CosyVoice 2 provides API operations that you can use to manage audio files and synthesize speech. This topic describes these API operations and explains how to call them.
Preparations
Deploy the CosyVoice 2 WebUI service or the high-performance service with separate frontend and backend components. You must also mount Object Storage Service (OSS) or another storage service to store uploaded audio files. For more information, see Quickly deploy a WebUI service or Quickly deploy a high-performance service with separate frontend and backend components.
Obtain the service endpoint and token.
ImportantFor the high-performance service with separate frontend and backend components, send API calls to the Frontend service.
For stress testing, use the VPC endpoint. This provides significantly higher processing speeds than the public endpoint.
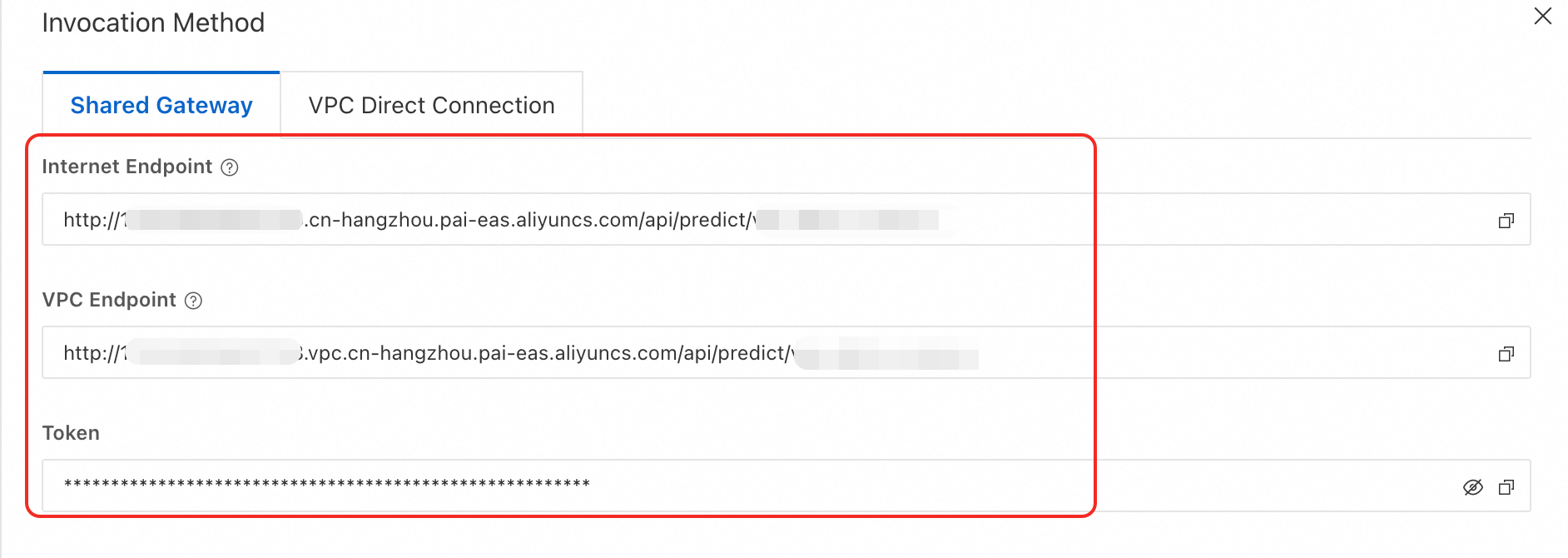
Click the name of the CosyVoice 2 WebUI service or Frontend service. On the Overview page, in the Basic Information section, click View Invocation Information.
In the Calling Information panel, on the Shared Gateway tab, obtain the service endpoint (EAS_SERVICE_URL) and token (EAS_TOKEN), and then remove the trailing
/from the endpoint.NoteTo use the public endpoint, the client must be able to access the public network.
To use the VPC endpoint, the client must be in the same virtual private cloud (VPC) as the service.
Prepare an audio file.
The following sample audio file is used in this topic:
Sample WAV audio file: zero_shot_prompt.wav
Sample audio text:
I hope you can do even better than me in the future.
API operations
Upload a reference audio file
Calling method
Endpoint
<EAS_SERVICE_URL>/api/v1/audio/reference_audioRequest method
POST
Request headers
Authorization: Bearer <EAS_TOKEN>Request parameters
file: Required. The audio file to upload. MP3, WAV, and PCM formats are supported. Type: file. Default value: None.
text: Required. The text content corresponding to the audio file. Type: string.
