PolarDBO Flink CDC reads full snapshot data and change data from PolarDB for PostgreSQL (Compatible with Oracle) databases. It is built on the community Postgres CDC connector, with targeted modifications to handle data types and built-in objects that differ between PolarDB for PostgreSQL (Compatible with Oracle) and community PostgreSQL.
Alibaba Cloud does not provide Service-Level Agreement (SLA) guarantees for PolarDBO Flink CDC, whether you build the connector JAR yourself or use the prebuilt JAR provided in this topic.
Version compatibility
| Flink-CDC release | Alibaba Cloud VVR version | JDK |
|---|---|---|
| release-3.5 | vvr-11.4-jdk11-flink-1.20 | JDK 11 |
| release-3.1 | vvr-8.0.x-flink-1.17 | JDK 8 |
| release-2.3 | vvr-4.0.15-flink-1.13 to vvr-6.0.2-flink-1.15 | JDK 8 |
Differences from Postgres CDC
PolarDBO Flink CDC is built on community Postgres CDC. For general syntax and parameters, refer to Postgres CDC. The following differences apply.
| Aspect | Postgres CDC | PolarDBO Flink CDC |
|---|---|---|
connector parameter |
postgres-cdc |
polardbo-cdc |
decoding.plugin.name |
Various | Must be pgoutput. Using other plugins may produce garbled characters for non-UTF-8 encoded databases. See the Debezium documentation. |
| DATE type mapping (Oracle 1.0 and 2.0) | DATE |
Must be TIMESTAMP in both source and sink Flink SQL tables. See Type mapping. |
| Supported databases | Community PostgreSQL | All PolarDB for PostgreSQL versions, PolarDB for PostgreSQL (Compatible with Oracle) 1.0, and PolarDB for PostgreSQL (Compatible with Oracle) 2.0 |
If your database is PolarDB for PostgreSQL (not Compatible with Oracle), use community Postgres CDC directly.
Pipeline connector (release-3.5+)
Release-3.5 and later also support the Pipeline connector mode, which reads both snapshot and incremental data for end-to-end full-database synchronization. Note that Pipeline connectors do not currently support synchronizing table schema changes. See the Postgres CDC Pipeline connector documentation.
Build the PolarDBO Flink CDC connector
This section explains how to build the connector JAR from source. If you prefer to skip building, use the prebuilt JAR links provided at the end of each release section.
Determine dependency versions
Before cloning any code, identify the correct versions for three dependencies.
Flink-CDC version
For Realtime Compute for Apache Flink, find the community Flink-CDC version that maps to your VVR version. See CDC and VVR version mapping. For the Flink-CDC repository, see Flink-CDC on GitHub.
Debezium version
In the pom.xml of your target Flink-CDC version, search for debezium.version. For the Debezium repository, see Debezium on GitHub.
PgJDBC version
In the pom.xml of the Postgres CDC module, search for org.postgresql. The file path differs by release:
-
Releases earlier than 3.0:
flink-connector-postgres-cdc/pom.xml -
Release 3.0 and later:
flink-cdc-connect/flink-cdc-source-connectors/flink-connector-postgres-cdc/pom.xml
For the PgJDBC repository, see PgJDBC on GitHub.
Build release-3.5
Flink-CDC release-3.5 is compatible with vvr-11.4-jdk11-flink-1.20.
-
Clone Flink-CDC, PgJDBC, and Debezium at the required versions.
git clone -b release-3.5 --depth=1 https://github.com/apache/flink-cdc.git git clone -b REL42.7.3 --depth=1 https://github.com/pgjdbc/pgjdbc.git git clone -b v1.9.8.Final --depth=1 https://github.com/debezium/debezium.git -
Copy the required files from PgJDBC and Debezium into the Flink-CDC source tree.
