Terapkan layanan inferensi DeepSeek-R1-Distill-Qwen-7B yang siap produksi di Alibaba Cloud Container Service for Kubernetes (ACK) menggunakan KServe dan Arena. Panduan ini mencakup penentuan ukuran GPU, persiapan model, penerapan layanan, verifikasi, dan pengaturan observabilitas.
Latar Belakang
DeepSeek-R1
KServe
Arena
Prasyarat
Sebelum memulai, pastikan Anda telah:
Memiliki kluster Kubernetes dengan node GPU — lihat Menambahkan kelompok node GPU ke kluster
Menghubungkan kubectl ke kluster — lihat Menghubungkan ke kluster menggunakan kubectl
Menginstal komponen ack-kserve — lihat Menginstal komponen ack-kserve
Mengonfigurasi klien Arena — lihat Mengonfigurasi klien Arena
Penentuan ukuran GPU
Parameter model merupakan konsumen utama memori GPU selama inferensi. Gunakan rumus berikut untuk memperkirakan memori GPU yang diperlukan:
GPU memory = Number of parameters × Bytes per parameterUntuk model 7B dengan presisi FP16: 7 × 10⁹ × 2 byte ≈ 13,04 GiB
Selain memuat bobot model, Anda memerlukan memori GPU tambahan untuk cache KV dan komputasi. Gunakan instans GPU dengan memori GPU minimal 24 GiB, seperti ecs.gn7i-c8g1.2xlarge atau ecs.gn7i-c16g1.4xlarge.
Untuk spesifikasi instans dan harga, lihat Keluarga instans komputasi dioptimalkan berakselerasi GPU dan penagihan Elastic GPU Service.
Terapkan layanan inferensi
Langkah 1: Siapkan file model
Unduh model DeepSeek-R1-Distill-Qwen-7B dari ModelScope.
Pastikan git-lfs telah diinstal sebelum melakukan cloning. Instal dengan
yum install git-lfsatauapt-get install git-lfs. Untuk opsi lainnya, lihat Install Git Large File Storage.git lfs install GIT_LFS_SKIP_SMUDGE=1 git clone https://www.modelscope.cn/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B.git cd DeepSeek-R1-Distill-Qwen-7B/ git lfs pullUnggah model ke bucket OSS.
Untuk instalasi dan penggunaan ossutil, lihat Instal ossutil.
ossutil mkdir oss://<your-bucket-name>/models/DeepSeek-R1-Distill-Qwen-7B ossutil cp -r ./DeepSeek-R1-Distill-Qwen-7B oss://<your-bucket-name>/models/DeepSeek-R1-Distill-Qwen-7BBuat persistent volume (PV) dan persistent volume claim (PVC) bernama
llm-modeluntuk memasang model ke dalam kluster. Untuk instruksi langkah demi langkah, lihat Gunakan volume provisioned statis ossfs 1.0.Konsol
Konfigurasikan PV dengan pengaturan berikut:
Item konfigurasi Nilai Tipe PV OSS Nama llm-model Sertifikat akses ID AccessKey dan Rahasia AccessKey untuk OSS ID bucket Bucket OSS yang dibuat pada langkah sebelumnya Path OSS /models/DeepSeek-R1-Distill-Qwen-7BKonfigurasikan PVC dengan pengaturan berikut:
Item konfigurasi Nilai Tipe PVC OSS Nama llm-model Mode alokasi Pilih PV yang sudah ada Volume yang ada Pilih PV yang dibuat di atas Kubectl
Terapkan YAML berikut untuk membuat Secret, PV, dan PVC:
apiVersion: v1 kind: Secret metadata: name: oss-secret stringData: akId: <your-oss-ak> # ID AccessKey untuk OSS akSecret: <your-oss-sk> # Rahasia AccessKey untuk OSS --- apiVersion: v1 kind: PersistentVolume metadata: name: llm-model labels: alicloud-pvname: llm-model spec: capacity: storage: 30Gi accessModes: - ReadOnlyMany persistentVolumeReclaimPolicy: Retain csi: driver: ossplugin.csi.alibabacloud.com volumeHandle: llm-model nodePublishSecretRef: name: oss-secret namespace: default volumeAttributes: bucket: <your-bucket-name> # Nama bucket url: <your-bucket-endpoint> # Titik akhir, misalnya oss-cn-hangzhou-internal.aliyuncs.com otherOpts: "-o umask=022 -o max_stat_cache_size=0 -o allow_other" path: <your-model-path> # misalnya /models/DeepSeek-R1-Distill-Qwen-7B/ --- apiVersion: v1 kind: PersistentVolumeClaim metadata: name: llm-model spec: accessModes: - ReadOnlyMany resources: requests: storage: 30Gi selector: matchLabels: alicloud-pvname: llm-model
Langkah 2: Terapkan layanan inferensi
Jalankan perintah berikut untuk memulai layanan inferensi.