Response parameters
Returns a reference audio object. For more information, see Response parameter list.
Request examples
cURL
# Replace <EAS_SERVICE_URL> and <EAS_TOKEN> with the service endpoint and token. curl -XPOST <EAS_SERVICE_URL>/api/v1/audio/reference_audio \ --header 'Authorization: Bearer <EAS_TOKEN>' \ --form 'file=@"/home/xxxx/zero_shot_prompt.wav"' \ --form 'text="I hope you can do even better than me in the future."'Python
import requests response = requests.post( "<EAS_SERVICE_URL>/api/v1/audio/reference_audio", # Replace <EAS_SERVICE_URL> with the service endpoint. headers={ "Authorization": "Bearer <EAS_TOKEN>", # Replace <EAS_TOKEN> with the service token. }, files={ "file": open("./zero_shot_prompt.wav", "rb"), }, data={ "text": "I hope you can do even better than me in the future." } ) print(response.text)Response example
{ "id": "50a5fdb9-c3ad-445a-adbb-3be32750****", "filename": "zero_shot_prompt.wav", "bytes": 111496, "created_at": 1748416005, "text": "I hope you can do even better than me in the future." }
View the list of reference audio files
Calling method
Endpoint
<EAS_SERVICE_URL>/api/v1/audio/reference_audio
Request method
GET
Request headers
Authorization: Bearer <EAS_TOKEN>Request parameters
limit: Optional. The maximum number of files to return. Type: integer. Default value: 100.
order: Optional. The sorting order of objects based on the created_at timestamp. Type: string. Valid values:
asc: ascending
desc (default): descending
Response parameters
Returns an array of reference audio objects. For more information, see Response parameter list.
Request examples
cURL
# Replace <EAS_SERVICE_URL> and <EAS_TOKEN> with the service endpoint and token. curl -XGET <EAS_SERVICE_URL>/api/v1/audio/reference_audio?limit=10&order=desc \ --header 'Authorization: Bearer <EAS_TOKEN>'Python
import requests response = requests.get( "<EAS_SERVICE_URL>/api/v1/audio/reference_audio", # Replace <EAS_SERVICE_URL> with the service endpoint. headers={ "Authorization": "Bearer <EAS_TOKEN>", # Replace <EAS_TOKEN> with the service token. } ) print(response.text)Response example
[ { "id": "50a5fdb9-c3ad-445a-adbb-3be32750****", "filename": "zero_shot_prompt.wav", "bytes": 111496, "created_at": 1748416005, "text": "I hope you can do even better than me in the future." } ]
View a specific reference audio file
Calling method
Endpoint
<EAS_SERVICE_URL>/api/v1/audio/reference_audio/<reference_audio_id>Request method
GET
Request headers
Authorization: Bearer <EAS_TOKEN>Path parameters
reference_audio_id: Required. The ID of the reference audio file. To obtain the ID, see View the list of reference audio files. Type: String. Default value: None.
Response parameters
Returns a reference audio object. For more information, see Response parameter list.
Request examples
cURL
# Replace <EAS_SERVICE_URL> and <EAS_TOKEN> with the service endpoint and token. # Replace <reference_audio_id> with the reference audio ID. curl -XGET <EAS_SERVICE_URL>/api/v1/audio/reference_audio/<reference_audio_id> \ --header 'Authorization: Bearer <EAS_TOKEN>'Python
import requests response = requests.get( "<EAS_SERVICE_URL>/api/v1/audio/reference_audio/<reference_audio_id>", # Replace <EAS_SERVICE_URL> with the service endpoint. headers={ "Authorization": "Bearer <EAS_TOKEN>", # Replace <EAS_TOKEN> with the service token. } ) print(response.text)Response example
{ "id": "50a5fdb9-c3ad-445a-adbb-3be32750****", "filename": "zero_shot_prompt.wav", "bytes": 111496, "created_at": 1748416005, "text": "I hope you can do even better than me in the future." }
Delete a reference audio file
Calling method
Endpoint
<EAS_SERVICE_URL>/api/v1/audio/reference_audio/<reference_audio_id>Request method
DELETE
Request headers
Authorization: Bearer <EAS_TOKEN>Path parameters
reference_audio_id: Required. The ID of the reference audio file. To obtain the ID, see View the list of reference audio files. Type: String. Default value: None.
