You can use E-MapReduce (EMR) JindoFS in cache mode to connect to Object Storage Service (OSS) that is used as the data lake.
Background information
You can use EMR JindoFS in cache or block storage mode to connect to OSS.
When you use JindoFS in cache mode, files are stored as objects in OSS, and the frequently accessed objects are cached on the local disk of an EMR cluster to improve the data access efficiency. In cache mode, JindoFS can access objects in OSS without the need to convert the object formats. JindoFS is fully compatible with OSS clients. For more information, see Use JindoFS in cache mode.
The block storage mode ensures efficient read and write operations and high metadata accessibility. JindoFS uses OSS as the storage backend. In block storage mode, JindoFS stores data as blocks in OSS and uses Namespace Service to maintain metadata. This ensures high performance when you read and write data or query metadata. For more information, see Use JindoFS in block storage mode.
Prerequisites
An EMR cluster is created. For more information, see Create a cluster.
Before you create a cluster, take note of the following items:
The EMR cluster and OSS belong to the same Alibaba Cloud account. We recommend that the EMR cluster and OSS bucket be located in the same region.
When you create a cluster, turn on Assign Public IP Address to access the cluster over the Internet and Remote Logon to log on to a remote server by using Shell.
SmartData and Bigboot are dependent services to use configurations of JindoFS. If these services are not selected by default, select these services.
A delivery task is created. For more information, see Use the Tablestore console to deliver data to OSS.
Procedure
Use EMR JindoFS in cache mode to connect to OSS and enable local cache. For more information, see Use JindoFS in cache mode.
After you enable local cache, hot data blocks are cached on local disks. By default, this feature is disabled, which indicates that EMR directly reads data from OSS. After you enable local cache, Jindo automatically manages cached data. Jindo clears cached data based on the disk space usage you configured. Configure the usage to clear cached data and adjust the space usage of local disks.
Start Spark SQL.
Use remote logon tools such as PuTTY to log on to the EMR Header server.
Run the following command to run Spark SQL:
spark-sql --master yarn --num-executors 5 --executor-memory 1g --executor-cores 2
Use an SQL statement to create a external table that maps to an OSS folder.
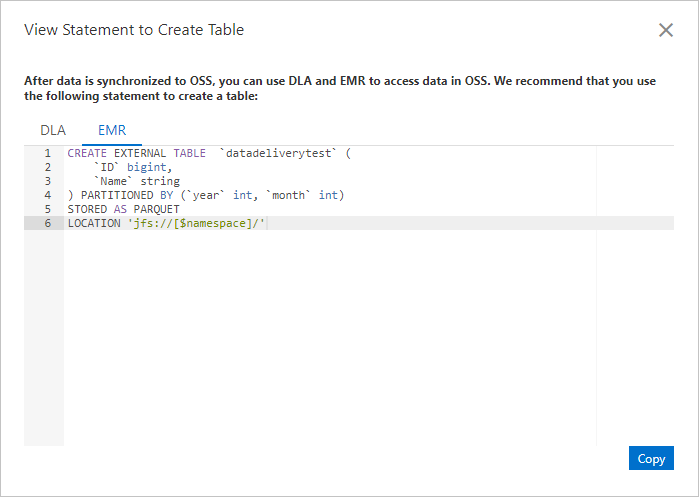
Obtain an SQL statement in the Tablestore console. The following example of an SQL statement is used only for reference:
CREATE EXTERNAL TABLE lineitem (l_orderkey bigint,l_linenumber bigint,l_receiptdate string,l_returnflag string,l_tax double,l_shipmode string,l_suppkey bigint,l_shipdate string,l_commitdate string,l_partkey bigint,l_quantity double,l_comment string,l_linestatus string,l_extendedprice double,l_discount double,l_shipinstruct string) PARTITIONED BY (`year` int, `month` int) STORED AS PARQUET LOCATION 'jfs://test/' ;
To obtain an SQL statement in the Tablestore console, use the following method:
On the Deliver Data to OSS tab, click View SQL Statement to Create Table in the Actions column corresponding to a delivery task. You can view and copy the SQL statement. The following figure shows an example of an SQL statement that is used to create an external table.
Execute the following SQL statement to load data partitions from an OSS source.
lineitem is the name of the external table.
msck repair table lineitem;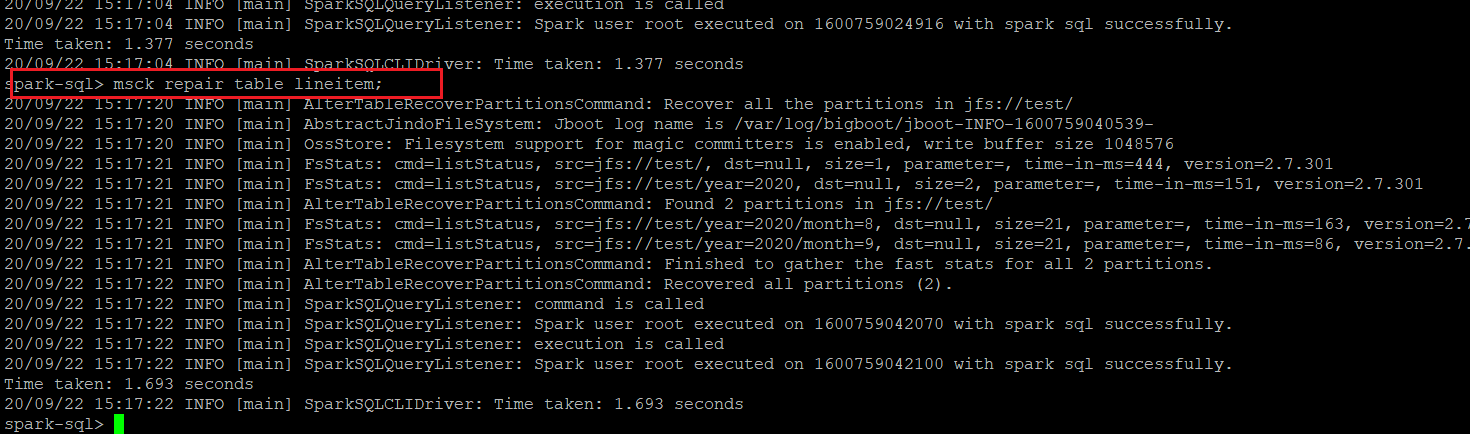
Query data.
select * from lineitem limit 1;