OpenSearch Vector Search Edition supports multiple vector index algorithms and distance metrics for various retrieval scenarios.
Vector retrieval overview
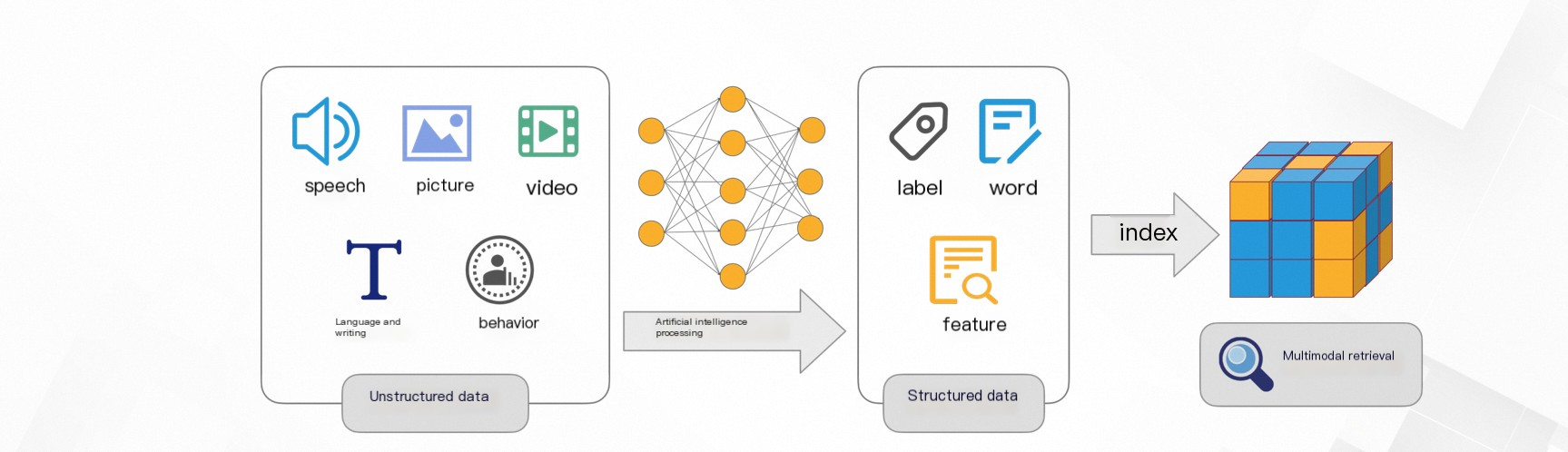
Data exists in multiple modalities beyond text, including images, videos, and audio. Multimodal data conveys details that text cannot, such as color, shape, motion, sound, and spatial relationships.

Information modalities continue to diversify across fields.

In multimodal scenarios, information is classified into two categories: structured and unstructured.
Unstructured data is difficult for computers to understand, and traditional text tokenization methods cannot meet retrieval demands across fields. Vector search solves this problem.
What are vectors, and how does vector retrieval work?
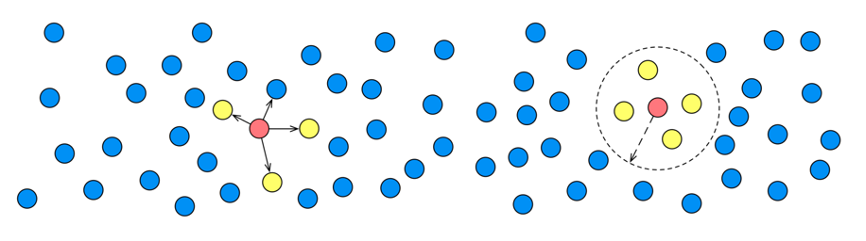
Unstructured data from the physical world is transformed into multi-dimensional vectors that represent entities and their relationships.
The system calculates distances between vectors — smaller distances indicate higher similarity — and returns the most similar results.
Algorithms
linear
The linear algorithm computes the distance between the query vector and every vector in the dataset.
Scenario: Use this algorithm if you require a 100% recall rate.
Disadvantages: This algorithm is inefficient for large datasets due to high CPU and memory consumption.
