Sharding models for different programming languages
SchedulerX splits large jobs into shards that run in parallel across multiple workers. This distributed approach speeds up big data computing tasks such as batch-processing database tables. SchedulerX supports sharding jobs in Java, Python, Shell, and Go.
How sharding works
A sharding job divides work into numbered units called shards. SchedulerX assigns these shards to the available workers in your application group. Each worker processes only its assigned shards.
Static sharding vs. dynamic sharding
SchedulerX provides two sharding models:
| Model | Use case | Example |
|---|---|---|
| Static sharding | Fixed number of shards | Split 1,024 database tables across workers for parallel processing |
| Dynamic sharding | Unknown or changing data volume | Process a continuously growing table in batches using MapReduce |
Static sharding is compatible with elastic-job. Dynamic sharding uses the SchedulerX MapReduce model, which is the mainstream framework and is not open source.
High availability, throttling, and resharding
All sharding jobs are built on the MapReduce model and include the following features:
| Feature | Description |
|---|---|
| High availability | If a worker fails, the master worker automatically reassigns its shards to a healthy worker. |
| Traffic throttling | Controls how many shards each worker processes in parallel. For example, with 1,000 shards across 10 workers, set each worker to run at most 5 shards at a time. The remaining shards wait in queue. |
| Automatic resharding | Automatically reruns failed tasks without manual intervention. |
Configure high availability and traffic throttling in the advanced settings when you create a job. For details, see Create a job and Advanced parameters for job management.
Shard access methods by language
Each language accesses the shard index and shard parameter through different mechanisms:
| Language | Shard index | Shard parameter |
|---|---|---|
| Java | context.getShardingId() | context.getShardingParameter() |
| Python | sys.argv[1] | sys.argv[2] |
| Shell | $1 | $2 |
| Go | os.Args[1] | os.Args[2] |
Create a Java sharding job
Prerequisites
Before you begin, make sure that you have:
A SchedulerX application group with connected workers
SchedulerX agent version 1.1.0 or later (required for multi-language sharding)
Step 1: Configure the job in the console
Log on to the SchedulerX console.
In the top navigation bar, select a region.
In the left-side navigation pane, click Task Management.
On the Jobs page, select a namespace from the Namespace drop-down list and click Create task.
In the Basic configuration step of the Create task wizard, set Execution mode to Shard run.
In the Sharding parameters field, define the mapping between shard indexes and parameters. Separate multiple sharding parameters with commas (,) or specify only one sharding parameter in each line. Use the format
Shard index 1=Shard parameter 1,Shard index 2=Shard parameter 2,.... For example:0=order_db,1=user_db,2=payment_db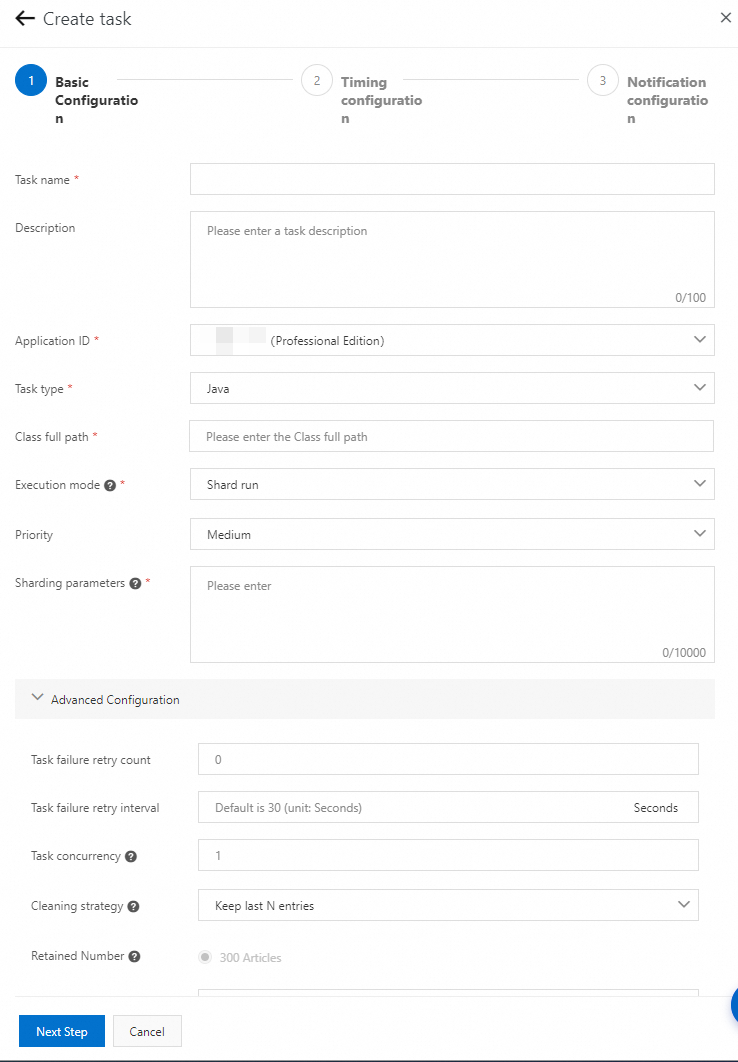
Click Next Step and complete the remaining configuration.
