The failover with hot replica feature in PolarDB can improve failover speed and implement transaction status preservation. This topic describes how the failover with hot replica feature works.
Background information
The evolution of ApsaraDB high availability can be divided into the following phases: primary/secondary high availability (HA), shared memory HA, and PolarDB cloud-native HA. Primary/secondary HA has the replication latency issue in cases such as DDL and large transactions because it uses binary log replication. PolarDB HA solves the latency issue by using physical replication and improves scalability by using the shared storage of PolarStore. However, connection interruptions and transaction rollbacks still occur in scenarios such as version upgrades. A large number of request errors are also reported on the application client. The failover with hot replica feature is introduced to address issues such as minor version upgrade, scaling, and disaster recovery. This feature is also necessary for PolarDB evolution to serverless.
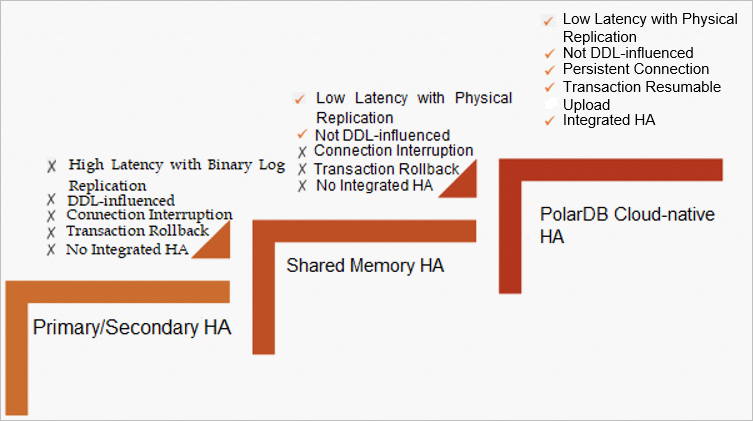 The failover with hot replica feature of PolarDB optimizes three aspects: fault detection, failover speed, and experience. It distinguishes scheduled switchover such as cluster configuration changes and minor version upgrades from failover. The failover with hot replica feature combines multiple techniques to tackle customer challenges:
The failover with hot replica feature of PolarDB optimizes three aspects: fault detection, failover speed, and experience. It distinguishes scheduled switchover such as cluster configuration changes and minor version upgrades from failover. The failover with hot replica feature combines multiple techniques to tackle customer challenges:
Voting Disk Service (VDS): VDS is a high availability module based on the shared disk architecture that can be used to implement autonomous management of cluster nodes. VDS greatly shortens the time required for fault detection and primary node selection.
Global prefetching: Powered by global prefetching, hot replica nodes can prefetch multiple modules inside the storage engine, reducing the time required for failover.
PolarProxy supports persistent connections and transaction status preservation. After persistent connections and transaction status preservation are enabled, PolarDB implements active O&M without interrupting your services during cluster configuration changes or minor version upgrade.
Prerequisites
Your cluster is a PolarDB for MySQL Enterprise Edition cluster. It meets one of the following cluster version requirements:
The PolarDB cluster runs MySQL 5.6 and the revision version is 5.6.1.0.35 or later.
The PolarDB cluster runs MySQL 5.7 and the revision version is 5.7.1.0.24 or later.
The PolarDB cluster runs MySQL 8.0.1 and the revision version is 8.0.1.1.29 or later.
The PolarDB cluster runs MySQL 8.0.2 and the revision version is 8.0.2.2.12 or later.
PolarDB for MySQL PolarProxy is 2.8.1 or later. For more information about how to view and update the PolarProxy version, see Upgrade the cluster version.
Precautions
If the failover with hot replica feature is not enabled for read-only nodes, your services may be interrupted for about 20 to 30 seconds when failover occurs. Therefore, make sure that your applications can be automatically reconnected to the cluster. If the hot replica feature is enabled for read-only nodes, failover can be completed within 3 to 10 seconds.
