AI Agents must continuously track context in multi-turn conversations, a task that demands low latency and high concurrency from the memory layer. This article uses the "one-sentence food ordering" scenario in Taobao Flash Sale as a case study to demonstrate how to build a high-performance short-term memory system for AI Agents using Tair's data structures, distributed locks, and elastic scaling capabilities.
Business background
The Taobao Flash Sale AI Agent allows users to complete the entire ordering process, from recommendations to checkout and payment, using natural language. The goal is to reduce the traditional 3-to-5-minute ordering time to under 30 seconds.
When a user says, "Order me a Baiya Juexian from Chagee with less sugar, no ice, and deliver it to my office," the underlying AI Agent must complete a series of operations within seconds: intent recognition, address parsing, product search, specification matching, adding items to the cart, and placing the order. Each step relies on an accurate memory of the preceding conversation.
In the "one-sentence food ordering" project, a collaboration between Taobao Flash Sale and Qianwen, Tair is the core of the AI Agent's short-term memory layer. Drawing from this real-world business scenario, this article introduces key practices for AI Agent memory management with Tair, including data model design and concurrency control.
Applicable scenarios
The design patterns in this article apply to the following AI Agent scenarios:
Conversational agents that need to maintain context across multi-turn conversations, such as customer service bots, shopping assistants, and personal assistants.
Real-time interactive scenarios that are sensitive to end-to-end latency and require millisecond-level memory read and write operations.
Multi-tool invocation scenarios with a risk of concurrent writes, such as an AI Agent calling multiple tools simultaneously.
Online services with fluctuating traffic that require elastic scaling.
Why memory systems need Tair
An AI Agent's memory system is extremely sensitive to latency. According to Little's Law (Concurrency ≈ QPS × Latency), if memory access latency increases from 5 ms to 50 ms, the number of in-flight requests multiplies tenfold. This can quickly exhaust resources such as connections, threads, and queues. Since each conversational turn involves multiple memory reads and writes, latency compounds, potentially leading to queuing, timeouts, and even cascading failures.
The difference between 5 ms and 50 ms is not just a user experience optimization; it is the dividing line between a system that can scale stably and one that cannot. This is the core reason the Taobao Flash Sale AI Agent chose Tair for its memory layer. With its proprietary multi-threaded kernel, Tair provides stable low latency. This keeps memory access within a safe threshold, fundamentally preventing a vicious cycle of performance degradation under high concurrency.
