For use cases such as historical file collection, data migration, or batch data processing, traditional incremental log collection cannot collect existing static files in a single run. The server text log one-time collection feature enables you to deploy collection configurations in bulk to a Machine Group through the console or API. This collects the contents of specified static files once, and the task then automatically terminates.
Applicability
LoongCollector version 3.3 or later.
LoongCollector supports host collection on Linux and Windows, but not container collection.
Collection configuration
Preparation: Create a Project and a Logstore. A Project is a resource management unit that isolates logs from different services. A Logstore stores the logs.
Configure a machine group (Install LoongCollector): Install LoongCollector based on your server type and add it to a machine group. Use the machine group to manage collection nodes, distribute configurations, and monitor server health.
Create and configure a one-time file collection rule:
Global and input configuration: Name the collection configuration and specify the log source and scope.
Log processing and structuring: Configure processing settings based on your log format.
Multiline logs: Handles log entries that span multiple lines, such as Java stack traces or Python tracebacks. Use a start-of-line regex to identify the beginning of each log entry, merging subsequent lines into a single record.
Structured parsing: Configure a parser plugin (such as regex, delimiter, or NGINX mode) to parse raw strings into structured key-value pairs. This lets you query and analyze each field independently.
Log filtering: Configure collection blocklists and content filtering rules to select only relevant logs, which reduces redundant data transmission and storage.
Log categorization: Configure log topics to flexibly categorize logs from different services, servers, or source paths.
Query and analysis configuration: The full-text index is enabled by default and supports keyword searches. For structured fields, enable a field index to improve search efficiency and support precise queries and analysis.
Verify collection results: After completing the configuration, verify that logs are collected successfully. If you encounter issues such as logs not being collected, heartbeat failures, or parsing errors, see the FAQ.
Prerequisites
Before collecting logs, you need to create a Project and a LogStore to manage and store your logs. If you already have these resources, skip this step and proceed to Configure a Machine Group (Install LoongCollector).
Create a project
Create a LogStore
In the Project list, click your target Project.
In the left-side navigation pane, go to
 and click +.
and click +.On the Create LogStore page, configure the following core parameters:
Logstore Name: Enter a name that is unique within the Project. This name cannot be changed after creation.
Logstore Type: Select Standard or Query based on a feature comparison.
Billing Mode:
Pay-by-feature: This mode bills you separately for each resource, such as storage, indexing, and read/write operations. It is ideal for small-scale scenarios or for workloads with unpredictable feature usage.
Pay-by-ingested-data: This mode bills you only for the volume of ingested raw data. It includes 30 days of free storage and free features such as data processing and shipping. It is ideal for workloads with a data retention period close to 30 days or with complex data processing pipelines.
Data Retention Period: Specify the number of days to retain logs, from 1 to 3,650. A value of 3,650 means permanent retention. The default is 30 days.
Leave the remaining parameters at their default values and click OK. For more information, see Manage a LogStore.
Step 1: Configure a machine group
After completing the prerequisites, install LoongCollector on different types of servers and add them to a machine group.
These installation steps apply only if the log source is an ECS instance in the same Alibaba Cloud account and region as the Log Service Project.
If your ECS instance and Project are not in the same account or region, or if your log source is an on-premises server, see Install and configure LoongCollector.
Procedure:
On the
 Logstores page, click
Logstores page, click  next to the target logstore name to expand it.
next to the target logstore name to expand it.Click . On the One-time Logtail Configuration tab, click Add Logtail Configuration.
In the Quick Data Import dialog box, click Integrate Now on the One-Time File Collection - Host card.
On the Machine Group Configurations page, configure the following parameters:
Scenario: Servers
Installation Environment: ECS
Select Machine Group: Select an action based on the LoongCollector and machine group status on the target server:
If LoongCollector is installed and has been added to a machine group, select it from the Source Machine Group list and add it to the Applied Machine Group list. You do not need to create a new one.
If LoongCollector is not installed, click Create Machine Group:
The following steps describe the one-click process to install LoongCollector and create a machine group.
The system automatically lists the ECS instances that are in the same region as the Project. Select one or more instances from which you want to collect logs.
Click Install and Create Machine Group. The system automatically installs LoongCollector on the selected ECS instances.
Enter a Name for the machine group and click OK.
NoteIf the installation fails or remains in a pending state, verify that the ECS instance is in the same region as the Project.