Response parameters
Returns a reference to an audio object.
Request examples
cURL
# Replace <EAS_SERVICE_URL> and <EAS_TOKEN> with the service endpoint and token. # Replace <reference_audio_id> with the reference audio ID. curl -XDELETE <EAS_SERVICE_URL>/api/v1/audio/reference_audio/<reference_audio_id> \ --header 'Authorization: Bearer <EAS_TOKEN>'Python
import requests response = requests.delete( "<EAS_SERVICE_URL>/api/v1/audio/reference_audio/<reference_audio_id>", # Replace <EAS_SERVICE_URL> with the service endpoint. headers={ "Authorization": "Bearer <EAS_TOKEN>", # Replace <EAS_TOKEN> with the service token. } ) print(response.text)Response example
{ "code": "OK", "message": "reference audio: c0939ce0-308e-4073-918f-91ac88e3**** deleted.", "data": {} }
Create speech synthesis
Calling method
Endpoint
<EAS_SERVICE_URL>/api/v1/audio/speechRequest method
POST
Request headers
Authorization: Bearer <EAS_TOKEN>Content-Type: application/json
Request parameters
model: Required. The model name. Only CosyVoice2-0.5B is supported. Type: string. Default value: None.
input: Required. The input content. Type: object. Default value: None. The object contains the following parameters:
mode: Required. The speech synthesis mode. Type: string. Valid values:
fast_replication: fast replication
cross_lingual_replication: cross-lingual replication
natural_language_replication: natural language replication
text: Required. The text to synthesize. Type: string. Default value: None.
reference_audio_id: Required. The ID of the reference audio file. To obtain the ID, see View the list of reference audio files. Type: string. Default value: None.
instruct: Optional. The instruction text to dynamically adjust the voice style, such as tone, emotion, and speed. This parameter is effective only when mode is set to natural_language_replication. Type: string. Default value: None.
sample_rate: Optional. The audio sampling rate. Default value: 24000.
bit_rate: Optional. The bit rate. Type: string. Default value: 192k. Supported values: 16k, 32k, 48k, 64k, 128k, 192k, 256k, 320k, and 384k.
volume: Optional. The volume. Type: float. Default value: 1.0. For example, 3.0 means triple the volume, and 0.8 means 0.8 times the volume.
speed: Optional. The speed of the output speech. The value ranges from 0.5 to 2.0. Type: float. Default value: 1.0.
output_format: Optional. The format of the output audio. Supported formats: wav, mp3, and pcm. Default value: wav.
stream: Optional. Specifies whether to enable streaming output. Type: boolean. Default value: true.
Response parameters
Returns a speech chunk object in a stream. For more information, see Response parameter list.
Request examples
Non-streaming call
cURL
Replace <EAS_SERVICE_URL> and <EAS_TOKEN> with the service endpoint and token.
Replace <reference_audio_id> with the reference audio ID.
# Replace <EAS_SERVICE_URL> and <EAS_TOKEN> with the service endpoint and token. # Replace <reference_audio_id> with the reference audio ID. curl -XPOST <EAS_SERVICE_URL>/api/v1/audio/speech \ --header 'Authorization: Bearer <EAS_TOKEN>' \ --header 'Content-Type: application/json' \ --data '{ "model": "CosyVoice2-0.5B", "input": { "mode": "natural_language_replication", "reference_audio_id": "<reference_audio_id>", "text": "Receiving a birthday gift from a friend far away, the unexpected surprise and deep blessings filled my heart with sweet joy, and my smile bloomed like a flower.", "speed": 1.0, "output_format": "mp3", "sample_rate": 32000, "bit_rate": "48k", "volume": 2.0, "instruct": "Speak in Sichuan dialect" }, "stream": false }'The Base64-encoded result is returned:
{"output":{"finish_reason":null,"audio":{"data":"DNgB9djax9su3Ba...."}},"request_id": "f90a65be-f47b-46b5-9ddc-70bae550****"}Python
Install the following dependencies:
pip install requests==2.32.3 packaging==24.2import json import base64 import requests from packaging import version required_version = "2.32.3" if version.parse(requests.__version__) < version.parse(required_version): raise RuntimeError(f"requests version must >= {required_version}") with requests.post( "<EAS_SERVICE_URL>/api/v1/audio/speech", # Replace <EAS_SERVICE_URL> with the service endpoint. # Example: "http://cosyvoice-frontend-test.1534081855183999.cn-hangzhou.pai-eas.aliyuncs.com/api/v1/audio/speech" headers={ "Authorization": "Bearer <EAS_TOKEN>", # Replace <EAS_TOKEN> with the service token. "Content-Type": "application/json", }, json={ "model": "CosyVoice2-0.5B", "input": { "mode": "natural_language_replication", "reference_audio_id": "<reference_audio_id>", # Replace <reference_audio_id> with the reference audio ID. "text": "Receiving a birthday gift from a friend far away, the unexpected surprise and deep blessings filled my heart with sweet joy, and my smile bloomed like a flower.", "output_format": "mp3", "sample_rate": 24000, "speed": 1.0, "bit_rate": "48k", "volume": 2.0, "instruct": "Speak in Sichuan dialect" }, "stream": False }, timeout=10 ) as response: if response.status_code != 200: print(response.text) exit() data = json.loads(response.content) encode_buffer = data['output']['audio']['data'] decode_buffer = base64.b64decode(encode_buffer) with open('./http_non_stream.mp3', 'wb') as f: f.write(decode_buffer)Streaming call
cURL
Replace <EAS_SERVICE_URL> and <EAS_TOKEN> with the service endpoint and token.
