This topic describes the graph analysis based on PolarDB and uses the financial transaction fraud detection scenarios to discover correlation between fraudulent transactions and calculate the Jaccard similarity between transactions to provide fraud warning.
About the graph database engine
Graph analysis is a critical field of data science. It uses graph structures to represent data and perform various computing and analytic tasks. A graph structure consists of nodes (or vertices) and edges, with nodes representing entities and edges representing the relationships between the entities. Graph computing is commonly used in areas including social network analysis, recommendation systems, knowledge graphs, and path optimization.
PolarDB for PostgreSQL is highly compatible with Apache AGE and supports storage and query of knowledge graphs. It allows you to use both the standard ANSI SQL and openCypher graph query language to query data within the same database cluster.
Fully compatible with PolarDB for PostgreSQL
AGE is an extension for PolarDB for PostgreSQL. It can be used in existing PolarDB databases without the need for database reconstruction. AGE leverages all features provided by PolarDB, including transaction support, concurrency control, and various indexing and performance optimization features.
Unified graph and relational queries
AGE enables the concurrent processing of relational and graph data. It allows you to use both SQL and the graph query language in a single query to simplify the handling of complex data models, which improves operation efficiency.
Cypher query language supported
AGE supports the Cypher query language, which is tailored for graph databases. Its syntax is simple and flexible, providing an intuitive approach to querying and manipulating graph data.
High performance
By combining the optimization features provided by PolarDB and indexes tailored for graph data, AGE can efficiently manage large-scale graph data and complex graph queries.
In conclusion, based on the capabilities provided by AGE, PolarDB can handle graph queries in a simple and efficient manner.

Scenarios
Background information
In today's fraud and financial crimes, fraudsters often use methods such as changing identities to work around risk control rules. Graph structures can use graph databases to track user behaviors, analyze discrete fraud data in real time, and identify and effectively prevent fraud acts.
Data and models
The data comes from public datasets in financial transactions. They are transaction records from Vesta, including the devices, transaction addresses, email addresses, and other information related to transactions. These data sets can be used to identify fraudulent transactions and identify risks.
The raw data is in CSV format and contains transaction information (such as transaction IDs, transaction addresses, and email addresses) and transaction identification information (such as device information and device type). A large amount of information is included in the data sets. The following figure outlines the data model. Some details may vary in the actual scenarios.

Vertexes
transactionproductaddr1(Transaction address 1)addr2(Transaction address 2)emaildomain(Email domain name used in the transaction)deviceinfo(Transaction device information)devicetype(Transaction device type)
Edges
transaction_product(Relationship between the transaction and product)transaction_addr1(Relationship between the transaction and address 1)transaction_addr2(Relationship between the transaction and address 2)transaction_emaildomain(Relationship between the transaction and email domain name)transaction_deviceinfo(Relationship between the transaction and device information)transaction_deviceinfo(Relationship between the transaction and device type)
In the preceding model, the transaction is at the center and associated with others using the transaction ID (transactionid ).
Best practices
Age Viewer is a visualization tool for graph databases and can display query results in graphs. For more information, see Age Viewer.
Recommended configurations
For a good experience, the following configurations are recommended for the PolarDB cluster:
Product: Standard Edition
Database engine: PostgreSQL 14
Revision version: >=14.12.23.1
CPU cores: >= 4
Memory: >= 16 GB
Disk capacity: >= 100 GB
Prepare the database
You must use a privileged account to install the extension.
CREATE EXTENSION age;Add the extension to the search path and preload library of the database or user that uses the extension.
Load the extension at the session level:
NoteCompatibility issues may occur when you use Data Management (DMS) to configure the
search_path. In such cases, you can use PolarDB-Tools to execute related statements.SET search_path = ag_catalog, "$user", public; SELECT * FROM get_cypher_keywords() limit 0;Load the extension permanently:
ALTER DATABASE <dbname> SET search_path = ag_catalog, "$user", public; ALTER DATABASE <dbname> SET session_preload_libraries TO 'age';
Write data to the database
Create a graph. Use the
create_graphfunction in theag_catalogschema to create a graph (namedfraud_graph).SELECT create_graph('fraud_graph');Inserts vertexes and edges. The data is downloaded in a CSV file and cannot be directly stored as graph data of vertexes and-edges. Contact us to obtain the Python script for converting data to vertexes and edges in PolarDB. The conversion results are shown in the following sections.