The specifications of hot replica nodes must be the same as those of the primary node.
The In-Memory Column Index (IMCI) feature can be used together with the Voting Disk Service (VDS) module of the failover with hot replica feature only under these conditions. For more information about the feature, see Overview.
For a cluster whose revision version is 8.0.1.1.42 or later or 8.0.2.2.23 or later:
If a cluster contains a read-only node where the failover with hot replica feature is enabled, you can add read-only IMCI nodes to the cluster.
If a read-only IMCI node already exists in a cluster, you cannot enable the hot standby feature for any read-only node in the cluster.
For a cluster whose revision version is earlier than 8.0.1.1.42 or earlier than 8.0.2.2.23, the IMCI feature cannot be used together with failover with hot replica feature.
If a cluster contains a read-only node for which the failover with hot replica feature is enabled, you cannot add read-only IMCI nodes to the cluster.
NoteIf you want to add a read-only IMCI node to the cluster, contact us to disable VDS. When VDS is being disabled, all nodes in the cluster are automatically restarted.
If a read-only IMCI node already exists in a cluster, you cannot enable the hot standby feature for any read-only node in the cluster.
If you want to enable the failover with hot replica feature for the cluster, delete the read-only column store node first.
How it works
The following core technologies are utilized to implement the failover with hot replica feature in PolarDB:
New high availability module: VDS
After the failover with hot replica feature is enabled, PolarDB activates VDS. With the shared disk architecture of PolarDB, VDS provides autonomous management, fault detection, and primary node selection of cluster nodes.
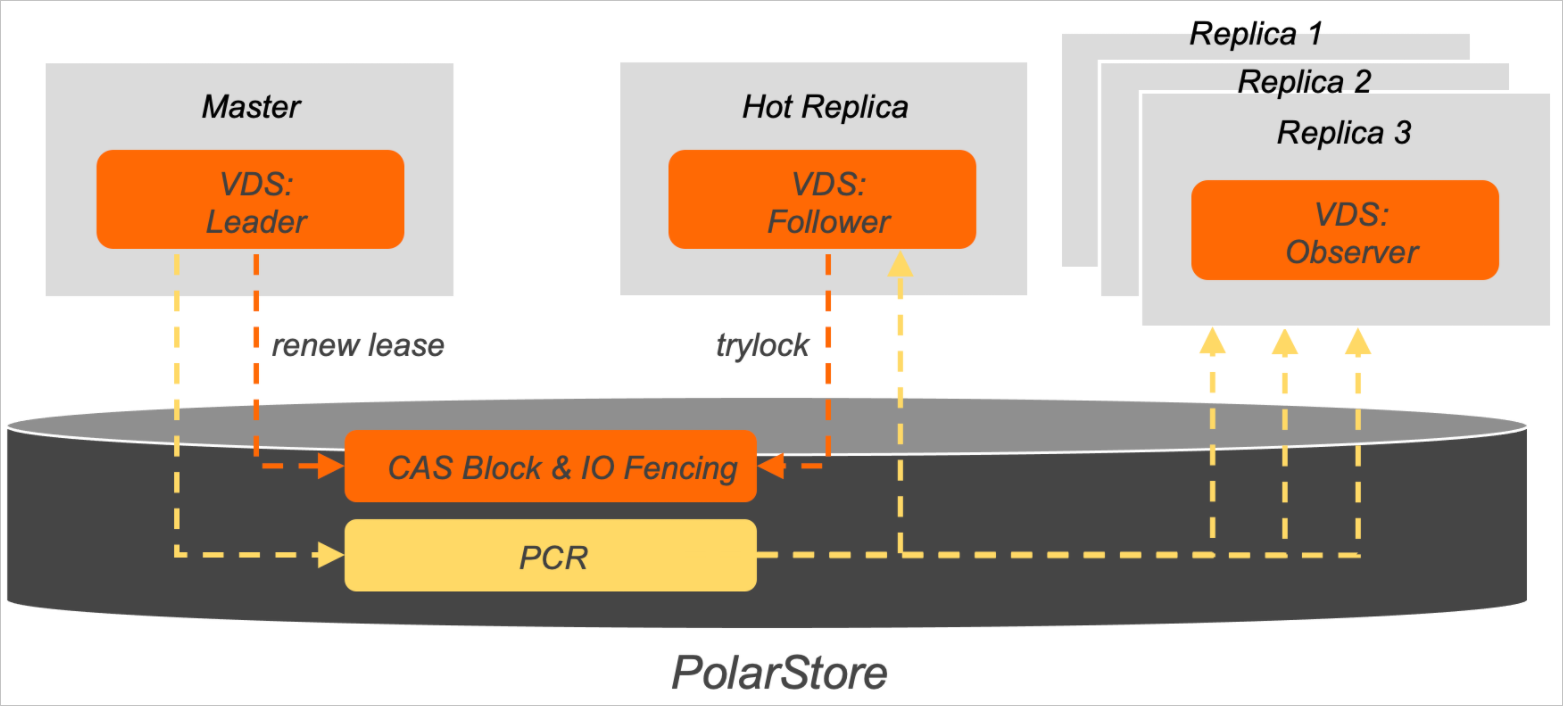 Details about the architecture of VDS:
Details about the architecture of VDS:Each compute node in VDS has an independent thread. VDS threads are classified into three categories: Leader, Follower, and Observer. In a PolarDB cluster, Leader threads run on the primary node, Follower threads run on the hot replica node, and Observer threads run on read-only nodes. A PolarDB cluster can contain one leader thread, one follower thread, and multiple observer threads.
VDS creates two data modules on PolarStore: Compare-and-Swap (CAS) Block and Polar Cluster Registry (PCR).
CAS Block is an atomic data block that supports CAS operations provided by PolarStore. CAS allows for lease-based distributed locks in VDS and records metadata such as lock holder and lease time. The primary node and hot replica node of a PolarDB cluster use lock acquirement and lock renewal semantics to detect faults and select the primary node.
PCR stores the information of PolarDB node management, such as the topology status of a cluster. Leader threads have the permission to write data to PCR, while Follower and Observer threads have only the permission to read data from PCR. When a Follower thread is designated as a Leader thread, the original Leader thread becomes a Follower thread. Only the latest Leader thread has the permission to write data to PCR. PCR also rebuilds the topology.
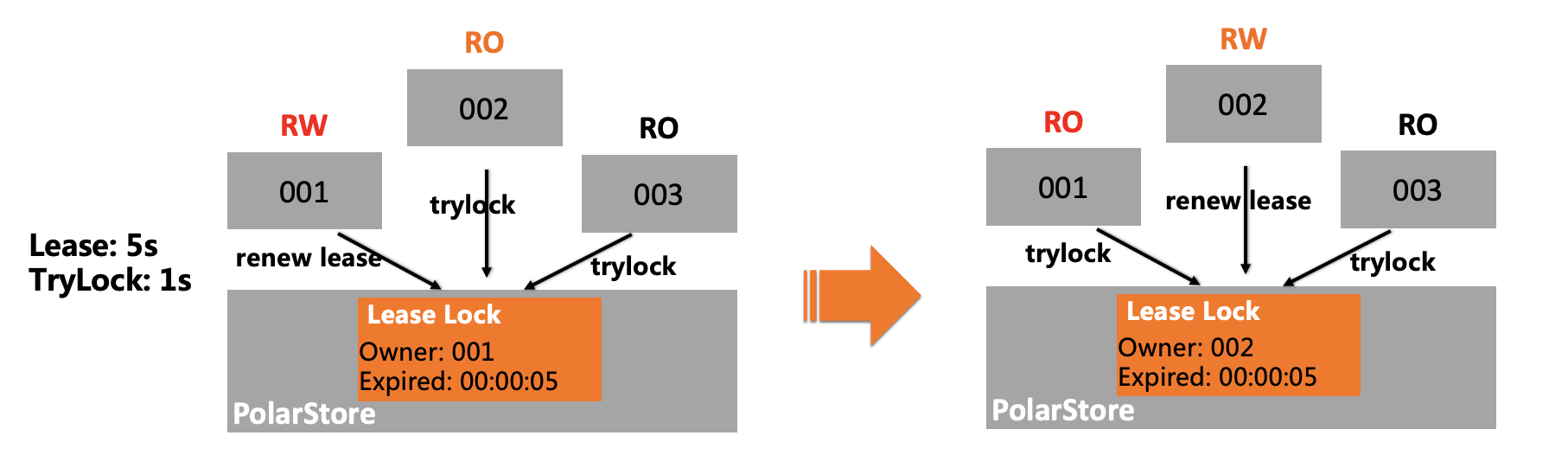
In general, the primary node provides read and write services, and the corresponding Leader thread regularly renews its lock in VDS. When the primary node becomes unavailable, a hot replica node takes over. The process is described in the following section:
After the lease of the primary node expires, a Follower thread is locked and is elected as the Leader thread. At this point, the hot replica node becomes the primary node.
