The Experience Center lets you test AI search services — document parsing, text embedding, reranking, and more — through a visual interface, without writing code. After you verify that a service meets your requirements, download the sample code to start building.
Available services
| Service category | Description |
|---|---|
| Document/Image Parsing | Extracts logical structure (titles, paragraphs, tables, images) from unstructured documents and outputs content in a structured format. Also includes image content recognition using a multimodal large language model (LLM) and optical character recognition (OCR) for text in images. |
| Document Slice | Splits HTML, Markdown, and TXT content into chunks based on paragraphs, semantics, or custom rules. Supports extracting code, images, and tables as rich text. |
| Text embedding | Converts text into dense vectors for semantic search and retrieval-augmented generation (RAG) pipelines. Six models are available — see Text embedding models. |
| Multimodal vector | Converts images and text into vectors for cross-modal retrieval. Two bilingual (Chinese and English) models are available — see Multimodal vector models. |
| Sparse text embedding | Converts text into sparse vectors that represent keywords and term frequencies. Combine with dense vectors for hybrid search to improve retrieval precision. The OpenSearch sparse text vectorization service supports 100+ languages with a maximum input of 8,192 tokens. |
| Dimensionality reduction | Fine-tunes vector models to reduce embedding dimensions, lowering storage and compute costs without significant retrieval quality loss. |
| Query analysis | Analyzes user queries using LLMs and natural language processing (NLP). Supports intent recognition, query expansion, and NL2SQL conversion to improve retrieval and Q&A performance in RAG scenarios. |
| Sorting service | Scores and reranks documents by semantic relevance to a query. Three reranker models are available — see Reranker models. |
| Speech recognition | Converts audio and video content to structured text. Supports multiple languages. |
| Video snapshot | Extracts keyframes from video files. Use with multimodal embedding or image parsing to enable cross-modal retrieval. |
| Large model | Generates responses to natural language questions using LLMs. Ten models are available, including Qwen3-235B-A22B, DeepSeek-R1, and OpenSearch-Qwen-Turbo — see Large models. |
| Internet Search | Supplements your private knowledge base with real-time web results, giving the LLM more context to generate accurate responses. |
Text embedding models
| Model | Languages | Max input | Output dimensions |
|---|---|---|---|
| OpenSearch text vectorization service-001 | 40+ | 300 tokens | 1,536 |
| OpenSearch universal text vectorization service-002 | 100+ | 8,192 tokens | 1,024 |
| OpenSearch text vectorization service-Chinese-001 | Chinese | 1,024 tokens | 768 |
| OpenSearch text vectorization service-English-001 | English | 512 tokens | 768 |
| GTE text embedding-multilingual-Base | 70+ | 8,192 tokens | 768 |
| Qwen3 text embedding-0.6B | 100+ | 32k tokens | 1,024 |
Multimodal vector models
M2-Encoder-multimodal vector model: A bilingual (Chinese and English) multimodal service trained on 6 billion image-text pairs (3 billion Chinese and 3 billion English) based on BM-6B. The model supports cross-modal retrieval of images and text, including text-to-image and image-to-text search, and image classification tasks.
M2-Encoder-Large-multimodal vector model: A bilingual (Chinese and English) multimodal service. Compared to the M2-Encoder model, it has a larger model size of 1 billion (1B) parameters, providing stronger expression capabilities and better performance in multimodal tasks.
Reranker models
| Model | Languages | Max input |
|---|---|---|
| BGE rearrangement model | Chinese, English | 512 tokens (query + document) |
| OpenSearch self-developed rearrange model | Chinese, English | 512 tokens (query + document) |
| Qwen3 sorting-0.6B | 100+ | 32k tokens (query + document) |
Large models
Qwen3-235B-A22B: A new generation of the Qwen series of large language models. Based on extensive training, Qwen3 has made breakthroughs in inference, instruction following, agent capabilities, and multilingual support. It supports over 100 languages and dialects, with powerful multilingual understanding, reasoning, and generation capabilities.
OpenSearch-Qwen-Turbo: Built on the Qwen-Turbo large language model, this model is fine-tuned with supervised learning to enhance retrieval and reduce harmful content.
Qwen-Turbo: The fastest and most cost-effective model in the Qwen series. It is suitable for simple jobs. For more information, see Model List.
Qwen-Plus: A balanced model in terms of capability. Its inference performance, cost, and speed are between those of Qwen-Max and Qwen-Turbo. It is suitable for moderately complex jobs. For more information, see Model List.
Qwen-Max: The best-performing model in the Qwen series. It is suitable for complex, multi-step jobs. For more information, see Model List.
QwQ deep thinking model: A QwQ reasoning model trained on the Qwen2.5-32B model. Its reasoning capabilities have been significantly improved through reinforcement learning.
DeepSeek-R1: A large language model that specializes in complex reasoning tasks. It performs well in understanding complex instructions and ensuring result accuracy.
DeepSeek-V3: A Mixture of Experts (MoE) model that excels in long text, code, mathematics, encyclopedic knowledge, and Chinese language capabilities.
DeepSeek-R1-distill-qwen-7b: A model fine-tuned on Qwen-7B using knowledge distillation. The training samples are generated by DeepSeek-R1.
DeepSeek-R1-distill-qwen-14b: A model fine-tuned on Qwen-14B using knowledge distillation. The training samples are generated by DeepSeek-R1.
Test services
All services follow the same pattern: select a service category, provide input data, and click Get Results. After the results appear, view the Result source code for the raw API response and the Sample code for ready-to-use integration code.
Test document parsing
Log on to the Open Platform for AI Search console.
In the left navigation pane, click Experience Center.
For Service Category, select Document/Image Parsing (document-analyze), then select a service from Experience Services.
Provide test data using Sample data or Manage data. Two input methods are supported:
File: Upload a local file. Supported formats: Txt, PDF, HTML, Doc, Docx, PPT, and PPTX. Maximum file size: 20 MB. Files are purged after 7 days — the platform does not retain your data.
URL: Enter one or more file URLs, each on a separate line, and specify the file type.
ImportantSelect the correct file type. Mismatched formats cause parsing to fail.
ImportantUse the URL import feature in compliance with applicable laws. You are responsible for ensuring your actions adhere to the target platform's terms of service and the rights of content owners.

