Gunakan metrik etcd dan panel Dasbor untuk mendeteksi serta mendiagnosis masalah pada lapisan kontrol kluster ACK.
Sebelum memulai
Akses
Lihat Tampilan dasbor pemantauan untuk komponen lapisan kontrol.
Daftar metrik
Tabel berikut mencantumkan metrik komponen etcd.
|
Metric |
Type |
Description |
|
cpu_utilization_core |
Gauge |
Penggunaan CPU, dalam satuan core. |
|
etcd_server_has_leader |
Gauge |
Dalam algoritma konsensus Raft, satu anggota etcd dipilih sebagai leader. Leader mengirim heartbeat berkala untuk menjaga stabilitas kluster. Menunjukkan apakah terdapat leader di antara anggota etcd.
|
|
etcd_server_is_leader |
Gauge |
Menunjukkan apakah anggota etcd ini merupakan leader.
|
|
etcd_server_leader_changes_seen_total |
Counter |
Total perubahan leader yang diamati oleh anggota etcd ini. |
|
etcd_mvcc_db_total_size_in_bytes |
Gauge |
Ukuran total database anggota etcd. |
|
etcd_mvcc_db_total_size_in_use_in_bytes |
Gauge |
Ukuran yang digunakan dari database anggota etcd. |
|
etcd_disk_backend_commit_duration_seconds_bucket |
Histogram |
Waktu yang dibutuhkan untuk menulis perubahan data ke penyimpanan backend dan melakukan commit. Batas bucket adalah |
|
etcd_debugging_mvcc_keys_total |
Gauge |
Jumlah total kunci yang disimpan di etcd. |
|
etcd_server_proposals_committed_total |
Gauge |
Dalam Raft, perubahan state diajukan sebagai proposal. Total proposal yang telah dikomit ke log Raft. |
|
etcd_server_proposals_applied_total |
Gauge |
Total proposal yang telah diterapkan. |
|
etcd_server_proposals_pending |
Gauge |
Jumlah proposal yang tertunda. |
|
etcd_server_proposals_failed_total |
Counter |
Jumlah proposal yang gagal. |
|
memory_utilization_byte |
Gauge |
Penggunaan memori, dalam satuan byte. |
|
resource_utilization_level |
Gauge |
Tingkat pemanfaatan sumber daya.
|
Metrik pemanfaatan sumber daya berikut tidak lagi digunakan. Hapus semua alert atau aturan pemantauan yang bergantung pada metrik ini:
cpu_utilization_ratio: Pemanfaatan CPU.
memory_utilization_ratio: Pemanfaatan memori.
Panduan dasbor
Dasbor menggunakan kueri PromQL untuk memvisualisasikan metrik etcd.
Ikhtisar dasbor
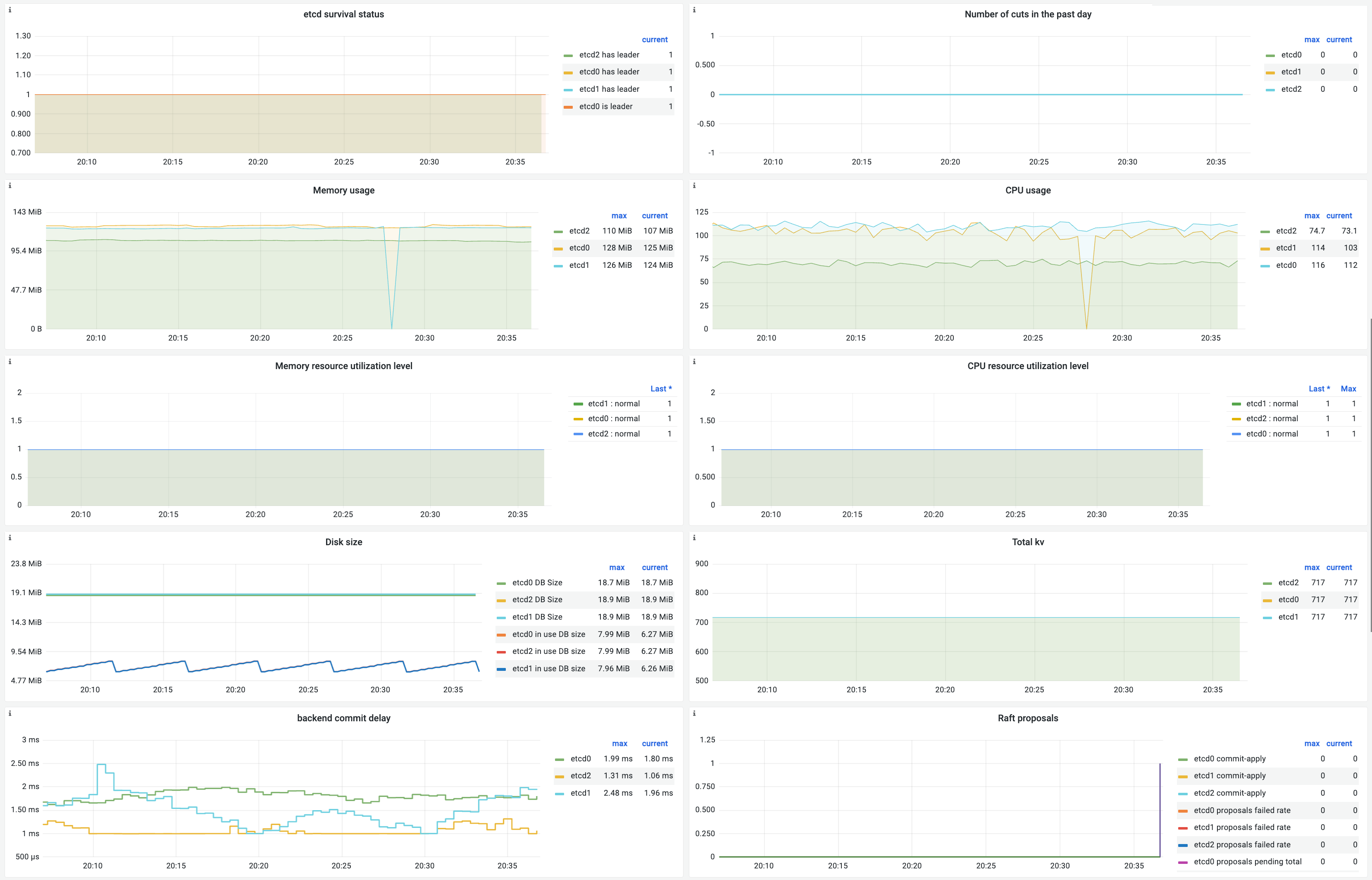
Deskripsi panel
|
Parameter |
PromQL |
Description |
|
etcd liveness status |
|
|
|
Leader changes in the last day |
|
Jumlah perubahan leader etcd selama sehari terakhir. |
