In-Memory Column Index (IMCI) adds a column store and in-memory computing layer to PolarDB for MySQL, enabling hybrid transactional and analytical processing (HTAP) on a single cluster — without sacrificing OLTP performance or migrating your data.
Why MySQL needs a column store
MySQL was designed for online transaction processing (OLTP): single-row lookups, concurrent writes, low-latency transactions. As PolarDB clusters routinely store hundreds of terabytes, users increasingly need real-time analytics on the same data that drives their applications. Three architectural approaches have emerged.
MySQL + dedicated AP database
Deploy two separate systems — MySQL for OLTP and a specialized OLAP database for analytics — with a synchronization pipeline between them. You get the best engine for each workload, but the cost is high: two technology stacks to maintain, synchronization latency that keeps analytics data stale, and no straightforward path to real-time consistency.

Multi-replica divergent design
Distributed NewSQL databases like TiDB (starting with version 4.0) assign different storage formats to different replicas within each Raft group. One replica runs TiFlash, a column store, to serve analytical queries; other replicas handle OLTP. Intelligent query routing selects the right replica automatically. This works well for new deployments but requires migrating from MySQL, which introduces compatibility issues.
Integrated hybrid row-column store
The most advanced approach stores both row-oriented and column-oriented data in the same database instance. All major commercial databases use this design:
-
Oracle introduced the Database In-Memory suite in Oracle Database 12c (2013), using in-memory column store with hybrid row-column execution and query optimizations based on materialized expressions and JoinGroup.
-
SQL Server added columnstore indexes in SQL Server 2016 SP1, supporting row-oriented tables, column-oriented tables, and hybrid combinations.
-
IBM Db2 shipped BLU Acceleration in Kepler 10.5 (2013), combining column store, in-memory computing, and data skipping.

All three converged on this design for the same reason: a column store delivers better I/O efficiency (compression, data skipping, column pruning) and better CPU efficiency (cache-friendly access patterns). But column store indexes are sparse — they cannot efficiently locate individual rows the way a B+ tree index can. A hybrid row-column engine resolves this: the row store handles OLTP with precise row-level indexing, while the column store accelerates bulk analytical scans. DRAM's low latency compensates for the performance gap in column store updates.
Why PolarDB needed a new execution engine
PolarDB's capability stack mirrors open source MySQL. While PolarDB handles OLTP efficiently and supports up to 500 TB of data per cluster, complex analytical queries remain slow. The bottlenecks are fundamental to MySQL's architecture:
-
Serial execution model. MySQL's volcano iterator model processes one row at a time. Each row retrieval triggers multiple layers of function calls, including virtual function dispatch. This destroys CPU pipeline efficiency and prevents use of SIMD instructions.
-
No parallel query. MySQL's executor is single-threaded. Parallel query support in MySQL 8.0 covers only basic operations such as
COUNT(*); complex analytical SQL runs serially regardless of how many CPU cores are available. -
Row store I/O waste. When an analytical query needs only 3 columns from a 50-column table, MySQL still reads all 50 columns from disk. Row store format makes selective column access inherently inefficient.
PolarDB's parallel query framework addresses the CPU bottleneck by distributing scan work across multiple threads and aggregating results on the main thread:
Parallel query breaks the single-core ceiling and reduces query time for scan-heavy workloads. But the row store's I/O inefficiency imposes a ceiling that parallel execution alone cannot overcome. Eliminating that ceiling requires a column store.
A column store improves performance at two levels:
-
I/O efficiency. Queries read only the columns they need. Column data compresses with over 10x efficiency compared to row store. Combined with rough indexes (MIN/MAX statistics per data block), large blocks of irrelevant data can be skipped before decompression. In PolarDB's compute-storage separated architecture, less data transferred across the network directly translates to faster query response.
-
CPU efficiency. Column data is stored contiguously, which improves CPU cache hit rates and reduces L1/L2 cache miss stalls. Contiguous column data also enables SIMD vectorization, multiplying single-core throughput.
