Horizontal auto scaling automatically adjusts service replicas based on real-time metrics to maintain performance and optimize resource utilization.
How it works
Horizontal auto scaling dynamically adjusts the number of replicas based on configured metric thresholds.
-
Calculate target replicas: The system calculates the target replica count (desiredReplicas) using the ratio of current metric value (currentMetricValue) to desired metric value (desiredMetricValue), multiplied by current replica count (currentReplicas).
-
Formula:
desiredReplicas = ceil[currentReplicas × ( currentMetricValue / desiredMetricValue )] -
Example: With 2 current replicas and QPS Threshold of Individual Instance set to 10, when average QPS per replica rises to 23, target replicas become
5 = ceil[2 * (23/10)]. If average QPS drops to 2, target replicas become1 = ceil[5 * (2/10)]. -
With multiple configured metrics, the system calculates target replicas for each metric and uses the maximum value as the final target.
-
-
Trigger logic: When calculated target replicas exceed current replicas, the system triggers scale-out. When target replicas fall below current replicas, the system triggers scale-in.
ImportantTo prevent frequent scaling operations due to metric fluctuations, the system applies a 10% tolerance range to thresholds. For example, with a QPS threshold of 10, scale-out triggers only when QPS consistently exceeds 11 (10 × 1.1). This means:
-
QPS fluctuations between 10 and 11 do not trigger scale-out.
-
Scale-out triggers only when QPS remains stable at 11 or higher.
This mechanism reduces unnecessary resource changes and improves system stability and cost-effectiveness.
-
-
Delayed execution: Scaling operations support a delay mechanism to prevent frequent adjustments caused by brief traffic fluctuations.
User guide
Configure horizontal auto scaling policies using the PAI console or the eascmd client.
Enable or update auto scaling
Console
-
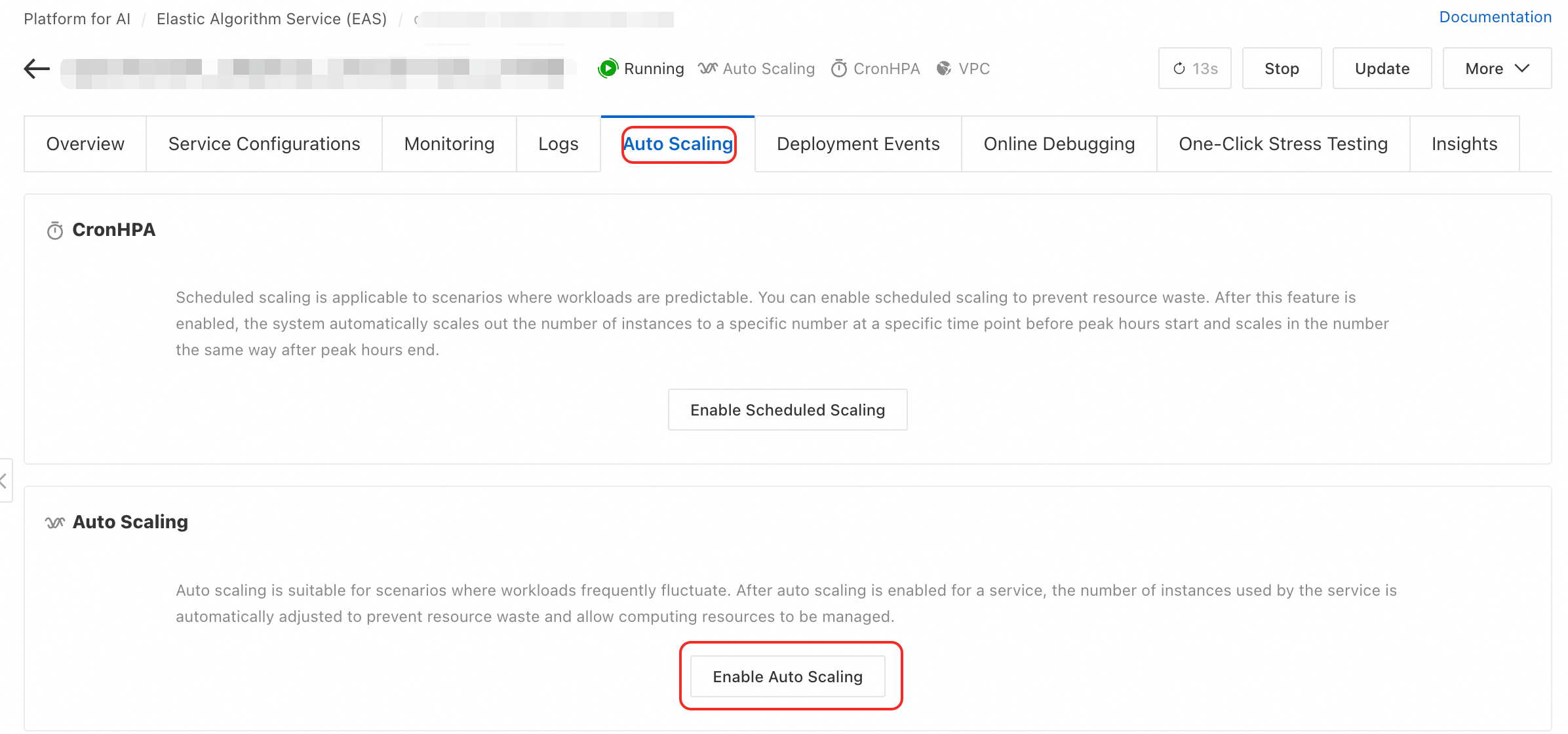
Log on to the PAI console. Select a region on the top of the page. Then, select the desired workspace and click Elastic Algorithm Service (EAS).
-
On the service list, click the target service name to access the service details page.
-
On the Auto Scaling tab, in the Auto Scaling section, click Enable Auto Scaling or Update.
-
In the Auto Scaling Settings dialog box, configure the parameters.