mkdir -p flink-cdc/flink-cdc-connect/flink-cdc-source-connectors/flink-connector-postgres-cdc/src/main/java/org/postgresql/core/v3 mkdir -p flink-cdc/flink-cdc-connect/flink-cdc-source-connectors/flink-connector-postgres-cdc/src/main/java/org/postgresql/jdbc cp pgjdbc/pgjdbc/src/main/java/org/postgresql/core/v3/ConnectionFactoryImpl.java flink-cdc/flink-cdc-connect/flink-cdc-source-connectors/flink-connector-postgres-cdc/src/main/java/org/postgresql/core/v3 cp pgjdbc/pgjdbc/src/main/java/org/postgresql/core/v3/QueryExecutorImpl.java flink-cdc/flink-cdc-connect/flink-cdc-source-connectors/flink-connector-postgres-cdc/src/main/java/org/postgresql/core/v3 cp pgjdbc/pgjdbc/src/main/java/org/postgresql/jdbc/PgDatabaseMetaData.java flink-cdc/flink-cdc-connect/flink-cdc-source-connectors/flink-connector-postgres-cdc/src/main/java/org/postgresql/jdbc cp pgjdbc/pgjdbc/src/main/java/org/postgresql/core/Oid.java flink-cdc/flink-cdc-connect/flink-cdc-source-connectors/flink-connector-postgres-cdc/src/main/java/org/postgresql/core cp debezium/debezium-connector-postgres/src/main/java/io/debezium/connector/postgresql/TypeRegistry.java flink-cdc/flink-cdc-connect/flink-cdc-source-connectors/flink-connector-postgres-cdc/src/main/java/io/debezium/connector/postgresql -
From the
flink-cdcdirectory, apply two upstream bug fixes. These fixes will be merged into the community 3.6 release.cd flink-cdc # Timestamp conversion bug fix git fetch origin 2f32836a783f80f295c9dce339c11afec2a32dc2 git cherry-pick 2f32836a783f80f295c9dce339c11afec2a32dc2 # Implicit behavior (SELECT *) bug fix git fetch origin 0d86de24494a855c2d83f9b1052c2e888e182cb1 git cherry-pick 0d86de24494a855c2d83f9b1052c2e888e182cb1For the full diff of each fix, see the timestamp conversion fix and the implicit behavior fix.
-
Apply the PolarDBO compatibility patch.
git apply release-3.5_support_polardbo.patchDownload the patch file: release-3.5_support_polardbo.patch.
-
Build the connector JAR with Maven (requires JDK 11).
mvn clean install -DskipTests -Dcheckstyle.skip=true -Dspotless.check.skip # The JAR is output to: # flink-cdc-connect/flink-cdc-pipeline-connectors/flink-cdc-pipeline-connector-postgres/target
Prebuilt JAR (JDK 11): flink-cdc-pipeline-connector-polardbo-3.5-SNAPSHOT-20260212.jar
Build release-3.1
Flink-CDC release-3.1 is compatible with vvr-8.0.x-flink-1.17.
-
Clone Flink-CDC, PgJDBC, and Debezium at the required versions.
git clone -b release-3.1 --depth=1 https://github.com/apache/flink-cdc.git git clone -b REL42.5.1 --depth=1 https://github.com/pgjdbc/pgjdbc.git git clone -b v1.9.8.Final --depth=1 https://github.com/debezium/debezium.git -
Copy the required files from PgJDBC and Debezium into the Flink-CDC source tree.