Key terms
| Term | Definition |
|---|---|
| IMCI | In-Memory Column Index. PolarDB's implementation of a hybrid row-column store. |
| Columnar index | A secondary index in InnoDB that stores column data in columnar format instead of row format. |
| Row group | The unit of data organization in a columnar index. Each row group holds 64,000 rows. |
| Data pack | A single column's data within one row group, stored contiguously and compressed. |
| Rough index | Pre-computed statistics (MIN, MAX, SUM, null count, row count) for each data pack, used to skip irrelevant data packs without decompressing them. |
| In-Memory Column Store Area | The memory region where active data packs are cached for query execution. Column data is compressed on disk and cached here. |
| Degree of parallelism (DOP) | The number of parallel threads used to execute a query. Auto DOP selects this automatically based on system resources. |
| Volcano model | A query execution model where each operator exposes a Next() interface, pulling data from child operators one row (or batch) at a time. |
| Vectorized execution | A variant of the volcano model where each Next() call returns a batch of rows rather than a single row, enabling SIMD acceleration. |
How IMCI works
IMCI combines four technical innovations:
-
Columnar indexes in InnoDB. Create columnar indexes on selected columns using DDL statements. Columnar indexes use column-compressed storage — significantly smaller than row store — and reside in the In-Memory Column Store Area by default. When memory is insufficient, they spill to shared storage.
-
Column-oriented execution engine. PolarDB's executor accesses data in batches of 4,096 rows and applies SIMD instructions to process multiple values in a single CPU operation. All key operators (Scan, Hash Join, Nested Loop Join, Group By) support parallel execution. Compared to MySQL's row executor, the column executor delivers several orders of magnitude higher performance on analytical workloads.
-
Hybrid row-column optimizer. When a query is submitted, the optimizer evaluates the cost of three execution paths — row store serial execution, row store parallel query, and IMCI — and selects the lowest-cost plan. A whitelist mechanism ensures that queries using unsupported column types or operators fall back to the row store automatically, preserving 100% MySQL compatibility.
-
AP/TP workload isolation. Configure a dedicated read-only (RO) node as an analytical node with columnar indexes. Analytical queries run on the RO node using all available CPU and memory, with no impact on OLTP workloads running on read/write (RW) nodes.

Technical architecture
Hybrid row-column optimizer
The optimizer decides whether to run a query on the row store, the parallel query engine, or IMCI. This involves two mechanisms: a whitelist for compatibility and cost-based plan selection for performance.
Achieving 100% MySQL compatibility
Not every query can run on IMCI. Two constraints limit coverage:
-
Column coverage. A query that references columns not included in any columnar index cannot use IMCI for those columns.
-
Operator coverage. The IMCI execution engine is a complete rewrite, not an extension of MySQL's row executor. Some column types, operators, and expression forms are not yet implemented in the IMCI engine.
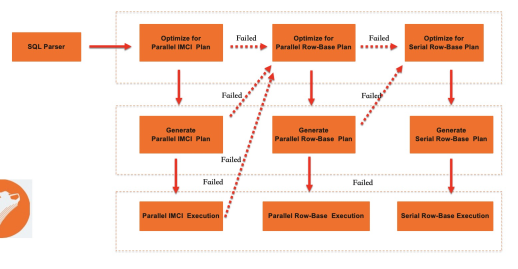
The whitelist mechanism checks data types, operators, expressions, and unsupported scenarios (such as multi-statements) against a known-good list. If a query passes the whitelist, it is eligible for IMCI execution. If not, it falls back to MySQL's native row executor. This fallback guarantees 100% compatibility: IMCI accelerates what it can, and MySQL handles everything else.
Query plan conversion
Plan conversion transforms MySQL's abstract syntax tree (AST) representation into an IMCI logical plan. The process traverses the execution plan tree and rewrites AST nodes as relational operators, handling implicit type conversions to maintain compatibility with MySQL's flexible type system.
The logical plan is then optimized into a physical plan. Beyond standard optimizations (Hash Join vs. Nested Loop Join selection), the IMCI optimizer converts subqueries that the IMCI executor cannot handle directly into equivalent join operations.
Three-way cost-based selection
PolarDB's optimizer chooses among three execution paths:
| Execution path | Description | Compatibility | Performance on AP workloads |
|---|---|---|---|
| Row store serial execution | MySQL's native single-threaded executor | Highest | Lowest |
| Row store parallel query | Multi-threaded execution on row store data | High | Moderate |
| IMCI | Vectorized, parallel execution on columnar indexes | Narrowest SQL coverage | Highest |
The optimizer follows this process:
-
Parse the SQL statement and generate a logical plan. Pass the plan to both MySQL's native optimizer and IMCI's plan compiler.
-
Calculate the row-store execution cost. If it exceeds a threshold, attempt to push the query to IMCI.
-
If IMCI cannot execute the query, attempt to generate a parallel query plan.
-
If neither IMCI nor parallel query can handle the query, fall back to row-store serial execution.