Overall architecture
The memory layer (Memory Service) of the Taobao Flash Sale AI Agent sits between the agent orchestrator and the underlying tool services and uses Tair to manage session-level state.
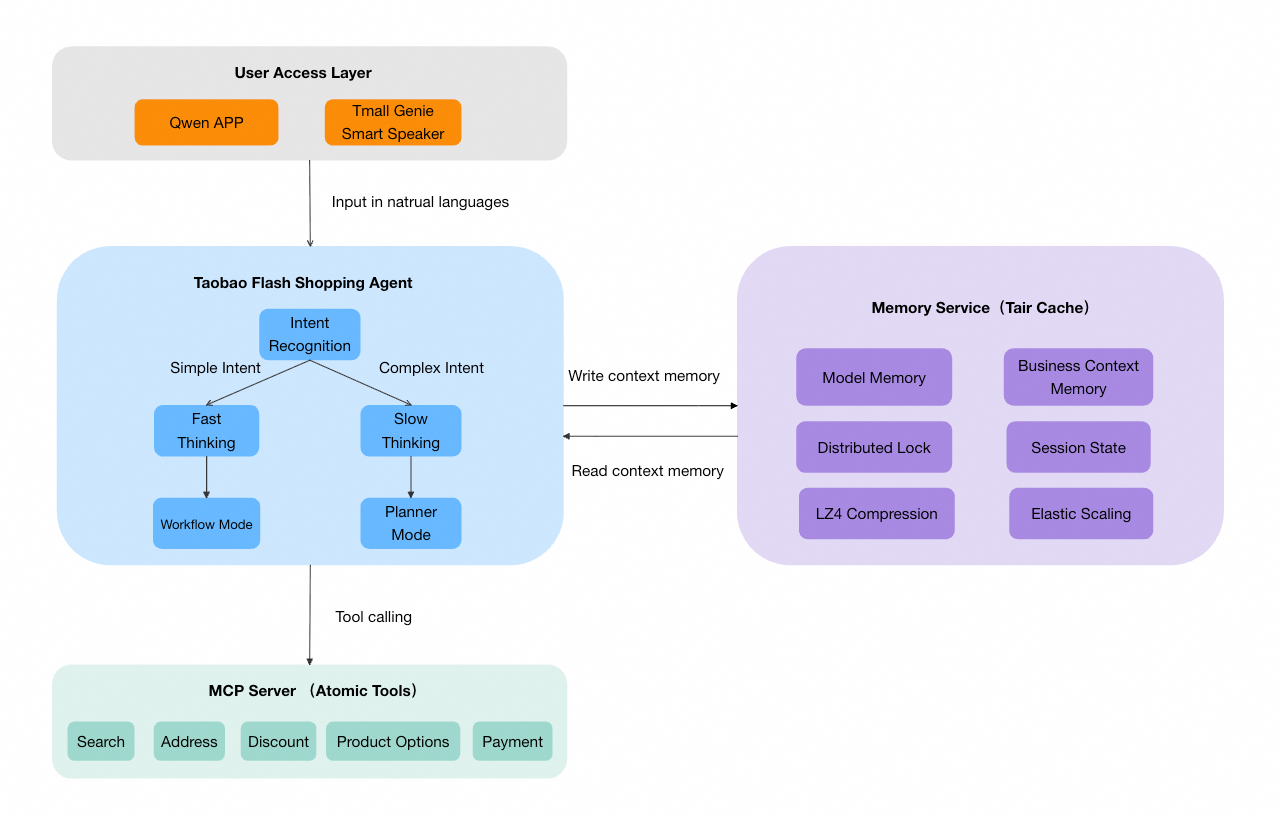
Memory classification and data model
The Taobao Flash Sale AI Agent chose Tair as its short-term memory storage engine for several key reasons:
Low latency: An agent's conversational flow is extremely sensitive to response time. Tair's proprietary multi-threaded kernel provides microsecond-level read and write capabilities, meeting the demands of real-time interaction.
Rich data structures: Tair allows you to map different memory types to the most suitable data structures, which simplifies application development.
Elastic scaling: Tair supports seamless cluster scaling and burstable bandwidth, enabling rapid expansion during traffic peaks without impacting business operations.
TTL lifecycle management: Session memory naturally expires, and its TTL mechanism automatically removes expired data.
Short-term memory is divided into two main categories, each mapped to a different Tair data structure:
Model memory — List
Model memory stores the conversation history for the large language model (LLM) to process. In each turn, the agent records the user's input and its own response, passing them as context to the model during the next inference round.
This history is stored in a Tair List, with one key per session:
Key: memory:model:{sessionId}
Type: List
Example data:
[
{"role": "user", "content": "I'd like to order a milk tea."},
{"role": "assistant", "content": "I found 3 milk tea shops near you...", "cards": [...]},
{"role": "user", "content": "This one, less sugar and no ice."},
{"role": "assistant", "content": "Selected: Baiya Juexian, less sugar, no ice, large..."}
]Core operations:
# After each conversation turn, append the new dialogue record
RPUSH memory:model:{sessionId} "{Conversation Record JSON}"
# Before model inference, read the last N turns as context
LRANGE memory:model:{sessionId} -{N} -1
# Set a session expiration time (e.g., 30 minutes)
EXPIRE memory:model:{sessionId} 1800The system converts raw conversation data, which includes text and rich media content such as cards, into a natural language format that the model can more easily understand. This reduces token consumption.
Business context memory — Hash
Business context memory stores structured state information from the business process. The agent's tool layer and intent processors query and update this information when executing business logic.