mkdir -p flink-cdc/flink-cdc-connect/flink-cdc-source-connectors/flink-connector-postgres-cdc/src/main/java/org/postgresql/core/v3 mkdir -p flink-cdc/flink-cdc-connect/flink-cdc-source-connectors/flink-connector-postgres-cdc/src/main/java/org/postgresql/jdbc cp pgjdbc/pgjdbc/src/main/java/org/postgresql/core/v3/ConnectionFactoryImpl.java flink-cdc/flink-cdc-connect/flink-cdc-source-connectors/flink-connector-postgres-cdc/src/main/java/org/postgresql/core/v3 cp pgjdbc/pgjdbc/src/main/java/org/postgresql/core/v3/QueryExecutorImpl.java flink-cdc/flink-cdc-connect/flink-cdc-source-connectors/flink-connector-postgres-cdc/src/main/java/org/postgresql/core/v3 cp pgjdbc/pgjdbc/src/main/java/org/postgresql/jdbc/PgDatabaseMetaData.java flink-cdc/flink-cdc-connect/flink-cdc-source-connectors/flink-connector-postgres-cdc/src/main/java/org/postgresql/jdbc cp debezium/debezium-connector-postgres/src/main/java/io/debezium/connector/postgresql/TypeRegistry.java flink-cdc/flink-cdc-connect/flink-cdc-source-connectors/flink-connector-postgres-cdc/src/main/java/io/debezium/connector/postgresql -
Apply the PolarDBO compatibility patch.
git apply release-3.1_support_polardbo.patchDownload the patch file: release-3.1_support_polardbo.patch.
-
Build the connector JAR with Maven (requires JDK 8).
mvn clean install -DskipTests -Dcheckstyle.skip=true -Dspotless.check.skip -Drat.skip=true # The JAR is output to the target folder of flink-sql-connector-postgres-cdc
Prebuilt JAR (JDK 8): flink-sql-connector-postgres-cdc-3.1-SNAPSHOT.jar
Build release-2.3
Flink-CDC release-2.3 is compatible with vvr-4.0.15-flink-1.13 through vvr-6.0.2-flink-1.15.
-
Clone Flink-CDC, PgJDBC, and Debezium at the required versions.
git clone -b release-2.3 --depth=1 https://github.com/apache/flink-cdc.git git clone -b REL42.2.26 --depth=1 https://github.com/pgjdbc/pgjdbc.git git clone -b v1.6.4.Final --depth=1 https://github.com/debezium/debezium.git -
Copy the required files from PgJDBC and Debezium into the Flink-CDC source tree.
mkdir -p flink-cdc/flink-connector-postgres-cdc/src/main/java/org/postgresql/core/v3 mkdir -p flink-cdc/flink-connector-postgres-cdc/src/main/java/org/postgresql/jdbc mkdir -p flink-cdc/flink-connector-postgres-cdc/src/main/java/io/debezium/connector/postgresql cp pgjdbc/pgjdbc/src/main/java/org/postgresql/core/v3/ConnectionFactoryImpl.java flink-cdc/flink-connector-postgres-cdc/src/main/java/org/postgresql/core/v3 cp pgjdbc/pgjdbc/src/main/java/org/postgresql/core/v3/QueryExecutorImpl.java flink-cdc/flink-connector-postgres-cdc/src/main/java/org/postgresql/core/v3 cp pgjdbc/pgjdbc/src/main/java/org/postgresql/jdbc/PgDatabaseMetaData.java flink-cdc/flink-connector-postgres-cdc/src/main/java/org/postgresql/jdbc cp debezium/debezium-connector-postgres/src/main/java/io/debezium/connector/postgresql/TypeRegistry.java flink-cdc/flink-connector-postgres-cdc/src/main/java/io/debezium/connector/postgresql -
Apply the PolarDBO compatibility patch.
git apply release-2.3_support_polardbo.patchDownload the patch file: release-2.3_support_polardbo.patch.
-
Build the connector JAR with Maven (requires JDK 8).
mvn clean install -DskipTests -Dcheckstyle.skip=true -Dspotless.check.skip -Drat.skip=true # The JAR is output to the target folder of flink-sql-connector-postgres-cdc
Prebuilt JAR (JDK 8): flink-sql-connector-postgres-cdc-2.3-SNAPSHOT.jar
Configure the database
PolarDBO Flink CDC reads change stream data through logical replication. Before running a Flink job, complete the following steps on your PolarDB for PostgreSQL (Compatible with Oracle) cluster.