This cost model assumes IMCI outperforms parallel query, which outperforms serial execution. In practice, a parallel index join on row-store indexes can sometimes be cheaper than a sort-merge join on a column store. The optimizer may select IMCI in cases where a row-store plan would be faster.
Column-oriented execution engine
The IMCI execution engine is a complete rewrite, independent of MySQL's row executor. Its goal is to eliminate two fundamental bottlenecks: virtual function overhead per row and inability to parallelize execution.
Vectorized parallel executor
The engine uses a modified volcano model: each Next() call returns a batch of 4,096 rows instead of one row at a time. This batch-at-a-time model enables two optimizations:
Vectorization. Processing data in column-oriented batches makes SIMD instructions applicable. Instead of one operation per CPU clock, SIMD instructions process multiple values simultaneously. Combined with contiguous column storage, which maximizes CPU cache utilization, vectorized execution achieves significantly higher single-core throughput than MySQL's row executor.
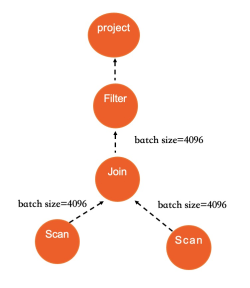
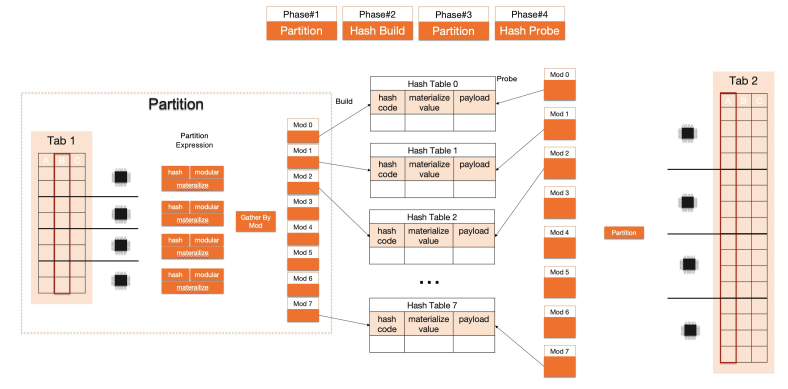
Parallel execution. Scan, Hash Join, Nested Loop Join, and Group By all support parallel execution. When the optimizer determines that a table scan exceeds the threshold for parallel execution, it calculates a recommended DOP based on available CPU, memory, and I/O resources, the queue of scheduled tasks, query complexity, and configurable parameters. All operators in a plan use the same DOP. Override the DOP for a specific query using hints.
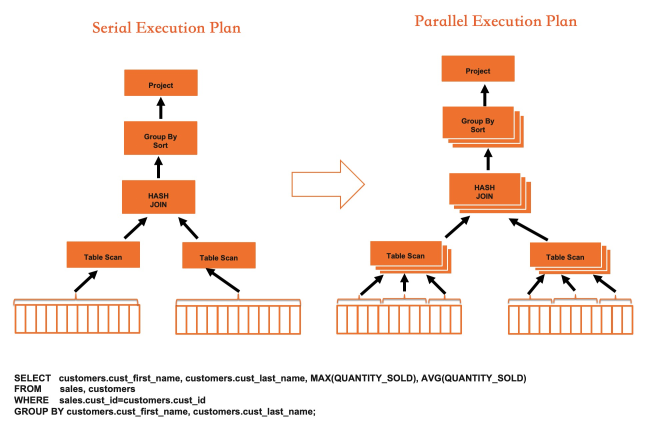
The following diagram shows Hash Join execution in IMCI, illustrating how parallelization and vectorization work together:
Vectorization raises single-core throughput; parallelism breaks the single-core ceiling. Together, they make the IMCI execution engine several orders of magnitude faster than MySQL's row executor on analytical SQL.
Vectorized expression system
Analytical SQL is expression-heavy: filters, projections, aggregations, and computed columns all involve expression evaluation. In MySQL's row executor, each row evaluation triggers a recursive traversal of the expression tree, with one virtual function call per expression node per row. This pattern is hostile to both CPU caches and branch prediction.
