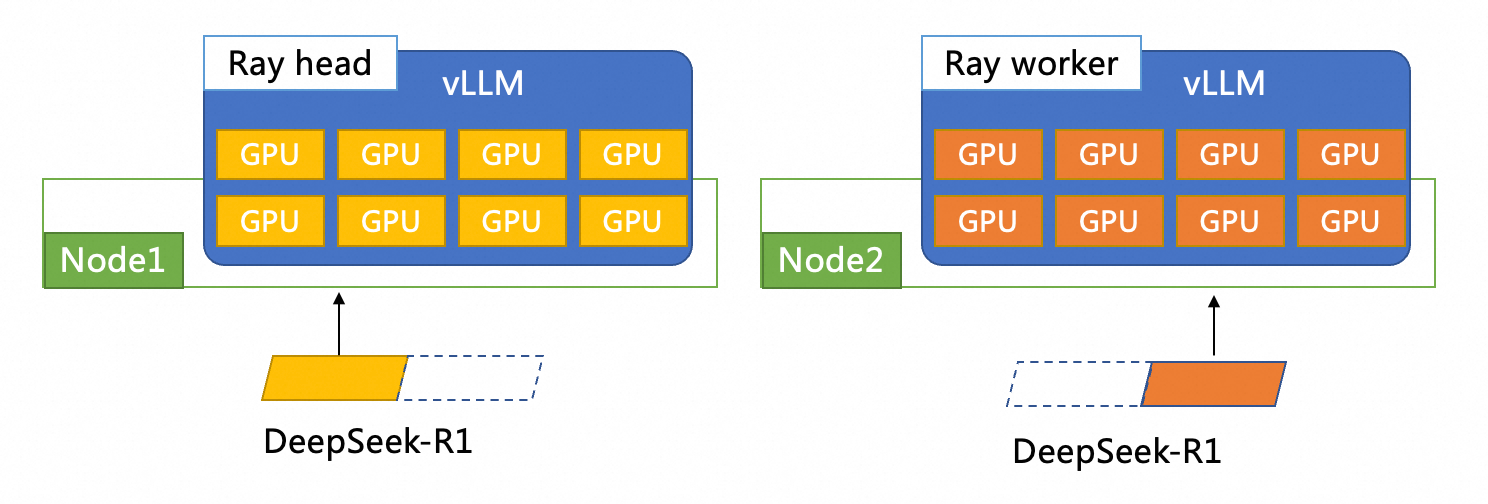
Dalam dokumen ini, vLLM + ray digunakan untuk menerapkan model DeepSeek-R1 secara terdistribusi. Gambar berikut menunjukkan arsitektur penyebaran keseluruhan. Dua pod vLLM diterapkan pada dua instance ECS. Setiap pod vLLM memiliki delapan GPU. Salah satu pod berfungsi sebagai node kepala Ray dan pod lainnya berfungsi sebagai node pekerja Ray.
1.2 Unduh model
Dalam contoh bagian ini, DeepSeek-R1 digunakan untuk menjelaskan cara mengunduh model dari dan mengunggah model ke Object Storage Service (OSS) serta membuat volume persisten (PV) dan klaim volume persisten (PVC) dalam kluster ACK.
Untuk informasi lebih lanjut tentang cara mengunggah model ke Apsara File Storage NAS (NAS), lihat Pasang volume NAS yang disediakan secara statis.
Untuk mempercepat unduhan dan unggahan file, Anda bisa langsung menyalin file ke bucket OSS Anda.
Unduh file model.
Jalankan perintah berikut untuk menginstal Git:
# Jalankan yum install git atau apt install git. yum install gitJalankan perintah berikut untuk menginstal plug-in Git Large File Support (LFS):
# Jalankan yum install git-lfs atau apt install git-lfs. yum install git-lfsJalankan perintah berikut untuk mengkloning repositori DeepSeek-R1 di ModelScope ke mesin lokal Anda:
GIT_LFS_SKIP_SMUDGE=1 git clone https://modelscope.cn/models/deepseek-ai/DeepSeek-R1Jalankan perintah berikut untuk mengakses direktori DeepSeek-R1 dan menarik file besar yang dikelola oleh LFS:
cd DeepSeek-R1 git lfs pull
Unggah file DeepSeek-R1 ke OSS.
