PAI-EAS Spot delivers cost-effective online inference using preemptible instances for latency-tolerant, cost-sensitive scenarios.
Scenarios
-
Non-critical business: Applications where occasional service interruptions have minimal impact.
-
Fault-tolerant processing: Services that handle temporary disruptions through retry mechanisms or fault tolerance methods.
-
High demand for cost optimization: Businesses and projects that aim to lower operational costs by using more affordable and flexible computing resources.
Create a spot service
-
Log on to the PAI console. Select a region at the top of the page, select the workspace, and click Elastic Algorithm Service (EAS).
-
On the Elastic Algorithm Service (EAS) page, click Deploy Service. In the Custom Model Deployment section, click Custom Deployment.
-
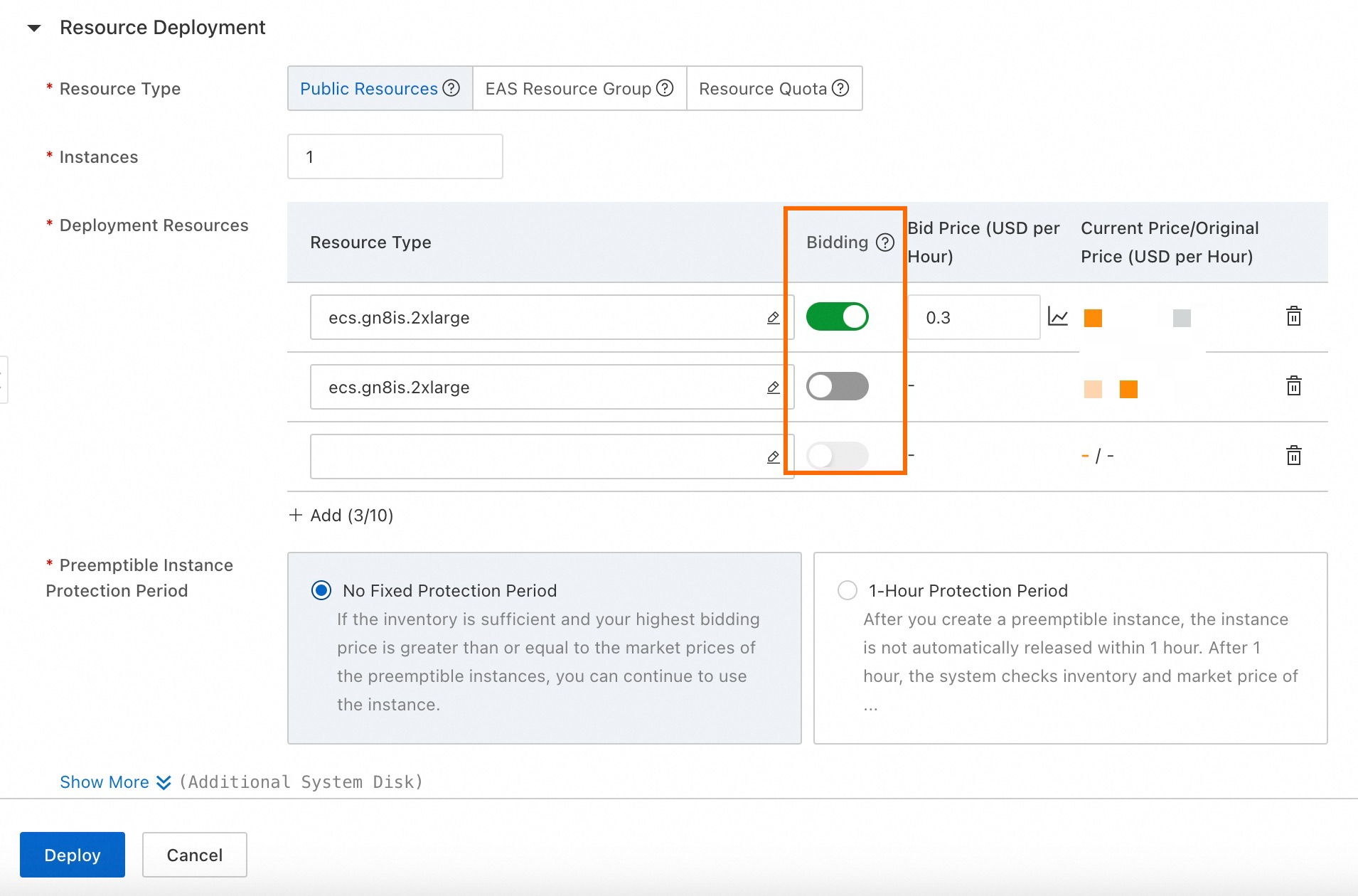
In the Resource Information section, select Public Resource as the resource type and select a resource specification (L or H specifications recommended).