The IMCI expression system replaces the tree iterator model with two optimizations:
-
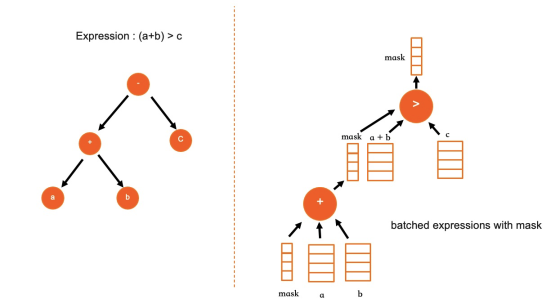
Batch processing with SIMD. Because column data is contiguous, the same expression can be applied to an entire batch of values using SIMD instructions. PolarDB rewrites the expression kernel for common data types — arithmetic operations (+, -, ×, /, and abs) on INT, DECIMAL, and DOUBLE — using AVX512 instructions. Single-core throughput improves by several times compared to scalar execution.
-
Linear expression layout. During query compilation, IMCI expressions are stored as a tree (similar to MySQL's structure). Before execution, the tree is flattened into a one-dimensional array in post-order traversal. Execution iterates over the array linearly, eliminating recursive function calls entirely. This linear layout also separates data from computation, which simplifies parallel execution.
Hybrid row-column store
OLTP and OLAP have fundamentally different storage requirements. OLTP needs precise row-level indexing and efficient single-row modifications. OLAP needs bulk column scanning and high compression. PolarDB's hybrid row-column store — using the same design as Oracle Database In-Memory and SQL Server's columnstore index — stores both formats simultaneously in one engine:
-
Real-time consistency. Row-oriented and column-oriented data stay in sync at the transaction level. Data written to the row store appears in analytical queries immediately after commit.
-
Cost efficiency. Specify only the columns that need analytical acceleration as columnar indexes. Full data continues in the row store. Index only the columns you actually analyze, not the entire table.
-
Simplified operations. No data synchronization pipeline to maintain, no consistency gaps to monitor.
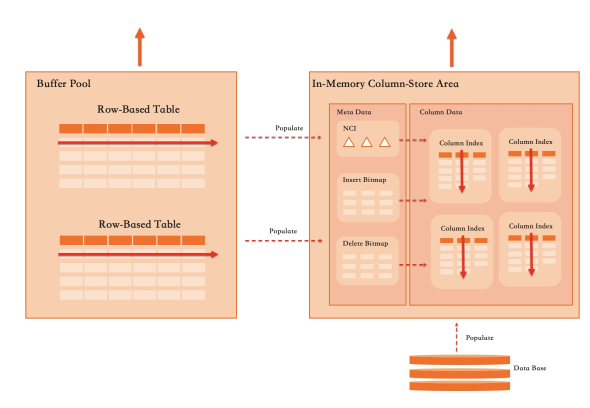
Column store maintenance must be lightweight enough that it does not degrade OLTP performance. If there is a conflict, OLTP performance takes priority. This constraint shapes every design decision below.
Column store as a secondary index
IMCI implements the column store as a secondary index of InnoDB, rather than as a separate storage engine. This design unlocks several advantages:
-
Transaction reuse. InnoDB already applies INSERT, UPDATE, and DELETE operations to all secondary indexes atomically, within the same transaction. IMCI inherits this transaction framework without modification.
-
Encoding reuse. Columnar indexes use the same data encoding as other row-store indexes. No character set or collation conversion is needed when moving data between formats.
-
Flexible column selection. Create columnar indexes on any subset of columns. Add or drop columns using DDL. Index high-cardinality analytical columns (INT, FLOAT, DOUBLE) while keeping large columns used only for point queries (TEXT, BLOB) in the row store.
-
Recovery reuse. Crash recovery reuses InnoDB's redo log module. Columnar indexes on RO nodes or standby nodes are rebuilt from redo log, integrating cleanly with PolarDB's physical replication process.
-
Lifecycle management. A columnar index shares the lifecycle of the primary index, simplifying schema management.
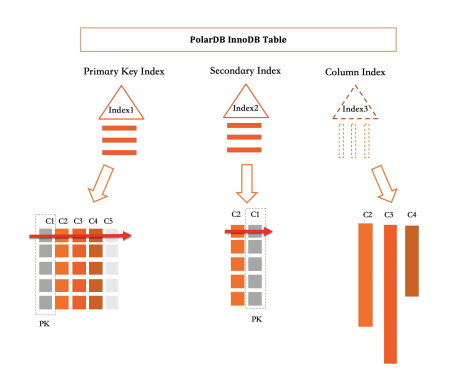
In PolarDB, the primary index and all secondary indexes are B+ trees. A columnar index is logically an index — it captures all inserts, updates, and deletes on the indexed columns — but physically, it stores columns independently rather than encoding them together into a single row.