To add a server with LoongCollector already installed to an existing machine group, see How do I add a server to an existing machine group?
Check heartbeat status: Click Next. When the Heartbeat Status of Machine Group section appears, check the Heartbeat. If the status is OK, the machine group is connected properly. Click Next to proceed to the Logtail configuration page.
If the status is FAIL, establishing the initial heartbeat may take some time. Wait about two minutes and then refresh the heartbeat status. If the status is still FAIL after refreshing, see Machine group heartbeat connection fails for further troubleshooting.
Step 2: Configure a one-time file collection rule
After you complete the LoongCollector installation and machine group configuration, go to the Logtail Configurations page to define log collection and processing rules.
1. Global and input configurations
Define the name for the collection configuration, and specify the source and scope of log collection.
Global Configurations:
Configuration Name: Specify a custom name for the collection configuration. The name must be unique within the Project and cannot be modified after creation. The naming rules are as follows:
Can only contain lowercase letters, digits, hyphens (-), and underscores (_).
Must start and end with a lowercase letter or a digit.
Execution Timeout: The default is 600s (10 minutes), and the timeout can be set from 600 to 604,800 seconds (10 minutes to 7 days). If a collection task exceeds this timeout, it is forcibly stopped, and any remaining data is not collected.
ImportantNote on configuration updates: When you update a configuration, its validity period is reset. To prevent duplicate task execution or unexpected data reporting, ensure that the machine group scope is correct and that the previous task execution time did not exceed the Execution Timeout.
Force rerun on update: Off by default.
Off:
When you update collection configuration parameters other than Execution Timeout or Input Configurations, the system resumes the current collection progress instead of restarting the task. This ensures uninterrupted collection.
If you modify the Execution Timeout or Input Configurations, the system reruns the collection task.
On: When you update the collection configuration, the task forcibly restarts. This ensures all data is processed and reported according to the latest settings. Note: Data collected before the update is not deleted. To clear previously collected data, see Soft deletion in Simple Log Service.
Input Configurations:
Type: One-time File Collection (LoongCollector 3.3+ required).
File Path: The path from which logs are collected.
NoteLoongCollector determines the list of files to collect and their sizes when it retrieves the configuration. It does not collect new files or content appended to existing files after this point.
Linux: The path must start with a forward slash (
/). For example,/data/mylogs/**/*.logcollects all files with the.logextension in all subdirectories of/data/mylogs.Windows: The path must start with a drive letter. For example,
C:\Program Files\Intel\**\*.Log.
Maximum Directory Monitoring Depth: The maximum directory depth that the wildcard
**in the File Path can match. The default value is 0, which means that only the current directory is monitored.
2. Log processing and structuring
Configure log processing rules to convert raw, unstructured logs into structured, searchable data, which improves query and analysis efficiency. We recommend that you first Add Log Sample.
In the Processor Configurations area of the Logtail Configurations page, click Add Sample Log and enter your log content. The system uses this sample to identify the log format and helps you generate a regular expression and parsing rules, which simplifies the configuration process.
Scenario 1: Processing multiline logs
A log entry, such as a Java exception stack trace or a JSON object, often spans multiple lines. In the default collection mode, such an entry is split into multiple incomplete records, causing a loss of context. To prevent this, enable multiline mode and configure a line-beginning regular expression to merge consecutive lines that belong to the same log entry into a single, complete log.
Example:
Raw log | Default mode | Multiline mode |
| In the query results, each log entry carries duplicate metadata such as the IP address | In the Simple Log Service console, a Java exception log containing the |
Procedure: In the Processor Configurations area of the Logtail Configurations page, enable Multi-line Mode:
Type: Select Custom or Multi-line JSON.
Custom: Use this option for logs with an inconsistent format. You must configure a Regex to Match First Line to identify the start of each log entry.