Step 1: Set database parameters
Configure the following parameters on the PolarDB cluster. You can set them in the PolarDB console — see Set cluster parameters.
| Parameter | Required value | Notes |
|---|---|---|
wal_level |
logical |
Adds logical replication metadata to the write-ahead log (WAL). The cluster restarts after you modify this parameter. Plan your maintenance window accordingly. |
max_wal_senders |
Greater than (current replication slots used + slots required by Flink jobs) | Controls the maximum number of WAL sender processes. |
max_replication_slots |
Greater than (current replication slots used + slots required by Flink jobs) | Controls the maximum number of replication slots. |
Step 2: Set REPLICA IDENTITY for each subscribed table
Run the following command for every table you want to capture:
ALTER TABLE schema.table REPLICA IDENTITY FULL;REPLICA IDENTITY is a PostgreSQL table-level setting that controls whether the logical decoding plugin includes the old column values in INSERT and UPDATE events. Setting it to FULL ensures complete data synchronization.
Setting REPLICA IDENTITY to FULL may lock the table. Plan your maintenance window accordingly. To check the current setting before modifying it, run:
SELECT relreplident = 'f' FROM pg_class WHERE relname = 'tablename';Step 3: Verify account permissions
Connect using a privileged account or an account that has all of the following:
-
LOGINpermission -
REPLICATIONpermission -
SELECTpermission on each subscribed table (required for full snapshot reads)
Step 4: Use the primary endpoint
Connect only to the primary endpoint of the PolarDB cluster. Cluster endpoints do not support logical replication.
Additional configuration for partitioned tables (release-3.5+)
For partitioned tables, configure the following. See the Postgres CDC community documentation for details.
-
Set
scan.include-partitioned-tables.enabledtotrue. -
Manually create a PUBLICATION in the database with the
publish_via_partition_root=trueoption, then specify its name using thedebezium.publication.nameparameter. -
Set
table-nameto match only parent tables. The regular expression must not match child tables, or full snapshot data will be duplicated.
Type mapping
Type mappings are identical to community PostgreSQL except for the DATE type, which differs across PolarDB product versions.
| PolarDB for PostgreSQL field type | Flink field type | Notes |
|---|---|---|
| SMALLINT | SMALLINT | |
| INT2 | SMALLINT | |
| SMALLSERIAL | SMALLINT | |
| SERIAL2 | SMALLINT | |
| INTEGER | INT | |
| SERIAL | INT | |
| BIGINT | BIGINT | |
| BIGSERIAL | BIGINT | |
| REAL | FLOAT | |
| FLOAT4 | FLOAT | |
| FLOAT8 | DOUBLE | |
| DOUBLE PRECISION | DOUBLE | |
| NUMERIC(p, s) | DECIMAL(p, s) | |
| DECIMAL(p, s) | DECIMAL(p, s) | |
| BOOLEAN | BOOLEAN | |
| DATE | TIMESTAMP (Oracle 1.0 and 2.0) / DATE (PolarDB for PostgreSQL) | PolarDB for PostgreSQL (Compatible with Oracle) uses a 64-bit DATE type; community PostgreSQL uses 32-bit. For Oracle 1.0 and 2.0, map DATE columns to TIMESTAMP in both source and sink tables. Using DATE causes the error: java.time.DateTimeException: Invalid value for EpochDay (valid values -365243219162 - 365241780471). |
| TIME [(p)] [WITHOUT TIMEZONE] | TIME [(p)] [WITHOUT TIMEZONE] | |
| TIMESTAMP [(p)] [WITHOUT TIMEZONE] | TIMESTAMP [(p)] [WITHOUT TIMEZONE] | |
| CHAR(n) | STRING | |
| CHARACTER(n) | STRING | |
| VARCHAR(n) | STRING | |
| CHARACTER VARYING(n) | STRING | |
| TEXT | STRING | |
| BYTEA | BYTES |
Examples
Source connector
This example synchronizes the shipments table from the flink_source database in a PolarDB for PostgreSQL (Compatible with Oracle) 2.0 cluster to the shipments_sink table in the flink_sink database.