For the table shown above: the primary index stores all five columns (C1–C5); a secondary index stores two columns (C2, C1) encoded together in a B+ tree; the columnar index stores three columns (C2, C3, C4) in split, independent column format.
When all columns required by a query are covered by a columnar index, query execution uses only that index — never touching the primary index. This is the same covering index optimization MySQL already supports, applied to column-format data. Analytical queries on covered columns run dozens to hundreds of times faster than equivalent row-store queries.
Organization of column-oriented data
Each column in a columnar index is stored in append-write mode, unordered. Space reclamation uses deletion labels and background compaction rather than in-place updates. Key design points:
-
Row groups. Records are organized in row groups of 64,000 rows each. Within a row group, each column is stored as a separate data pack.
-
Active row group. One row group is active at any time, accepting new writes. When it fills up, it freezes. All its data packs are compressed and flushed to disk, and rough index statistics are computed for each pack.
-
Row IDs. Each new row is assigned a row ID. The system uses the row ID to locate that row's data across all column data packs. A mapping index from primary keys to row IDs supports subsequent deletions and updates.
-
Deletion labels. Delete operations set a bit in a delete bitmap rather than modifying column data in place. Update operations combine a deletion label on the old row with an append write of the new row data to the active row group.
-
Background compaction. When invalid (deleted) records in a row group exceed a threshold, background compaction reclaims space and improves storage density for analytical scans.
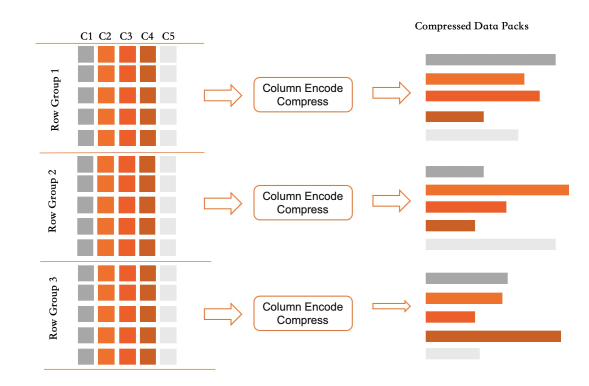
This design keeps write operations lightweight: a write appends column data to memory; a delete sets a label; an update sets a label and appends. Column store maintenance adds minimal overhead to OLTP transactions, and transaction-level isolation is preserved throughout.
Full and incremental row-to-column conversion
Columnar indexes are populated in two scenarios:
Full conversion (initial index build). When creating a columnar index on an existing table, PolarDB scans the InnoDB primary index in parallel and converts all indexed columns to column format. This is an online DDL operation — it does not block running transactions, and its speed is limited only by available I/O throughput and CPU resources.
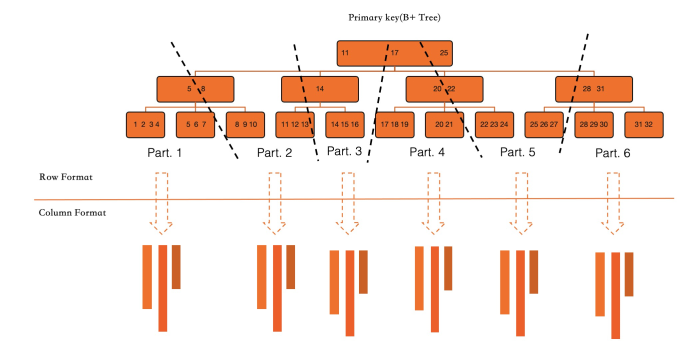
Incremental conversion (ongoing transactions). After a columnar index is created, every transaction that modifies indexed columns updates both the row store and the column store:
-
Without IMCI: the transaction locks rows, modifies data pages, and releases locks before commit.
-
With IMCI: the transaction additionally creates a column store update cache. Data page modifications are recorded in the cache. Before the transaction releases locks and commits, the cache is applied to the column store.
