Spark on MaxCompute supports the local, cluster, and DataWorks running modes.
Local mode
Spark on MaxCompute allows you to debug jobs in local mode that is used in native Spark.
The local mode is similar to the YARN cluster mode. To use the local mode, you must make the following preparations:
Create a MaxCompute project and obtain the AccessKey ID and AccessKey secret of the account that can be used to access the MaxCompute project.
Download the Spark on MaxCompute client.
Prepare environment variables.
Configure the spark-defaults.conf file.
Download and compile a demo project template.
For more information, see Set up a Linux development environment.
You can submit a job by running the spark-submit script on the Spark on MaxCompute client. The following code provides an example:
## Java/Scala
cd $SPARK_HOME
./bin/spark-submit --master local[4] --class com.aliyun.odps.spark.examples.SparkPi \
/path/to/odps-spark-examples/spark-examples/target/spark-examples-2.0.0-SNAPSHOT-shaded.jar
## PySpark
cd $SPARK_HOME
./bin/spark-submit --master local[4] \
/path/to/odps-spark-examples/spark-examples/src/main/python/odps_table_rw.pyPrecautions
In local mode, Tunnel is used to read data from and write data to MaxCompute tables. As a result, the read and write operations in local mode are slower than those in YARN cluster mode.
In local mode, Spark on MaxCompute is run on your on-premises machine. Therefore, you may encounter the situation that you can access Spark on MaxCompute that runs in local mode over a virtual private cloud (VPC), but you cannot access Spark on MaxCompute that runs in YARN cluster mode over a VPC.
In local mode, the network is not isolated. However, in YARN cluster mode, the network is isolated, and you must configure the required parameters for access over a VPC.
In local mode, you must use a public endpoint to access Spark on MaxCompute over a VPC. However, in YARN cluster mode, you must use an internal endpoint to access Spark on MaxCompute over a VPC. For more information about the endpoints of MaxCompute, see Endpoints.
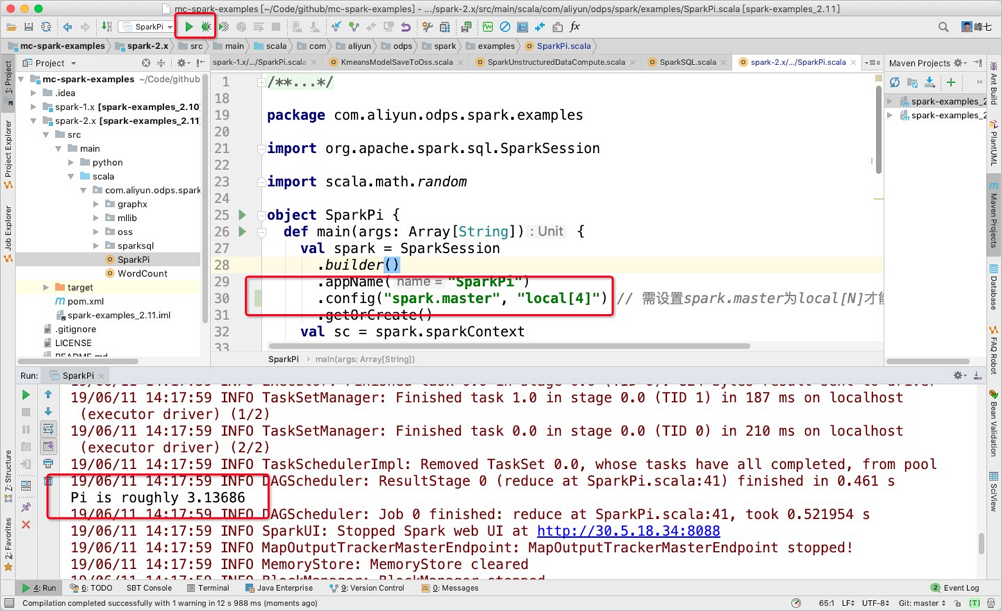
If you run Spark on MaxCompute in IntelliJ IDEA in local mode, you must specify the related configurations in the code. However, these configurations must be deleted from the code if you want to run Spark on MaxCompute in IntelliJ IDEA in YARN cluster mode.
Run Spark on MaxCompute in IntelliJ IDEA in local mode
Spark on MaxCompute allows you to directly run code in IntelliJ IDEA in local mode by using N threads. This frees you from submitting code on the Spark on MaxCompute client. Take note of the following items when you run the code:
You must manually specify the related configurations in the
odps.conffile in the main/resource directory when you run the code in IntelliJ IDEA in local mode. You cannot directly reference the configurations in the spark-defaults.conf file. The following code provides an example:NoteYou must specify configuration items in the
odps.conffile for Spark 2.4.5 and later.dops.access.id="" odps.access.key="" odps.end.point="" odps.project.name=""You must manually add the required dependencies in the
jarsfolder for the Spark on MaxCompute client in IntelliJ IDEA. Otherwise, the following error is reported:the value of spark.sql.catalogimplementation should be one of hive in-memory but was odpsYou can refer to the following steps to configure the dependencies:
In the main menu bar of IntelliJ IDEA, choose .
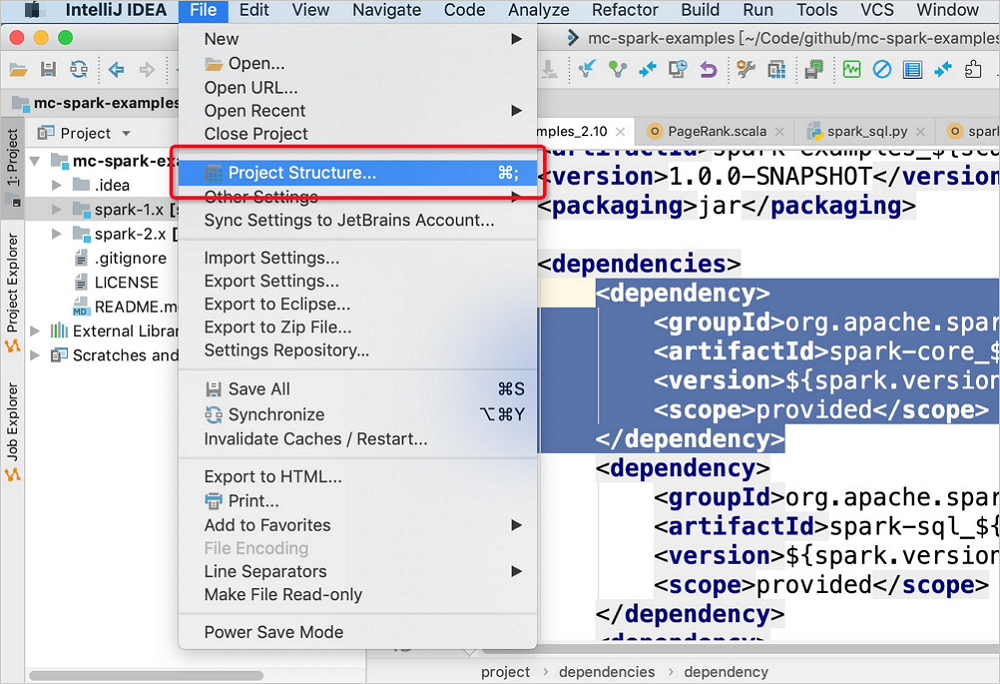
On the Project Structure page, click Modules in the left-side navigation pane. On the tab that appears, click spark-examples_2.11. In the panel that appears, click the Dependencies tab. Then, click the
 icon in the lower-left corner and select JARS or directories.
icon in the lower-left corner and select JARS or directories.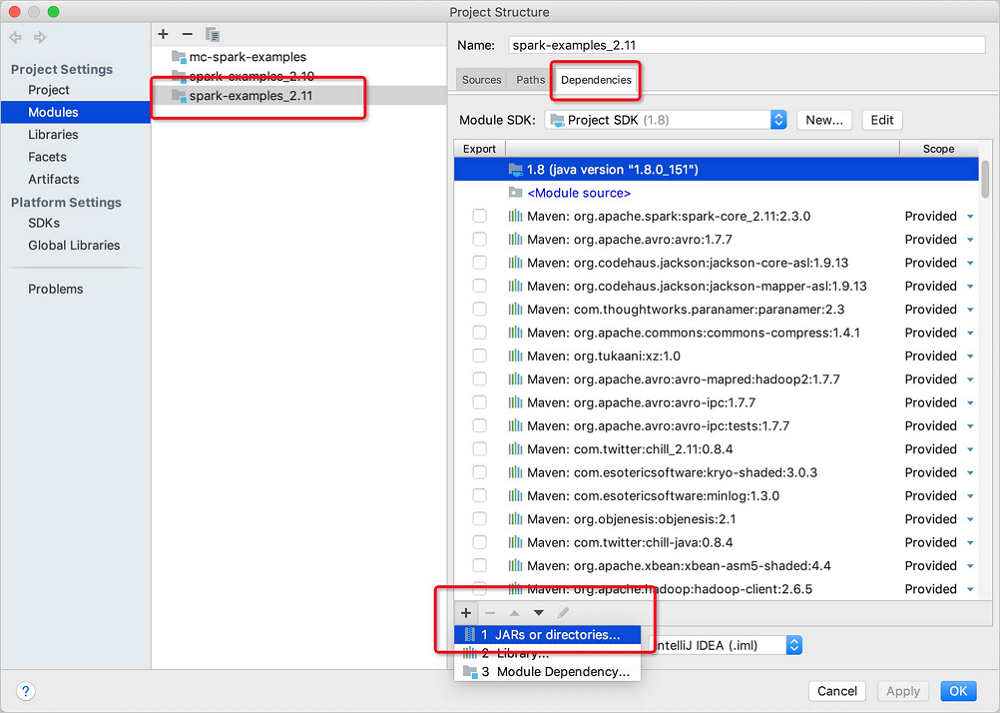
In the jars folder, choose the required version of the Spark on MaxCompute package > jars > required JAR file and click Open in the lower-right corner.
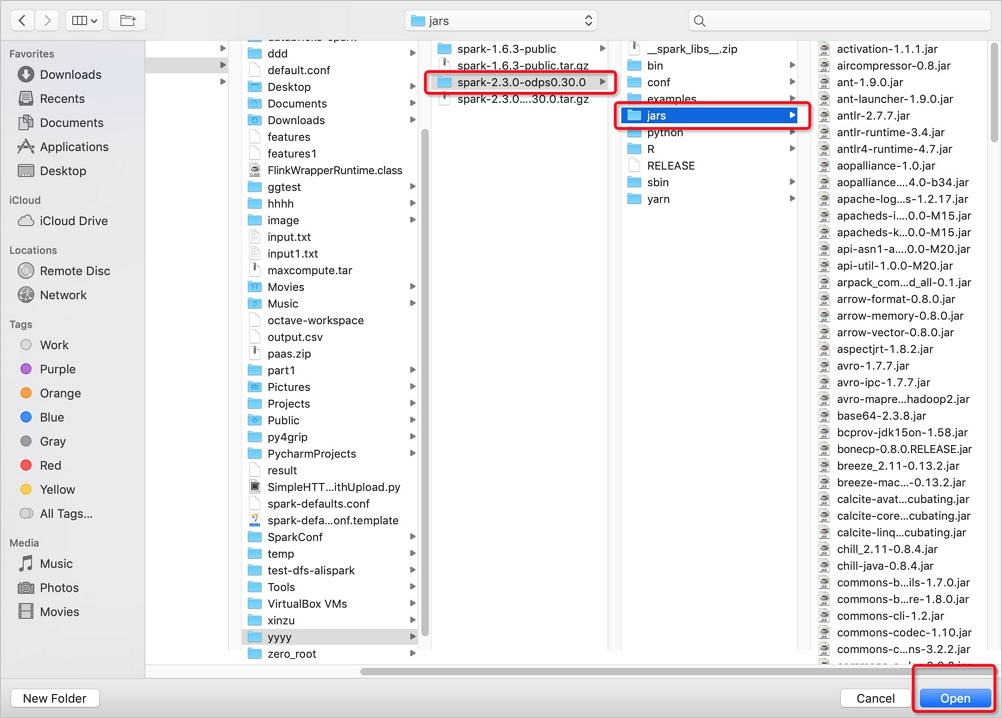
Click OK.
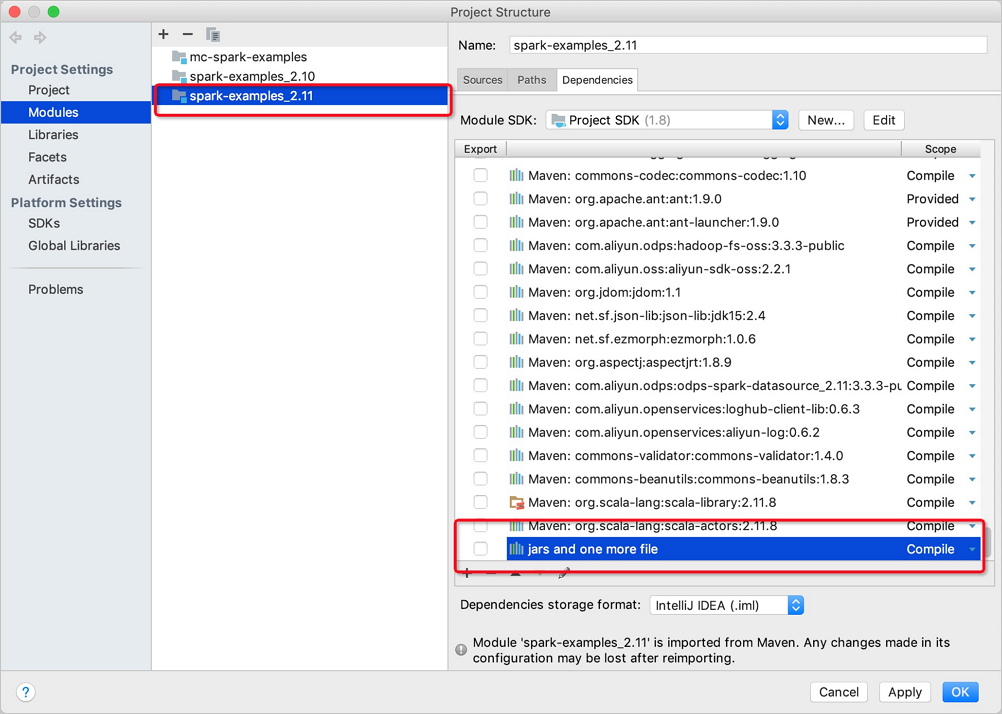
Submit the configurations in IntelliJ IDEA.
Cluster mode
In cluster mode, you must specify the Main method as the entry point of a custom application. A Spark job ends when Main succeeds or fails. This mode is suitable for offline jobs. You can use Spark on MaxCompute in this mode together with DataWorks to schedule jobs. The following code provides an example on how to use command lines to run Spark on MaxCompute in this mode:
# /path/to/MaxCompute-Spark: the path where the compiled application JAR package is saved.
cd $SPARK_HOME
bin/spark-submit --master yarn-cluster --class com.aliyun.odps.spark.examples.SparkPi \
/path/to/MaxCompute-Spark/spark-2.x/target/spark-examples_2.11-1.0.0-SNAPSHOT-shaded.jarDataWorks mode
You can run the offline jobs of Spark on MaxCompute in cluster mode in DataWorks to integrate and schedule the other types of nodes.
Perform the following steps:
Upload the required resources in a DataWorks workflow and click the Submit icon.
In the created workflow, select ODPS Spark from Data Analytics.
Double-click the ODPS Spark node in the workflow and configure the parameters for the Spark job. For the ODPS Spark node, the Spark Version parameter has three options, and the Language parameter has two options. The other parameters that you need to configure vary based on the Language parameter. You can configure the parameters as prompted. For more information, see Develop a MaxCompute Spark task. Where:
Main JAR Resource: the resource file used by the job. You must upload the resource file to DataWorks before you perform this operation.
Configuration Items: the configuration items required to submit the job.
You do not need to configure
spark.hadoop.odps.access.id,spark.hadoop.odps.access.key, andspark.hadoop.odps.end.point. By default, the values of these configuration items are the same as those of the MaxCompute project. You can also explicitly specify these configuration items to overwrite their default values.You must add the configurations in the
spark-defaults.conffile to the configuration items of the ODPS Spark node one by one. The configurations include the number of executors, memory size, andspark.hadoop.odps.runtime.end.point.The resource file and configuration items of the ODPS Spark node map the parameters and items of the spark-submit command, as described in the following table. You do not need to upload the spark-defaults.conf file. Instead, you must add the configurations in the spark-defaults.conf file to the configuration items of the ODPS Spark node one by one.
ODPS Spark node
spark-submit
Main JAR Resource and Main Python Resource
app jar or python fileConfiguration Items
--conf PROP=VALUEMain Class
--class CLASS_NAMEArguments
[app arguments]JAR Resources
--jars JARSPython Resources
--py-files PY_FILESFile Resources
--files FILESArchive Resources
--archives ARCHIVES
Run the ODPS Spark node to view the operational logs of the job and obtain the URLs of both Logview and Jobview from the logs for further analysis and diagnosis.
After the Spark job is defined, you can orchestrate and schedule services of different types in the workflow.