If you uploaded your own data, select the file or URL from the drop-down list.

Click Get Results.
Results: Shows parsing progress and output.
Result source code: Displays the raw API response. Click Copy Code or Download File to save it locally.
Sample code: Provides ready-to-use code for calling the document parsing service.

Test document chunking
Log on to the Open Platform for AI Search console.
In the left navigation pane, click Experience Center.
For Service Category, select Document Slice (document-split), then select a service from Experience Services.
Provide test data using Sample data or My data. If entering your own content, select the correct format: TXT, HTML, or Markdown.
Select the correct data format. Mismatched formats cause chunking to fail.
Set Maximum Slice Length (default: 300 tokens, maximum: 1,024 tokens). This controls the maximum number of tokens per chunk. Smaller chunks improve retrieval precision for specific queries; larger chunks preserve more context per result. Adjust based on your use case and the embedding model's token limit.
Toggle Return to sentence level slice if needed, then click Get Results.
Results: Shows chunking progress and output.
Result source code: Displays the raw API response. Click Copy Code or Download File to save it locally.
Sample code: Provides ready-to-use code for calling the document chunking service.
Test text and sparse embedding
Log on to the Open Platform for AI Search console.
In the left navigation pane, click Experience Center.
For Service Category, select Text Embedding (text-embedding), then select a model from Experience Services.
Set Content Type to Document or Query, depending on whether you are embedding indexed content or a search query.
Add input text using Add Text Group or Directly Enter JSON Code.

Click Get Results.
Results: Displays the embedding vectors.
Result source code: Displays the raw API response. Click Copy Code or Download File to save it locally.
Sample code: Provides ready-to-use code for calling the text embedding service.