arena serve kserve \
--name=deepseek \
--image=kube-ai-registry.cn-shanghai.cr.aliyuncs.com/kube-ai/vllm:v0.6.6 \
--gpus=1 \
--cpu=4 \
--memory=12Gi \
--data=llm-model:/models/DeepSeek-R1-Distill-Qwen-7B \
"vllm serve /models/DeepSeek-R1-Distill-Qwen-7B --port 8080 --trust-remote-code --served-model-name deepseek-r1 --max-model-len 32768 --gpu-memory-utilization 0.95 --enforce-eager"Parameter Arena
| Parameter | Wajib | Deskripsi |
|---|---|---|
--name | Ya | Nama layanan inferensi. Harus unik secara global. |
--image | Ya | Image kontainer untuk layanan inferensi. |
--gpus | Tidak | Jumlah GPU yang dialokasikan. Default: 0. |
--cpu | Tidak | Jumlah CPU yang dialokasikan. |
--memory | Tidak | Jumlah memori yang dialokasikan. |
--data | Tidak | Memasang PVC llm-model ke /models/DeepSeek-R1-Distill-Qwen-7B di dalam kontainer. |
Parameter vLLM serve
| Parameter | Deskripsi |
|---|---|
--port 8080 | Port tempat server vLLM mendengarkan. |
--trust-remote-code | Mengizinkan pemuatan kode model kustom dari repositori model. Diperlukan untuk model DeepSeek. |
--served-model-name deepseek-r1 | Nama model yang diekspos di API. Digunakan sebagai bidang model dalam permintaan API. |
--max-model-len 32768 | Panjang token maksimum untuk input + output. Diatur ke 32.768 untuk menyeimbangkan jendela konteks dan memori GPU. |
--gpu-memory-utilization 0.95 | Fraksi memori GPU yang dicadangkan untuk model dan cache KV. Diatur ke 0,95 untuk memaksimalkan penggunaan memori sambil menyisakan ruang cadangan. |
--enforce-eager | Menonaktifkan penangkapan graf CUDA dan menjalankan dalam mode eksekusi eager. Mengurangi overhead memori startup, berguna ketika memori GPU terbatas. |
Output yang diharapkan:
inferenceservice.serving.kserve.io/deepseek created
INFO[0003] The Job deepseek has been submitted successfully
INFO[0003] You can run `arena serve get deepseek --type kserve -n default` to check the job statusLangkah 3: Verifikasi penerapan
Periksa status layanan.
arena serve get deepseekOutput yang diharapkan:
Name: deepseek Namespace: default Type: KServe Version: 1 Desired: 1 Available: 1 Age: 3m Address: http://deepseek-default.example.com Port: :80 GPU: 1 Instances: NAME STATUS AGE READY RESTARTS GPU NODE ---- ------ --- ----- -------- --- ---- deepseek-predictor-7cd4d568fd-fznfg Running 3m 1/1 0 1 cn-beijing.172.16.1.77Status
Available: 1danRunningmengonfirmasi bahwa layanan siap digunakan.Kirim permintaan uji melalui gerbang NGINX Ingress.