When the original primary node recovers, it fails to acquire a lock. Then, the original primary node is degraded to a hot replica node.
When the primary node selection process is completed, PCR broadcasts the new topology information to all Observer threads. In this way, read-only nodes can automatically connect to the new primary node and restore the synchronization links for log sequence numbers (LSNs) and binary logs.
Global prefetching system
Compared to regular read-only nodes, the hot standby node is a special kind of read-only node that reserves a small portion of CPU and memory resources to optimize switch-over speed. The global prefetching system is the most important module in failover with hot replica. It synchronizes the metadata of the primary node in real time and prefetches key data into the memory to improve failover speed. The global prefetching system consists of four modules: Buffer Pool, Undo, Redo, and Binlog.
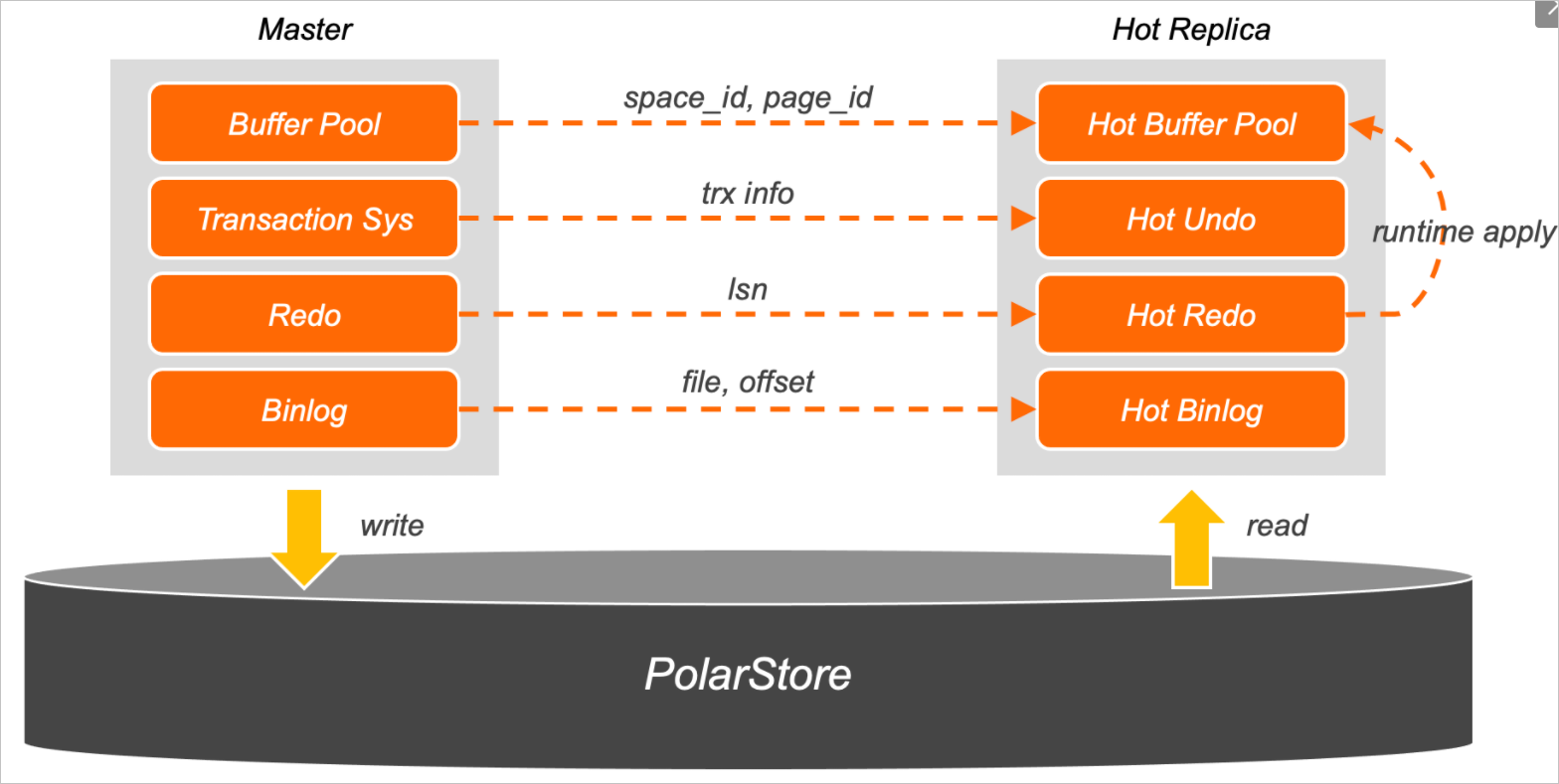
Buffer Pool
The Buffer Pool module monitors the linked list that is used to implement the Least Recently Used (LRU) algorithm in the buffer pool for the primary node in real time and sends relevant data to the hot replica node. The hot replica node selects frequently accessed pages and prefetches them to the memory to avoid performance degradation caused by a significant drop in the buffer pool hit rate when a read-only node is elected as the primary node.
Undo
The Undo module prefetches data in the transaction system. During the failover, PolarDB finds the pending transactions from undo pages and roll back the transactions Read-only nodes process only large-scale analytical query requests and do not access uncommitted transactions of the primary node. This leads to long I/O wait time for undo pages. The failover with hot replica feature prefetches undo pages and plays back to the latest version by using Runtime Apply to reduce the recovery time of the transaction system.