Clustering
Quantized Clustering
Overview:
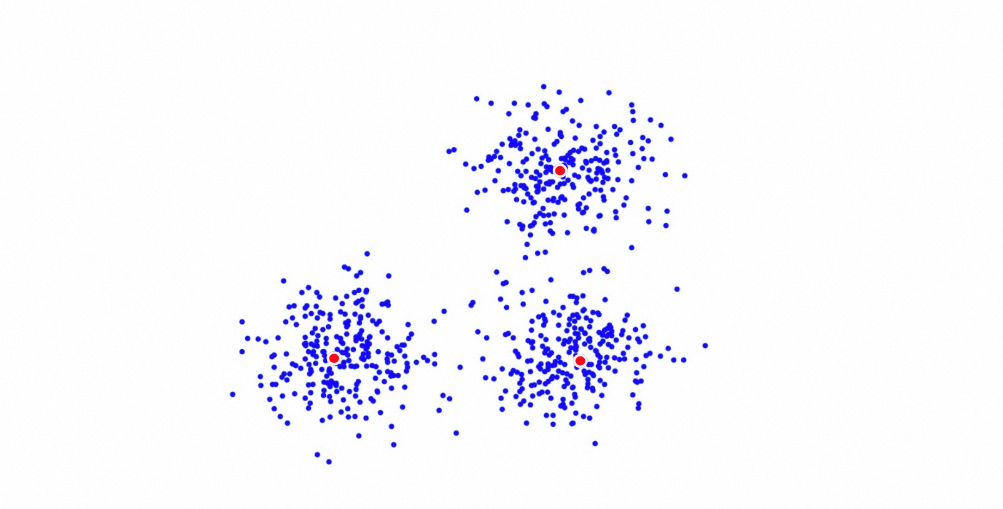
Quantized Clustering (QC) is a vector retrieval algorithm developed by Alibaba based on k-means clustering. It clusters vectors into n centroids and assigns each document to its nearest centroid, forming n inverted lists. During retrieval, the query selects the closest centroids, scans their inverted lists, and returns the top-k nearest documents.
QC supports fp16 and int8 quantization to reduce index size and improve performance at the cost of a slight reduction in recall rate.
QC is suitable for real-time data scenarios or GPU-accelerated low-latency use cases.
Parameter tuning:
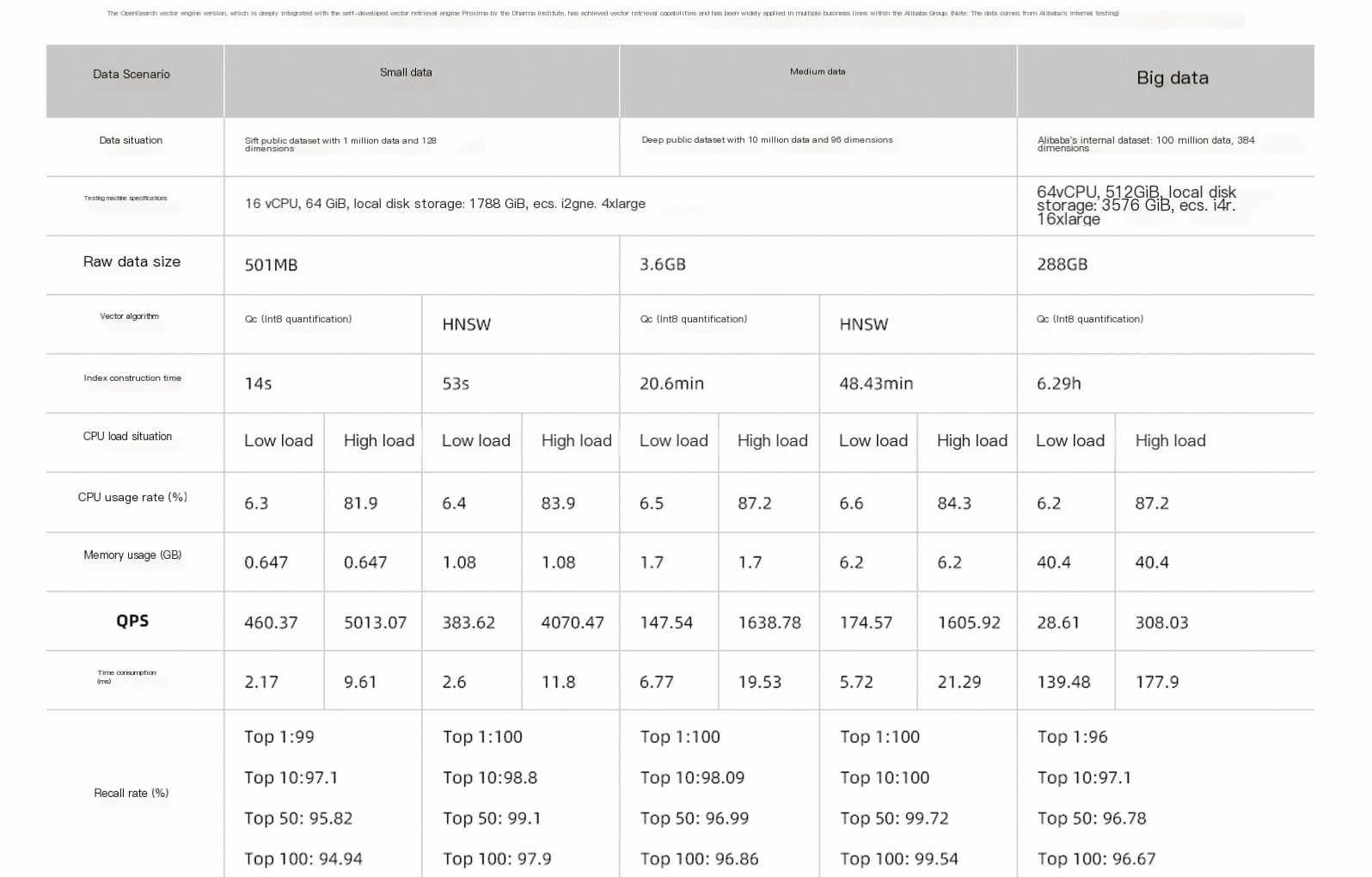
Performance comparison:
HNSW
Overview:
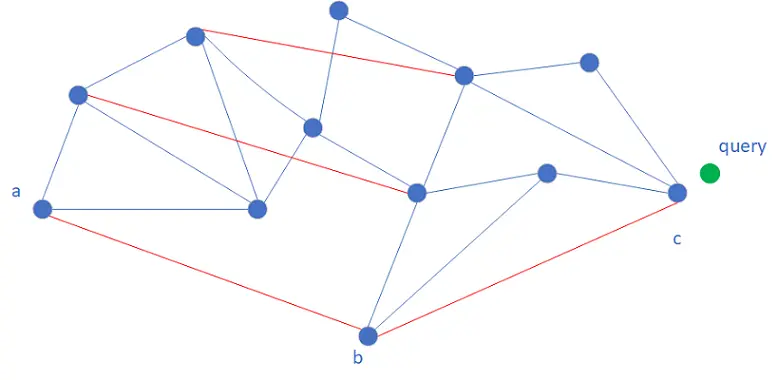
Hierarchical Navigable Small World (HNSW) is a proximity graph-based vector retrieval algorithm. It builds a graph with edges between nearby vectors. During retrieval, the search starts from an entry node, traverses to the nearest neighbor at each step, and iterates until convergence — when no neighbor of the current node is closer to the query than the best match already found.