Masuk ke Konsol OSS untuk melihat dan menyalin nama bucket OSS yang Anda buat.
Untuk informasi lebih lanjut tentang cara membuat bucket OSS, lihat Buat Bucket.
Instal dan konfigurasikan ossutil untuk mengelola sumber daya OSS. Untuk informasi lebih lanjut, lihat Instal ossutil.
Jalankan perintah berikut untuk membuat direktori bernama DeepSeek-R1 di OSS:
ossutil mkdir oss://<Nama-Bucket-Anda>/models/DeepSeek-R1Jalankan perintah berikut untuk mengunggah file model ke OSS:
ossutil cp -r ./DeepSeek-R1 oss://<Nama-Bucket-Anda>/models/DeepSeek-R1
Konfigurasikan PV dan PVC untuk kluster tujuan. Untuk informasi lebih lanjut, lihat Gunakan volume ossfs 1.0 yang disediakan secara statis.
Buat PV
Masuk ke Konsol ACK. Di panel navigasi di sebelah kiri, klik Clusters.
Di halaman Clusters, temukan kluster yang Anda inginkan dan klik namanya. Di panel di sebelah kiri, pilih .
Di halaman PersistentVolumes, klik Create di pojok kanan atas.
Di kotak dialog Create PersistentVolume, konfigurasikan parameter.
Tabel berikut menjelaskan parameter PV.
Parameter
Deskripsi
PV Type
Dalam contoh ini, pilih OSS.
Volume Name
Dalam contoh ini, masukkan llm-model.
Access Certificate
Pasangan AccessKey yang digunakan untuk mengakses bucket OSS. Pasangan AccessKey terdiri dari ID AccessKey dan Rahasia AccessKey.
Bucket ID
Pilih bucket OSS yang Anda buat pada langkah sebelumnya.
OSS Path
Masukkan path model, seperti
/models/DeepSeek-R1.
Buat PVC
Di halaman Clusters, temukan kluster yang Anda inginkan dan klik namanya. Di panel di sebelah kiri, pilih .
Di halaman PersistentVolumeClaims, klik Create di pojok kanan atas.
Di halaman Create PersistentVolumeClaim, isi parameter.
Tabel berikut menjelaskan parameter PVC.
Parameter
Deskripsi
PVC Type
Dalam contoh ini, pilih OSS.
Name
Dalam contoh ini, masukkan llm-model.
Allocation Mode
Dalam contoh ini, pilih Existing Volumes.
Existing Storage Class
Klik hyperlink Select PV dan pilih PV yang Anda buat.
1.3 Terapkan model
Instal LeaderWorkerSet.
Masuk ke Konsol ACK.
Di panel navigasi di sebelah kiri, klik Clusters, lalu klik nama kluster yang Anda buat.
Di panel navigasi di sebelah kiri, klik . Di halaman Helm, klik Deploy.
Di langkah Basic Information, masukkan Application Name dan Namespace, temukan lws di bagian Chart, dan klik Next. Dalam contoh ini, nama aplikasi (lws) dan namespace (lws-system) digunakan.
Di langkah Parameters, pilih Chart Version terbaru, dan klik OK untuk menginstal lws.
Terapkan model.
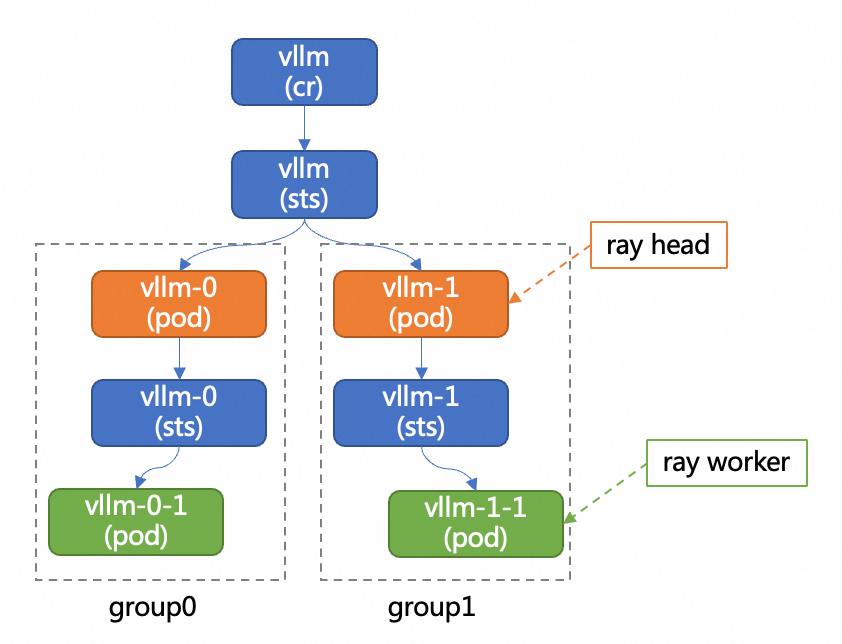
Gambar berikut menunjukkan diagram arsitektur penyebaran terdistribusi vLLM.