Sample vertex data
SELECT * FROM cypher('fraud_graph', $$ MERGE (v:transaction {transactionid : 2990783, isfraud : 0 } ) RETURN v $$ ) as (n agtype); SELECT * FROM cypher('fraud_graph', $$ MERGE (v:product {productid : 158945 } ) RETURN v $$ ) as (n agtype); SELECT * FROM cypher('fraud_graph', $$ MERGE (v:addr1 {addr1 : '299.0' } ) RETURN v $$ ) as (n agtype); SELECT * FROM cypher('fraud_graph', $$ MERGE (v:addr2 {addr2 : '87.0' } ) RETURN v $$ ) as (n agtype); SELECT * FROM cypher('fraud_graph', $$ MERGE (v:emaildomain {emaildomain : 'gmail.com' } ) RETURN v $$ ) as (n agtype); SELECT * FROM cypher('fraud_graph', $$ MERGE (v:deviceinfo {deviceinfo : 'SM-G920V Build/NRD90M' } ) RETURN v $$ ) as (n agtype); SELECT * FROM cypher('fraud_graph', $$ MERGE (v:devicetype {devicetype : 'mobile' } ) RETURN v $$ ) as (n agtype); ...Sample edge data
SELECT * FROM cypher('fraud_graph', $$ MATCH (a:transaction), (b:product) WHERE a.transactionid = 2990783 AND b.productid = 158945 MERGE (a)-[e:transaction_product]->(b) RETURN e$$) as (e agtype); SELECT * FROM cypher('fraud_graph', $$ MATCH (a:transaction), (b:addr1) WHERE a.transactionid = 2990783 AND b.addr1 = '299.0' MERGE (a)-[e:transaction_addr1]->(b) RETURN e$$) as (e agtype); SELECT * FROM cypher('fraud_graph', $$ MATCH (a:transaction), (b:addr2) WHERE a.transactionid = 2990783 AND b.addr2 = '87.0' MERGE (a)-[e:transaction_addr2]->(b) RETURN e$$) as (e agtype); SELECT * FROM cypher('fraud_graph', $$ MATCH (a:transaction), (b:emaildomain) WHERE a.transactionid = 2990783 AND b.emaildomain = 'gmail.com' MERGE (a)-[e:transaction_emaildomain_p]->(b) RETURN e$$) as (e agtype); SELECT * FROM cypher('fraud_graph', $$ MATCH (a:transaction), (b:deviceinfo) WHERE a.transactionid = 2999403 AND b.deviceinfo = 'SM-G920V Build/NRD90M' MERGE (a)-[e:transaction_deviceinfo]->(b) RETURN e$$) as (e agtype); SELECT * FROM cypher('fraud_graph', $$ MATCH (a:transaction), (b:devicetype) WHERE a.transactionid = 2999404 AND b.devicetype = 'mobile' MERGE (a)-[e:transaction_devicetype]->(b) RETURN e$$) as (e agtype); ...
Save the conversion results as an SQL file and use a client tool (such as psql) to import data.
Examples
Simple queries
Statistics
Count the number of vertexes of each type.
SELECT * FROM cypher('fraud_graph', $$ MATCH (n) RETURN count(*) $$) as (number_of_vertex agtype);Sample result:
number_of_vertex ---- 1076004Count the number of
transactionvertexes.SELECT * FROM cypher('fraud_graph', $$ MATCH (n:transaction) RETURN count(*) $$) as (number_of_transaction agtype);Sample result:
number_of_transaction ---- 545591Query the number of fraudulent transactions in the data.
SELECT * FROM cypher('fraud_graph', $$ MATCH (n:transaction) WHERE n.isfraud = 1 RETURN count(*) $$) as (number_of_fraud_transaction agtype);Sample result:
number_of_fraud_transaction ---- 18919Count the number of edges.
SELECT * FROM cypher('fraud_graph', $$ MATCH ()-[r]->() RETURN count(*) $$) as (number_of_edge agtype);Sample result:
number ------ 2131254
Filter queries and sort queries
Query the transaction information and all associated information for transaction ID 2988706.