Replace <reference_audio_id> with the reference audio ID.
# Replace <EAS_SERVICE_URL> and <EAS_TOKEN> with the service endpoint and token. # Replace <reference_audio_id> with the reference audio ID. curl -XPOST <EAS_SERVICE_URL>/api/v1/audio/speech \ --header 'Authorization: Bearer <EAS_TOKEN>' \ --header 'Content-Type: application/json' \ --data '{ "model": "CosyVoice2-0.5B", "input": { "mode": "natural_language_replication", "reference_audio_id": "<reference_audio_id>", "text": "Receiving a birthday gift from a friend far away, the unexpected surprise and deep blessings filled my heart with sweet joy, and my smile bloomed like a flower.", "speed": 1.0, "output_format": "mp3", "sample_rate": 32000, "bit_rate": "48k", "volume": 2.0, "instruct": "Speak in Sichuan dialect" }, "stream": true }'The Base64-encoded result is returned:
data: {"output":{"finish_reason":null,"audio":{"data":"DNgB9djax9su3Ba...."}},"request_id": "f90a65be-f47b-46b5-9ddc-70bae550****"} data: {"output":{"finish_reason":null,"audio":{"data":"DNgB9djax9su3Ba...."}},"request_id": "f90a65be-f47b-46b5-9ddc-70bae550****"} data: {"output":{"finish_reason":null,"audio":{"data":"DNgB9djax9su3Ba...."}},"request_id": "f90a65be-f47b-46b5-9ddc-70bae550****"} data: {"output":{"finish_reason":null,"audio":{"data":"DNgB9djax9su3Ba...."}},"request_id": "f90a65be-f47b-46b5-9ddc-70bae550****"}Python
Install the Python SSE client:
pip install requests==2.32.3 packaging==24.2 sseclient-py==1.8.0 -i http://mirrors.cloud.aliyuncs.com/pypi/simple --trusted-host mirrors.cloud.aliyuncs.comimport io import json import base64 import wave import requests from sseclient import SSEClient # pip install sseclient-py from packaging import version required_version = "2.32.3" if version.parse(requests.__version__) < version.parse(required_version): raise RuntimeError(f"requests version must >= {required_version}") with requests.post( "<EAS_SERVICE_URL>/api/v1/audio/speech", # Replace <EAS_SERVICE_URL> with the service endpoint. # Example: "http://cosyvoice-frontend-test.1534081855183999.cn-hangzhou.pai-eas.aliyuncs.com/api/v1/audio/speech" headers={ "Authorization": "Bearer <EAS_TOKEN>", # Replace <EAS_TOKEN> with the service token. "Content-Type": "application/json", }, json={ "model": "CosyVoice2-0.5B", "input": { "mode": "natural_language_replication", "reference_audio_id": "<reference_audio_id>", # Replace <reference_audio_id> with the reference audio ID. "text": "Receiving a birthday gift from a friend far away, the unexpected surprise and deep blessings filled my heart with sweet joy, and my smile bloomed like a flower.", "output_format": "mp3", "sample_rate": 24000, "speed": 1.0, "bit_rate": "48k", "volume": 2.0, "instruct": "Speak in Sichuan dialect" }, }, timeout=10 ) as response: if response.status_code != 200: print(response.text) exit() messages = SSEClient(response) with open('./http_stream.mp3', 'wb') as f: for i, msg in enumerate(messages.events()): print(f"Event: {msg.event}, Data: {msg.data}") data = json.loads(msg.data) if data['error'] is not None: print(data['error']) break encode_buffer = data['output']['audio']['data'] decode_buffer = base64.b64decode(encode_buffer) f.write(decode_buffer)Websocket API
Install the following dependency:
pip install websocket-client==1.8.0 -i http://mirrors.cloud.aliyuncs.com/pypi/simple --trusted-host mirrors.cloud.aliyuncs.com#!/usr/bin/python # -*- coding: utf-8 -*- import base64 import json import logging import sys import time import uuid import traceback import websocket class TTSClient: def __init__(self, api_key, uri, params, log_level='INFO'): """ Initializes a TTSClient instance. Parameters: api_key (str): The API key for authentication. uri (str): The WebSocket service endpoint. """ self._api_key = api_key # Replace with your API key. self._uri = uri # Replace with your WebSocket endpoint. self._task_id = str(uuid.uuid4()) # Generate a unique task ID. self._ws = None # WebSocketApp instance self._task_started = False # Specifies whether a task-started message is received. self._task_finished = False # Specifies whether a task-finished or task-failed message is received. self._check_params(params) self._params = params self._chunk_metrics = [] self._metrics = {} self._first_package_time = None self._last_time = None self._init_log(log_level) self.audio_data = b'' def _init_log(self, log_level): self._log = logging.getLogger("ws_client") log_formatter = logging.Formatter('%(asctime)s - Process(%(process)s) - %(levelname)s - %(message)s') stream_handler = logging.StreamHandler(stream=sys.stdout) stream_handler.setFormatter(log_formatter) self._log.addHandler(stream_handler) self._log.setLevel(log_level) def get_metrics(self): """Gets the performance metrics of the synthesis result.""" return self._metrics def _check_params(self, params): assert 'mode' in params and params['mode'] in ['fast_replication', 'cross_lingual_replication', 'natural_language_replication'] assert 'reference_audio_id' in params assert 'output_format' in params and params['output_format'] in ['wav', 'mp3', 'pcm'] if params['mode'] == 'natural_language_replication': assert 'instruct' in params and params['instruct'] else: if 'instruct' in params: del params['instruct'] def on_open(self, ws): """ The callback function when a WebSocket connection is established. Sends a run-task instruction to start a speech synthesis task. """ self._log.debug("WebSocket connected") # Construct a run-task instruction. run_task_cmd = { "header": { "action": "run-task", "task_id": self._task_id, "streaming": "duplex" }, "payload": { "task_group": "audio", "task": "tts", "function": "SpeechSynthesizer", "model": "cosyvoice-v2", "parameters": { "mode": self._params['mode'], "reference_audio_id": self._params['reference_audio_id'], "output_format": self._params.get('output_format', 'wav'), "sample_rate": self._params.get('sample_rate', 24000), "bit_rate": self._params.get('bit_rate', '192k'), "volume": self._params.get('volume', 1.0), "instruct": self._params.get('instruct', ''), "speed": self._params.get('speed', 1.0), "debug": True, }, "input": {} } } # Send the run-task instruction. ws.send(json.dumps(run_task_cmd)) self._log.debug("run-task instruction sent") def on_message(self, ws, message): """ The callback function when a message is received. Processes text and binary messages separately. """ try: msg_json = json.loads(message) # self._log.debug(f"Received JSON message: {msg_json}") self._log.debug(f"Received JSON message: {msg_json['header']['event']}") if "header" in msg_json: header = msg_json["header"] if "event" in header: event = header["event"] if event == "task-started": self._log.debug("Task started") self._task_started = True # Send a continue-task instruction. for text in self._params['texts']: self.send_continue_task(text) # After all continue-task instructions are sent, send a finish-task instruction. self.send_finish_task() self._last_time = time.time() elif event == "result-generated": metrics = msg_json['payload']['metrics'] cur_time = time.time() metrics['client_cost_time'] = cur_time - self._last_time self._last_time = cur_time encode_data = msg_json["payload"]["output"]["audio"]["data"] decode_data = base64.b64decode(encode_data) self._log.debug(f"Received audio data, size: {len(decode_data)} bytes") self.audio_data += decode_data metrics['client_rtf'] = metrics['client_cost_time'] / metrics['speech_len'] self._chunk_metrics.append(metrics) elif event == "task-finished": self._metrics = { 'client_first_package_time': self._chunk_metrics[0]['client_cost_time'], "client_rtf": sum([m["client_cost_time"] for m in