This example validates basic connectivity. For production jobs, tune parameters according to the Postgres CDC documentation.
Prerequisites
PolarDB cluster
-
Purchase a PolarDB for PostgreSQL (Compatible with Oracle) 2.0 cluster on the PolarDB cluster purchase page.
-
View the primary endpoint. If Realtime Compute for Apache Flink and the PolarDB cluster are in the same virtual private cloud (VPC), use the private endpoint. Otherwise, apply for a public endpoint.
-
Create the
flink_sourceandflink_sinkdatabases in the console. See Create a database. -
In
flink_source, create theshipmentstable and insert a test row.CREATE TABLE public.shipments ( shipment_id INT, order_id INT, origin TEXT, destination TEXT, is_arrived BOOLEAN, order_time DATE, PRIMARY KEY (shipment_id) ); ALTER TABLE public.shipments REPLICA IDENTITY FULL; INSERT INTO public.shipments SELECT 1, 1, 'test1', 'test1', false, now(); -
In
flink_sink, create theshipments_sinktable. Note thatorder_timeuses TIMESTAMP, not DATE.CREATE TABLE public.shipments_sink ( shipment_id INT, order_id INT, origin TEXT, destination TEXT, is_arrived BOOLEAN, order_time TIMESTAMP, PRIMARY KEY (shipment_id) );
Realtime Compute for Apache Flink
-
Log on to the Realtime Compute console and purchase a Flink instance. See Purchase Realtime Compute for Apache Flink. Deploy the instance in the same region and VPC as the PolarDB cluster to use the private endpoint.
-
Create a custom connector and upload the PolarDBO Flink CDC JAR. Set Formats to debezium-json. See Create a custom connector.
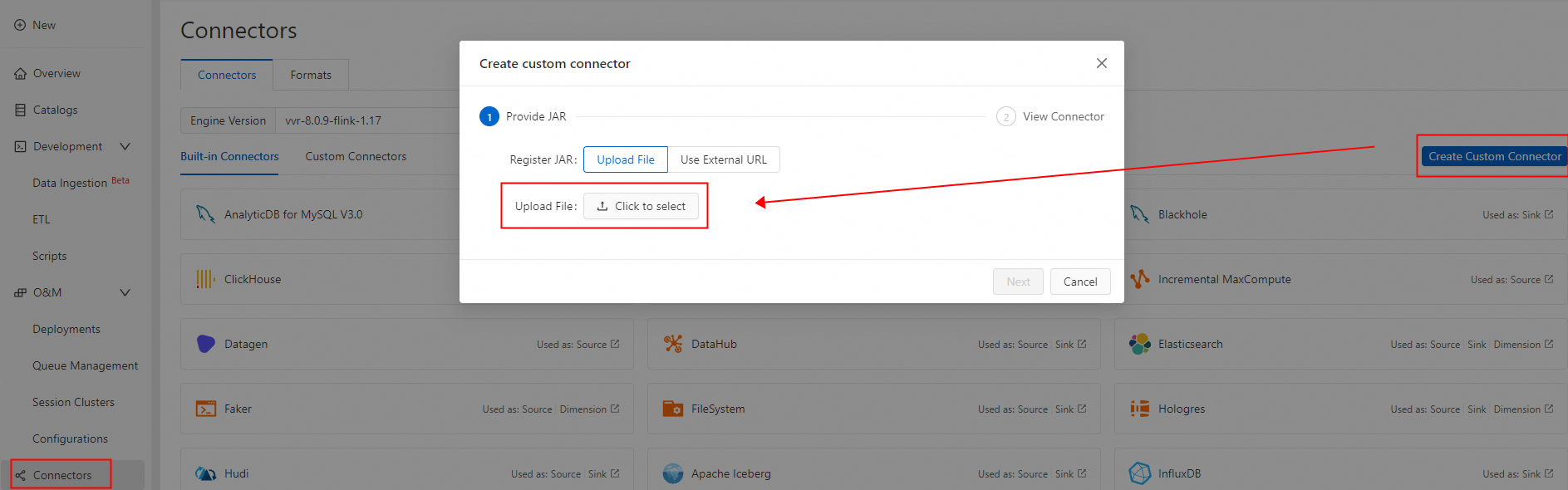
Create and run the Flink job
-
Log on to the Realtime Compute console and create a new SQL job draft. See Develop an SQL draft. Use the following Flink SQL, replacing the placeholders with your PolarDB primary endpoint, port, username, and password.