# Dapatkan alamat IP NGINX Ingress NGINX_INGRESS_IP=$(kubectl -n kube-system get svc nginx-ingress-lb -ojsonpath='{.status.loadBalancer.ingress[0].ip}') # Dapatkan hostname layanan inferensi SERVICE_HOSTNAME=$(kubectl get inferenceservice deepseek -o jsonpath='{.status.url}' | cut -d "/" -f 3) # Kirim permintaan chat completion curl -H "Host: $SERVICE_HOSTNAME" \ -H "Content-Type: application/json" \ http://$NGINX_INGRESS_IP:80/v1/chat/completions \ -d '{"model": "deepseek-r1", "messages": [{"role": "user", "content": "Say this is a test!"}], "max_tokens": 512, "temperature": 0.7, "top_p": 0.9, "seed": 10}'Output yang diharapkan:
{"id":"chatcmpl-0fe3044126252c994d470e84807d4a0a","object":"chat.completion","created":1738828016,"model":"deepseek-r1","choices":[{"index":0,"message":{"role":"assistant","content":"<think>\n\n</think>\n\nIt seems like you're testing or sharing some information. How can I assist you further? If you have any questions or need help with something, feel free to ask!","tool_calls":[]},"logprobs":null,"finish_reason":"stop","stop_reason":null}],"usage":{"prompt_tokens":9,"total_tokens":48,"completion_tokens":39,"prompt_tokens_details":null},"prompt_logprobs":null}
Observabilitas
Layanan inferensi LLM menghasilkan berbagai metrik yang kaya. vLLM mengekspos metrik inferensi seperti throughput token dan latensi; KServe menambahkan metrik kesehatan dan performa layanan. Keduanya terintegrasi ke dalam Arena dan dapat diaktifkan hanya dengan satu flag.