Redo
The Redo module caches the redo logs of hot replica and read-only nodes in the redo hash table of the memory in real time.
Binlog
After binary logs are enabled, InnoDB transactions in the Prepare state decide whether to commit or roll back a transaction based on binary logs. When a large number of transactions are executed, the system may require several seconds or minutes to read and parse all the binary logs. Hot replica nodes use background threads to asynchronously cache the latest binary logs in the I/O cache and parse them in advance to improve failover speed.
PolarDB supports dynamic conversion between hot replica nodes and common standby nodes. In actual scenarios, you can enable one hot replica node for a long time, or enable the hot replica feature only for a short time during configuration changes or upgrades. PolarDB allows you to configure the primary node and read-only nodes of different specifications. However, at least one read-only node must use the same specifications as the primary node for disaster recovery. We recommend that you configure this node as a hot replica node.
Persistent connections and transaction status preservation
However, the failover or hot upgrade may affect your service and cause issues such as transient connections, connection failures, and rollback of existing transactions. This increases the complexity and risks of application development.
PolarDB supports the Persistent connections feature. Persistent connections are implemented in the way that PolarProxy serves as a connecting bridge between your application and PolarDB. When the database performs a primary/secondary failover, PolarProxy connects database nodes to your application and restores the previous session, including the original system variables, user variables, character set encoding, and other information.
