In Tair (Redis OSS-compatible) instances that use the cluster architecture or read/write splitting architecture, proxy nodes are responsible for request routing, load balancing, and failover. Proxy nodes can simplify client-side logic and support advanced features such as multiple databases (DBs) and caching hotkeys. Understanding the routing rules of proxy nodes and how they handle specific commands helps you design more efficient business systems.
Overview of proxy nodes
A proxy node is a standalone component in a Tair instance. It does not consume the resources of data shards. Tair uses multiple proxy nodes to implement load balancing and failover.
Capability | Description |
Usage mode transition for cluster instances | Proxy nodes can bridge architectures, allowing you to use a cluster architecture instance as if it were a standalone one. Proxy nodes support cross-slot operations for commands that manage multiple keys, such as DEL, EXISTS, MGET, MSET, SDIFF, and UNLINK. For more information, see List of commands supported in proxy mode. When a standalone architecture instance can no longer meet your business requirements, you can migrate data to a cluster architecture instance with proxy nodes without modifying your code. This significantly reduces business transformation costs. |
Load balancing and request routing | Proxy nodes establish persistent connections with backend data shards and handle request routing and load balancing. For more information about routing, see Routing rules of proxy nodes. |
Manage traffic to read replicas | Proxy nodes continuously monitor the status of read replicas and control traffic in the following situations:
|
After you enable the proxy query cache feature, proxy nodes cache requests that contain hotkeys and their corresponding responses. When a proxy node receives the same request within the cache validity period, it directly returns the result to the client without interacting with the backend data shards. This helps mitigate access skew caused by a large number of read requests to hotkeys. Note You can enable this feature by setting the query_cache_enabled parameter. This feature is available only for Tair Memory-optimized and Persistent Memory-optimized instances. | |
Support for multiple databases (DBs) | In cluster mode, native Redis and cluster clients do not support multiple databases (DBs). They only use the default database Note If you use a StackExchange.Redis client, you must use version 2.7.20 or later. Otherwise, an error occurs. For more information, see the StackExchange.Redis upgrade announcement. |
As proxy technology evolves, the number of proxy nodes is not the only factor that determines processing capacity. Alibaba Cloud ensures that the ratio of proxy nodes in a cluster instance meets the specified requirements.
Routing rules of proxy nodes
For more information about commands, see Command overview.
Architecture | Routing rule | Description |
Cluster architecture | Basic routing rules |
|
Routing rules for specific commands |
| |
Read/write splitting architecture | Basic routing rules |
|
Routing rules for specific commands |
|
Proxy query cache
Proxy nodes can cache requests that contain hotkeys and their corresponding query results. When a proxy node receives the same request within the cache validity period, it directly returns the result to the client without interacting with the backend data shards. This feature can mitigate or prevent performance degradation caused by access skew from a high volume of read requests to hotkeys.
The database kernel identifies a hotkey using sorting and statistical algorithms, similar to the Hot Key (QPS) in the Top Key Analytics feature. By default, a key is identified as a hotkey if its QPS exceeds 5,000. You can also customize this threshold using the
bigkey-thresholdparameter.If a hotkey is modified while its data is cached, the changes are not synchronized to the cache. This means that subsequent requests may read stale data from the cache until the cache entry expires. You can shorten the cache validity period based on your business requirements.
Proxy nodes do not cache the entire hotkey. Instead, they cache the requests that contain the hotkey and the corresponding query results.
This feature is available only for Tair Memory-optimized and Persistent Memory-optimized instances that use the cluster architecture in proxy mode or the read/write splitting architecture.
Use cases
This feature is suitable for scenarios such as trending topic lists, popular user profiles, and game announcements, where applications can tolerate slightly stale data.
Architecture

Usage
This feature is disabled by default. You can enable it by setting the query_cache_enabled parameter.
Parameters
You can use the Tair-developed QUERYCACHE KEYS, QUERYCACHE INFO, and QUERYCACHE LISTALL commands to view the usage of the Tair proxy query cache.
Commands
Connection usage
Typically, a proxy node establishes persistent connections with data shards to process requests. However, when a request includes one of the following commands, the proxy node creates additional, non-aggregatable connections on the corresponding data shards based on the command's requirements. In these cases, the maximum number of connections for the instance is limited by the connection limit of a single data shard. For information about the connection limit of a single shard, see the specifications of your instance. Use these commands with care to avoid exceeding the connection limit.