Untuk mengaktifkan metrik Prometheus, tambahkan --enable-prometheus=true ke perintah arena serve kserve:
arena serve kserve \
--name=deepseek \
--image=kube-ai-registry.cn-shanghai.cr.aliyuncs.com/kube-ai/vllm:v0.6.6 \
--gpus=1 \
--cpu=4 \
--memory=12Gi \
--enable-prometheus=true \
--data=llm-model:/models/DeepSeek-R1-Distill-Qwen-7B \
"vllm serve /models/DeepSeek-R1-Distill-Qwen-7B --port 8080 --trust-remote-code --served-model-name deepseek-r1 --max-model-len 32768 --gpu-memory-utilization 0.95 --enforce-eager"Untuk daftar lengkap metrik vLLM, lihat dokumentasi Metrik vLLM.
Impor dasbor Grafana
Visualisasikan metrik inferensi menggunakan dasbor Grafana vLLM. Tampilan dasbor yang dikonfigurasi seperti berikut:
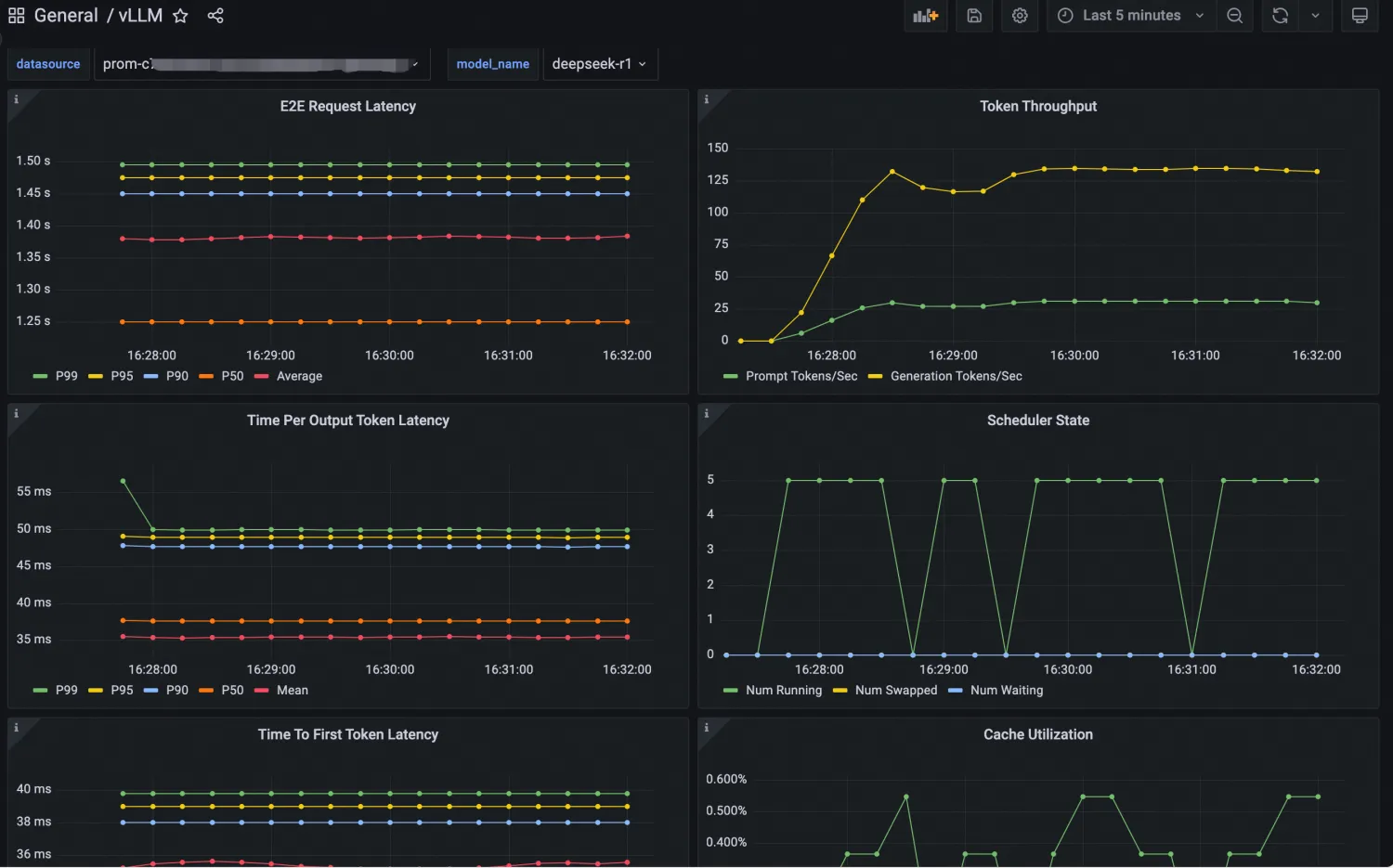
Impor dasbor
Masuk ke Konsol ARMS.
Di panel navigasi kiri, klik Integration Management.
Di tab Integrated Environments, pilih Container Service, cari kluster ACK Anda berdasarkan nama, lalu klik lingkungan target.

Pada tab Component Management, salin Cluster ID, lalu klik tautan di samping Dashboard Directory.

Di sebelah kanan tab Dashboards, klik Import.

Salin isi file grafana.json, tempelkan ke area Import via panel json, lalu klik Load.
Anda juga dapat mengimpor dengan mengunggah langsung file JSON tersebut.
Pertahankan pengaturan default dan klik Import.
Verifikasi data dasbor
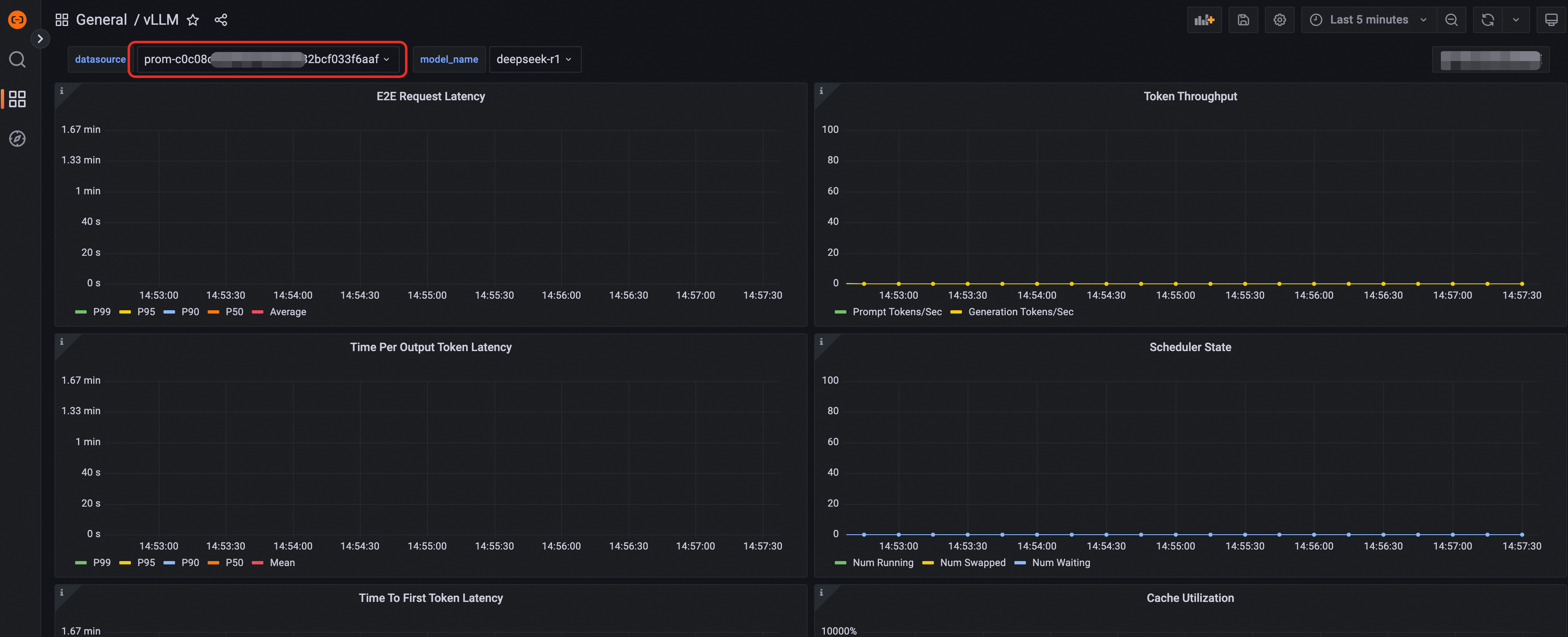
Cari sumber data menggunakan ID Kluster yang disalin atau ID instans Prometheus, lalu pilih sumber data target.
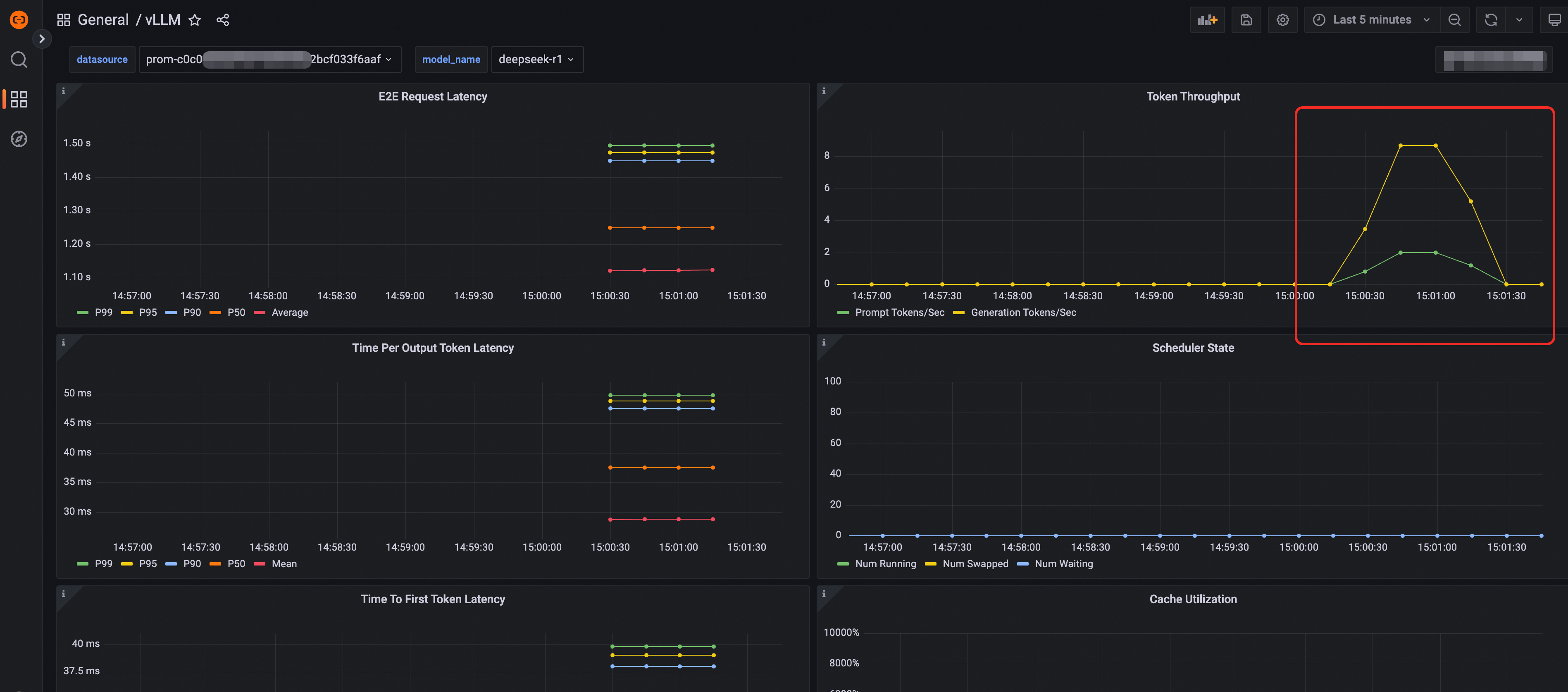
Kirim beberapa permintaan ke layanan inferensi untuk mensimulasikan trafik, lalu verifikasi metrik seperti Token Throughput pada dasbor.
Peningkatan untuk produksi
Skalabilitas elastis
Jika beban kerja inferensi Anda memiliki trafik yang bervariasi, gunakan integrasi Horizontal Pod Autoscaler (HPA) KServe dengan komponen ack-alibaba-cloud-metrics-adapter dari ACK untuk secara otomatis menskalakan pod berdasarkan pemanfaatan CPU, memori, GPU, dan metrik kustom. Hal ini menjaga stabilitas layanan selama lonjakan trafik tanpa over-provisioning.
Untuk informasi lebih lanjut, lihat Mengonfigurasi auto scaling untuk layanan.
Akselerasi model
Ketika kluster menarik file model besar dari OSS atau NAS, latensi tinggi dan delay cold start dapat memengaruhi ketersediaan layanan. Gunakan Fluid untuk menyimpan cache data model di dekat pod inferensi, sehingga secara signifikan mengurangi waktu pemuatan.
Untuk informasi lebih lanjut, lihat Menggunakan Fluid untuk akselerasi model.