NoteThe DATE type in PolarDB for PostgreSQL (Compatible with Oracle) is 64-bit. Define
order_timeas TIMESTAMP (not DATE) in both source and sink tables. Using DATE causes a type mismatch error such as:java.time.DateTimeException: Invalid value for EpochDay (valid values -365243219162 - 365241780471): 1720891573000.CREATE TEMPORARY TABLE shipments ( shipment_id INT, order_id INT, origin STRING, destination STRING, is_arrived BOOLEAN, order_time TIMESTAMP, PRIMARY KEY (shipment_id) NOT ENFORCED ) WITH ( 'connector' = 'polardbo-cdc', 'hostname' = '<yourHostname>', 'port' = '<yourPort>', 'username' = '<yourUserName>', 'password' = '<yourPassWord>', 'database-name' = 'flink_source', 'schema-name' = 'public', 'table-name' = 'shipments', 'decoding.plugin.name' = 'pgoutput', 'slot.name' = 'flink' ); CREATE TEMPORARY TABLE shipments_sink ( shipment_id INT, order_id INT, origin STRING, destination STRING, is_arrived BOOLEAN, order_time TIMESTAMP, PRIMARY KEY (shipment_id) NOT ENFORCED ) WITH ( 'connector' = 'jdbc', 'url' = 'jdbc:postgresql://<yourHostname>:<yourPort>/flink_sink', 'table-name' = 'shipments_sink', 'username' = '<yourUserName>', 'password' = '<yourPassWord>' ); INSERT INTO shipments_sink SELECT * FROM shipments; -
Deploy and start the job.

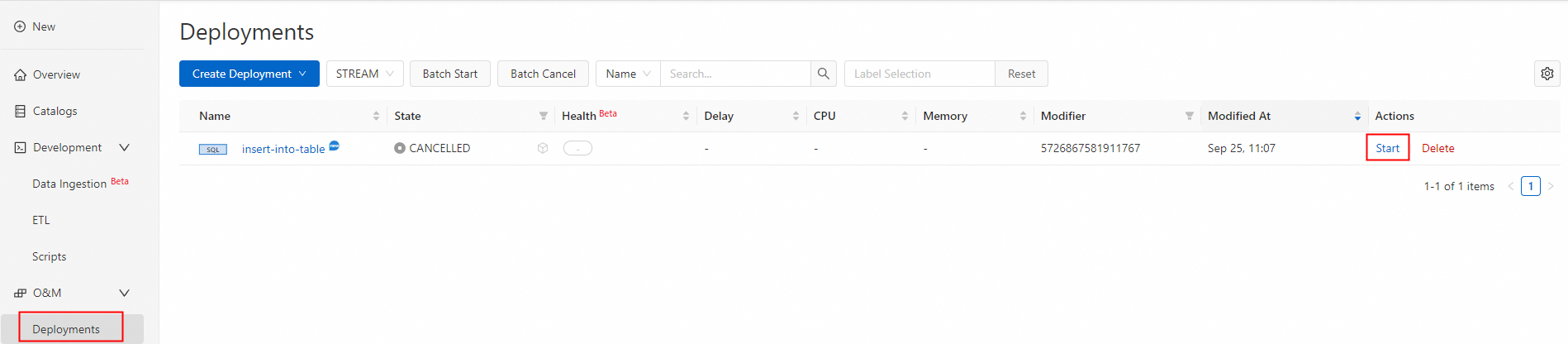
Verify the results
Once the job status changes to Running, query the sink table to confirm the initial snapshot was captured:
SELECT * FROM public.shipments_sink;Expected output:
shipment_id | order_id | origin | destination | is_arrived | order_time
-------------+----------+--------+-------------+------------+---------------------
1 | 1 | test1 | test1 | f | 2024-09-18 05:45:08
(1 row)To validate incremental change capture, run DML operations on the source table:
INSERT INTO public.shipments SELECT 2, 2, 'test2', 'test2', false, now();
UPDATE public.shipments SET is_arrived = true WHERE shipment_id = 1;
DELETE FROM public.shipments WHERE shipment_id = 2;
INSERT INTO public.shipments SELECT 3, 3, 'test3', 'test3', false, now();
UPDATE public.shipments SET is_arrived = true WHERE shipment_id = 3;Query the sink table again:
SELECT * FROM public.shipments_sink;Expected output:
shipment_id | order_id | origin | destination | is_arrived | order_time
-------------+----------+--------+-------------+------------+---------------------
1 | 1 | test1 | test1 | t | 2024-09-18 05:45:08
3 | 3 | test3 | test3 | t | 2024-09-18 07:33:23