Test multimodal embedding
Log on to the Open Platform for AI Search console.
In the left navigation pane, click Experience Center.
For Service Category, select Multimodal Vector (multi-modal-embedding), then select a model from Experience Services and choose Text, Image, or Text + Image as the input type.
Uploaded images are purged after 7 days. The platform does not retain your data.

Click Get Results.
Results: Displays the multimodal embedding vectors.
Result source code: Displays the raw API response. Click Copy Code or Download File to save it locally.
Sample code: Provides ready-to-use code for calling the multimodal embedding service.

Test the reranker
Log on to the Open Platform for AI Search console.
In the left navigation pane, click Experience Center.
For Service Category, select Sorting Service (ranker), then select a model from Experience Services.
Provide test data using Sample data or enter your own documents.
Enter a query in Search Query.

Click Get Results. The service scores each document by its relevance to the query and returns results in descending order.
Results: Shows relevance scores and ranked document order.
Result source code: Displays the raw API response. Click Copy Code or Download File to save it locally.
Sample code: Provides ready-to-use code for calling the reranking service.

Test video snapshot
Log on to the Open Platform for AI Search console.
In the left navigation pane, click Experience Center.
For Service Category, select Video Snapshot (video-snapshot).
Provide a video using Sample data or upload your own.
Click Get Results. The service extracts keyframes from the video.
Test speech recognition
Log on to the Open Platform for AI Search console.
In the left navigation pane, click Experience Center.
For Service Category, select Speech Recognition (audio-asr).
Provide audio data using Sample data or upload your own file.
Click Get Results. The service converts the audio content to structured text.
Test LLM services
Log on to the Open Platform for AI Search console.
In the left navigation pane, click Experience Center.
For Service Category, select Large model (text-generation), then select a model from Experience Services. To enable the Internet Search service, click
 . The service determines whether to perform an Internet search based on the query.
. The service determines whether to perform an Internet search based on the query.Enter a question and submit. The model generates a response. The response page shows the number of input and output tokens for the session. Delete the conversation or copy the full response as needed.
ImportantAll content is generated by an AI model. Accuracy and completeness are not guaranteed. The generated content does not represent our views or opinions.
Test image content parsing
Log on to the Open Platform for AI Search console.
In the left navigation pane, click Experience Center.
For Service Category, select Image Content Parsing (image-analyze). For Experience Services, select Image Content Recognition Service 001 or Image Text Recognition Service 001.
Provide an image using the sample images or upload your own.

Click Get Results. The service analyzes the image and outputs recognized content.
Results: Shows the detection output.
Result source code: Displays the raw API response. Click Copy Code or Download File to save it locally.
Sample code: Provides ready-to-use code for calling the image content parsing service.

