Microservices Engine (MSE) cloud-native gateways collect real-time queries per second (QPS) metrics from incoming traffic. By feeding these metrics into a Kubernetes HorizontalPodAutoscaler (HPA), backend applications in Container Service for Kubernetes (ACK) clusters scale out when traffic increases and scale in when traffic drops -- without manual intervention.
This guide walks through the end-to-end setup: deploying a metrics adapter, connecting an ACK service to the gateway, enabling log shipping, and configuring an HPA that scales pods based on per-pod QPS thresholds.
How it works
The auto-scaling pipeline consists of four components:
MSE cloud-native gateway --> Simple Log Service (SLS) --> Metrics adapter --> HPA --> Scale DeploymentThe MSE cloud-native gateway processes incoming requests and generates access logs.
Log shipping sends these access logs to an SLS logstore in NGINX Ingress-compatible format.
The ack-alibaba-cloud-metrics-adapter reads QPS metrics from SLS and exposes them as Kubernetes external metrics.
The HPA evaluates the external QPS metric against a target threshold and adjusts the replica count of the backend Deployment.
The HPA uses the External metric type because gateway QPS originates outside the Kubernetes metrics pipeline, unlike Resource (CPU/memory) or Pods metrics.
Prerequisites
Before you begin, make sure that you have:
An MSE cloud-native gateway. For more information, see Create a cloud-native gateway
An ACK managed cluster. For more information, see Create an ACK managed cluster
Step 1: Install the metrics adapter
The metrics adapter bridges SLS metrics and the Kubernetes metrics API. Install it from the ACK Marketplace.
Log on to the ACK console.
In the left-side navigation pane, choose Marketplace > Marketplace.
Search for ack-alibaba-cloud-metrics-adapter and click its card.
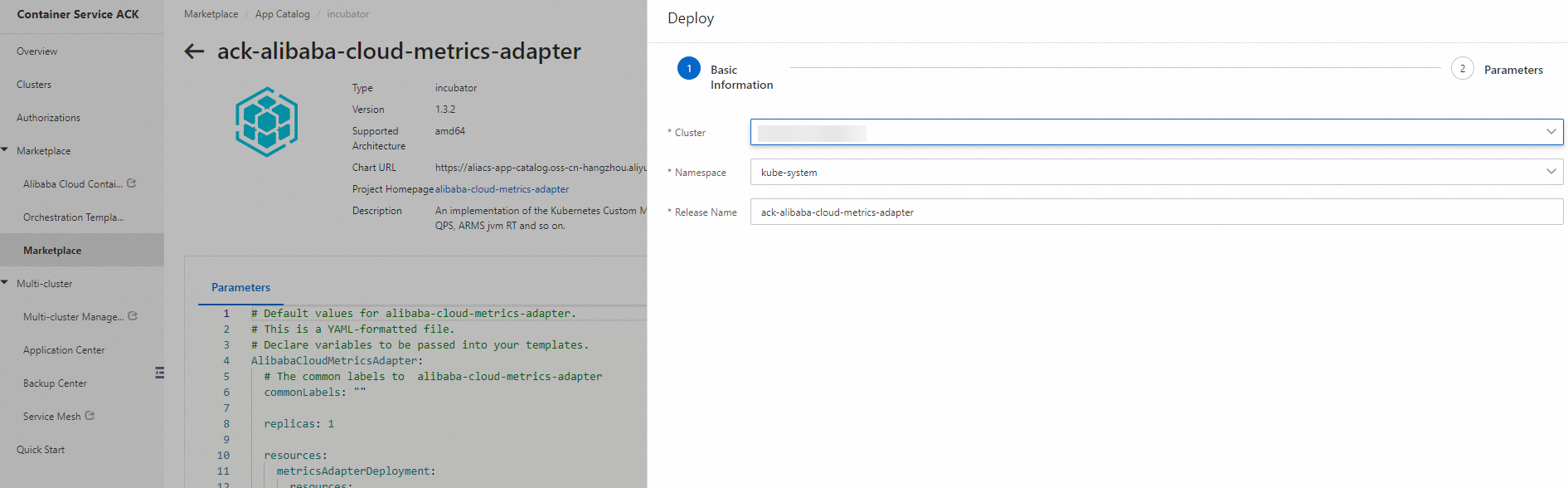
Click Deploy in the upper-right corner. In the Deploy panel, configure the settings and click OK.
