Lihat metrik workqueue kube-controller-manager, sumber daya, dan Kube API melalui dasbor pemantauan.
Konsep Utama
Workqueue
Sebelum memulai
Akses dasbor
Lihat Dasbor pemantauan untuk komponen lapisan kontrol kluster.
Daftar metrik
Tabel berikut mencantumkan metrik
memory|
Metric |
Type |
Description |
|
workqueue_adds_total |
Counter |
Total event yang ditambahkan ke |
|
workqueue_depth |
Gauge |
Kedalaman |
|
workqueue_queue_duration_seconds_bucket |
Histogram |
Waktu tunggu item di |
|
memory_utilization_byte |
Gauge |
Penggunaan memory. Satuan: byte. |
|
cpu_utilization_core |
Gauge |
Pemanfaatan CPU. Satuan: core. |
|
resource_utilization_level |
Gauge |
Tingkat pemanfaatan resource.
|
|
rest_client_requests_total |
Counter |
Total permintaan HTTP berdasarkan kode status, metode, dan host. |
|
rest_client_request_duration_seconds_bucket |
Histogram |
Latensi permintaan HTTP berdasarkan verb dan URL. |
Metrik pemanfaatan resource berikut ini tidak lagi digunakan. Hapus semua alert atau aturan pemantauan yang bergantung pada metrik ini:
-
cpu_utilization_ratio: CPU utilization.
-
memory_utilization_ratio: Memory utilization.
Penggunaan dashboard
Konfigurasikan quantile permintaan dan interval pengambilan sampel PromQL pada dashboard. Bagian berikut menjelaskan setiap grafik beserta kueri PromQL-nya.
Workqueue
Tampilan dashboard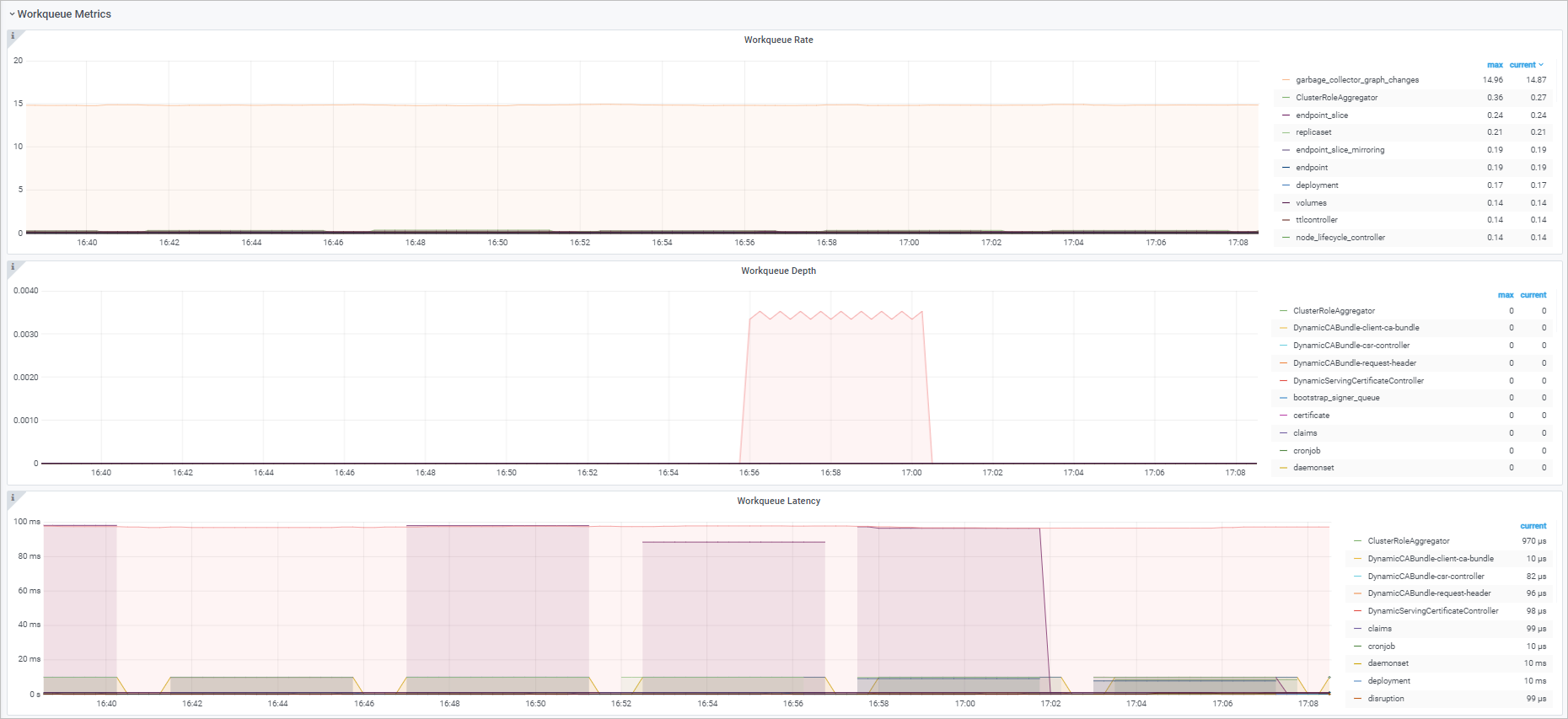
Grafik
|
Name |
PromQL |
Description |
|
Workqueue Add Rate |
sum(rate(workqueue_adds_total{job="ack-kube-controller-manager"}[$interval])) by (name) |
Laju event yang ditambahkan ke |