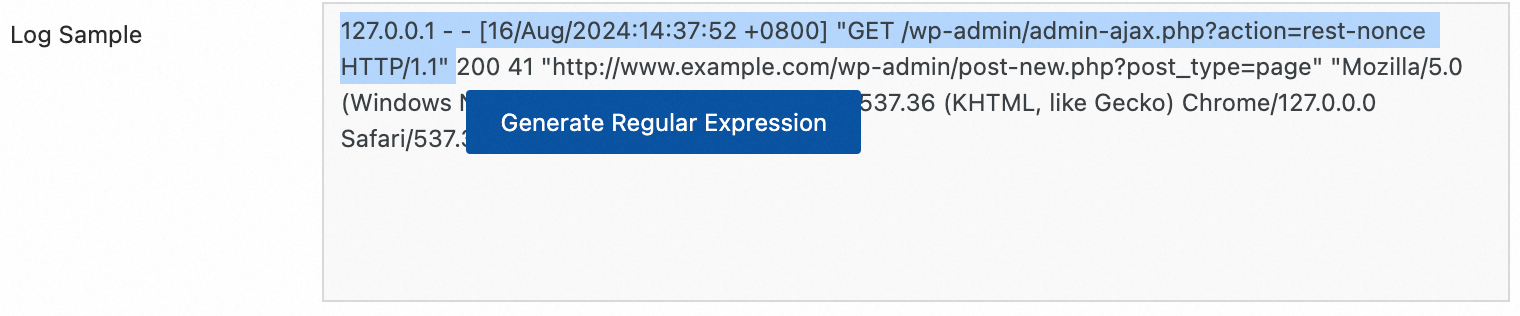
Regex to Match First Line: You can generate this expression automatically or enter it manually. The regular expression must match a complete line of data. For example, the expression for the sample log is
\[\d+-\d+-\w+:\d+:\d+,\d+]\s\[\w+]\s.*.To automatically generate the expression, click Generate, select the desired log content in the Log Sample text box, and then click Generate Regular Expression.
To manually enter the expression, click Manually Enter Regular Expression, provide your expression, and then click Validate.
Multi-line JSON: If your raw logs are in standard JSON format, Simple Log Service automatically handles newlines within a single JSON log entry.
Processing Method If Splitting Fails:
Discard: If a block of text does not match the line-beginning rule, it is discarded.
Retain Single Line: Text that does not match the rule is instead processed in single-line mode, with each line treated as a separate log.
Scenario 2: Processing structured logs
Querying and analyzing an unstructured log or a semi-structured log, such as an NGINX access log or application output, can be inefficient. Simple Log Service provides various data processing plugins that automatically convert raw logs in different formats into structured data. This provides a solid foundation for subsequent analysis, monitoring, and alerting.
Example:
Raw log | Structured log |
| |
Procedure: In the Processor Configurations area of the Logtail Configurations page:
Add a processor plugin: Click Add Processor and configure a plugin such as regex, delimiter, or JSON parsing based on your log format. This example uses an NGINX log and selects .
NGINX Log Configuration: Copy the entire
log_formatdefinition from your NGINX server's configuration file (nginx.conf) and paste it into this text box.Example:
log_format main '$remote_addr - $remote_user [$time_local] "$request" ''$request_time $request_length ''$status $body_bytes_sent "$http_referer" ''"$http_user_agent"';ImportantThe format definition here must exactly match the format that is used to generate the log on your server. Otherwise, parsing fails.
Common parameters: The following parameters are common across multiple data processor plugins and serve the same purpose.
Original field: Specifies the source field to parse. The default is
content, which is the entire collected log entry.Retain original field if parsing fails: Recommended. If the plugin fails to parse a log, for example, due to a format mismatch, this option retains the original log content in the specified original field.
Retain original field if parsing succeeds: This option retains the original log content even after successful parsing.
3. Log filtering
Collecting large volumes of low-value or irrelevant logs, such as DEBUG or INFO entries, wastes storage, increases costs, impairs query efficiency, and poses data leakage risks. To address these issues, use fine-grained filtering rules for efficient and secure log collection.
Content filtering
Filter logs based on field content, for example, by collecting only logs where the level is WARNING or ERROR.
Example:
Raw logs | Collect only |
| |
Procedure: In the Processor Configurations area of the Logtail Configurations page:
Click Add Processor and select :
Field Name: The log field to filter by.
Field Value: The regular expression used for filtering. Only full-text matching is supported; partial keyword matching is not.
Collection blacklist
Use a blacklist to exclude specified directories or files to prevent the upload of irrelevant or sensitive logs.
Procedure: In the Logtail Configurations page, go to the area, enable Collection Blacklist, and click Add.
Exact matching and wildcard matching are supported for directories and filenames. The only supported wildcards are the asterisk (*) and the question mark (?).