Enable the Bidding switch and set your bid. View the historical price curve to inform your bid, which displays market price trends over the past 48 hours.
 Important
Important-
The bid price is not the actual price, which is the market price. The bid price represents the maximum price you are willing to pay. If market price falls below your bid, resources remain allocated and are not released. You are charged the market price, not the bid price.
-
Set bid price at 20% of original price. For example, if pay-as-you-go price for an instance is $ 2.58 per hour, market price is unlikely to exceed 20% of original price, which is $ 0.516 per hour. This strategy provides significant cost savings while ensuring stable resource availability. For more information, see Specify preemptible instances.
-
Configure regular instances alongside preemptible instances to prevent service deployment failures during instance preemption.
-
-
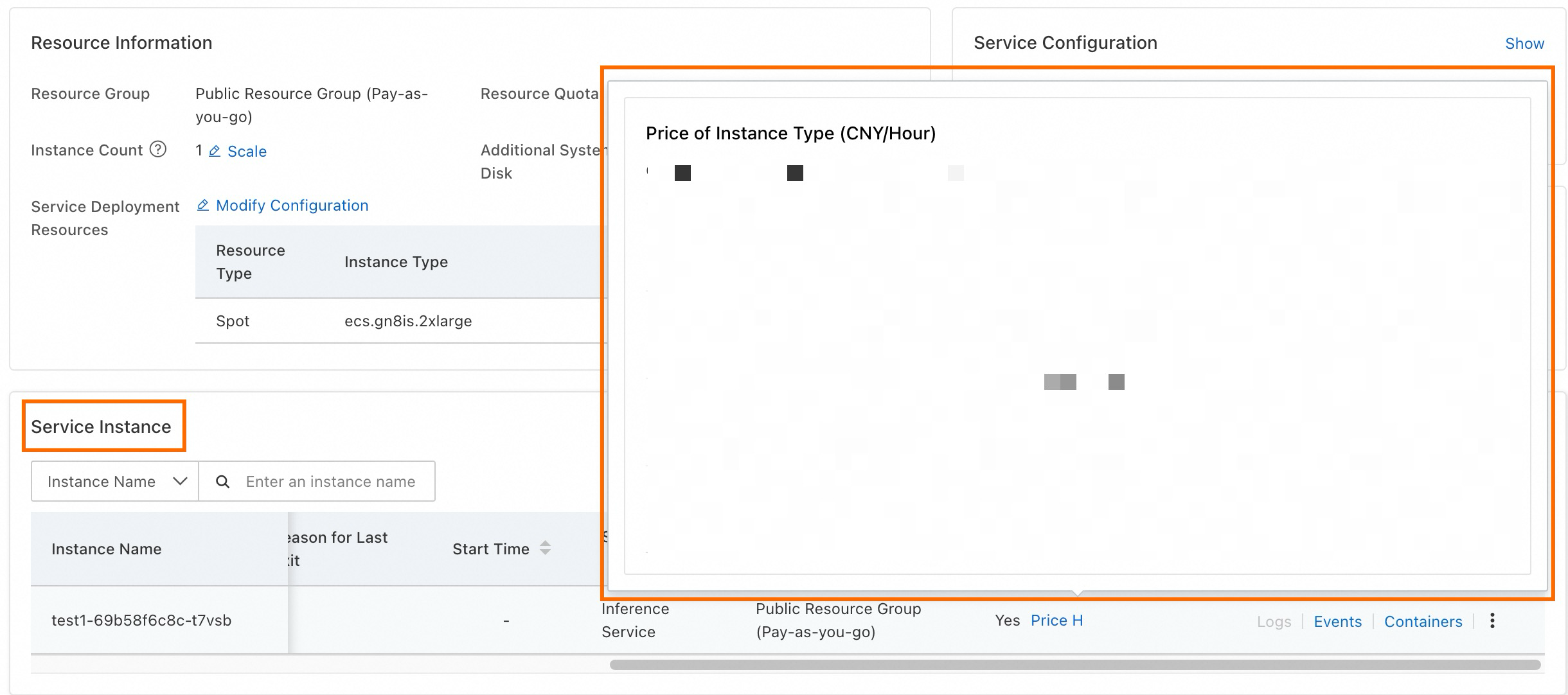
After deployment, monitor price fluctuations over the past 48 hours on the service details page to understand and manage cost variations.