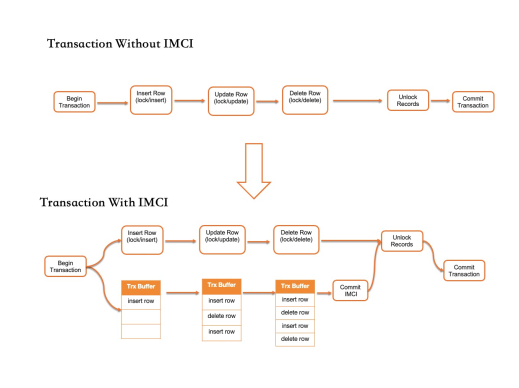
For typical OLTP transactions, the time spent modifying memory data pages is a small fraction of the total transaction time. The column store update adds minimal latency. For large transactions affecting many rows, column store updates are applied in real time but remain invisible until the transaction commits — keeping commit latency within a narrow range. For workloads that tolerate some data freshness lag, column store updates can be applied asynchronously to further reduce the impact on OLTP performance.
Transaction isolation in the column store mirrors the row store. Each row in a row group records the ID of the transaction that wrote it. Each deletion label in a delete bitmap records the transaction ID that set it. AP queries use these transaction IDs to construct a globally consistent snapshot, with minimal overhead.
Rough index scheme
All data packs are unordered and append-written, so columnar indexes cannot support precise row-level filtering the way ordered B+ tree indexes can. Instead, IMCI uses a rough index scheme based on pre-computed statistics to skip irrelevant data packs before decompression.
When an active data pack finishes writing and freezes, the system computes and stores these statistics in the data pack's metadata:
-
Minimum value
-
Maximum value
-
Sum of values
-
Null value count
-
Total record count
These statistics persist in memory. For frozen data packs with deletions, statistics are updated in the background.
At query time, the optimizer classifies each data pack as relevant, irrelevant, or possibly relevant based on query predicates and the pack's statistics. Irrelevant packs are skipped entirely. For aggregate operations such as COUNT and SUM, relevant packs can often be answered directly from pre-computed statistics, skipping decompression altogether.
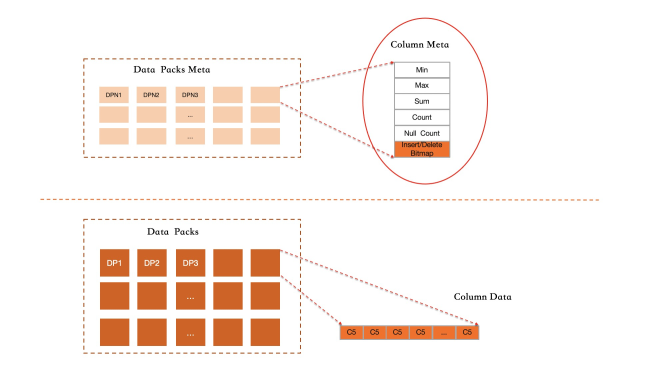
Rough indexes work best for queries that scan large volumes of data — exactly the workload IMCI targets. For queries that locate a small number of specific rows, the cost-based optimizer routes to a row-store index instead.
TP/AP resource isolation
Running OLTP and OLAP on the same cluster creates resource contention risk: a large analytical query can consume enough CPU and I/O to spike OLTP latency. PolarDB supports three deployment modes to isolate these workloads, using its write-once-read-many architecture to add independent RO nodes.
| Mode | Configuration | Isolation level | When to use |
|---|---|---|---|
| Mode 1 | IMCI enabled on the RW node | None — TP and AP share CPU and memory | Light AP load; report queries against batch-imported data |
| Mode 2 | IMCI enabled on a dedicated AP-type RO node | CPU and memory fully isolated; I/O shared | Moderate AP load; most production HTAP deployments |
| Mode 3 | IMCI enabled on a dedicated standby node with independent shared storage | CPU, memory, and I/O fully isolated | Heavy AP load; strict latency SLAs for OLTP |
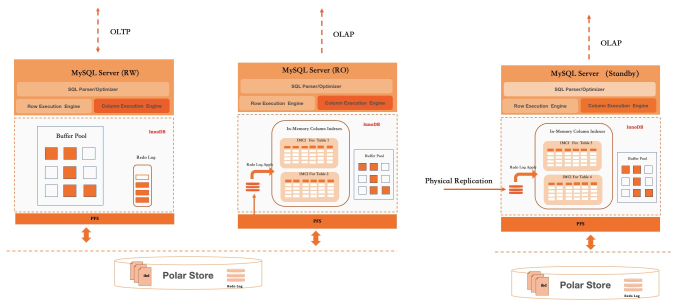
In addition to deployment-level isolation, Auto DOP limits the resources any single analytical query can consume. The DOP calculation accounts for current system load, available CPU and memory, and the queue of scheduled queries — preventing a single large query from starving other requests.
OLAP performance
For benchmark results, see IMCI performance.