SELECT *
FROM cypher('fraud_graph', $$
MATCH (n:transaction)-[r]->(v)
WHERE n.transactionid = 2988706
RETURN v
$$) as (e agtype);Sample result:
e
---------
{"id": 2251799813685249, "label": "addr2", "properties": {"addr2": "87.0"}}::vertex
{"id": 2533274790395906, "label": "emaildomain", "properties": {"emaildomain": "gmail.com"}}::vertex
{"id": 2533274790395906, "label": "emaildomain", "properties": {"emaildomain": "gmail.com"}}::vertex
{"id": 1970324836974595, "label": "addr1", "properties": {"addr1": "325.0"}}::vertex
{"id": 1125899906844295, "label": "product", "properties": {"productid": 137934}}::vertexThe SQL preview result in Age Viewer:
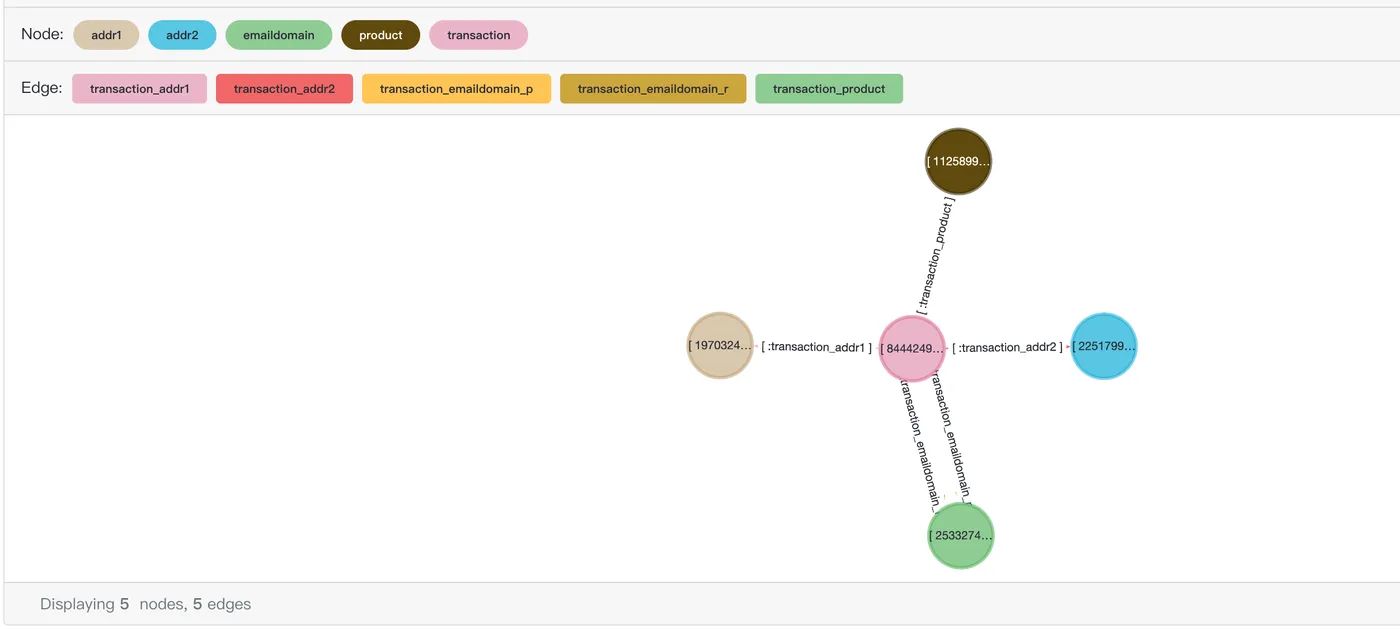
General scenarios
KNNs
The k-nearest neighbor (KNN) method uses the similarity between data nodes to identify potential fraud acts. KNNs can help evaluate the similarity between data nodes. Whether a node is normal can be determined by finding k neighbors with similar features to the data node. For example, a transaction may be marked as suspicious if it differs significantly from most of its neighbors (transaction nodes) in terms of features such as amount, location, and time.
Query transaction records (2-nearest neighbors) in the same address as transaction 2988706. The information about these neighbors can be used to determine whether this transaction is suspicious.