Recycling and fault tolerance mechanisms
EAS recycling mechanism
EAS typically receives notification approximately 5 minutes before spot instance recycling. Upon notification, EAS initiates graceful shutdown to divert traffic from scheduled-for-recycling instances, preventing service interruptions. Simultaneously, EAS automatically launches new instances following your resource configuration order to minimize recycling impact and maintain uninterrupted service.
Configure regular instances alongside preemptible instances to ensure continuous and stable service.
Switch back to spot instances after recycling
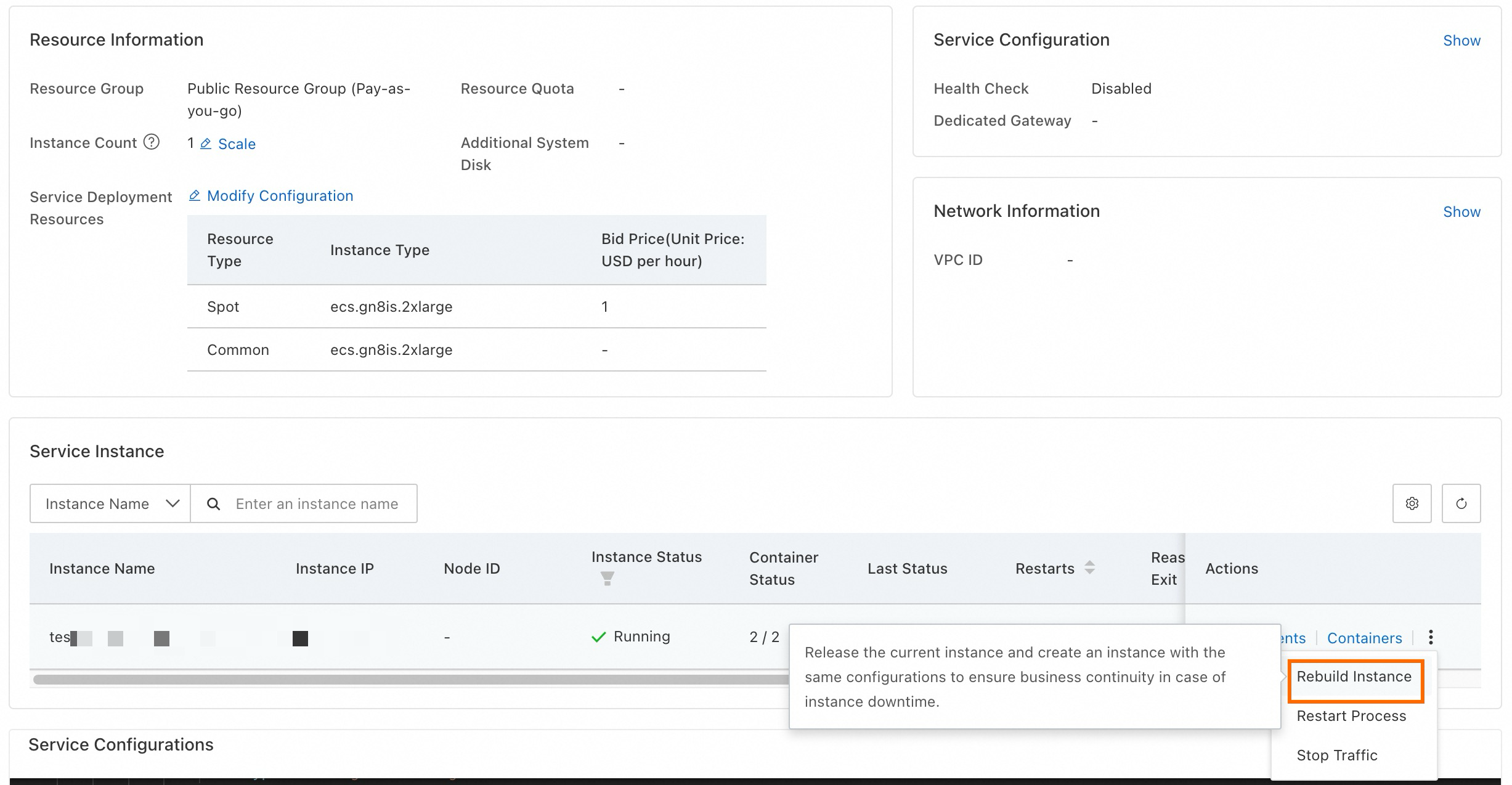
If regular resources replace a recycled spot instance and you want to switch back once inventory restores, use the Rebuild Instance feature.