(2 rows)Pipeline connector
This example uses the PolarDBO Flink CDC Pipeline connector to synchronize the shipments1 and shipments2 tables from the flink_source database in a PolarDB for PostgreSQL (Compatible with Oracle) 2.0 cluster. It uses the Print connector as a sink for debugging.
This example validates basic connectivity. For production jobs, configure parameters according to the Postgres CDC Pipeline connector documentation.
Prerequisites
PolarDB cluster
-
Purchase a PolarDB for PostgreSQL (Compatible with Oracle) 2.0 cluster on the PolarDB cluster purchase page.
-
View the primary endpoint. If Realtime Compute for Apache Flink and the PolarDB cluster are in the same VPC, use the private endpoint. Otherwise, apply for a public endpoint.
-
Create the
flink_sourcedatabase. See Create a database. -
Create the
shipments1andshipments2tables and insert test data.CREATE TABLE public.shipments1 ( shipment_id INT, order_id INT, origin TEXT, destination TEXT, is_arrived BOOLEAN, order_time DATE, PRIMARY KEY (shipment_id) ); ALTER TABLE public.shipments1 REPLICA IDENTITY FULL; INSERT INTO public.shipments1 SELECT 1, 1, 'test1', 'test1', false, now(); CREATE TABLE public.shipments2 ( shipment_id INT, order_id INT, origin TEXT, destination TEXT, is_arrived BOOLEAN, order_time DATE, PRIMARY KEY (shipment_id) ); ALTER TABLE public.shipments2 REPLICA IDENTITY FULL; INSERT INTO public.shipments2 SELECT 1, 1, 'test1', 'test1', false, now();
Realtime Compute for Apache Flink
Log on to the Realtime Compute console and purchase a Flink instance. See Enable Realtime Compute for Apache Flink. Deploy the instance in the same region and VPC as the PolarDB cluster to use the private endpoint.
Create and run the Flink job
-
Log on to the Realtime Compute console and create a new data ingestion draft. See Flink CDC data ingestion job quick start. Use the following configuration, replacing the placeholders with your PolarDB primary endpoint, port, username, and password.
source: type: polardbo name: PolarDB Oracle Source hostname: '<yourHostname>' port: '<yourPort>' username: '<yourUserName>' password: '<yourPassWord>' tables: flink_source.public.shipments[12] decoding.plugin.name: pgoutput slot.name: pgtest sink: type: values name: values Sink print.enabled: true -
In More Configurations, add the Pipeline connector JAR you built.

-
Click Deploy in the upper right corner.

-
On the job O&M page, click Start.