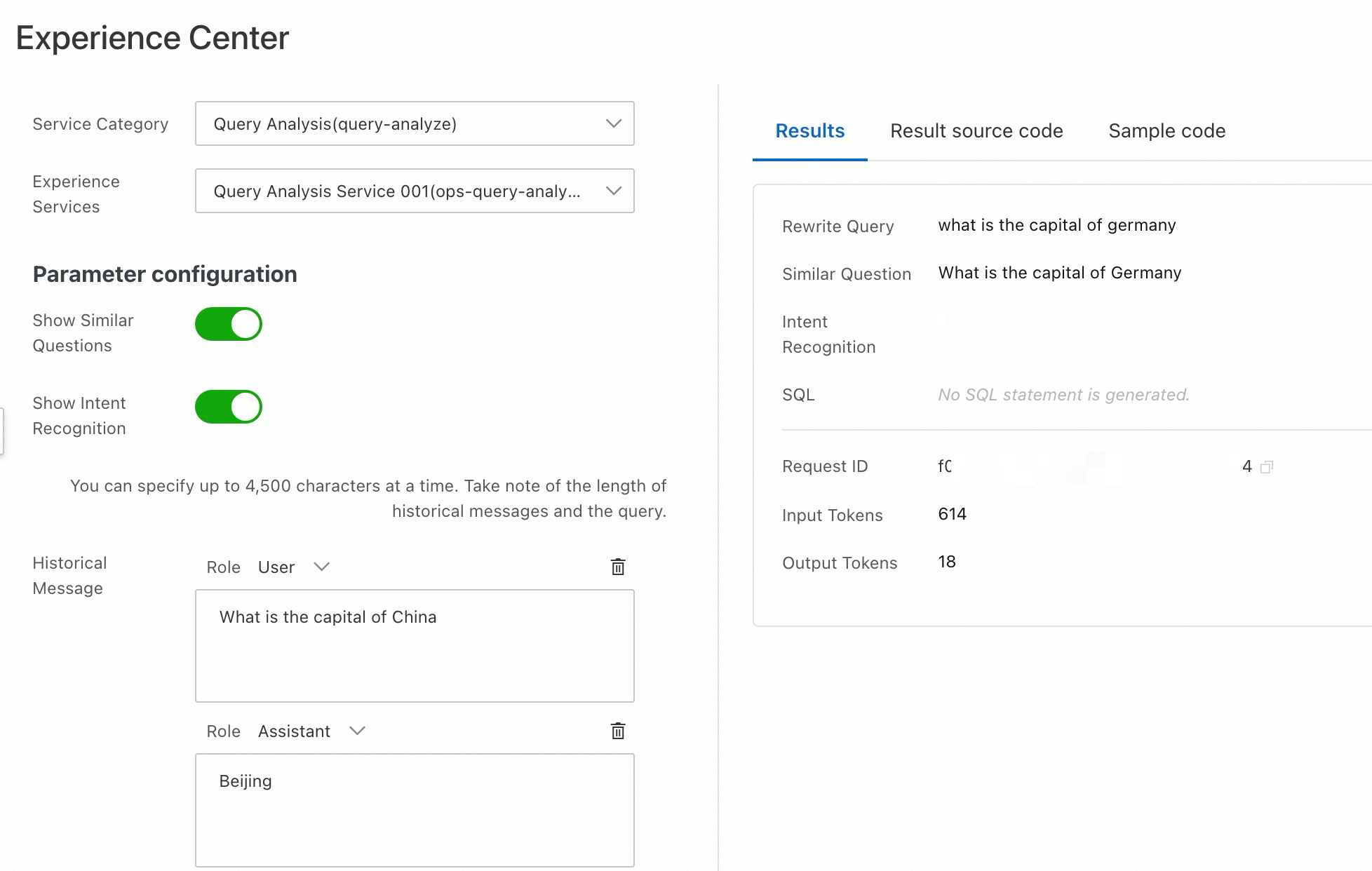
Test query analysis
Log on to the Open Platform for AI Search console.
In the left navigation pane, click Experience Center.
For Service Category, select Query Analysis (query-analyze).
Enter a query in Search Query for intent recognition. To test multi-turn behavior, add conversation history in Historical Message — the model combines both the history and the query when performing analysis. To test NL2SQL, enable Show NL2SQL and select a service configuration to convert natural language queries into SQL statements.
Click Get Results.
Results: Shows the analysis output.
Result source code: Displays the raw API response. Click Copy Code or Download File to save it locally.
Sample code: Provides ready-to-use code for calling the query analysis service.
Test vector fine-tuning
Log on to the Open Platform for AI Search console.
In the left navigation pane, click Experience Center.
For Service Category, select Dimensionality Reduction (embedding-dim-reduction).
Select the fine-tuned model, set Produced Vector Dimension to a value less than or equal to the dimension used during training, and enter the original vector.
Click Get Results to view the dimension-reduced output.
For information about training a custom dimension reduction model, see Service customization.
Test internet search
Internet Search is available in two ways: as a standalone service, or enabled within the LLM service.
Log on to the Open Platform for AI Search console.
Select the destination region and switch to the AI Search Open Platform.
In the left navigation pane, click Experience Center.
For Service Category, select Internet Search (web-search).
Enter a query in Search Query and review the results.