File Path Blacklist: The file paths to ignore. Examples:
/home/admin/private*.log: Ignores all files in the/home/admin/directory that start withprivateand end with.logduring collection./home/admin/private*/*_inner.log: Ignores files that end with_inner.login directories that start withprivatewithin the/home/admin/directory.
File Blacklist: The filenames to ignore during collection. Example:
app_inner.log: Ignores all files namedapp_inner.logduring collection.
Directory Blacklist: Directory paths cannot end with a forward slash (
/). Examples:/home/admin/dir1/: The directory blacklist has no effect./home/admin/dir*: During collection, ignores files in all subdirectories of/home/admin/whose names start withdir./home/admin/*/dir: Ignores all files in any second-level subdirectory nameddirunder the/home/admin/directory. For example, files in the/home/admin/a/dirdirectory are ignored, but files in the/home/admin/a/b/dirdirectory are collected.
4. Categorize logs
When logs from multiple applications or instances share the same format but have different paths, such as /apps/app-A/run.log and /apps/app-B/run.log, it can be difficult to distinguish their sources after collection. By configuring a log topic, you can logically differentiate logs from various applications, services, or paths. This enables efficient categorization and precise querying within a unified storage destination.
Procedure: In the area, select a topic generation method. The following types are supported:
Machine group topic: When you apply a collection configuration to multiple machine groups, LoongCollector automatically uses the server's machine group name as the value for the
__topic__field. This is useful for categorizing logs by host.Custom: Use the format
customized://<custom-topic-name>, for example,customized://app-login. This method is suitable for static topics with fixed business identifiers.File path extraction: Extracts key information from the full path of a log file to dynamically tag the log source. This is useful when multiple users or applications share the same log filename but reside in different paths. For example, when multiple users or services write logs to different top-level directories but use the same subdirectory path and filename, you cannot distinguish the source by filename alone:
/data/logs ├── userA │ └── serviceA │ └── service.log ├── userB │ └── serviceA │ └── service.log └── userC └── serviceA └── service.logIn this case, you can configure file path extraction and use a regular expression to extract key information from the full path. The matched result is then uploaded to the Logstore as the log topic.
File path extraction rules
When you configure the regular expression, the system automatically determines the output field format based on the number and names of the capture groups. The rules are as follows:
In a regular expression for a file path, you must escape forward slashes (
/).Capture group type
Use case
Generated field
Regex example
Sample matched path
Sample generated field
Single capture group (only one
(.*?))When you need only one dimension to distinguish sources, such as by username or environment.
Generates the
__topic__field.\/logs\/(.*?)\/app\.log/logs/userA/app.log__topic__: userAMultiple Capture Groups - Unnamed (multiple
(.*?))When you need multiple dimensions to distinguish sources but do not require semantic labels.
Generates the tag field
__tag__:__topic_{i}__, where{i}is the index of the capture group.\/logs\/(.*?)\/(.*?)\/app\.log/logs/userA/svcA/app.log__tag__:__topic_1__:userA;__tag__:__topic_2__:svcANamed multiple capture groups (using
(?P<name>.*?)When you need multiple dimensions to distinguish sources and want clear, meaningful field names for easy querying and analysis.
Generate the tag field
__tag__:{name}\/logs\/(?P<user>.*?)\/(?P<service>.*?)\/app\.log/logs/userA/svcA/app.log__tag__:user:userA;__tag__:service:svcA
Step 3: Query and analysis
After completing log processing and plugin configuration, click Next to go to the Query and Analysis Configurations page.
The full-text index is enabled by default and supports keyword search on raw log content.
To query by field, once the Preview Data loads, click Automatic Index Generation. Log Service then generates a field index based on the first entry in the preview.
After completing the configuration, click Next to finish the collection process.
Step 4: Verify collection results
After the configuration takes effect, on the query and analysis page for the target logstore, click Search & Analyze to view the log data.
FAQ
One-time collection lifecycle
After a one-time collection configuration is created, it follows the lifecycle below:

Configuration distribution window: LoongCollector (Logtail) can pull the configuration within 5 minutes of its creation. After 5 minutes, new LoongCollector (Logtail) instances can no longer obtain this configuration.
Automatic configuration deletion: Log Service automatically deletes the configuration 7 days after creation.