Verify the results
Once the job is running, open Job logs > Running Task Managers > Stdout to see the snapshot phase events:
CreateTableEvent{tableId=public.shipments2, schema=columns={`shipment_id` INT NOT NULL,`order_id` INT,`origin` STRING,`destination` STRING,`is_arrived` BOOLEAN,`order_time` TIMESTAMP(6)}, primaryKeys=shipment_id, options=()}
CreateTableEvent{tableId=public.shipments1, schema=columns={`shipment_id` INT NOT NULL,`order_id` INT,`origin` STRING,`destination` STRING,`is_arrived` BOOLEAN,`order_time` TIMESTAMP(6)}, primaryKeys=shipment_id, options=()}
DataChangeEvent{tableId=public.shipments2, before=[], after=[1, 1, test1, test1, false, 2026-01-07T16:30:44], op=INSERT, meta=()}
DataChangeEvent{tableId=public.shipments1, before=[], after=[1, 1, test1, test1, false, 2026-01-07T16:30:44], op=INSERT, meta=()}To validate incremental change capture, run DML on the source tables:
INSERT INTO public.shipments1 SELECT 2, 2, 'test2', 'test2', false, now();
UPDATE public.shipments1 SET is_arrived = true WHERE shipment_id = 1;
DELETE FROM public.shipments1 WHERE shipment_id = 2;
INSERT INTO public.shipments1 SELECT 3, 3, 'test3', 'test3', false, now();
UPDATE public.shipments1 SET is_arrived = true WHERE shipment_id = 3;
INSERT INTO public.shipments2 SELECT 2, 2, 'test2', 'test2', false, now();
UPDATE public.shipments2 SET is_arrived = true WHERE shipment_id = 1;
DELETE FROM public.shipments2 WHERE shipment_id = 2;
INSERT INTO public.shipments2 SELECT 3, 3, 'test3', 'test3', false, now();
UPDATE public.shipments2 SET is_arrived = true WHERE shipment_id = 3;The Stdout logs will show corresponding DataChangeEvent entries for the incremental phase:
DataChangeEvent{tableId=public.shipments1, before=[], after=[2, 2, test2, test2, false, 2026-01-07T16:44:50], op=INSERT, meta=()}
DataChangeEvent{tableId=public.shipments1, before=[1, 1, test1, test1, false, 2026-01-07T16:30:44], after=[1, 1, test1, test1, true, 2026-01-07T16:30:44], op=UPDATE, meta=()}
DataChangeEvent{tableId=public.shipments1, before=[2, 2, test2, test2, false, 2026-01-07T16:44:50], after=[], op=DELETE, meta=()}
DataChangeEvent{tableId=public.shipments1, before=[], after=[3, 3, test3, test3, false, 2026-01-07T16:44:50], op=INSERT, meta=()}
DataChangeEvent{tableId=public.shipments1, before=[3, 3, test3, test3, false, 2026-01-07T16:44:50], after=[3, 3, test3, test3, true, 2026-01-07T16:44:50], op=UPDATE, meta=()}
DataChangeEvent{tableId=public.shipments2, before=[], after=[2, 2, test2, test2, false, 2026-01-07T16:44:50], op=INSERT, meta=()}
DataChangeEvent{tableId=public.shipments2, before=[1, 1, test1, test1, false, 2026-01-07T16:30:44], after=[1, 1, test1, test1, true, 2026-01-07T16:30:44], op=UPDATE, meta=()}
DataChangeEvent{tableId=public.shipments2, before=[2, 2, test2, test2, false, 2026-01-07T16:44:50], after=[], op=DELETE, meta=()}
DataChangeEvent{tableId=public.shipments2, before=[], after=[3, 3, test3, test3, false, 2026-01-07T16:44:50], op=INSERT, meta=()}
DataChangeEvent{tableId=public.shipments2, before=[3, 3, test3, test3, false, 2026-01-07T16:44:50], after=[3, 3, test3, test3, true, 2026-01-07T16:44:50], op=UPDATE, meta=()}