Click Rebuild Instance to release resources and recreate an instance of the same configuration:
Recommended configuration strategy
To enhance service stability and accelerate new instance startup, apply the following configuration strategies.
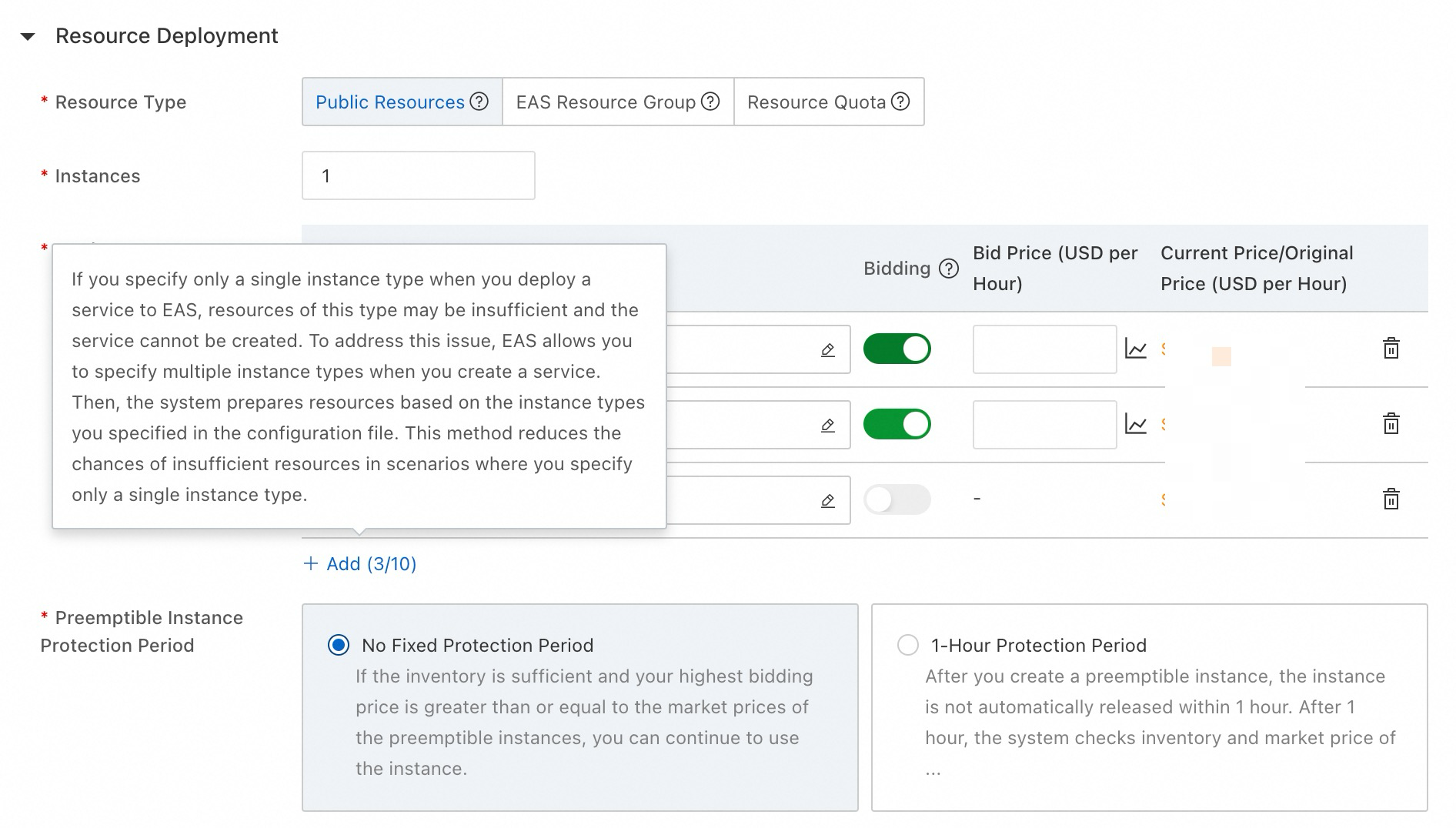
Configure multiple instance specifications
For service stability and reliability, diversify resource configurations by selecting multiple specifications. Include at least one regular resource as backup in your configuration. EAS sequentially uses specifications based on specified order, maximizing service operation stability. For more information, see Specify multiple instance types.