This memory is divided into six sub-modules by business domain and stored in a Tair Hash:
Key: memory:context:{sessionId}
Type: Hash
Field structure:
{
"session": "{Session metadata: user ID, channel, session stage, etc.}",
"search": "{Search status: current query, search results, recommended product list, etc.}",
"order": "{Order status: shopping cart contents, selected SKU, item quantity, etc.}",
"conversation": "{Conversation status: current intent, previous intent, intent switch flag, etc.}",
"coupon": "{Coupon information: available coupons, selected coupon, etc.}",
"bizState": "{Business state: shipping address, delivery method, payment status, etc.}"
}Core operations:
# Update a single sub-module (e.g., when the user confirms a shipping address)
HSET memory:context:{sessionId} bizState "{Updated Business State JSON}"
# Read a specific sub-module
HGET memory:context:{sessionId} order
# Read all context at once (for scenarios requiring global information, like intent recognition)
HGETALL memory:context:{sessionId}
# Set an expiration time
EXPIRE memory:context:{sessionId} 1800The field-level read and write capabilities of the Hash data structure allow each business module to update independently without interfering with others. This avoids the race conditions associated with read-modify-write patterns on a full JSON object. For example, when the search module updates product recommendations, it does not affect the order module, which might be writing data to the shopping cart at the same time.
Data structure comparison
Memory type | Data structure | Reason |
Conversation history | List | Conversations are ordered time-series data. The List data structure supports ordered appends (RPUSH) and range reads (LRANGE). |
Business context memory | Hash | The memory is divided into multiple fields by domain. The Hash data structure supports independent, field-level reads and writes, which prevents race conditions. |
Session state flags | String | The String data structure is suitable for atomic state flags (such as the session stage) that require simple operations. |
Distributed lock | String | It is implemented using SET NX EX to ensure concurrency safety. |
Concurrency safety: Distributed locks
In a real-world application, concurrent writes to the same session can occur. For example, if a user sends messages in quick succession or provides new input while a streaming response is in progress, multiple requests might try to modify the same session's memory data simultaneously.
The Taobao Flash Sale AI Agent uses a Tair distributed lock to protect the read and write consistency of memory. The lock is applied at the individual session level:
# Acquire a session-level distributed lock (with a 3-second timeout to prevent deadlocks)
SET lock:memory:{sessionId} {requestId} NX EX 3
# After acquiring the lock, perform memory read and write operations
HSET memory:context:{sessionId} order "{Updated Order Status}"
RPUSH memory:model:{sessionId} "{New Conversation Record}"
# Release the lock after the operation is complete (using a Lua script to ensure only the lock owner can release it)
EVAL
if redis.call('GET', KEYS[1]) == ARGV[1] then
return redis.call('DEL', KEYS[1])
else
return 0
endThe lock granularity is at the session level (sessionId), not a global lock. This means there is no lock contention between different user sessions, which avoids impacting the overall system throughput. The lock timeout is set to a few seconds to prevent prolonged blocking if the process holding the lock exits unexpectedly.
Handling traffic spikes
During the Qianwen Spring Festival Red Packet event, the Taobao Flash Sale AI Agent handled a concurrency load more than 10 times the estimated peak. Each user conversation can trigger dozens of Tair operations (reading history, updating state, lock operations, etc.), amplifying the agent's concurrent requests into an order-of-magnitude higher volume of Tair operations.
The memory layer of the Taobao Flash Sale AI Agent is built on Tair (Redis-compatible). Compared to a self-managed Redis deployment, Tair's advantages in kernel performance, elastic scaling, and operations were critical for handling this traffic spike.
Tair kernel performance
Tair uses a multi-threaded model, delivering up to three times the read and write performance of an open-source Redis instance of the same specification. This means that for the same instance size, Tair can handle three times the operational throughput of open-source Redis.
This performance advantage is particularly critical in AI Agent scenarios. A single user conversation can trigger dozens of Tair operations, such as reading conversation history, updating business context, and acquiring or releasing distributed locks. With the single-threaded model of open-source Redis, the database can easily become a bottleneck under high concurrency. Tair's multi-threaded kernel allows a single node to fully utilize multi-core CPU resources, enabling it to handle higher concurrency without needing to add more nodes.
Elastic and seamless scaling
In an agent's conversational flow, memory data exhibits a typical read-heavy pattern: the agent must read the complete conversation history and business context before each inference round (read operations), while a write operation only occurs to append a new record at the end of each turn. The read-to-write ratio is typically between 5:1 and 10:1.