Step 2: Deploy a sample backend application
Deploy a sample Deployment and Service in your ACK cluster. If you already have a backend application, skip to Step 3.
In the left-side navigation pane of the ACK console, click Clusters.
On the Clusters page, click the name of your cluster.
In the left-side navigation pane, choose Workloads > Deployments.
Click Create Resources in YAML. Select Custom from the Sample Template drop-down list, paste the following YAML, and click Create.
apiVersion: apps/v1
kind: Deployment
metadata:
name: httpbin-deploy
labels:
app: httpbin-deploy
spec:
replicas: 1
selector:
matchLabels:
app: httpbin
template:
metadata:
labels:
app: httpbin
spec:
containers:
- image: kennethreitz/httpbin
imagePullPolicy: IfNotPresent
name: httpbin
ports:
- name: http
containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: httpbin-svc
namespace: default
labels:
app: httpbin-svc
spec:
ports:
- port: 8080
name: http
protocol: TCP
targetPort: 80
selector:
app: httpbin
type: ClusterIPThis creates:
A Deployment named
httpbin-deploywith one replica running thehttpbincontainer on port 80.A Service named
httpbin-svcthat exposes the Deployment on port 8080 within the cluster.
Step 3: Connect the ACK service to the gateway
Register your ACK cluster as a service source in the MSE gateway, then add the backend service.
Add a service source
-
Log on to the MSE console. In the top navigation bar, select a region.
-
In the left-side navigation pane, choose Cloud-native Gateway > Gateways. On the Gateways page, click the ID of the gateway.
In the left-side navigation pane, click Routes. Click the Sources tab.
Click Add Source. Set Source Type to Container Service, select the ACK cluster where the application is deployed, and click OK.
Add a service
On the same Routes page, click the Services tab.
Click Add Service. In the Services section, select the service source you added, and click OK.
Create a routing rule
Create a routing rule for the service. For detailed instructions, see Create a routing rule.
Step 4: Enable log shipping
Log shipping sends gateway access logs to SLS, which the metrics adapter reads to calculate QPS.
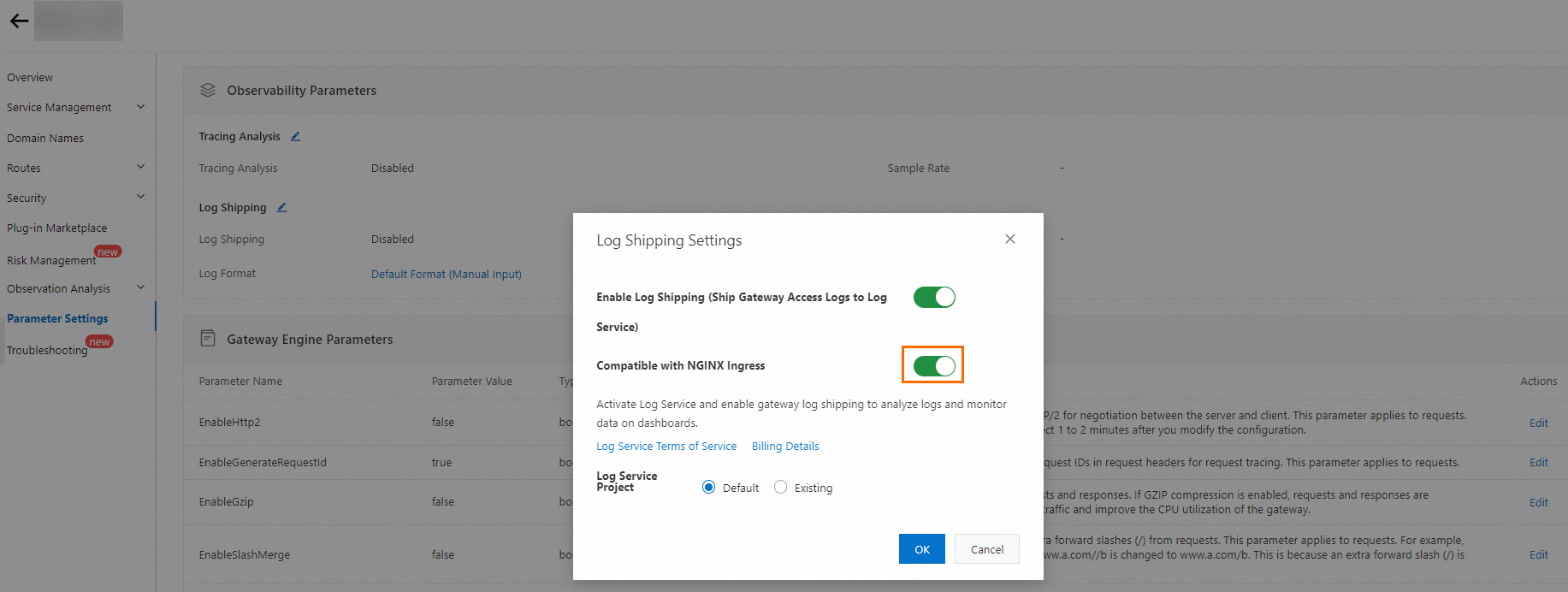
In the left-side navigation pane of your gateway, click Parameter Settings.