Task execution: The collection task must be completed within the execution timeout. If the task exceeds the execution timeout, the system forcibly stops it.
One-time vs. legacy file collection
The legacy historical file collection method is no longer recommended. Use one-time file collection to import historical data. Compared to the legacy method, which required manually creating configuration files, one-time file collection significantly improves configuration efficiency, reliability, and observability. The following table provides a detailed comparison:
Comparison item | Legacy method | One-time file collection |
Configuration method | Create a | Create a configuration in the console or via the API and deploy it to a machine group in batches. |
File matching | Manually enter file paths and filenames. | Provides streamlined configuration similar to |
Progress monitoring | No status reporting or local logs. | Uses a checkpoint to track the collection progress, with granularity down to the current offset of each file. |
Reliability | Low. It runs as a separate process with no resource controls or checkpoint mechanism. | High. It uses standard pipeline-level resource management, supports flow control to avoid impacting other collection tasks, and enables resumable transfer. |
Flexibility | Low. You must use an existing collection configuration. | High. You can orchestrate the collection configuration and modify it during the task. |
Machine group heartbeat is fail
Check the user ID. If your server is not an ECS instance, or if your ECS instance and Project belong to different Alibaba Cloud accounts, check whether the correct user ID file exists in the specified directory. If it does not exist, create it manually by using one of the following commands.
Linux: Run the
cd /etc/ilogtail/users/ && touch <uid>command to create a user identifier file.Windows: Go to the
C:\LogtailData\users\directory and create an empty file named<uid>.
Check the machine group identifier: If you used a user-defined identifier when you created the machine group, check whether the
user_defined_idfile exists in the specified directory. If it does, check whether the content of the file matches the user-defined identifier that is configured for the machine group.Linux:
# Configure the user-defined identifier. If the directory does not exist, create it manually. echo "user-defined-1" > /etc/ilogtail/user_defined_idWindows: Create a
user_defined_idfile in theC:\LogtailDatadirectory and write the user-defined identifier to it. (If the directory does not exist, create it manually.)
If both the user ID and machine group identifier are correct, see Troubleshoot LoongCollector (Logtail) machine group issues for troubleshooting steps.
Adding a server to a machine group
To add a new server, such as a newly deployed ECS instance or a self-managed server, to an existing machine group, follow these steps to associate it with the group and apply its collection configuration.
If a server is added to a machine group more than 5 minutes after the one-time collection configuration is created, it will not receive the configuration. Check the countdown timer at the top of the collection configuration page to see the remaining time.
Prerequisites
An existing machine group.
LoongCollector (Logtail) is installed on the new server.
Procedure
View the target machine group's identifier.
In the target Project, click
 in the left-side navigation pane.
in the left-side navigation pane.On the Machine Groups page, click the name of the target machine group.
On the machine group configuration page, view the machine group identifier.
Perform one of the following actions based on the identifier type.
NoteA single machine group cannot contain both Linux and Windows servers. Do not configure the same user-defined identifier on both Linux and Windows servers. To configure multiple user-defined identifiers on a single server, separate them with a line break.
Type 1: The machine group identifier is an IP address
On the server, run the following command to open the
app_info.jsonfile and view theipvalue.cat /usr/local/ilogtail/app_info.jsonOn the configuration page of the target machine group, click Modify and enter the IP address of the server. If you have multiple IP addresses, separate them with line breaks.
After you complete the configuration, click Save and confirm the heartbeat status. If the status is OK, the server automatically applies the machine group's collection configuration.
If the heartbeat status is FAIL, see Machine group heartbeat is FAIL for troubleshooting instructions.
Type 2: The machine group identifier is a user-defined identifier
Based on the operating system, write the user-defined identifier string that matches the target machine group to the specified file:
If the directory does not exist, create it manually. The file path and name are fixed by Log Service and cannot be customized.
Linux: Write a custom string to the
/etc/ilogtail/user_defined_idfile.Windows: Write a custom string to
C:\LogtailData\user_defined_id.
Appendix: Native processing plugins
Regular expression parsing
Extract log fields using a regular expression and parse the log into key-value pairs. Each field can be independently queried and analyzed.
Example:
|
Raw log without any processing |
Using the regular expression parsing plugin |
|
|
Procedure: In the Processor Configurations section of the Logtail Configuration page, click Add Processor and select :
-
Regular Expression: The expression used to match logs. Generate it automatically or enter it manually:
-
Automatic generation:
-
Click Generate.