The persistent connections feature can be applied to only idle connections. If the current session has a transaction that is being executed at the moment when the node is switched, PolarProxy cannot retrieve the original transaction context from PolarDB. The new primary node will roll back the uncommitted transactions and release the row locks held by these transactions. In this case, persistent connections cannot be maintained. To solve this issue, PolarDB provides the transaction status preservation feature. Transaction status preservation, together with the persistent connections feature, allows for fast failover to deliver high availability without interrupting your services.
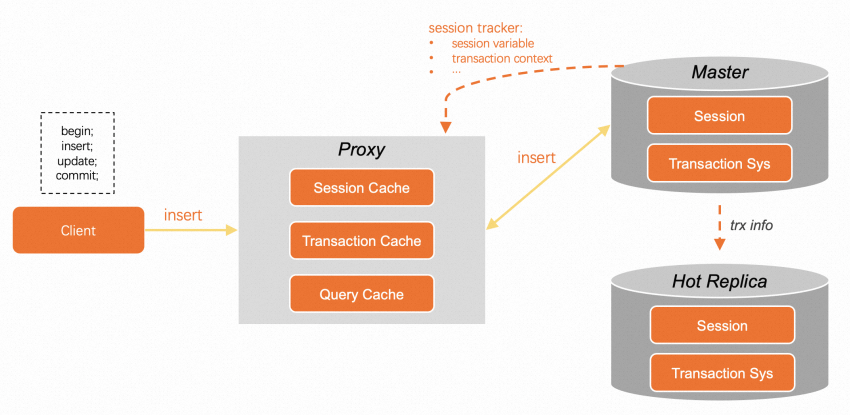
Unlike logical replication based on binary logs, the physical replication architecture allows PolarDB to rebuild the same transactions on the hot replica node as on the primary node.
For example, the process of committing a transaction in an application is BEGIN > INSERT > UPDATE > COMMIT and the transaction status preservation feature is enabled. After the transaction starts to be executed, PolarProxy caches the most recently executed SQL statement while forwarding the SQL statement to the primary node. After the INSERT statement is executed on the primary node, PolarDB automatically saves the savepoint of the latest statement as part of the transaction information. The session tracker returns the current session and transaction information to PolarProxy. Then, PolarProxy temporarily saves the data to the internal cache. Session information, such as character sets and user variables, is used for maintaining connections. The transaction information, such as trx_id and undo_no, is used for transaction status preservation. In addition, transaction information is continuously synchronized to the hot replica over a separate RDMA link. If binary logs are enabled for the backend database, the local binary log cache corresponding to each transaction is synchronized to the hot replica node.