Terapkan model menggunakan Arena
Jalankan perintah berikut untuk menerapkan layanan:
arena serve distributed \ --name=vllm-dist \ --version=v1 \ --restful-port=8080 \ --image=kube-ai-registry.cn-shanghai.cr.aliyuncs.com/kube-ai/vllm:v0.10.0 \ --readiness-probe-action="tcpSocket" \ --readiness-probe-action-option="port: 8080" \ --readiness-probe-option="initialDelaySeconds: 30" \ --readiness-probe-option="periodSeconds: 30" \ --share-memory=30Gi \ --data=llm-model:/models/DeepSeek-R1 \ --leader-num=1 \ --leader-gpus=8 \ --leader-command="bash /vllm-workspace/examples/online_serving/multi-node-serving.sh leader --ray_cluster_size=\$(LWS_GROUP_SIZE); python3 -m vllm.entrypoints.openai.api_server --model /models/DeepSeek-R1 --port 8080 --trust-remote-code --served-model-name deepseek-r1 --gpu-memory-utilization 0.95 --tensor-parallel-size 8 --pipeline-parallel-size 2 --enforce-eager" \ --worker-num=1 \ --worker-gpus=8 \ --worker-command="bash /vllm-workspace/examples/online_serving/multi-node-serving.sh worker --ray_address=\$(LWS_LEADER_ADDRESS)"Output yang Diharapkan:
configmap/vllm-dist-v1-cm created service/vllm-dist-v1 created leaderworkerset.leaderworkerset.x-k8s.io/vllm-dist-v1-distributed-serving created INFO[0002] The Job vllm-dist has been submitted successfully INFO[0002] You can run `arena serve get vllm-dist --type distributed-serving -n default` to check the job statusJalankan perintah berikut untuk melihat kemajuan penyebaran layanan inferensi:
arena serve get vllm-distOutput yang Diharapkan:
Name: vllm-dist Namespace: default Type: Distributed Version: v1 Desired: 1 Available: 1 Age: 3m Address: 192.168.138.65 Port: RESTFUL:8080 GPU: 16 Instances: NAME STATUS AGE READY RESTARTS GPU NODE ---- ------ --- ----- -------- --- ---- vllm-dist-v1-distributed-serving-0 Running 3m 1/1 0 8 cn-beijing.10.x.x.x vllm-dist-v1-distributed-serving-0-1 Running 3m 1/1 0 8 cn-beijing.10.x.x.x
Terapkan model menggunakan kubectl
Jalankan file
DeepSeek_R1.yamluntuk menerapkan layanan model.apiVersion: leaderworkerset.x-k8s.io/v1 kind: LeaderWorkerSet metadata: name: vllm-dist spec: replicas: 1 leaderWorkerTemplate: size: 2 restartPolicy: RecreateGroupOnPodRestart leaderTemplate: metadata: labels: role: leader spec: volumes: - name: model persistentVolumeClaim: claimName: llm-model - name: dshm emptyDir: medium: Memory sizeLimit: 15Gi containers: - name: vllm-leader image: kube-ai-registry.cn-shanghai.cr.aliyuncs.com/kube-ai/vllm:v0.10.0 command: - sh - -c - >- bash /vllm-workspace/examples/online_serving/multi-node-serving.sh leader --ray_cluster_size=$(LWS_GROUP_SIZE); python3 -m vllm.entrypoints.openai.api_server --model /models/DeepSeek-R1 --port 8080 --trust-remote-code --served-model-name deepseek-r1 --gpu-memory-utilization 0.95 --tensor-parallel-size 8 --pipeline-parallel-size 2 --enforce-eager resources: limits: nvidia.com/gpu: "8" requests: nvidia.com/gpu: "8" ports: - containerPort: 8080 readinessProbe: initialDelaySeconds: 30 periodSeconds: 30 tcpSocket: port: 8080 volumeMounts: - mountPath: /models/DeepSeek-R1 name: model - mountPath: /dev/shm name: dshm workerTemplate: spec: volumes: - name: model persistentVolumeClaim: claimName: llm-model - name: dshm emptyDir: medium: Memory sizeLimit: 15Gi containers: - name: vllm-worker image: kube-ai-registry.cn-shanghai.cr.aliyuncs.com/kube-ai/vllm:v0.10.0 command: - sh - -c - "bash /vllm-workspace/examples/online_serving/multi-node-serving.sh worker --ray_address=$(LWS_LEADER_ADDRESS)" resources: limits: nvidia.com/gpu: "8" requests: nvidia.com/gpu: "8" ports: - containerPort: 8080 volumeMounts: - mountPath: /models/DeepSeek-R1 name: model - mountPath: /dev/shm name: dshm --- apiVersion: v1 kind: Service metadata: name: vllm-dist-v1 spec: type: ClusterIP ports: - port: 8080 protocol: TCP targetPort: 8080 selector: leaderworkerset.sigs.k8s.io/name: vllm-dist role: leaderkubectl create -f DeepSeek_R1.yamlJalankan perintah berikut untuk melihat kemajuan penyebaran layanan inferensi:
kubectl get po |grep vllm-distOutput yang Diharapkan:
NAME READY STATUS RESTARTS AGE vllm-dist-0 1/1 Running 0 20m vllm-dist-0-1 1/1 Running 0 20m
Buat port lokal untuk meneruskan permintaan inferensi model.
Jalankan perintah
kubectl port-forwarduntuk mengonfigurasi penerusan port antara lingkungan lokal dan layanan inferensi.CatatanJika Anda menjalankan perintah
kubectl port-forwarduntuk mengonfigurasi penerusan port, layanan tidak andal, aman, atau dapat diperluas dalam lingkungan produksi. Anda hanya dapat menggunakan layanan ini untuk pengembangan dan debugging. Jangan jalankan perintah ini untuk mengonfigurasi penerusan port dalam lingkungan produksi. Untuk informasi lebih lanjut tentang solusi jaringan yang digunakan untuk memfasilitasi produksi dalam kluster ACK, lihat Manajemen Ingress.kubectl port-forward svc/vllm-dist-v1 8080:8080Kirim permintaan ke layanan inferensi.
curl http://localhost:8080/v1/completions -H "Content-Type: application/json" -d '{ "model": "deepseek-r1", "prompt": "San Francisco is a", "max_tokens": 10, "temperature": 0.6 }'Output yang Diharapkan:
{"id":"cmpl-15977abb0adc44d9aa03628abe9fcc81","object":"text_completion","created":1739346042,"model":"ds","choices":[{"index":0,"text":" city that needs no introduction. Known for its iconic","logprobs":null,"finish_reason":"length","stop_reason":null,"prompt_logprobs":null}],"usage":{"prompt_tokens":5,"total_tokens":15,"completion_tokens":10,"prompt_tokens_details":null}}
2. Gunakan Dify untuk membangun asisten Q&A DeepSeek
Anda dapat menginstal dan mengonfigurasi Dify dalam kluster Container Service for Kubernetes. Untuk informasi lebih lanjut, lihat Instal ack-dify.