Parameter description
-
Basic configuration
Parameter
Description
Recommendations and risk warnings
Minimum Replicas
Minimum replicas for scale-in operations. Minimum value: 0.
Production environment: For services requiring continuous availability, set this to
1or higher.ImportantSetting this to
0removes all replicas during zero traffic. New requests face full cold start delay (tens of seconds to several minutes), making the service unavailable. Services using a dedicated gateway do not support0.Maximum Replicas
Maximum replicas for scale-out operations. Maximum value: 1000.
Set this value based on your estimated peak traffic and account resource quota to prevent unexpected traffic spikes from causing cost overruns.
General Scaling Metrics
Built-in performance metrics used to trigger scaling.
-
QPS Threshold of Individual Instance: Set based on stress test results, typically 70% to 80% of single replica optimal performance.
ImportantTo set single-replica QPS threshold to a decimal value, use the client (eascmd) and set the
qps1kfield. -
CPU Utilization Threshold: Setting too low wastes resources; setting too high increases request latency. Set based on response time (RT) metrics.
-
GPU utilization threshold: Set this value based on RT metrics.
-
Asynchronous Queue Length: Applies only to asynchronous services. Set this based on the average task processing time and acceptable latency. For more information, see Configure horizontal auto scaling for asynchronous inference services.
Custom Scaling Metric
You can report custom metrics and use them for auto scaling. For more information, see Custom monitoring and scaling metrics.
Suitable for complex scenarios where built-in metrics do not meet business requirements.
-
-
Advanced configuration
Parameter
Description
Recommendations and risk warnings
Scale-out Starts in
Observation window for scale-out decisions. After scale-out triggers, the system observes metrics during this period. If metric values fall below threshold, scale-out cancels. Unit: seconds.
Default:
0seconds (immediate scale-out). Increase this value (e.g., 60 seconds) to prevent unnecessary scaling from transient traffic spikes.Scale-in Starts in
Observation window for scale-in decisions—the key parameter to prevent service jitter. Scale-in occurs only after metrics remain below threshold for this entire duration. Unit: seconds.