SELECT *
FROM cypher('fraud_graph', $$
MATCH (n:transaction)-[:transaction_addr1]->(:addr1)<-[:transaction_addr1]-(t:transaction)
WHERE n.transactionid = 2988706
RETURN t
$$) as (e agtype);Sample result:
e
-----
{"id": 844424930131972, "label": "transaction", "properties": {"isfraud": 0, "transactionid": 2987001}}::vertex
{"id": 844424930131978, "label": "transaction", "properties": {"isfraud": 0, "transactionid": 2987007}}::vertex
{"id": 844424930132041, "label": "transaction", "properties": {"isfraud": 0, "transactionid": 2987070}}::vertex
{"id": 844424930132053, "label": "transaction", "properties": {"isfraud": 0, "transactionid": 2987082}}::vertex
....The SQL preview result in Age Viewer:
SELECT *
FROM cypher('fraud_graph', $$
MATCH (n:transaction)-[r:transaction_addr1]->(a:addr1)<-[r2:transaction_addr1]-(t:transaction)
WHERE n.transactionid = 2988706
RETURN [n,r,a,r2,t]::path
LIMIT 50
$$) as (e agtype);Only 50 records are returned. More records may cause the frontend system to crash.
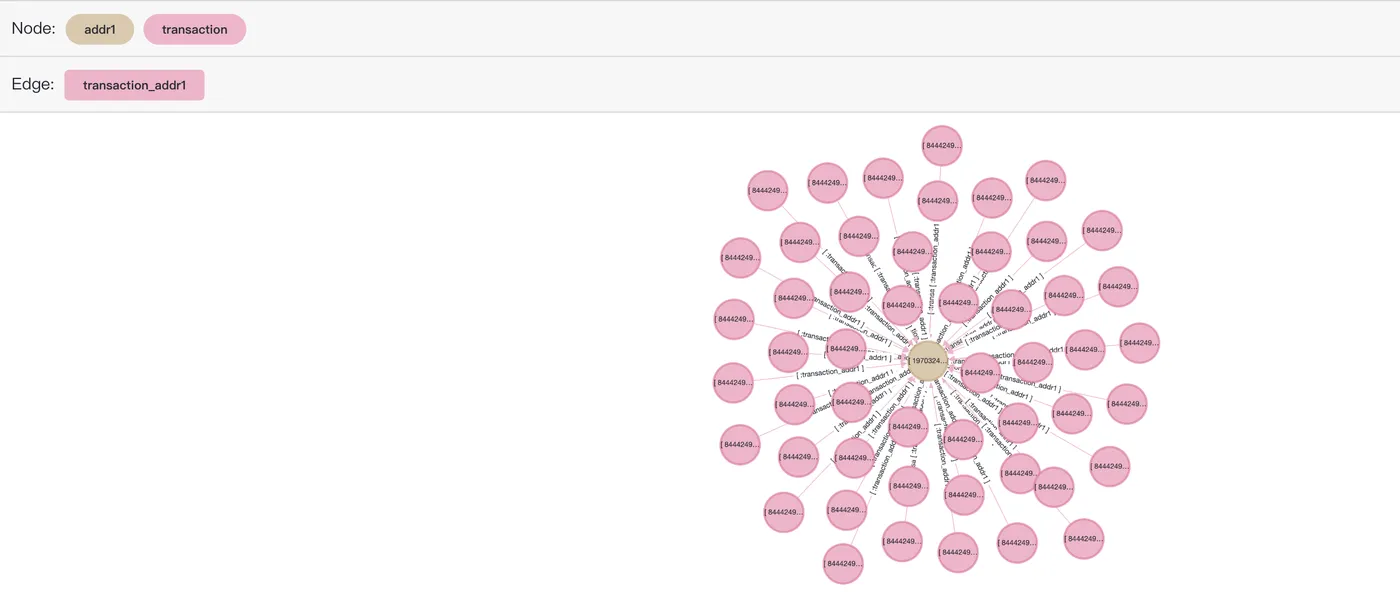
Pathfinding
In identifying fraudulent transactions, paths are mainly reflected in using graph theory and network analysis to identify potential fraud acts. In financial transactions and in the network, a transaction can often be viewed as a graph, with vertexes representing accounts or customers and edges representing activities. By analyzing the structure of this graph, some abnormal patterns and fraud acts can be found. By calculating the path between transactions, you can quickly identify the transaction chain from one suspicious account to other accounts, showing hidden connections between accounts.
Querying the path of a fake transaction between transaction records 2987000 and 2987172 can find all the fake transaction links with the two transaction records.