To accelerate convergence, HNSW uses a multilayer graph similar to a skip list. Retrieval starts at the top layer and moves down. When traversal converges at a node in layer k, that node becomes the entry point for layer k-1. Upper layers have sparser nodes, enabling larger step sizes and faster iteration.
Parameter tuning:
QGraph
Overview:
Quantized Graph (QGraph) is an improved algorithm developed by OpenSearch based on HNSW. It quantizes raw data before building the graph index, reducing index size to as low as one-eighth of HNSW while achieving several times better performance through CPU instruction optimizations for integer calculations. The trade-off is a lower recall rate due to reduced vector distinctiveness, which can be mitigated by retrieving more results.
QGraph supports int4, int8, and int16 quantization. Smaller bit widths reduce memory usage and increase performance but lower the recall rate. int16 quantization provides nearly the same performance and recall rate as non-quantized data.
Parameter tuning:
CAGRA
Overview:
CUDA ANN GRAph-based (CAGRA) is a proximity graph algorithm optimized for NVIDIA GPUs, designed for high-concurrency and batch retrieval scenarios.
Unlike HNSW, CAGRA builds a single-layer proximity graph optimized for parallel computing. During a query, it iteratively selects top-k nodes from a candidate set as starting points and updates the set with their neighbors until convergence.
CAGRA supports two execution policies: single-CTA maps one query to one thread block for high throughput with large batches, and multi-CTA uses multiple thread blocks per query for better recall with small batches but lower throughput for large batches. The system selects the optimal policy automatically at runtime.
Parameter tuning:
DiskANN
Overview:
DiskANN is a disk-based approximate nearest neighbor (ANN) search algorithm for datasets that exceed available memory. It uses the Vamana graph algorithm to maintain high-performance indexing and retrieval while storing data on disk.
The DiskANN algorithm is supported only when the data node family is SSD.
Parameter tuning:
CagraHnsw
Overview:
CagraHnsw is a vector retrieval algorithm developed by OpenSearch that combines CAGRA and HNSW for rapid index building on massive datasets.
CagraHnsw uses GPUs to build indexes (like CAGRA) and converts them to HNSW-compatible format for CPU-based retrieval. This combines fast GPU index building with cost-effective CPU queries, making it more economical than CAGRA for workloads without sustained high concurrency.
Vector distance types
Vector retrieval calculates distances between vectors and returns the top-k most similar results. A smaller distance indicates higher similarity.
OpenSearch Vector Search Edition supports three distance metrics: squared Euclidean distance, inner product, and cosine distance.
Squared Euclidean distance (SquareEuclidean)
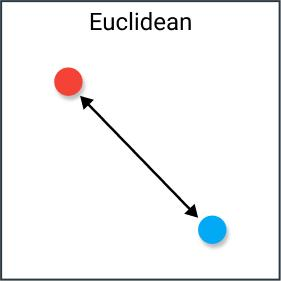
Euclidean distance measures the straight-line distance between two vectors by taking the square root of the sum of squared coordinate differences. Smaller values indicate higher similarity.
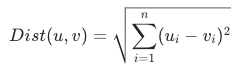
Inner product distance (InnerProduct)
The inner product (dot product) multiplies corresponding elements of two vectors and sums the products. Larger values indicate higher similarity. This metric is common in search and recommendation scenarios where the underlying model uses inner product scoring.
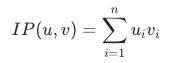
Cosine distance
Cosine distance measures the cosine of the angle between two vectors. Values range from -1 to 1: 1 indicates identical direction (highest similarity), 0 indicates perpendicularity, and -1 indicates opposite directions. This metric is commonly used for text similarity retrieval.