Tair supports a cluster architecture with read/write splitting. Tair then automatically distributes read requests to the read replicas, while write requests are routed to the primary node. The number of read replicas can be flexibly adjusted from 1 to 9, and the cluster can be scaled horizontally from 2 to 256 shards. You can linearly increase throughput by adding read replicas or shards before a traffic peak and then scale them down afterward to reduce costs.
Example
Normal traffic: An 8-shard cluster with 1 read replica per shard meets daily business needs.
Spring Festival event (5x to 10x peak traffic):
Option 1: Scale out to 5 read replicas per shard for a linear increase in read throughput.
Option 2: Scale out to a 16-shard cluster with 3 read replicas per shard to double both read and write capacity.
These scaling operations are completely transparent to your services. Traditional Redis clusters may produce errors such as -ASK and -TRYAGAIN during slot migration. For agent-based conversational scenarios, any request failure can lead to conversation interruption or memory loss. The cloud-native edition of Tair achieves seamless scaling through kernel-level optimizations—data is migrated atomically as an entire slot (rather than on a key-by-key basis), which prevents slot splitting. At the same time, a centralized control component coordinates cluster behavior, resulting in higher migration efficiency and more precise decision-making.
During the final stage of data migration, the latency of write requests to the corresponding slot may increase slightly, but the requests will not fail. For the agent's memory service, this means some requests might experience a minor increase in latency, but there will be no data loss or request errors.
Elastic bandwidth scaling
In addition to QPS pressure, the event also presented a significant bandwidth challenge. Each memory read by the AI Agent involves transferring conversation history and business context, resulting in a much larger data payload per request compared to simple key-value reads in traditional caching scenarios. During peak business hours, bandwidth can become a bottleneck before CPU or memory.
The Tair architecture provides two layers of elasticity:
Horizontal scaling for cluster bandwidth: In a cluster architecture, you can increase the total instance bandwidth by adding more load balancers (LBs). A single LB has a bandwidth limit of 20 Gbps. When the number of shards exceeds eight, you can add LBs as needed without interrupting existing connections.
Burstable bandwidth: When instantaneous traffic exceeds the fixed bandwidth, the system automatically scales up the bandwidth in seconds (up to a maximum of 288 MB/s per node). The system automatically releases the bandwidth when traffic subsides and bills you only for the burst amount used. Burstable bandwidth operates independently for each shard. If a shard experiences a bandwidth bottleneck due to a hot key, only that shard's bandwidth is automatically expanded, leaving other shards unaffected.
NoteBurstable bandwidth is particularly well-suited for the unpredictable traffic spikes common in AI Agent scenarios. Compared to pre-purchasing a high-spec fixed bandwidth package, on-demand bursting is more cost-effective.
Automatic TTL cleanup
By setting a reasonable TTL (for example, 30 minutes) on all session keys, memory usage automatically decreases after traffic peaks without manual intervention. Combined with Tair's elastic scaling, this enables fully automated resource management: scaling out for peaks, scaling in for troughs, and automatically cleaning up expired data.
As a result, the entire memory service remained stable during the Spring Festival traffic surge, with P99 latency consistently controlled at the millisecond level.
Summary and outlook
In the "one-sentence food ordering" use case for Taobao Flash Sale, Tair served as the core storage for the AI Agent's short-term memory layer, providing the following key capabilities:
Capability | Implementation | Problem solved |
Low-latency access | In-memory reads and writes with Tair | Meets the real-time requirements of the agent's conversational flow. |
Flexible data modeling | Combination of List, Hash, and String data structures | Adapts to different memory types, such as conversation history and business context. |
Lifecycle management | Automatic expiration with TTL | Automatically removes data after a session ends, reducing operational costs. |
Concurrency safety | Distributed locks (SET NX EX) | Ensures data consistency during concurrent writes from multiple requests. |
Elastic resilience | Read/write splitting and burstable bandwidth | Supports massive traffic spikes (such as a 10x peak during the Spring Festival event) with seamless elasticity. |
As AI Agent technology evolves, memory management is advancing to deeper levels. Future plans include building long-term memory capabilities to store user preferences and historical behavior patterns. This will allow the agent to remember not just "what was said in this conversation," but also "who this user is and what they like."
The memory system for AI Agents is evolving from "conversation-level" to "user-level," and Tair will continue to play a critical role in this evolution.