SELECT *
FROM cypher('fraud_graph', $$
MATCH (n:transaction)-[r]->(v)<-[r1]-(t:transaction)-[r2]->(v2)<-[r3]-(k:transaction)
WHERE n.transactionid = 2987000
and k.transactionid=2987172
and t.isfraud = 1
RETURN t
$$) as (e agtype);Sample result:
e
----
{"id": 844424930618281, "label": "transaction", "properties": {"isfraud": 1, "transactionid": 3473312}}::vertex
{"id": 844424930626886, "label": "transaction", "properties": {"isfraud": 1, "transactionid": 3481917}}::vertex
{"id": 844424930649640, "label": "transaction", "properties": {"isfraud": 1, "transactionid": 3504671}}::vertex
{"id": 844424930631805, "label": "transaction", "properties": {"isfraud": 1, "transactionid": 3486836}}::vertex
{"id": 844424930641980, "label": "transaction", "properties": {"isfraud": 1, "transactionid": 3497011}}::vertex
{"id": 844424930644942, "label": "transaction", "properties": {"isfraud": 1, "transactionid": 3499973}}::vertexThe SQL preview result in Age Viewer:
SELECT *
FROM cypher('fraud_graph', $$
MATCH (n:transaction)-[r]->(v)<-[r1]-(t:transaction)-[r2]->(v2)<-[r3]-(k:transaction)
WHERE n.transactionid = 2987000
and k.transactionid=2987172
and t.isfraud = 1
RETURN [n,r,v,r1,t,r2,v2,r3,k]::path
LIMIT 50
$$) as (e agtype);Only 50 records are returned. More records may cause the frontend system to crash.
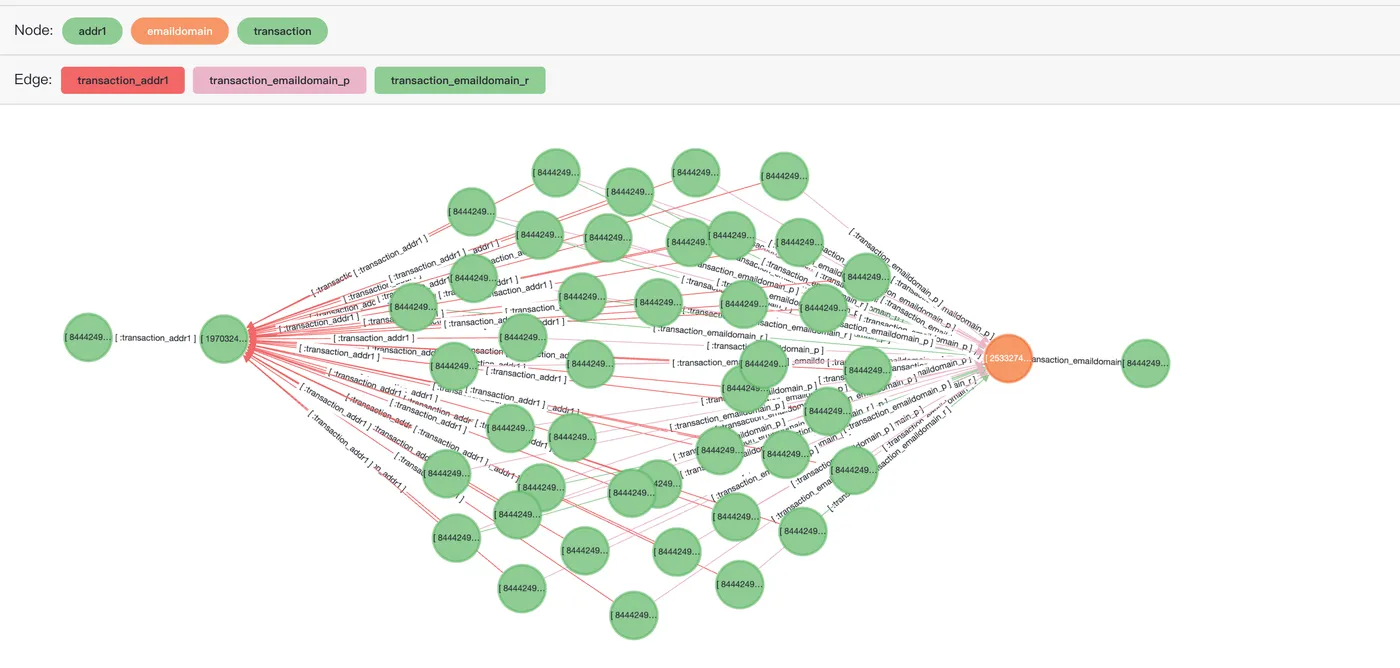
Common neighbor judgment
Common neighbor judgment uses social network or transactional network analysis to identify possible fraud acts. This method is mainly based on the graph theory. The relationship between the transaction participants is analyzed to discover suspicious transaction patterns. If two transactions have multiple common neighbors, and these neighbors have suspicious acts (such as frequent transactions and abnormal amounts), the transaction between the two accounts may be fraudulent.