In the Observability Parameters section, click the
 icon next to Log Shipping.
icon next to Log Shipping.In the Log Shipping Settings dialog box, turn on Enable Log Shipping (Ship Gateway Access Logs to Log Service) and Compatible with NGINX Ingress.
Step 5: Create an HPA with QPS-based scaling
Create an HPA that scales the backend Deployment based on per-pod QPS.
Run the following command or use the ACK console to apply this YAML:
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: higress-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1beta2
kind: Deployment
name: httpbin-deploy # Deployment to scale
minReplicas: 1 # Minimum pod count
maxReplicas: 10 # Maximum pod count
metrics:
- type: External # External metric (from SLS, not from K8s)
external:
metric:
name: sls_ingress_qps # QPS metric exposed by the metrics adapter
selector:
matchLabels:
sls.project: "aliyun-product-data-xxxxxxxxxxxxx-cn-hangzhou" # SLS project name
sls.logstore: "nginx-ingress" # SLS logstore name
sls.ingress.route: "default-httpbin-svc-8080" # <namespace>-<service>-<port>
target:
type: AverageValue
averageValue: 10 # Scale out when per-pod QPS exceeds 10Replace the following placeholders with your actual values:
| Parameter | Description | How to find the value |
|---|---|---|
sls.project | SLS project that stores gateway access logs | Go to the Overview page of your gateway in the MSE console. The project name appears in the log shipping section. |
sls.logstore | SLS logstore name | Default: nginx-ingress (when Compatible with NGINX Ingress is enabled). |
sls.ingress.route | Identifies the backend service | Format: <namespace>-<service-name>-<port>. For the sample service: default-httpbin-svc-8080. |
name (under scaleTargetRef) | Deployment to auto-scale | The name of your backend Deployment. |
averageValue | QPS threshold per pod that triggers scale-out | Adjust based on your application's capacity. |
Step 6: Verify auto-scaling
Generate traffic against the gateway route and confirm that the HPA scales the backend Deployment.
Run a load test against the gateway route to generate sustained QPS above the configured threshold (10 in the example).
Check the HPA status:
kubectl describe hpa higress-hpaIn the Events section of the output, look for
SuccessfulRescaleevents: "above target" means the average per-pod QPS exceeded theaverageValuethreshold, which triggered scale-out.Normal SuccessfulRescale 9m horizontal-pod-autoscaler New size: 3; reason: external metric sls_ingress_qps(...) above target Normal SuccessfulRescale 8m45s horizontal-pod-autoscaler New size: 4; reason: external metric sls_ingress_qps(...) above targetStop the load test. After the stabilization window (default: 300 seconds), the HPA scales the Deployment back down: "All metrics below target" means QPS dropped below the threshold and the HPA reduced the replica count.
Normal SuccessfulRescale 3m41s horizontal-pod-autoscaler New size: 3; reason: All metrics below target Normal SuccessfulRescale 2m55s horizontal-pod-autoscaler New size: 1; reason: All metrics below target
Tune scaling behavior (optional)
By default, the HPA uses a 300-second stabilization window for scale-down and no stabilization window for scale-up. To customize this behavior -- for example, to prevent rapid scale-down after a traffic spike -- add a behavior block to the HPA spec:
spec:
behavior:
scaleUp:
stabilizationWindowSeconds: 0 # Scale up immediately (default)
policies:
- type: Percent
value: 100
periodSeconds: 15
scaleDown:
stabilizationWindowSeconds: 300 # Wait 5 minutes before scaling down (default)
policies:
- type: Percent
value: 100
periodSeconds: 15For more information about scaling policies, see Horizontal Pod Autoscaling in the Kubernetes documentation.