self._chunk_metrics]) / sum([m["speech_len"] for m in self._chunk_metrics]), 'client_cost_time': sum([m["client_cost_time"] for m in self._chunk_metrics]), 'speech_len': sum([m["speech_len"] for m in self._chunk_metrics]), 'server_first_package_time': self._chunk_metrics[0]['server_cost_time'], 'server_rtf': sum([m["server_cost_time"] for m in self._chunk_metrics]) / sum([m["speech_len"] for m in self._chunk_metrics]), 'server_cost_time': sum([m["server_cost_time"] for m in self._chunk_metrics]), "generate_time": sum([m["generate_time"] for m in self._chunk_metrics]) } self._log.debug(f"Task finished. Request performance metrics: client_first_package_time: {self._metrics['client_first_package_time']:.3f}, client_rtf: {self._metrics['client_rtf']:.3f}, client_cost_time: {self._metrics['client_cost_time']:.3f}, speech_len: {self._metrics['speech_len']:.3f}, server_cost_time: {self._metrics['server_cost_time']:.3f}, generate_time: {self._metrics['generate_time']:.3f}") self._task_finished = True self.close(ws) elif event == "task-failed": self._log.error(f"Task failed: {msg_json}") self._task_finished = True self.close(ws) except json.JSONDecodeError as e: self._log.error(f"JSON parsing failed: {str(e)}\t{traceback.format_exc()}") def on_error(self, ws, error): """The callback function when an error occurs.""" self._log.error(f"WebSocket error: {error}\t{traceback.format_exc()}") self._metrics = {'error': error} def on_close(self, ws, close_status_code, close_msg): """The callback function when the connection is closed.""" self._log.debug(f"WebSocket closed: {close_msg} ({close_status_code})") def send_continue_task(self, text): """Sends a continue-task instruction with the text to be synthesized.""" cmd = { "header": { "action": "continue-task", "task_id": self._task_id, "streaming": "duplex" }, "payload": { "input": { "text": text } } } self._ws.send(json.dumps(cmd)) self._log.debug(f"Sent continue-task instruction, text content: {text}") def send_finish_task(self): """Sends a finish-task instruction to end the speech synthesis task.""" cmd = { "header": { "action": "finish-task", "task_id": self._task_id, "streaming": "duplex" }, "payload": { "input": {} } } self._ws.send(json.dumps(cmd)) self._log.debug("Sent finish-task instruction") def close(self, ws): """Actively closes the connection.""" if ws and ws.sock and ws.sock.connected: ws.close() self._log.debug("Connection actively closed") def run(self): """Starts the WebSocket client.""" # Set the request header for authentication. header = { "Authorization": f"Bearer {self._api_key}", } # Create a WebSocketApp instance. self._ws = websocket.WebSocketApp( self._uri, header=header, on_open=self.on_open, on_message=self.on_message, on_error=self.on_error, on_close=self.on_close ) self._log.debug("Listening for WebSocket messages...") self._ws.run_forever() # Start the persistent connection listener. # Example if __name__ == "__main__": API_KEY = "<EAS_TOKEN>" # Replace <EAS_TOKEN> with the service token. SERVER_URI = "ws://<EAS_SERVICE_URL>/api-ws/v1/audio/speech" # Replace <EAS_SERVICE_URL> with the service endpoint. # Example: "ws://cosyvoice-frontend-test.1534081855183999.cn-hangzhou.pai-eas.aliyuncs.com/api-ws/v1/audio/speech" texts = [ "Receiving a birthday gift from a friend far away, the unexpected surprise and deep blessings filled my heart with sweet joy, and my smile bloomed like a flower." ] params = { "mode": "natural_language_replication", "texts": texts, "reference_audio_id": "<reference_audio_id>", "speed": 1.0, "output_format": "mp3", "sample_rate": 24000, "bit_rate": "48k", "volume": 2.0, "instruct": "Speak in a calm tone" } client = TTSClient(API_KEY, SERVER_URI, params, log_level='DEBUG') client.run() with open('./websocket_stream.mp3', 'wb') as wfile: wfile.write(client.audio_data)