Query the common neighbors of transaction records 2987000 and 2987172 to find transactions with the same attributes (transaction addresses and devices).
SELECT *
FROM cypher('fraud_graph', $$
MATCH (n:transaction)-[]->(v)<-[]-(t:transaction)
WHERE n.transactionid = 2987000 and t.transactionid=2987172
RETURN v
$$) as (e agtype);Sample result:
e
-----
{"id": 2251799813685249, "label": "addr2", "properties": {"addr2": "87.0"}}::vertex
{"id": 1970324836974594, "label": "addr1", "properties": {"addr1": "315.0"}}::vertexThe SQL preview result in Age Viewer:
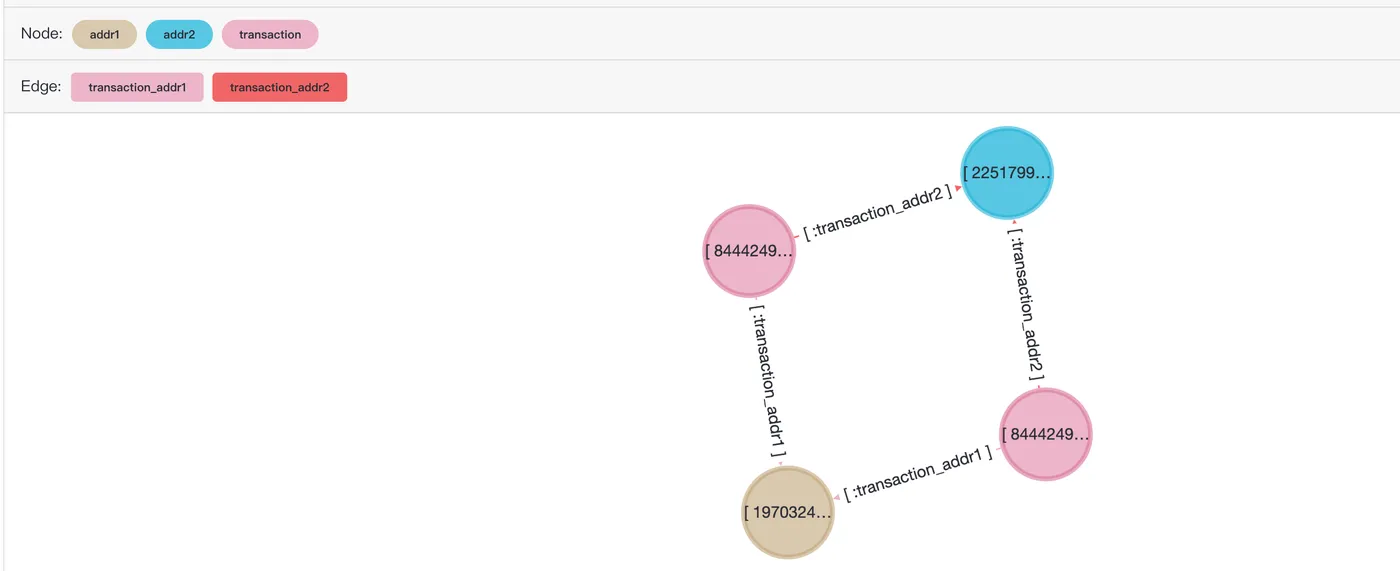
Jaccard similarity
The Jaccard similarity method uses the following formula to measure the similarity between two sets:
J(A,B)is the Jaccard similarity between sets A and B.∣A∩B∣is the intersection of sets A and B.∣A∪B∣is the union of sets A and B.
In fraud detection, the Jaccard similarity method serves multiple purposes:
Pattern identification: Fraud acts often have some common characteristics. Calculating the Jaccard similarity of user transactions or behaviors can identify similar transaction patterns and help detect potential fraud acts.
Customer group analysis: When analyzing customer behavior, Jaccard similarity can be used to compare similarities between different customers. Customers with high similarity may have similar risk characteristics.