Step 2: Implement the processor in your application
Extend JavaProcessor and use JobContext to retrieve the shard index and parameter:
@Component
public class HelloWorldProcessor extends JavaProcessor {
@Override
public ProcessResult process(JobContext context) throws Exception {
System.out.println("Shard index=" + context.getShardingId() + ", Shard parameter=" + context.getShardingParameter());
return new ProcessResult(true);
}
}Step 3: Verify the result
On the Instances page, find the job and click Details in the Operation column to view the execution result for each shard.
Create a Python sharding job
To run a Python sharding job, install the SchedulerX agent on your application server. SchedulerX distributes and maintains the script across workers automatically.
Prerequisites
Before you begin, make sure that you have:
A SchedulerX application group with connected workers
SchedulerX agent version 1.1.0 or later
The SchedulerX agent installed on your application server
Steps
Download the SchedulerX agent and deploy your script. For agent setup details, see Create a job.
Create a sharding job in the SchedulerX console. Set Execution mode to Shard run and define sharding parameters. Separate multiple sharding parameters with commas (,) or specify only one sharding parameter in each line. Use the format
Shard index 1=Shard parameter 1,Shard index 2=Shard parameter 2,.... For example:0=order_db,1=user_db,2=payment_dbIn your Python script, read the shard index from
sys.argv[1]and the shard parameter fromsys.argv[2]. Branch your processing logic based on the shard parameter:import sys shard_index = sys.argv[1] shard_param = sys.argv[2] print(f"Processing shard {shard_index}: {shard_param}") if shard_param == "order_db": # Process order database pass elif shard_param == "user_db": # Process user database pass elif shard_param == "payment_db": # Process payment database pass else: print(f"Unknown shard parameter: {shard_param}") sys.exit(1)On the Instances page, find the job and click Details in the Operation column to verify the result.
Create a Shell sharding job
Shell sharding jobs follow the same setup process as Python sharding jobs. Install the SchedulerX agent, create a sharding job in the console with Execution mode set to Shard run, and access the shard context through positional arguments.
#!/bin/bash
shard_index=$1
shard_param=$2
echo "Processing shard ${shard_index}: ${shard_param}"
case "${shard_param}" in
"order_db")
# Process order database
;;
"user_db")
# Process user database
;;
"payment_db")
# Process payment database
;;
*)
echo "Unknown shard parameter: ${shard_param}"
exit 1
;;
esacFor the full setup procedure, see Create a Python sharding job.
Create a Go sharding job
Go sharding jobs follow the same setup process as Python sharding jobs. Install the SchedulerX agent, create a sharding job in the console with Execution mode set to Shard run, and access the shard context through os.Args.
package main
import (
"fmt"
"os"
)
func main() {
shardIndex := os.Args[1]
shardParam := os.Args[2]
fmt.Printf("Processing shard %s: %s\n", shardIndex, shardParam)
switch shardParam {
case "order_db":
// Process order database
case "user_db":
// Process user database
case "payment_db":
// Process payment database
default:
fmt.Printf("Unknown shard parameter: %s\n", shardParam)
os.Exit(1)
}
}For the full setup procedure, see Create a Python sharding job.