|
Memory usage |
|
Penggunaan memori, dalam satuan byte. |
|
CPU usage |
|
Penggunaan CPU, dalam satuan millicore. |
|
Memory usage level |
|
|
|
CPU usage level |
|
|
|
Disk size |
etcd_mvcc_db_total_size_in_bytes |
Ukuran total database backend etcd. |
|
etcd_mvcc_db_total_size_in_use_in_bytes |
Ukuran yang digunakan dari database backend etcd. |
|
|
Total key-value pairs |
etcd_debugging_mvcc_keys_total |
Jumlah total pasangan kunci-nilai dalam kluster etcd. |
|
Backend commit latency |
|
Waktu yang dibutuhkan untuk menyimpan proposal secara persisten di database etcd. |
|
Raft proposal status |
|
Laju proposal Raft yang gagal per menit. |
|
|
Jumlah total proposal Raft yang tertunda. |
|
|
|
Jumlah proposal yang telah dikomit tetapi belum diterapkan. |
Anomali metrik umum
etcd liveness status
|
Kasus normal |
Kasus abnormal |
Description |
|
Ketiga anggota etcd memiliki leader, dan salah satunya harus menjadi leader: |
Satu anggota mengalami anomali. |
|
|
Lebih dari satu anggota mengalami anomali. |
Beberapa anggota melaporkan Periksa juga apakah ada anggota yang memiliki |
Backend commit latency
|
Kasus normal |
Kasus abnormal |
Description |
|
Latensi biasanya berkisar antara beberapa hingga puluhan milidetik. |
Latensi berkelanjutan mencapai ratusan milidetik atau lebih. |
Menunjukkan adanya masalah I/O disk. |
Anomali proposal Raft
|
Kasus normal |
Kasus abnormal |
Description |
|
Laju proposal Raft yang gagal adalah 0. |
Laju proposal Raft yang gagal lebih besar dari 0. |
Beberapa proposal gagal dikomit. Selidiki jika laju kegagalannya tinggi. |
|
Jumlah total proposal Raft yang tertunda adalah 0. |
Jumlah proposal Raft yang tertunda tidak nol dan bertahan lama. |
Adanya antrian proposal Raft, sering kali disebabkan oleh kecepatan penerapan (apply) yang lambat. Korelasikan dengan latensi commit backend. |
|
Selisih antara proposal Raft yang dikomit dan yang diterapkan adalah 0. |
Selisih antara proposal yang dikomit dan yang diterapkan lebih besar dari 0. |
Dapat mengindikasikan volume permintaan klien yang berlebihan pada etcd. Jika nilai ini melebihi 5000, etcd akan menolak permintaan dengan respons |
Referensi
Lihat Metrik pemantauan untuk kube-apiserver, Metrik pemantauan untuk kube-scheduler, Metrik pemantauan untuk kube-controller-manager, dan Metrik pemantauan untuk cloud-controller-manager.