The following example calculates the Jaccard similarity between two transactions based on information such as their associated transaction addresses and email addresses. If the associated information overlaps greatly, the transactions are highly similar.
Create the following functions.
The function used to obtain all associated vertexes for a specific transaction and return an array of IDs for all vertexes.
CREATE OR REPLACE FUNCTION find_ids(transactionid integer) RETURNS bigint[] LANGUAGE plpgsql AS $function$ DECLARE sql VARCHAR; ids bigint[]; BEGIN sql := 'SELECT array_agg(cast(e as bigint)) FROM ( SELECT * FROM cypher(''fraud_graph'', $$ MATCH (n:transaction)-[]->(v) WHERE n.transactionid = ' || text($1) || 'RETURN id(v) $$) as (e agtype)) as t;'; EXECUTE sql INTO ids; return ids; END $function$;Two functions for
unionandintersectionof arrays.CREATE OR REPLACE FUNCTION array_union(anyarray, anyarray) RETURNS anyarray LANGUAGE sql immutable AS $$ SELECT array_agg(a ORDER BY a) FROM ( SELECT DISTINCT unnest($1 || $2) AS a ) s; $$; CREATE OR REPLACE FUNCTION array_intersection(anyarray, anyarray) RETURNS anyarray LANGUAGE sql immutable AS $$ SELECT array_agg(e) FROM ( SELECT unnest($1) INTERSECT SELECT unnest($2) ) AS dt(e) $$;The function used to calculate the Jaccard similarity between two transactions.
CREATE OR REPLACE FUNCTION jaccardSimilarity(tid1 integer, tid2 integer) RETURNS float8 LANGUAGE plpgsql AS $function$ DECLARE sql VARCHAR; ids1 bigint[]; ids2 bigint[]; union_list bigint[]; intersection_list bigint[]; BEGIN ids1 = find_ids($1); ids2 = find_ids($2); union_list = array_union(ids1, ids2); -- union intersection_list = array_intersection(ids1, ids2); -- intersection RETURN CASE WHEN array_length(union_list,1) = 0 THEN 0 ELSE array_length(intersection_list,1) * 1.0/ array_length(union_list,1) END AS jaccardSimilarity; END $function$;
Executes the function to calculate the Jaccard similarity.
Compare the similarity between two specified transaction IDs.
SELECT jaccardSimilarity(2987000, 2987172);Sample result:
jaccardsimilarity ---- 0.4
To compare the similarity between all transactions, you can use
