The Elastic Algorithm Service (EAS) Scalable Job service supports model training and inference scenarios. In training scenarios, it supports running tasks in a loop within a single instance (Job) and provides automatic scaling based on queue length. In inference scenarios, it tracks the execution progress of each request to enable fairer task scheduling. This topic describes how to use the Scalable Job service.
Scenarios
Training scenarios
You can use the Scalable Job service in training scenarios:
-
Implementation: It uses a decoupled frontend and backend architecture that supports deploying resident frontend services and Scalable Job services.
-
Architecture benefits: Frontend services typically require few resources and are low-cost. Deploying resident frontend services avoids frequent service creation and reduces wait times. The backend Scalable Job service supports running training tasks in a loop within a single instance (Job), preventing instances from being repeatedly started and released, which improves throughput. The backend Scalable Job service also automatically scales out or in when the queue length becomes too long or too short, ensuring efficient resource use.
Inference scenarios
In model inference scenarios, the Scalable Job service can track the execution progress of each request to implement fairer task scheduling.
For inference services with long response times, use EAS asynchronous inference services. However, asynchronous services have the following issues:
-
The queue service cannot guarantee that requests are preferentially pushed to idle instances, leading to insufficient resource utilization.
-
During a service scale-in, the service cannot guarantee that requests within an instance are completed before the instance exits, which may cause requests to be interrupted and rescheduled.
To resolve these issues, the Scalable Job service provides the following optimizations:
-
Optimized subscription logic: Preferentially pushes requests to idle instances. Before an instance exits, it blocks and waits for the current requests to be processed.
-
Improved scaling efficiency: Unlike a periodic reporting mechanism, the queue service has a built-in monitoring service that quickly triggers scaling, reducing the scaling response time from minutes to about 10 seconds.
Basic architecture
The architecture consists of three parts: a queue service, a Horizontal Pod Autoscaler (HPA) controller, and a Scalable Job service, as shown in the following figure.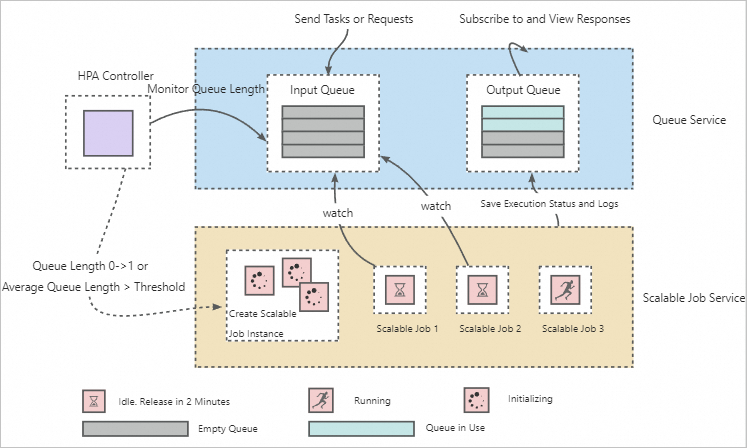
How it works:
-
The queue service decouples the sending and execution of requests or tasks, allowing a single Scalable Job service to process multiple different requests or tasks.
-
The HPA controller monitors the number of pending training tasks and requests in the queue service to implement elastic scaling for Scalable Job service instances. The default automatic scaling configurations for the Scalable Job service are as follows. For more information about the parameters, see Horizontal auto-scaling.
{ "behavior":{ "onZero":{ "scaleDownGracePeriodSeconds":60 # The grace period in seconds for scaling down to zero. }, "scaleDown":{ "stabilizationWindowSeconds":1 # The stabilization window in seconds for a scale-in. } }, "max":10, # The maximum number of instances (Jobs). "min":1, # The minimum number of instances (Jobs). "strategies":{ "avg_waiting_length":2 # The average load threshold for each instance (Job). } }
Service deployment
Deploy an inference service
The process is similar to creating an asynchronous inference service. Prepare a service configuration file based on the following example:
{
"containers": [
{
"image": "registry-vpc.cn-shanghai.aliyuncs.com/eas/eas-container-deploy-test:202010091755",
"command": "/data/eas/ENV/bin/python /data/eas/app.py",
"port": 8000,
}
],
"metadata": {
"name": "scalablejob",
"type": "ScalableJob",
"rpc.worker_threads": 4,
"instance": 1,
}
}Set type to ScalableJob to deploy the inference service as a Scalable Job service. For more information about other parameter settings, see JSON deployment. For more information about how to deploy an inference service, see Deploy an online photo generation inference service.
After the service is deployed, a queue service and a Scalable Job service are automatically created. The Autoscaler (horizontal auto-scaling) feature is also enabled by default.
Deploy a training service
Two deployment methods are supported: integrated deployment and independent deployment. The implementation logic and configuration details are described below. For specific deployment instructions, see Deploy an auto-scaling Kohya training service.
-
Implementation logic
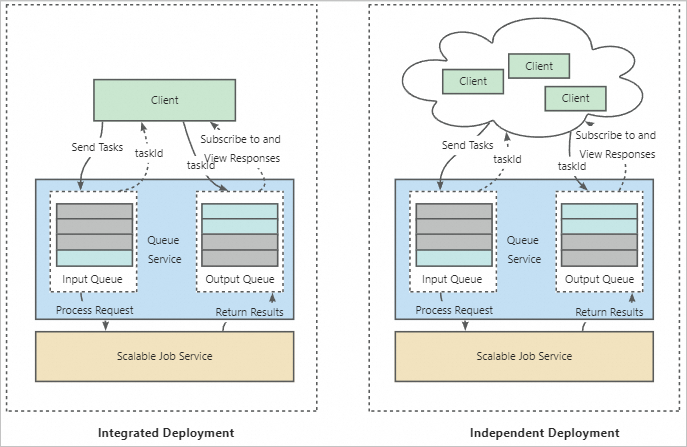
-
Integrated deployment: In addition to a queue service and a Scalable Job service, EAS creates a frontend service. The frontend service receives user requests and forwards them to the queue service. You can consider the frontend service as a client of the Scalable Job service. In this mode, the Scalable Job service is bound to a unique frontend service and can only execute training tasks sent from that frontend service.
-
Independent deployment: This method is suitable for multi-user scenarios. In this mode, the Scalable Job service acts as a shared backend service and can be bound to multiple frontend services. Each user can send training tasks from their own frontend service. The backend Job service creates corresponding Job instances to execute the training tasks. Each Job instance can execute different training tasks sequentially, allowing multiple users to share training resources. This avoids creating training tasks multiple times and effectively reduces costs.
-
-
Configuration details
When deploying a Scalable Job service, provide a custom image environment. For Kohya scenarios, you can directly use the `kohya_ss` image preset in EAS. The image must contain all dependencies required to execute the training task. Because it serves only as the execution environment for the training task, you do not need to configure a start command or port number. To perform initialization tasks before the training task starts, you can configure initialization commands. EAS creates a separate process inside the instance (Job) to execute these tasks. For information about how to prepare a custom image, see Custom images. The preset image address in EAS is: eas-registry-vpc.cn-shanghai.cr.aliyuncs.com/pai-eas/kohya_ss:2.2.
Integrated deployment
Prepare a service configuration file based on the following example, which uses the `kohya_ss` preset image provided by EAS:
{ "containers": [ { "image": "eas-registry-vpc.cn-shanghai.cr.aliyuncs.com/pai-eas/kohya_ss:2.2" } ], "metadata": { "cpu": 4, "enable_webservice": true, "gpu": 1, "instance": 1, "memory": 15000, "name": "kohya_job", "type": "ScalableJobService" }, "front_end": { "image": "eas-registry-vpc.cn-shanghai.cr.aliyuncs.com/pai-eas/kohya_ss:2.2", "port": 8001, "script": "python -u kohya_gui.py --listen 0.0.0.0 --server_port 8001 --data-dir /workspace --headless --just-ui --job-service" } }The key parameter settings are described below. For information about other parameter settings, see JSON deployment.
-
Set type to ScalableJobService.
-
By default, the frontend service uses the same resource group as the Scalable Job service. The system allocates 2 vCPUs and 8 GB of memory by default.
-
To customize the resource group or resources, refer to the following example:
{ "front_end": { "resource": "", # The dedicated resource group for the frontend service. "cpu": 4, "memory": 8000 } } -
To customize the instance type for deployment, refer to the following example:
{ "front_end": { "instance_type": "ecs.c6.large" } }
-
Independent deployment
Prepare a service configuration file based on the following example, which uses the `kohya_ss` preset image provided by EAS:
{ "containers": [ { "image": "eas-registry-vpc.cn-shanghai.cr.aliyuncs.com/pai-eas/kohya_ss:2.2" } ], "metadata": { "cpu": 4, "enable_webservice": true, "gpu": 1, "instance": 1, "memory": 15000, "name": "kohya_job", "type": "ScalableJob" } }Set type to ScalableJob. For information about other parameter settings, see JSON deployment.
In this mode, you must manually deploy a frontend service and implement request proxying within it. The proxy forwards received requests to the queue of the Scalable Job service, binding the frontend service to the backend Job service. For more information, see Send data to the queue service.
-
Service invocation
To distinguish between training and inference scenarios when calling a Scalable Job service, set the taskType field to command or query.
-
command: Identifies a training service.
-
query: Identifies an inference service.
You must explicitly specify `taskType` when calling the service. The following are examples:
-
HTTP call: For an inference service, replace `{Wanted_TaskType}` with `query`.
curl http://166233998075****.cn-shanghai.pai-eas.aliyuncs.com/api/predict/scalablejob?taskType={Wanted_TaskType} -H 'Authorization: xxx' -D 'xxx' -
When using an SDK, specify `taskType` using the `tags` parameter. In the following example, if it is an inference service, replace `wanted_task_type` with `query`.
# Create an input queue to send tasks or requests. queue_client = QueueClient('166233998075****.cn-shanghai.pai-eas.aliyuncs.com', 'scalabejob') queue_client.set_token('xxx') queue_client.init() tags = {"taskType": "wanted_task_type"} # Send a task or request to the input queue. index, request_id = inputQueue.put(cmd, tags)
Obtain results:
-
Inference service: Use the SDK for the EAS queue service to get results from the output queue. For more information, see Subscribe to the queue service.
-
Training service: Configure an OSS mount when deploying the service. This saves the training results directly to an OSS path for persistent storage. For more information, see Deploy an auto-scaling Kohya training service.
Configure log collection
The EAS Scalable Job service provides the enable_write_log_to_queue setting. Use this setting to write real-time logs to the queue.
{
"scalable_job": {
"enable_write_log_to_queue": true
}
}-
Training scenarios: This setting is enabled by default. Real-time logs are written back to the output queue. You can use the EAS queue service SDK to get training logs in real time. For more information, see Use a custom frontend service image to call a Scalable Job service.
-
Inference scenarios: This setting is disabled by default. Logs can only be output using stdout.
References
For more detailed scenarios of the EAS Scalable Job service, see the following topics: