OpenSearch Vector Search Edition pulls multimodal data—text, images, and video—directly from a Data Lake Formation (DLF) data source, vectorizes it using built-in models or the AI Search Open Platform, and indexes the results for similarity search. This turns unstructured lakehouse data into a searchable vector index without a separate ingestion pipeline.
Supported table formats: Paimon, Lance, and Object Table. Supported use cases: image search, text semantic search, and video search.
Prerequisites
Before you begin, ensure that you have:
-
A DLF data catalog, database, and data table configured—these identifiers are required during data synchronization
-
Reviewed the Data Lake Formation overview
Limitations
Review these constraints before configuring:
| Constraint | Detail |
|---|---|
| Vector: Video Search template | Does not support DLF as a full data source |
| Vector: Text Semantic Search template | Supports only the Paimon table format |
| Common Template and Vector: Image Search | Support Paimon, Lance, and Object Table formats |
| Paimon primary key table | Supports add, delete, update, and query operations |
| Paimon append-only table | Write-only; data cannot be modified or deleted after ingestion |
| Existing instances | Must upgrade the engine version before using DLF data sources |
Add a DLF data source
Step 1: Set basic information
-
On the Instance Details > Table Management page, click Add Table.
-
In the Basic Information step, configure the following parameters, then click Next.
Parameter Description Table Name A custom name for the table. Data Shards If you create multiple index tables, all must have the same shard count—or one table can have a single shard while the others share an identical count. Number of Resources for Data Updates Controls the compute allocated for data updates. Each index includes a free quota of two resources; each resource provides 4 CPU cores and 8 GB of memory. Resources beyond the free quota are billed. See Billing of Vector Search Edition. Scenario Template Choose from four built-in templates: Common Template, Vector: Image Search, Vector: Text Semantic Search, and Vector: Video Search. See Limitations for format restrictions per template. 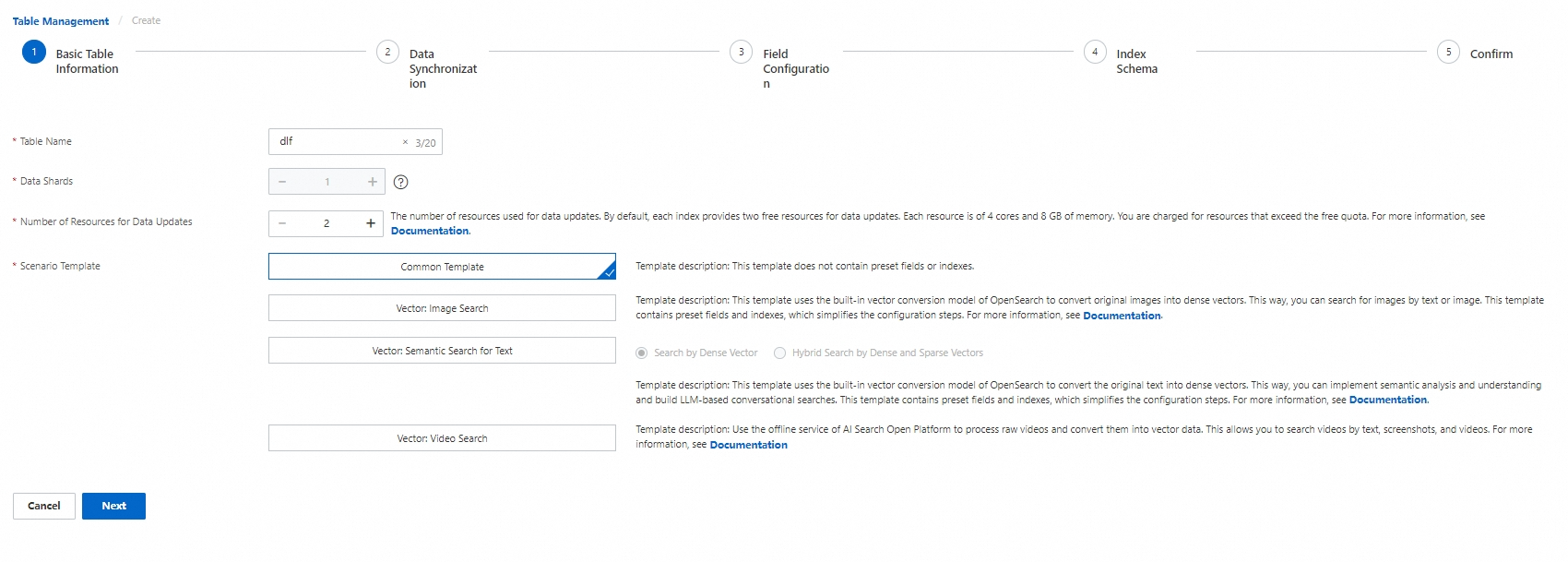
Step 2: Configure the data source
In the Data Synchronization step, configure the source, then click Next after the data source check passes.
| Parameter | Description |
|---|---|
| Full Data Source | Select Data Lake Formation (DLF). |
| Table Format | Select Paimon, Lance, or Object Table. See Table formats for details. |
| Data Catalog | The ID of the target DLF data catalog. |
| Database | The database in the target data catalog. |
| Data Table | The data table in the target database. |
| Relative Path | The relative path to files in the object table. Applies only when Table Format is Object Table. |
| Data Format | Select ha3 or json. Applies only when Table Format is Object Table. |
| Tag | A data version tag. If specified, OpenSearch uses the tagged data for the full import. If left blank, OpenSearch uses the latest data in the table. |
| Data Source Check | Verifies connectivity to the data source. Proceed to the next step only after verification passes. |
Table formats
Paimon is a lakehouse table format that supports real-time data updates and both stream and batch processing. Paimon provides a tag feature to retain metadata and data files of specific snapshots, preventing historical data loss due to snapshot expiration. Tags can be created automatically based on write jobs, generated periodically by processing time or watermark, or created, deleted, and rolled back manually. Configure a data retention policy to control the maximum number of tags or their retention period to ensure that historical data remains queryable. For more information, see Paimon Tags.
Lance is a vector table format designed for AI workloads that enables ultra-fast similarity searches on vectors. Lance uses tags to mark specific versions in a dataset's history, making it easier to track dataset evolution in frequently updated machine learning workflows. Tags do not create new versions—they exist as metadata in a separate folder and are not removed by the cleanup_old_versions operation—remove the tag first before removing the corresponding version. For more information, see Lance Tags.
Object Table is a metadata table format that lets you query and locate files stored in the cloud using SQL.
Step 3: Configure fields
In the Field Configuration step, configure the schema fields, then click Next.
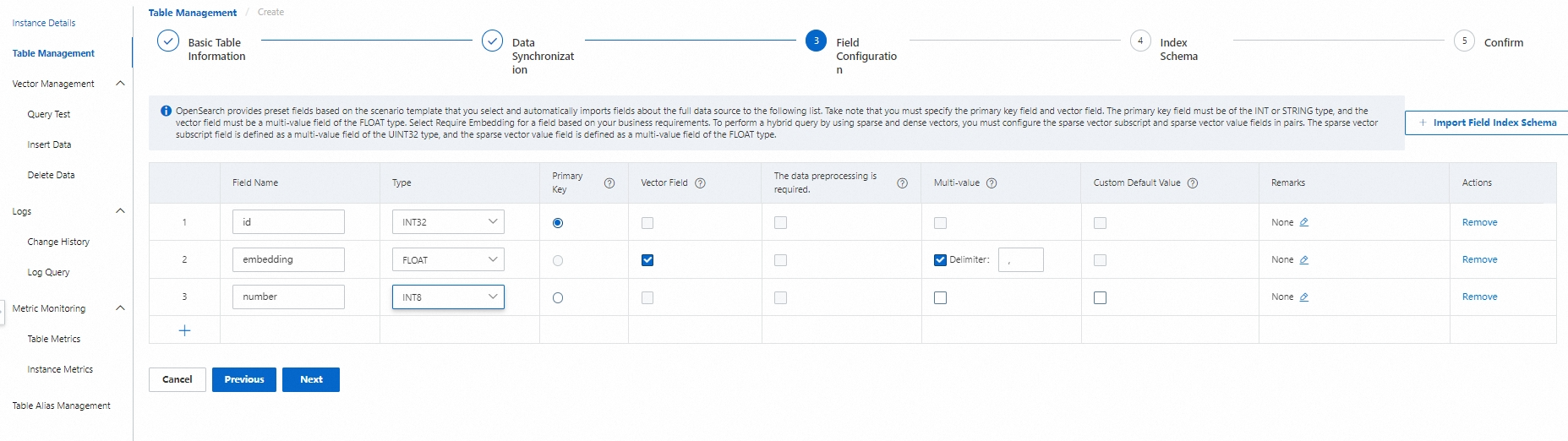
The following fields are required:
| Field | Type | Option to enable | Notes |
|---|---|---|---|
| Primary key | int or string |
Primary Key | Uniquely identifies each record. |
| Vector | float |
Vector Field | Multi-value float field by default. |
For String type fields, enable Data pre-processing required and click Configure to call a model that pre-processes the field data before indexing.
If a source field is missing or empty, the system assigns a default value automatically: 0 for numeric fields and an empty string for string fields. Specify custom default values to override these defaults.
Pre-processing by data type
Text data type

| Setting | Options |
|---|---|
| Data type | Text |
| Pre-processing template | Dense vectorization, or Dense + sparse vectorization |
| Model sources | Built-in models: A limited selection of model types, available at no cost. AI Search Open Platform: A broader model selection, billed per call. Activate a workspace and an API key on the AI Search Open Platform before use. See Billing methods and billable items. Custom model: Go to Models > Custom Models on the Vector Search Edition page and click Create Model. See Custom model. |
Image data type
| Setting | Options |
|---|---|
| Data type | Image |
| Data source | Object Storage Service (OSS): Store images in an OSS folder and specify the OSS path to import them directly. Base64 encoding: Encode the images first, then store them in a database or transfer them via API. DLF-Object Table: Specify the corresponding data catalog, database, and data table. |
| Pre-processing template | Image vectorization, Image content parsing, or Image content parsing + image vectorization |
| Model sources | Same options as Text: built-in models, AI Search Open Platform, or custom models. |
Video data type