Configure local directory memory cache
To accelerate model file retrieval when starting new instances after recycling, configure local directory memory cache. This uses idle memory to cache model files, reducing read time during scale-out and mitigating service downtime from spot recycling.
Enable Memory Caching when creating the EAS service to enhance instance scale-out efficiency. For more information, see Local memory cache folder.

The following table describes Memory Caching (cachefs) benefits using the Stable Diffusion model as an example. Enabling cachefs allows reading models from other instance memory within the service during scale-out (cachefs remote hit), significantly reducing model loading time compared to reading directly from mounted OSS directory.
|
Model |
Model size |
Model loading time (s) |
|
|
OSS mount |
cachefs remote hit |
||
|
anything-v4.5.safetensors |
7.2G |
89.88 |
15.18 |
|
Anything-v5.0-PRT-RE.safetensors |
2.0G |
16.73 |
5.46 |
|
cetusMix_Coda2.safetensors |
3.6G |
24.76 |
7.13 |
|
chilloutmix_NiPrunedFp32Fix.safetensors |
4.0G |
48.79 |
8.47 |
|
CounterfeitV30_v30.safetensors |
4.0G |
64.99 |
7.94 |
|
deliberate_v2.safetensors |
2.0G |
16.33 |
5.55 |
|
DreamShaper_6_NoVae.safetensors |
5.6G |
71.78 |
10.17 |
|
pastelmix-fp32.ckpt |
4.0G |
43.88 |
9.23 |
|
revAnimated_v122.safetensors |
4.0G |
69.38 |
3.20 |
Use ACR Enterprise Edition
To improve image pulling efficiency when starting new instances after recycling, use Container Registry (ACR) Enterprise Edition with image acceleration enabled. Deploy EAS services using accelerated images with the _accelerated suffix. Select the same VPC associated with your ACR instance when deploying EAS services.