|
Workqueue Depth |
sum(rate(workqueue_depth{job="ack-kube-controller-manager"}[$interval])) by (name) |
Rata-rata laju perubahan kedalaman |
|
Workqueue Processing Latency |
histogram_quantile($quantile, sum(rate(workqueue_queue_duration_seconds_bucket{job="ack-kube-controller-manager"}[5m])) by (name, le)) |
Waktu tunggu suatu item di dalam |
Sumber Daya
Tampilan Dashboard

Bagan
|
Chart name |
PromQL |
Description |
|
Memory Utilization |
memory_utilization_byte{container="kube-controller-manager"} |
Pemanfaatan memori. Satuan: byte. |
|
CPU Utilization |
cpu_utilization_core{container="kube-controller-manager"}*1000 |
Pemanfaatan CPU. Satuan: millicore. |
|
Memory Resource Utilization Level |
|
|
|
CPU Resource Utilization Level |
|
Kube API
Tampilan dashboard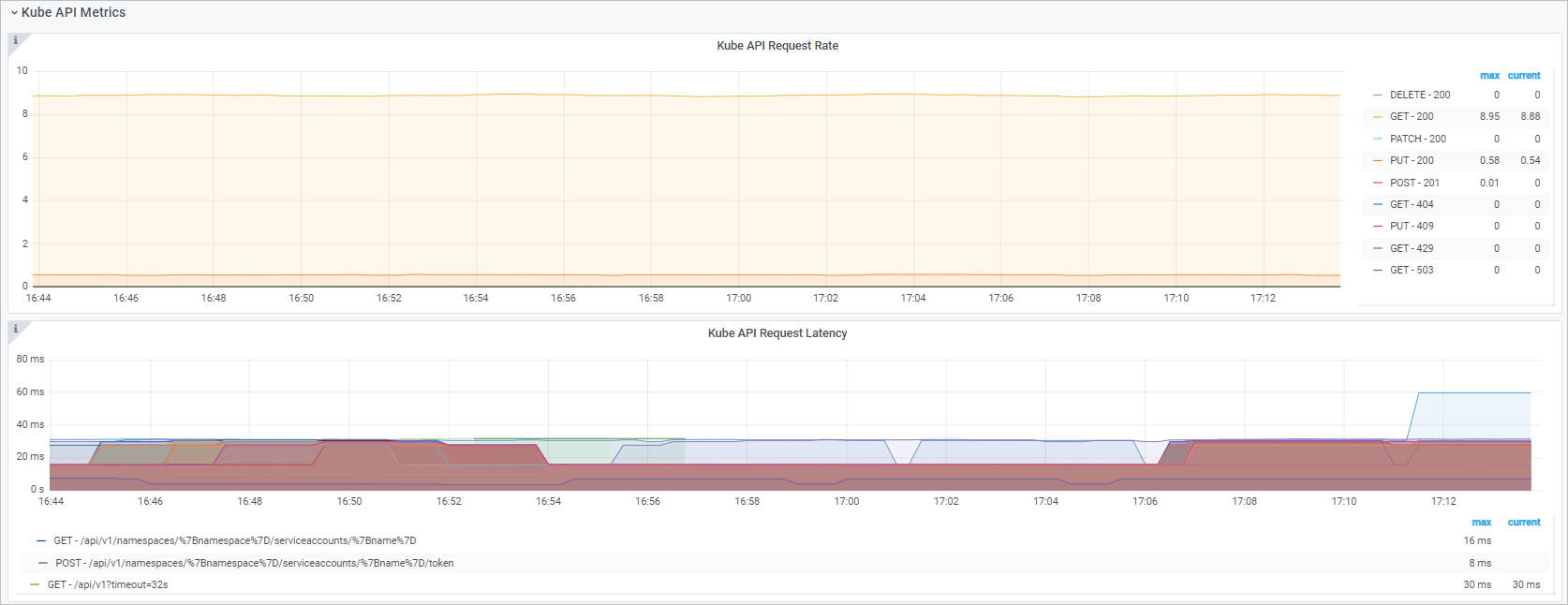
Grafik
|
Chart name |
PromQL |
Description |
|
Kube API Request QPS |
|
QPS permintaan HTTP dari kube-controller-manager ke kube-apiserver, berdasarkan metode dan kode status. |
|
Kube API Request Latency |
histogram_quantile($quantile, sum(rate(rest_client_request_duration_seconds_bucket{job="ack-kube-controller-manager"}[$interval])) by (verb,url,le)) |
Latensi permintaan HTTP dari kube-controller-manager ke kube-apiserver, berdasarkan verb dan URL. |
Referensi
Untuk metrik dan dashboard komponen lapisan kontrol lainnya, lihat Metrik pemantauan untuk komponen kube-apiserver, Metrik pemantauan untuk komponen etcd, Metrik pemantauan untuk komponen kube-scheduler, dan Metrik pemantauan untuk komponen cloud-controller-manager.