2.1. Konfigurasikan model DeepSeek
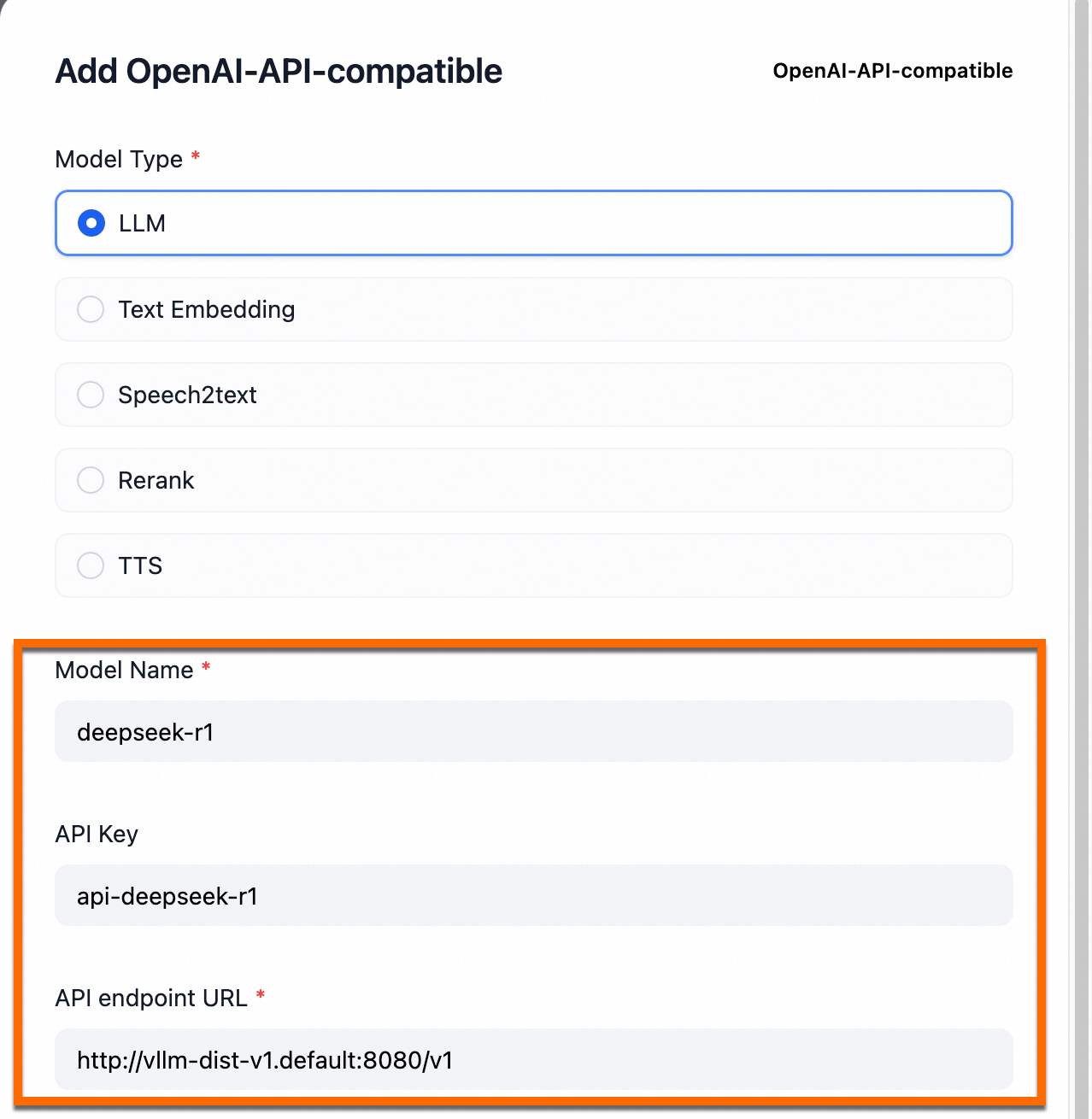
Masuk ke platform Dify. Klik foto profil Anda lalu klik Pengaturan. Di panel navigasi di sebelah kiri, klik Penyedia Model. Temukan
OpenAI-API-compatibledan klikTambah.
Tabel berikut menjelaskan parameter.
Parameter
Pengaturan
Catatan
Model name
deepseek-r1Anda tidak dapat mengubah parameter ini.
API Key
Contoh:
api-deepseek-r1Anda dapat mengonfigurasi parameter ini sesuai dengan kebutuhan bisnis Anda.
API endpoint URL
http://vllm-dist-v1.default:8080/v1Anda tidak dapat mengubah parameter ini. Nilai parameter ini adalah nama layanan DeepSeek lokal yang diterapkan pada langkah kedua.
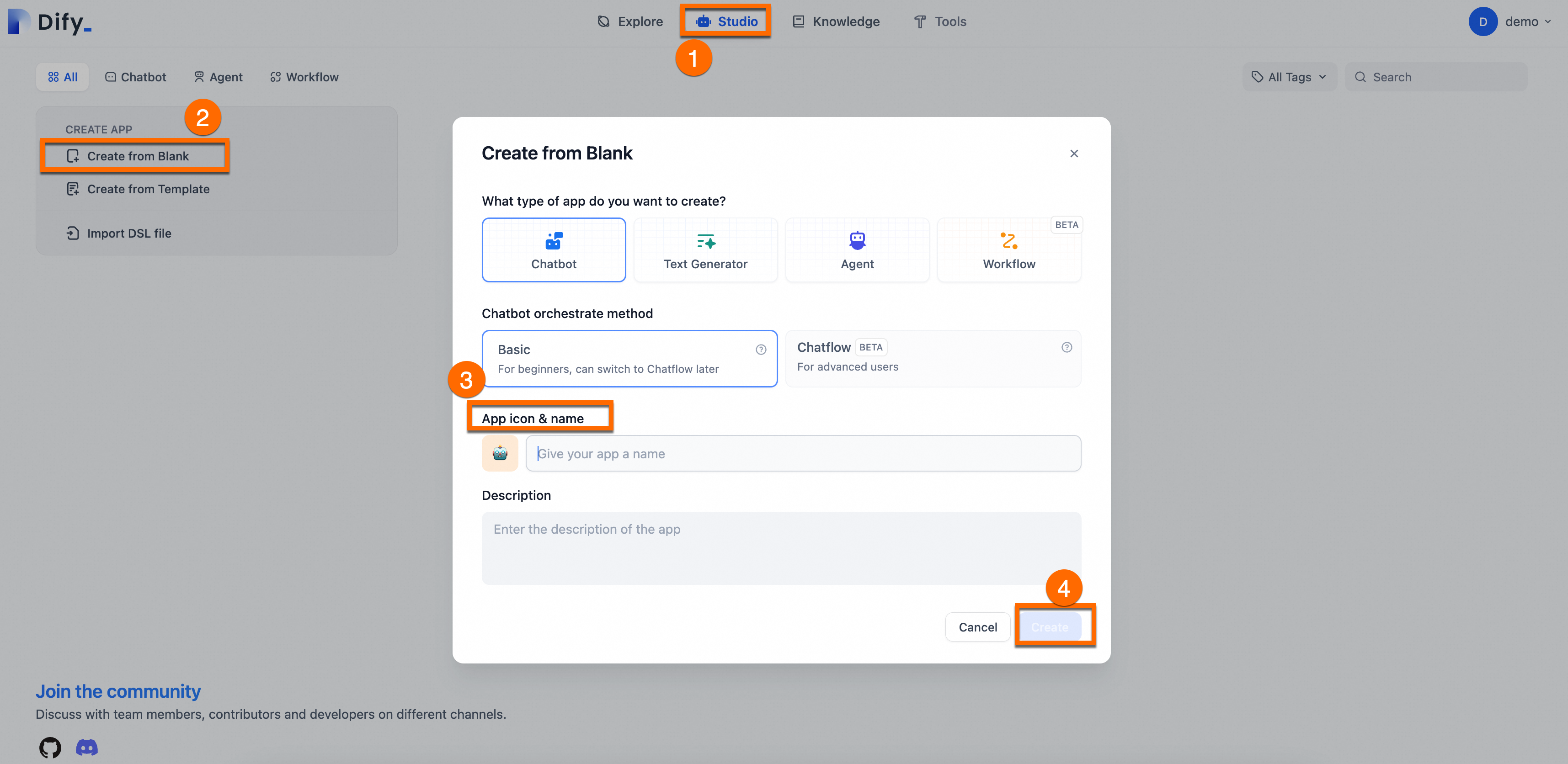
2.2. Buat asisten Q&A
Buat asisten Q&A berbasis AI serbaguna. Pilih Studio > Create from Blank. Tentukan name dan description untuk asisten. Gunakan pengaturan default untuk parameter lainnya.