Purchase an ACR Enterprise Edition and select Standard Edition for Instance Type. Enable image acceleration when creating an image repository to improve new instance scale-out efficiency. For more information, see Image acceleration.
Below is an example of image configuration during EAS custom deployment:
Purchase ACR instance:
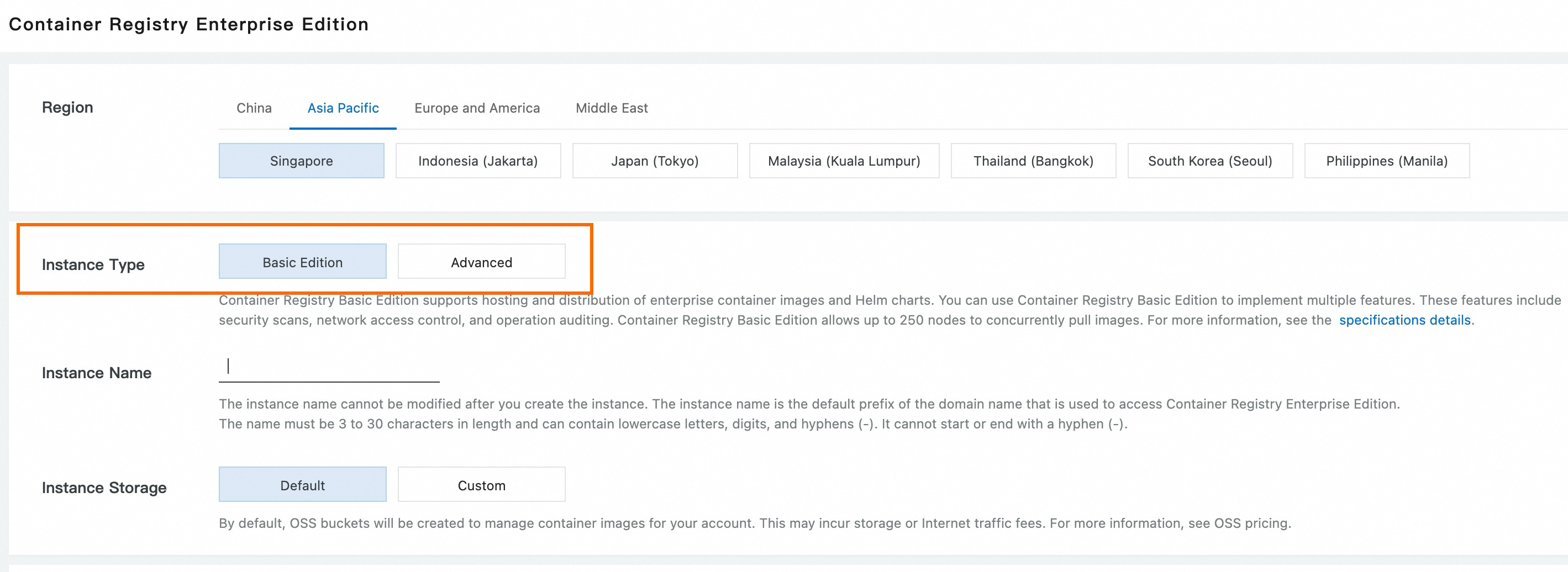
Enable Accelerated Image when creating an image repository:

Combine with scaling
For businesses with significant load fluctuations, enable horizontal auto scale-out and scale-in. Combine dedicated resource group, spot resource scaling, and regular resource to ensure smooth service operation and cost-efficiency. Configuration strategy:
-
Secure a base level of service traffic by purchasing EAS subscription/pay-as-you-go dedicated resource group. Configure the dedicated resource group in the console to meet GPU, CPU, and memory requirements for service startup.
-
Enable Elastic Resource Pool and configure multiple resource specifications. Prioritize spot resources, and use fallback resources last. This approach enables expansion to spot resources with sufficient inventory during peak times. If spot resources are insufficient, regular resources ensure smooth scale-out during business peaks.
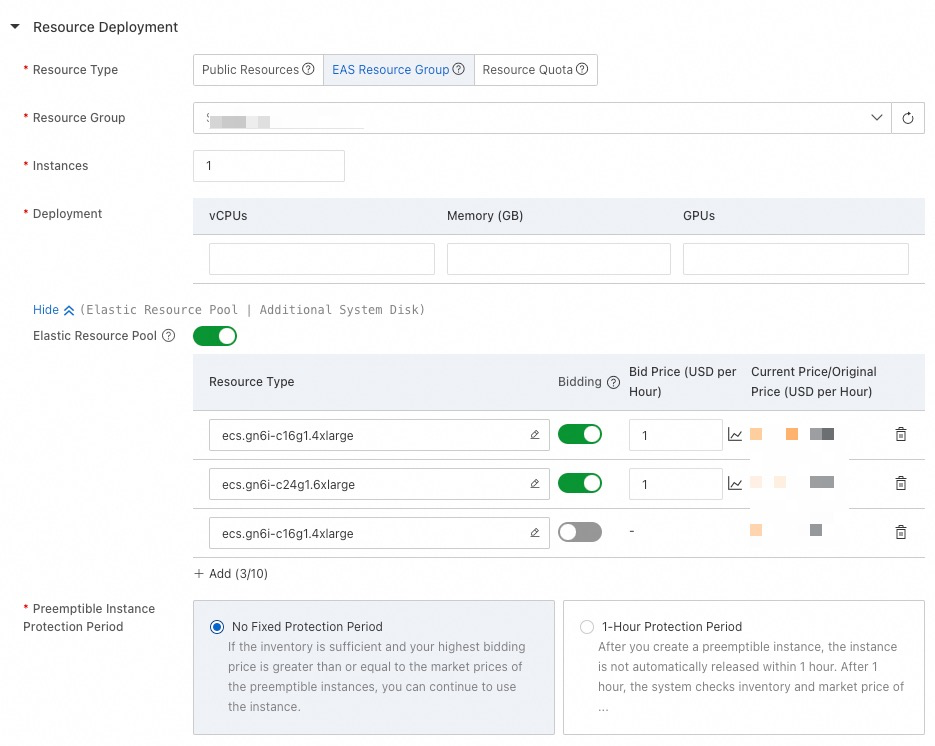
-
After deployment, enable Auto Scaling based on your business metrics on the service details page. Use General Scaling Metrics such as QPS, CPU utilization, and GPU utilization for auto scaling, or customize metrics to suit your needs.