| Setting | Options |
|---|---|
| Data type | Video |
| Data source | Object Storage Service (OSS) |
| Pre-processing template | Video processing |
| Model sources | Same options as Text: built-in models, AI Search Open Platform, or custom models. |
Step 4: Configure indexes
In the Index Schema step, configure the indexes, then click Next.
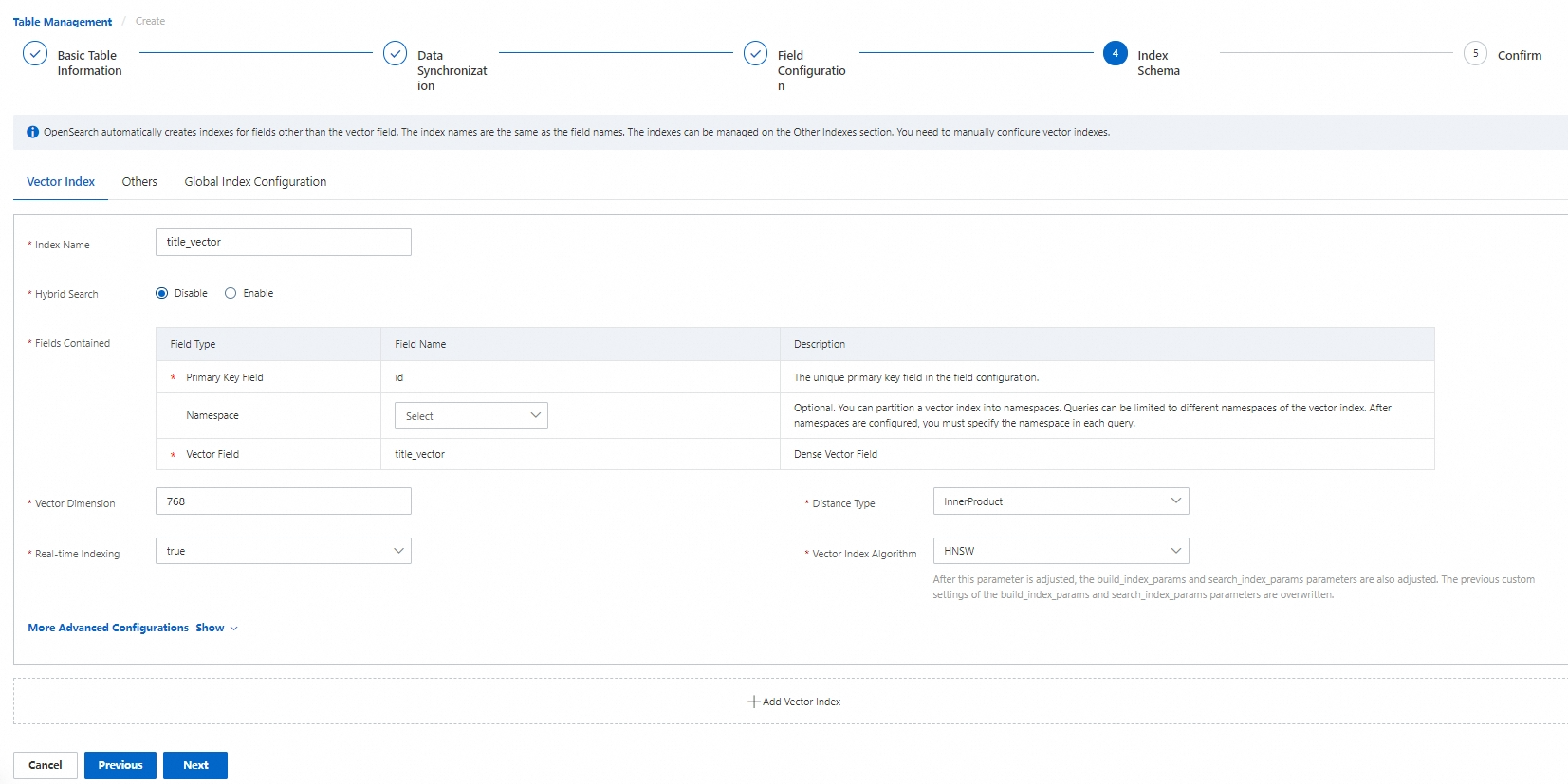
Vector index
| Parameter | Description |
|---|---|
| Vector Dimensions | Select dimensions that match the output of your embedding model. |
| Distance Type | Select the distance metric that matches your model output. Supported types: Squared Euclidean, Inner Product (dot product), and Cosine. |
| Vector Search Algorithm | Select the index algorithm for your use case. Supported algorithms: Linear, HNSW, QGraph, QC, DiskANN, and CagraHnsw. |
| Real-time Index | Whether to build real-time indexes for incremental data pushed via API calls. Default: true. |
To configure advanced vector index settings, expand the advanced section. See Common configurations for vector indexes for parameter details.

Other indexes
The system automatically generates a pk field and a primary key index. For all other non-vector fields, an index with the same name is created by default.
Global index configuration
Enable automatic cleanup for expired documents. When enabled, a document is deleted automatically when the difference between the current time and the document's timestamp exceeds the specified expiration time.
Step 5: Confirm and verify
-
In the Confirm step, click Confirm. The system creates the table. Track progress on the Change History page.
-
After the table status changes to In Use, run a query test on the Query Test page to verify that data is indexed and searchable.
Usage notes
When new data is written to a Paimon table in DLF, OpenSearch automatically triggers real-time indexing for that data. If you also write data manually using API calls, data consistency issues may occur—use API writes with caution in this scenario.