Default:
300seconds. This protects against frequent scale-in events from traffic fluctuations. Do not set too low to maintain service stability.Scale-in to 0 Instance Starts in
When Minimum Replicas is
0, this parameter defines wait time before replica count reduces to0.Delays complete service shutdown, providing buffer time for potential traffic recovery.
Scale-from-Zero Replica Count
Replica count to add when service scales from
0replicas.Set to a value that handles initial traffic burst and reduces service unavailability during cold start.
Client
Before running commands, ensure the client is downloaded and authenticated. Both enabling and updating use the autoscale command. Set policy using the -D parameter or a JSON configuration file.
-
Parameter format:
# Format: eascmd autoscale [region]/[service_name] -D[attr_name]=[attr_value] # Example: Set the minimum number of replicas to 2, the maximum to 5, and the QPS threshold to 10. eascmd autoscale cn-shanghai/test_autoscaler -Dmin=2 -Dmax=5 -Dstrategies.qps=10 # Example: Set the scale-in delay to 100 seconds. eascmd autoscale cn-shanghai/test_autoscaler -Dbehavior.scaleDown.stabilizationWindowSeconds=100 -
Configuration file format:
# Step 1: Create a configuration file (for example, scaler.json). # Step 2: Run the command: eascmd autoscale [region]/[service_name] -s [desc_json] # Example eascmd autoscale cn-shanghai/test_autoscaler -s scaler.json
Configuration example
The scaler.json example includes common configuration options:
Parameter description
|
Parameter |
Description |
|
|
Minimum replicas. |
|
|
Maximum replicas. |
|
|
Scaling metrics and thresholds.
|
|
|
Corresponds to Scale-out Delay in the console. |
|
|
Corresponds to Scale-in Delay in the console. |
Disable auto scaling
Client
-
Command format
eascmd autoscale rm [region]/[service_name] -
Example
eascmd autoscale rm cn-shanghai/test_autoscaler
Best practices
Scenario-specific configuration
-
CPU-intensive online inference: Configure both CPU Utilization Threshold and QPS Threshold Per Replica. CPU utilization reflects resource consumption; QPS reflects business load. Combining these metrics enables precise scaling.
-
GPU-intensive online inference: Focus on GPU Utilization Threshold. When GPU computing units saturate, scale out to handle more concurrent tasks.
-
Asynchronous task processing: Use Asynchronous Queue Length as the core metric. When backlogged tasks exceed threshold, scale-out increases processing capacity and reduces wait times.
Stability practices
-
Avoid scaling to zero: For synchronous production services, always set Minimum Replicas to
1or higher to ensure continuous availability and low latency. -
Set reasonable delays: Use Scale-in Delay to prevent service jitter from normal traffic fluctuations. Default value of
300seconds suits most scenarios.
FAQ
Why does my service not scale out when threshold is met?
Possible reasons include:
-
Insufficient resource quota: Available vCPU or GPU quota in your account for the current region is exhausted.
-
Scale-out delay active: If Scale-out Delay is configured, the system waits for this period to confirm sustained traffic increase.
-
Replica health check failed: Newly scaled-out replicas failed health checks, causing operation failure.
-
Maximum replicas reached: Current replica count reached the configured Maximum Replicas limit.
Why does my service scale in and out frequently?
This typically results from improper scaling policy configuration:
-
Threshold too sensitive: Threshold set too close to normal load level causes minor fluctuations to trigger scaling events.
-
Scale-in delay too short: Short delay periods cause system overreaction to brief traffic drops, triggering unnecessary scale-ins. When traffic recovers, another scale-out immediately triggers. Increase the Scale-in Delay.
References
-
To automatically scale replicas at scheduled times, see Scheduled auto scaling.
-
To flexibly allocate resources for changing demands, see Elastic resource pools.
-
To monitor auto scaling effects using custom metrics, see Custom monitoring and scaling metrics.