PolarDBstored procedures to complete more complex similarity calculation tasks for detecting fraudulent transactions.For example, you can use the following SQL statement to find all transactions that have the same address 1, address 2, and email domain name as transaction 2987002 and sort them by Jaccard similarity to obtain the first 50 transactions with the highest similarity.
WITH tmp AS (SELECT cast(e as integer) as transactionid FROM cypher('fraud_graph', $$ MATCH (n:transaction)-[:transaction_addr2]->(:addr2)<-[:transaction_addr2]-(t:transaction) WHERE n.transactionid = 2987002 MATCH (n:transaction)-[:transaction_addr1]->(:addr1)<-[:transaction_addr1]-(t:transaction) WHERE n.transactionid = 2987002 MATCH (n:transaction)-[:transaction_emaildomain_p]->(:emaildomain)<-[:transaction_emaildomain_p]-(t:transaction) WHERE n.transactionid = 2987002 RETURN t.transactionid $$) as (e agtype) ) SELECT transactionid, jaccardSimilarity(2987002, transactionid) as jaccardSimilarity FROM tmp ORDER by jaccardSimilarity DESC LIMIT 50;Sample result:
transactionid | jaccardsimilarity ---------------+------------------- 3323911 | 0.6 3328911 | 0.6 3009043 | 0.6 3039416 | 0.6 3039425 | 0.6 2993652 | 0.6 3045027 | 0.6 3037644 | 0.6 3045041 | 0.6 ...The SQL preview result in
Age Viewer. The results have been obtained in the previous calculation and only the first 10 transactions are used. If necessary, you can add it to the list.SELECT * FROM cypher('fraud_graph', $$ MATCH (n:transaction)-[r]->(v)<-[r2]-(t:transaction) WHERE n.transactionid = 2987002 AND t.transactionid IN [3323911, 3328911,3009043,3039416,3039425,2993652,3045027,3037644,3045041,3045049,3045279] RETURN [n,r,v,r2,t]::path $$) as (e agtype);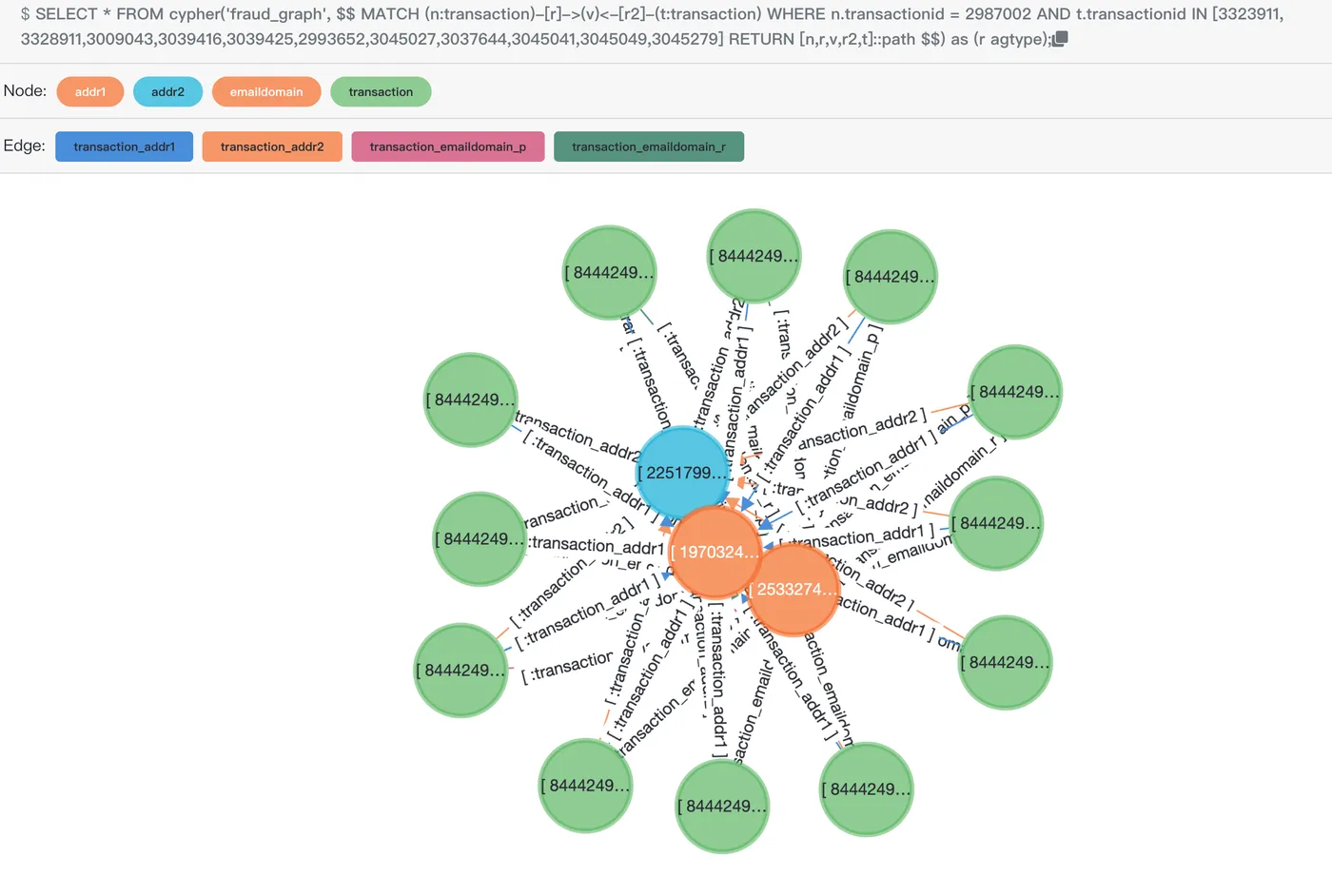
Summary
PolarDB for PostgreSQL can be used in graph analysis. Combined with the Age Viewer extension, PolarDB can be used to compute and analyze graph data, including using the Cypher query language to process and query graph data. This allows enterprises to implement unified data management and analysis.
Trial use
You can visit the PolarDB Free Trial page and select PolarDB for PostgreSQL to experience the graph computing feature of GanosBase.