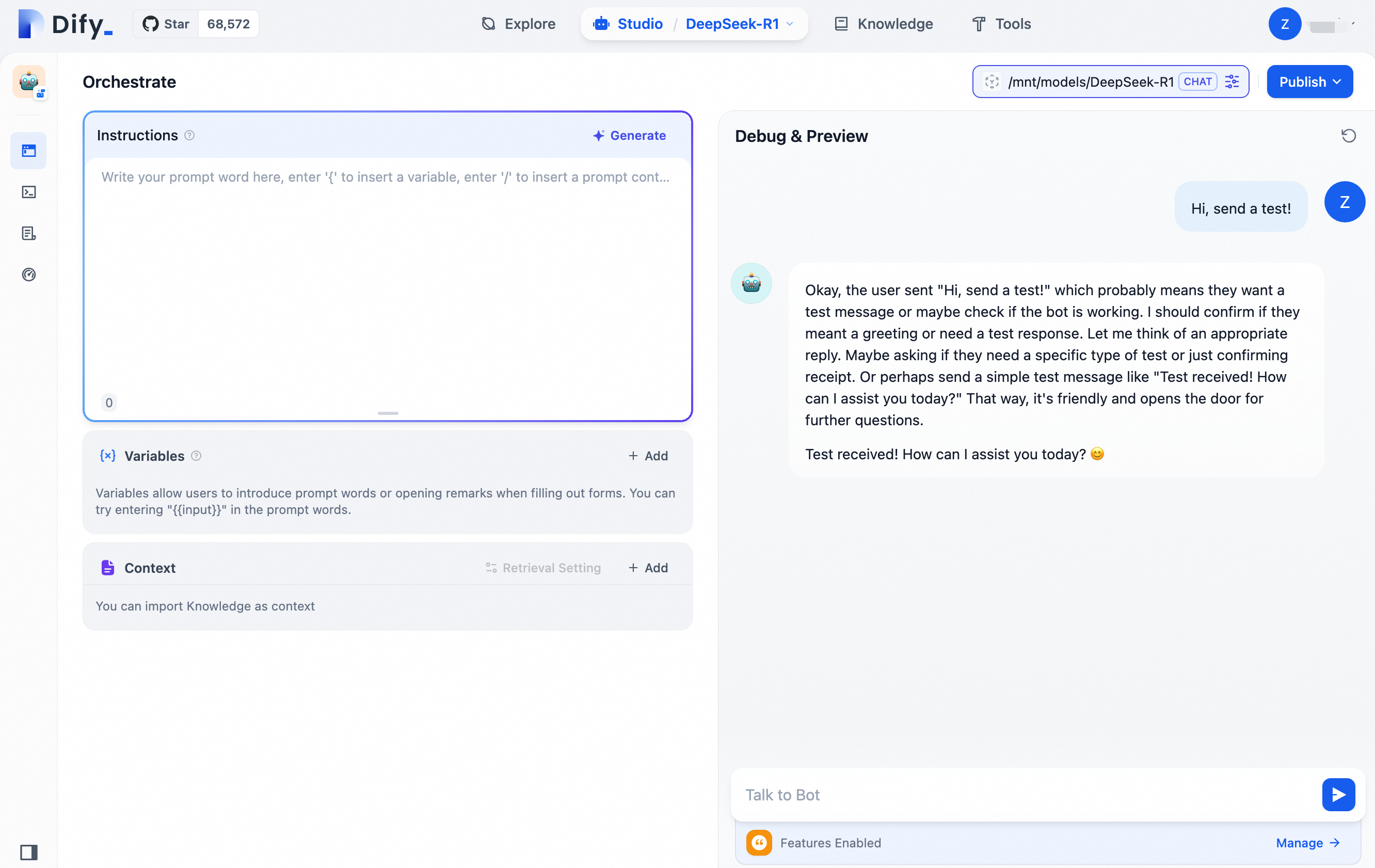
2.3 Uji asisten Q&A berbasis AI
Di sisi kanan halaman, Anda dapat memulai percakapan dengan DeepSeek.
Anda dapat mengintegrasikan asisten Q&A DeepSeek yang telah dikonfigurasi ke dalam lingkungan produksi pribadi Anda. Untuk informasi lebih lanjut, lihat Gunakan dalam Lingkungan Produksi.