-
In the Log Sample, select the log content to extract.
-
Click Generate Regular Expression.
-
-
Manual entry: Manually Enter Regular Expression based on the log format.
After configuration, click Validate to test whether the regular expression can correctly parse the log content.
-
-
Extracted Field: The field name (Key) that corresponds to the extracted log content (Value).
-
For other parameters, see the description of common configuration parameters in Use case 2: Structured logs.
For information about other parameters, see the general parameter descriptions in Scenario 2: Structured Logs.
Delimiter parsing
Structure log content using a separator to parse it into multiple key-value pairs. Both single-character and multi-character separators are supported.
Example:
|
Raw log without any processing |
Fields split by the specified character |
|
|
Procedure: In the Processor Configurations section of the Logtail Configuration page, click Add Processor and select :
-
Delimiter: Specifies the character used to split log content.
Example: For a CSV file, select Custom and enter a comma (,).
-
Quote: If a field value contains the separator, you must enclose the field value in quotes to prevent incorrect splitting.
-
Extracted Field: Specify the field name (Key) for each column in the order that they appear. The rules are as follows:
-
Field names can contain only letters, digits, and underscores (_).
-
Must start with a letter or an underscore (_).
-
Maximum length: 128 bytes.
-
-
For other parameters, see the description of common configuration parameters in Use case 2: Structured logs.
For information about other parameters, see the general parameter descriptions in Scenario 2: Structured Logs.
JSON parsing
Structure an Object-type JSON log by parsing it into key-value pairs.
Example:
|
Raw log without any processing |
Automatic extraction of standard JSON key-value pairs |
|
|
Procedure: In the Processor Configurations section of the Logtail Configuration page, click Add Processor and select :
-
Original Field: The field that contains the raw log to be parsed. The default value is content.
-
For other parameters, see the description of common configuration parameters in Use case 2: Structured logs.
For information about other parameters, see the general parameter descriptions in Scenario 2: Structured Logs.
Nested JSON parsing
Parse a nested JSON log into key-value pairs by specifying the expansion depth.
Example:
|
Raw log without any processing |
Expansion depth: 0, using expansion depth as a prefix |
Expansion depth: 1, using expansion depth as a prefix |
|
|
|
Procedure: In the Processor Configurations section of the Logtail Configuration page, click Add Processor and select :
-
Original Field: Specifies the name of the source field to expand, such as
content. -
JSON Expansion Depth: The expansion depth of the JSON object, where 0 (the default) indicates full expansion, 1 indicates expansion of the current level, and so on.
-
Character to Concatenate Expanded Keys: The separator for field names when a JSON object is expanded. The default value is an underscore (_).
-
Name Prefix of Expanded Keys: The prefix for field names after JSON expansion.
-
Expand Array: Expands an array into key-value pairs with indexes.
Example:
{"k":["a","b"]}is expanded to{"k[0]":"a","k[1]":"b"}.To rename the expanded fields (for example, from prefix_s_key_k1 to new_field_name), add a rename fields plugin afterward to complete the mapping.
-
For other parameters, see the description of common configuration parameters in Use case 2: Structured logs.
For information about other parameters, see the general parameter descriptions in Scenario 2: Structured Logs.
JSON array parsing
Use the json_extract function to extract JSON objects from a JSON array.
Example:
|
Raw log without any processing |
Extract JSON array structure |
|
|
Procedure: In the Processor Configurations section of the Logtail Configuration page, switch the Processing Mode to SPL, configure the SPL Statement, and use the json_extract function to extract JSON objects from the JSON array.
Example: Extract elements from the JSON array in the log field content and store the results in new fields json1 and json2.
* | extend json1 = json_extract(content, '$[0]'), json2 = json_extract(content, '$[1]')Apache log parsing
Structure the log content into multiple key-value pairs based on the definition in the Apache log configuration file.
Example:
|
Raw log without any processing |
Apache Common Log Format |
|
|
Procedure: In the Processor Configurations section of the Logtail Configuration page, click Add Processor and select :
-
The Log Format is combined.
-
The APACHE LogFormat Configuration are automatically populated based on the Log Format.
ImportantMake sure to verify the auto-filled content to ensure it is exactly the same as the LogFormat defined in your server's Apache configuration file (usually located at /etc/apache2/apache2.conf).