Rilis bertahap
Saat memperbarui model atau konfigurasi di lingkungan produksi, gunakan rilis bertahap untuk menerapkan perubahan ke sebagian kecil trafik terlebih dahulu dan memvalidasi stabilitas sebelum rilis penuh. ACK mendukung strategi rilis bertahap berbasis persentase trafik maupun berbasis header permintaan.
Untuk informasi lebih lanjut, lihat Menerapkan rilis bertahap untuk layanan inferensi.
Berbagi GPU
Model DeepSeek-R1-Distill-Qwen-7B memerlukan sekitar 14 GB memori GPU. Jika Anda menggunakan GPU dengan spesifikasi lebih tinggi, pertimbangkan berbagi GPU untuk menjalankan beberapa layanan inferensi pada satu GPU dan meningkatkan pemanfaatan GPU secara keseluruhan.
Untuk informasi lebih lanjut, lihat Menerapkan layanan inferensi berbagi GPU.
Langkah selanjutnya
Menggunakan daya komputasi ACS di edisi Pro kluster ACK yang dikelola
Membangun layanan inferensi model distillation DeepSeek menggunakan daya komputasi GPU ACS
Membangun layanan inferensi model versi lengkap DeepSeek menggunakan daya komputasi GPU ACS
Membangun layanan inferensi versi lengkap DeepSeek terdistribusi menggunakan daya komputasi GPU ACS