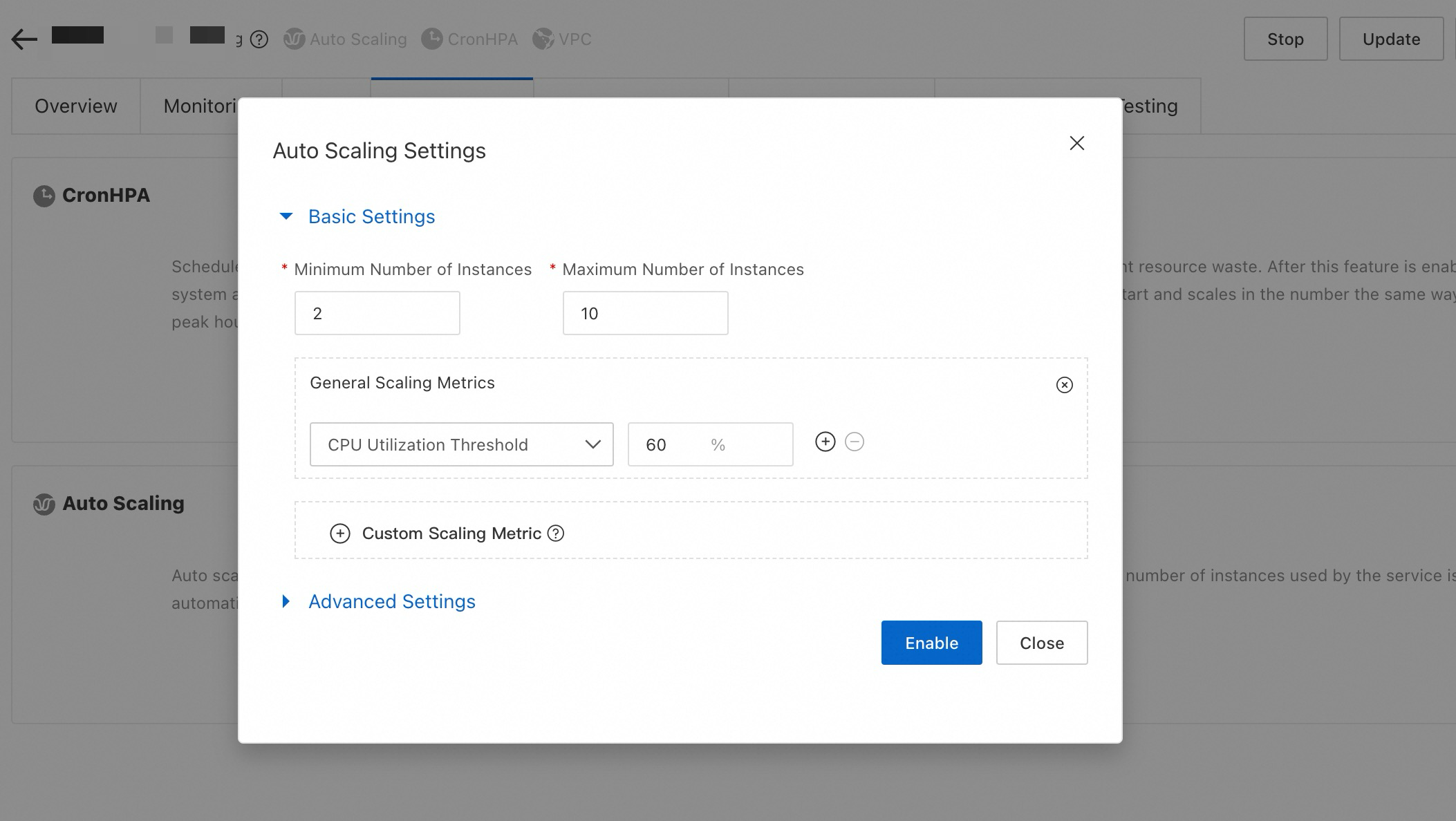
Enable Scheduled Scaling to align with predictable traffic fluctuations over time.
