Models like qwen3.5-plus and kimi-k2.5 support image understanding natively. For text-only models like glm-5 and MiniMax-M2.5, add a local skill for visual capabilities.
Image understanding skills consume Coding Plan quota. No additional charges apply.
Prerequisites
-
You have subscribed to Coding Plan. See Getting started.
-
You have set up Coding Plan and can use it normally. See Set up AI tools.
Visual support status
|
Model |
Visual support |
Description |
|
Yes |
No configuration needed -- pass images directly. |
|
No |
A skill or agent is required for visual capabilities. |
Method 1: Use a visual model directly (recommended)
qwen3.5-plus and kimi-k2.5 support image understanding natively. Switch to these models for frequent image work.
|
Tool |
How to switch |
|
Claude Code |
|
|
OpenCode |
|
|
Qwen Code |
|
For other tools, see Set up AI tools. After switching, reference image paths or drag images into conversations.
Method 2: Add visual capabilities using a skill or agent
Text-only models (glm-5, MiniMax-M2.5) require a skill or agent for visual capabilities.
Claude Code
-
Add a skill
Create a
skills/image-analyzerfolder in the.claudedirectory:mkdir -p .claude/skills/image-analyzerCreate a
SKILL.mdfile:--- name: image-analyzer description: Adds visual understanding to text-only models. Analyzes images like screenshots, charts, and diagrams. Pass the image path to get a description. model: qwen3.5-plus --- qwen3.5-plus has visual understanding capabilities. Use it directly for image understanding.Folder structure:
.claude/ └── skills/ └── image-analyzer/ └── SKILL.md -
Get started
-
Start Claude Code in your project directory, then switch to
glm-5with/model glm-5. -
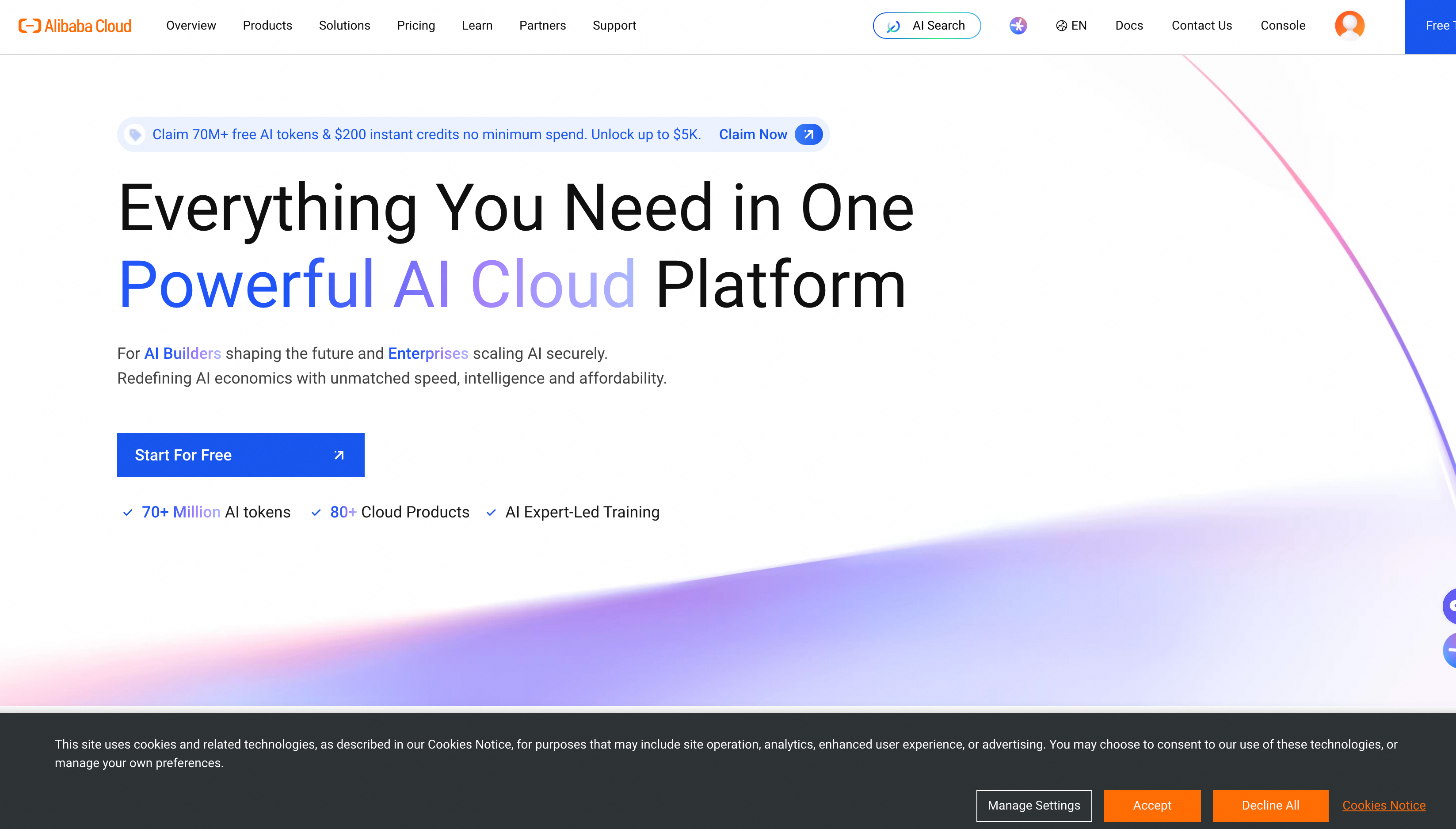
Download alibabacloud.png to your project directory. Then ask:
Load the image-analyzer skill and describe the information displayed in the alibabacloud.png banner.Response:
-
{kind=link}
OpenCode
-
Add an agent
Create an
agentsfolder in the.opencodedirectory:mkdir -p .opencode/agentsCreate an
image-analyzer.mdfile:NoteThe model field must use the provider and model name from your OpenCode configuration. For example, based on the OpenCode setup, use
bailian-coding-plan/qwen3.5-plus.--- description: Analyzes images using a vision-capable model. Invoke with @image-analyzer followed by the image path and your question. mode: subagent model: bailian-coding-plan/qwen3.5-plus tools: write: false edit: false --- You have vision capabilities. Analyze the image and return a clear description focused on the user's question.Folder structure:
.opencode/ └── agents/ └── image-analyzer.md -
Get Started
-
Start OpenCode in your project directory, then switch to
glm-5. -
Download alibabacloud.png to the project folder. Use
@to invokeimage-analyzer, then ask:@image-analyzer describe the information displayed in the alibabacloud.png banner.
-