-
For other parameters, see the description of common configuration parameters in Use case 2: Structured logs.
For information about other parameters, see the general parameter descriptions in Scenario 2: Structured Logs.
IIS log parsing
Structure the log content into multiple key-value pairs based on the IIS log format definition.
Comparison example:
|
Raw log |
Adaptation for Microsoft IIS server-specific format |
|
|
Procedure: In the Processor Configurations section of the Logtail Configuration page, click Add Processor and select :
-
Log Format: Select the log format for your IIS server.
-
IIS: The log file format for Microsoft Internet Information Services.
-
NCSA: Common Log Format.
-
W3C refers to the W3C Extended Log File Format.
-
-
IIS Configuration Fields: When you select IIS or NCSA, SLS uses the default IIS configuration fields. When you select W3C, you must set the fields to the value of the
logExtFileFlagsparameter in your IIS configuration file. For example:logExtFileFlags="Date, Time, ClientIP, UserName, SiteName, ComputerName, ServerIP, Method, UriStem, UriQuery, HttpStatus, Win32Status, BytesSent, BytesRecv, TimeTaken, ServerPort, UserAgent, Cookie, Referer, ProtocolVersion, Host, HttpSubStatus" -
For other parameters, see the description of common configuration parameters in Use case 2: Structured logs.
For information about other parameters, see the general parameter descriptions in Scenario 2: Structured Logs.
Data masking
Mask sensitive data in logs.
Example:
|
Raw log without any processing |
Masking result |
|
|
Procedure: In the Processor Configurations section of the Logtail Configuration page, click Add Processor and select :
-
Original Field: The field that contains the log content before parsing.
-
Data Masking Method:
-
const: Replaces sensitive content with a constant string.
-
md5: Replaces sensitive content with its MD5 hash.
-
-
Replacement String: If Data Masking Method is set to const, enter a string to replace the sensitive content.
-
Content Expression that Precedes Replaced Content: The expression used to find sensitive content, which is configured using RE2 syntax.
-
Content Expression to Match Replaced Content: The regular expression used to match sensitive content. The expression must be written in RE2 syntax.
Time parsing
Parse the time field in the log and set the parsing result as the log's __time__ field.
Example:
|
Raw log without any processing |
Time parsing |
|
|
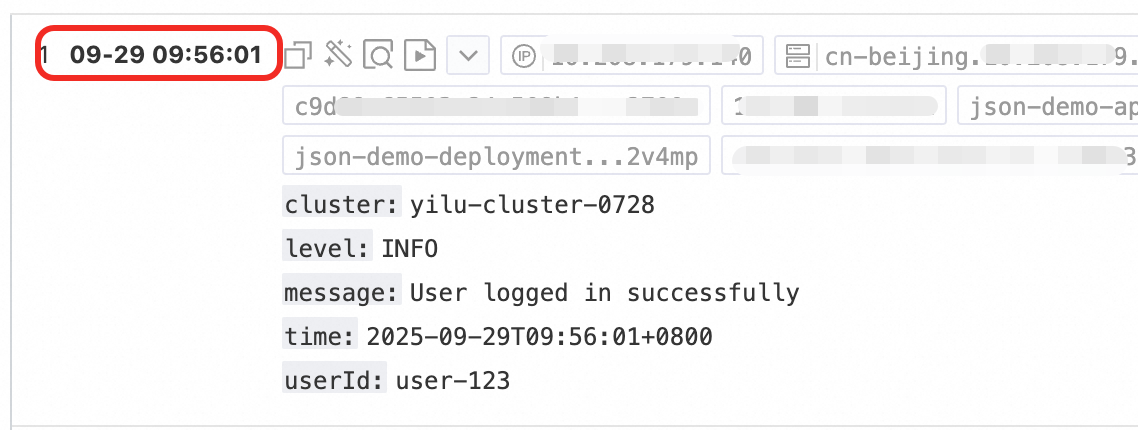
Procedure: In the Processor Configurations section of the Logtail Configuration page, click Add Processor and select :
-
Original Field: The field that contains the log content before parsing.
-
Time Format: Set the time format that corresponds to the timestamps in the log.
-
Time Zone: Select the time zone for the log time field. By default, this is the time zone of the environment where the LoongCollector (Logtail) process is running.