In proxy mode, the maximum number of connections for each data shard is 10,000 for Redis Open-Source Edition instances and 30,000 for Tair (Enterprise Edition) instances.
Blocking commands: BRPOP, BRPOPLPUSH, BLPOP, BZPOPMAX, BZPOPMIN, BLMOVE, BLMPOP, and BZMPOP.
Transaction commands: MULTI, EXEC, and WATCH.
MONITOR commands: MONITOR, IMONITOR, and RIMONITOR.
Subscription commands: SUBSCRIBE, UNSUBSCRIBE, PSUBSCRIBE, PUNSUBSCRIBE, SSUBSCRIBE, and SUNSUBSCRIBE.
FAQ
-
Can I forward Lua scripts that perform only read operations to read replicas?
Yes, you can forward Lua scripts that perform only read operations to read replicas. However, the following requirements must be met:
-
A read-only account is used. For more information, see Create and manage accounts.
-
The readonly_lua_route_ronode_enable parameter is set to 1 for your Tair instance. A value of 1 indicates that Lua scripts that perform only read operations are routed to read replicas. For more information, see Configure instance parameters.
-
Q: What is the difference between proxy mode and direct connection mode? Which mode is recommended?
A: We recommend using proxy mode. The differences are as follows:
Proxy mode: proxy nodes forward client requests to data shards. This mode provides features such as load balancing, read/write splitting, failover, proxy query cache, and persistent connections.
Direct connection mode: You can use a direct connection endpoint to bypass proxy nodes and connect directly to backend data shards. This is similar to connecting to a native Redis cluster. Compared with proxy mode, direct connection mode reduces proxy processing overhead and improves response latency.
Q: How are data reads and writes affected if a backend data shard becomes unavailable?
Each data shard uses a high-availability master-replica architecture. If a master node fails, the system automatically performs a failover to ensure high availability. The following table describes the impact of a data shard failure on data reads and writes in extreme scenarios and provides optimization solutions.
Scenario
Impact and optimization
Figure 1. Multi-key commands
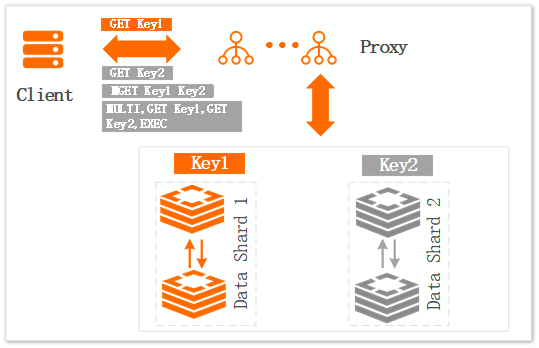
Impact:
A client sends four requests over four connections. If data shard 2 is unavailable, only Request 1 (GET Key1) can read data successfully. Requests that are routed to data shard 2 time out.
Optimization:
Reduce the use of multi-key commands, such as MGET, or reduce the number of keys in a single request. This prevents the entire request from failing due to a single unavailable data shard.
Reduce the use of transaction commands or decrease the size of transactions. This prevents the failure of a sub-transaction from causing the entire transaction to fail.
Figure 2. Single connection
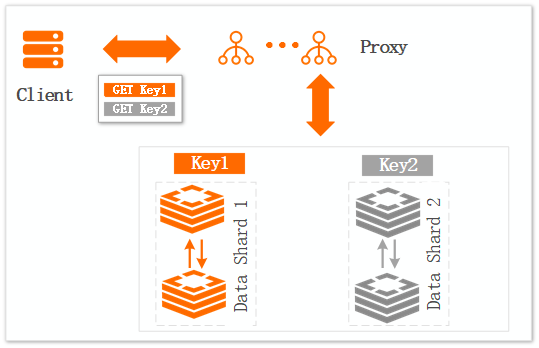
Impact:
A client sends two separate requests over a single connection. If data shard 2 is unavailable, Request 2 (GET Key2) times out. Because Request 1 (GET Key1) shares the same connection, it also fails to return a result.
Optimization:
Avoid or reduce the use of pipeline.
Avoid using clients that support only a single connection. We recommend that you use clients that support connection pooling. For more information, see Client connection tutorial. Ensure you configure a reasonable timeout and connection pool size.