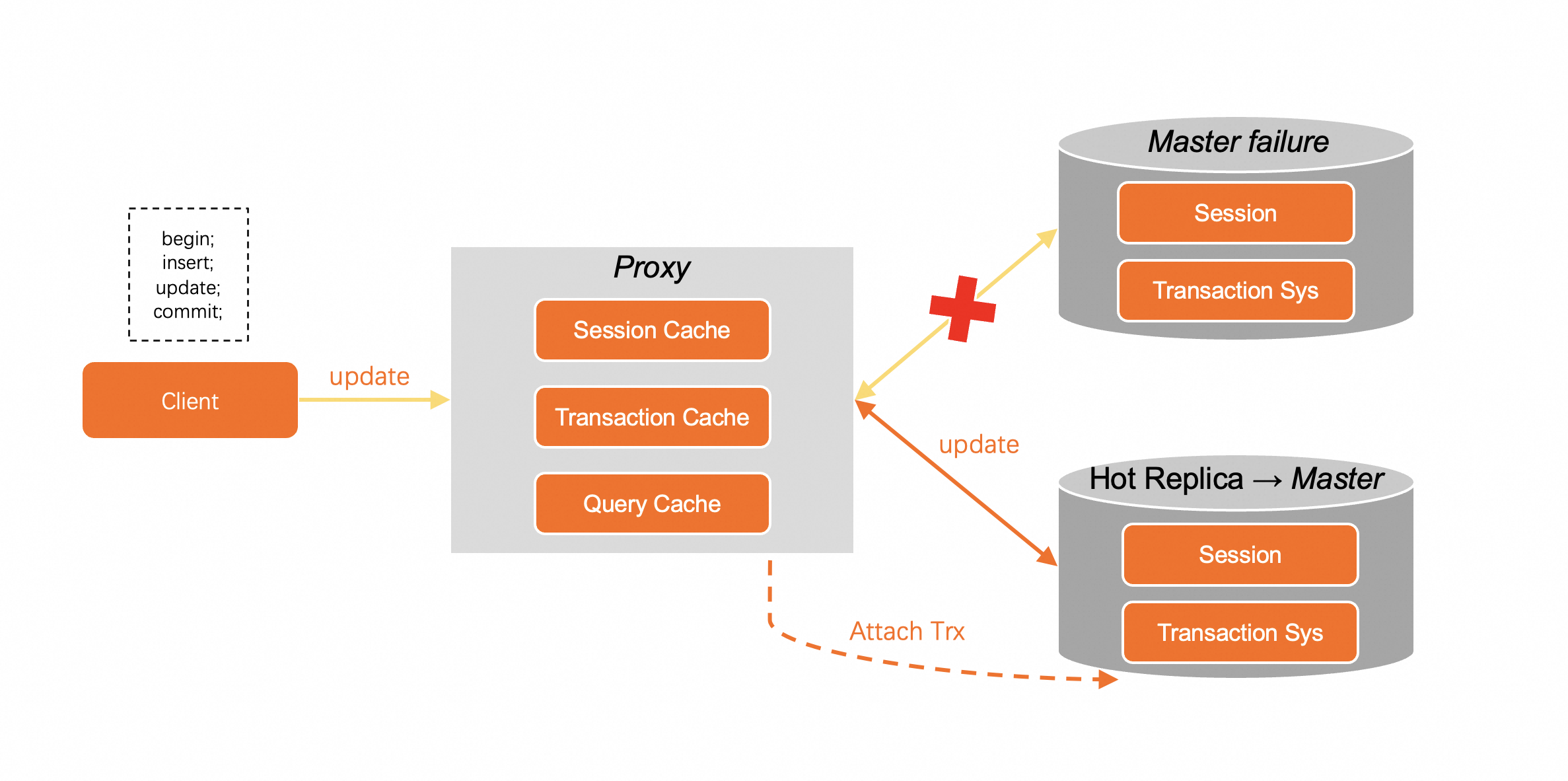
For example, the primary node is unavailable when the UPDATE statement is executed on PolarDB. PolarProxy does not immediately transmit the error from the underlying layer to the application connection, but holds the request for a period of time. After the failover, the new primary node can build all uncommitted transactions based on redo logs and asynchronously wait for uncommitted transactions without rolling back the transactions. When PolarProxy detects the successful failover message, it will use the session and transaction information cached by itself to rebuild the transaction by calling the Attach Trx API of PolarDB. PolarDB determines whether the transaction information is valid based on the PolarProxy information. If the transaction information is valid, it will be bound to the connection and rolled back to the savepoint of the undo_no corresponding to the last statement (the UPDATE statement).
After the transaction is rebuilt, PolarProxy can resend the latest UPDATE statement that failed to be executed to the new primary node from the SQL statement cache. During the failover process, no connection or transaction errors are reported on your application. The only difference is that the UPDATE statement may be slower than normal.
The failover with hot replica feature optimizes fault detection, failover speed, and experience on PolarDB by combining VDS, global prefetching system, and persistent connections and transaction status preservation. You can upgrade the cluster at any time without worrying about connection interruption or transaction interruption, and enjoy real elasticity of cloud-native databases.