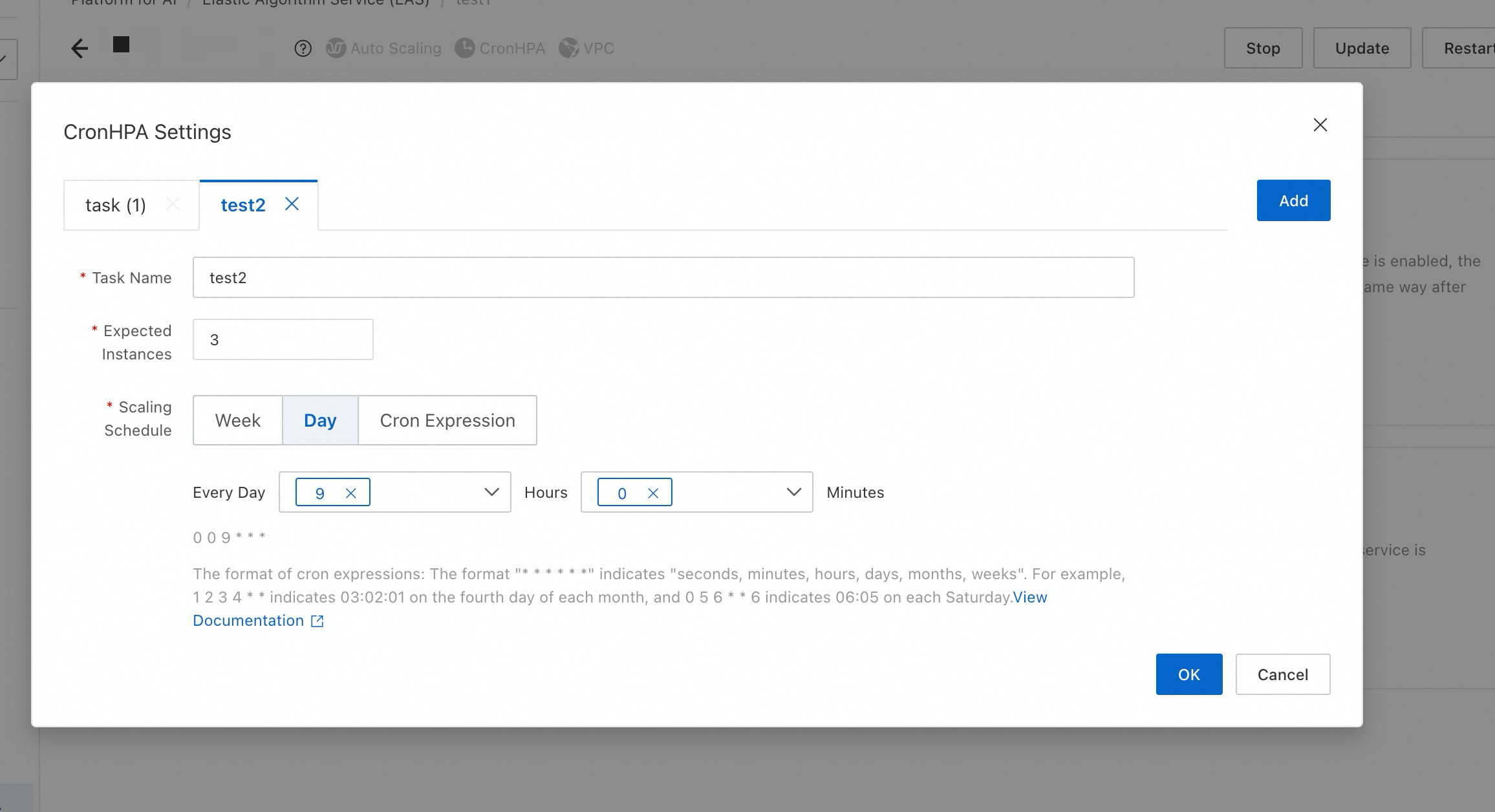
When creating services, dedicated resource group resources are used first, followed by sequential allocation of available resources from elastic resource pool based on configured sorting.
-
For example, if dedicated resource group is fully used and scaling to public resource pool is necessary, the system assesses how many instances can be created with current inventory of ecs.gn61-c16g1.4xlarge. If resources are still insufficient, it considers ecs.gn61-c24g1.6xlarge, and finally, regular ecs.gn6i-c16g1.4xlarge for remaining instances.
-
If 8 instances are required beyond dedicated resource group, allocation might be 2 instances from dedicated resource group, 3 from ecs.gn61-c16g1.4xlarge, 2 from ecs.gn61-c24g1.6xlarge, and 1 from regular ecs.gn61-c16g1.4xlarge.
For more information on EAS scaling, see: