This document describes how to use the MaxFrame AI Function in Alibaba Cloud MaxCompute and provides typical use cases to help you get started with large language model (LLM) offline inference applications.
Overview
MaxFrame AI Function is an end-to-end solution for large language model (LLM) offline inference on the Alibaba Cloud MaxCompute platform. It seamlessly integrates data processing with AI capabilities to lower the barrier to enterprise-level LLM adoption.
Design philosophy: "Data in, results out." This allows you to use the MaxFrame Python framework and pandas-style APIs to complete the entire workflow—from data preparation and processing to model inference and result storage—all within the MaxCompute ecosystem.
Applicable scenarios: MaxFrame AI Function is ideal for processing massive volumes of structured data (such as log analysis and user behavior logs), unstructured data (such as text translation and document summarization), and for vectorization. It supports processing petabyte-scale data in a single job and achieves low latency and linear scalability through its distributed computing architecture. You can use it to extract structured information from text, summarize content, generate abstracts, translate languages, and perform tasks such as text quality assessment and sentiment classification. This significantly simplifies LLM data processing and improves result quality.
Architecture
MaxFrame AI Function provides a flexible, general-purpose
generateinterface and concise, scenario-basedtaskinterfaces (for translation, structured data extraction, embedding, etc.). You select a model and provide a MaxCompute table and prompts as input.When an interface is executed, MaxFrame first splits the table data. You can set an appropriate concurrency level based on the data size and start a group of workers to perform the computation. Each worker uses the provided prompt template to render prompts from the input data rows, runs inference, and writes the results, including the success status, back to MaxCompute.
The overall architecture and workflow are shown in the following figure:
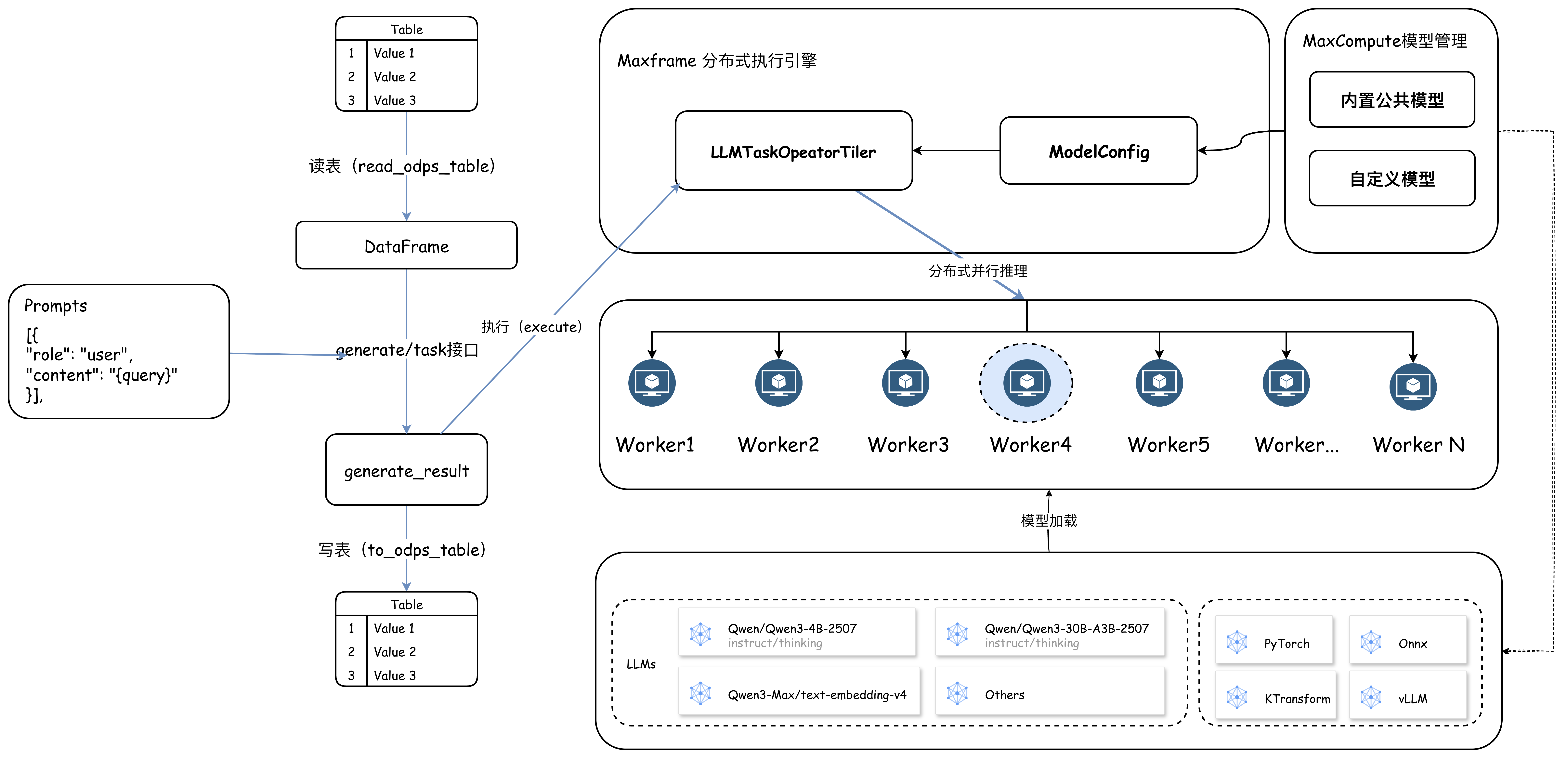
Key advantages:
Ease of use: Familiar Python APIs, an out-of-the-box model library, and zero deployment cost.
Scalability: Leverages MaxCompute CU (Compute Unit), GU (GPU Unit), and Inference Quota (token-based) resources to support large-scale parallel processing and improve overall token throughput.
Data + AI integration: Complete the entire workflow—from data reading and processing to AI inference and result storage—on a single platform. This reduces data migration costs and improves development efficiency.
Broad scenario coverage: Covers more than 10 common scenarios, including translation, structured data extraction, and vectorization.
Prerequisites
Supported regions:
China (Hangzhou), China (Shanghai), China (Beijing), China (Ulanqab), China (Shenzhen), China (Chengdu), China (Hong Kong), China (Hangzhou) Finance Cloud, and China (Shanghai) Finance Cloud.
Supported Python version: Python 3.11.
Supported SDK version: Ensure that your MaxFrame SDK version is 2.7.1 or later. You can check the version by running the following command:
// For Windows pip list | findstr maxframe // For Linux pip list | grep maxframeIf your version is outdated, run
pip install --upgrade maxframeto upgrade to the latest version.Install the latest MaxFrame client.
Supported models
Currently, MaxFrame provides out-of-the-box support for a series of built-in large language models (LLMs), such as Qwen 3, Deepseek-R1-Distill-Qwen, and Qwen3-embedding. It also supports calling commercial LLMs from Model Studio (Bailian), such as qwen3.7-max, qwen3.6-plus, qwen3.6-flash, deepseek-v4-pro, deepseek-v4-flash, qwen3-vl-embedding, and text-embedding-v4, covering both multimodal and text-based commercial flagship models. All models are hosted offline within the MaxCompute platform. This means you do not need to worry about model downloads, distribution, or API call concurrency limits. You can use the models by making simple API calls, allowing you to fully leverage the massive computing resources of MaxCompute to complete LLM offline inference tasks with high overall token throughput and concurrency.
Model catalog
Model series | Model name | Applicable quota |
Model Studio (Bailian) commercial models |
|
|
Qwen 3 series models |
|
|
Qwen3 Embedding models |
|
|
DeepSeek-R1-Distill-Qwen series models |
|
|
DeepSeek-R1-0528-Qwen3-8B |
|
|
Quota resource types
MaxFrame supports three types of resources, allowing you to choose the best fit for your model size and business requirements.
CU quota resources
A CU (1 CU = 1 vCPU + 4 GB memory) provides general-purpose CPU computing resources and is suitable for small models and inference tasks with small data volumes.
Configuration:
# Use CU Quota compute resources
options.session.quota_name = "mf_cpu_quota"GU quota resources
A GU provides GPU computing resources optimized for LLM inference. It supports larger models and is suitable for inference tasks with models of 8B parameters or more.
Configuration:
# Use GU Quota compute resources
options.session.gu_quota_name = "mf_gpu_quota"Inference quota resources (token-based billing)
This option allows you to call commercial LLMs directly from Model Studio (Bailian), such as qwen3-max and text-embedding-v4. Billing is based on actual token consumption. This approach eliminates the need to provision CU/GU resources or manage the underlying infrastructure, offering a flexible, convenient, and cost-effective solution.
Configuration:
# Use Inference Quota compute resources
options.session.inference_quota_name = "mf_token_quota"API reference
MaxFrame AI Function provides two types of interfaces to balance flexibility with ease of use: a general-purpose generate interface and scenario-based Task interfaces.
General-purpose: generate
The generate interface
Key parameters
Parameter | Required | Description |
model_name | Yes | The name of the model to use. |
df | Yes | The text or data to be analyzed, encapsulated in a DataFrame. |
prompt_template | Yes | A list of messages compatible with the OpenAI chat message format. You can use |
Task-specific: Task
Scenario-specific interface: Task
Preset, standardized task interfaces simplify development for common scenarios. Currently supported task interfaces include translate, extract, and embedding.
Key parameters
Parameter
Required
Description
model_name
Yes
The name of the model to use.
df
Yes
The text or data to be analyzed, encapsulated in a DataFrame.
Task-specific method
Yes
translate: text translationextract: structured data extractionembed: vectorization
Usage example
from maxframe.learn.contrib.llm.models.managed import ManagedTextLLM llm = ManagedTextLLM(name="<model_name>") # Text translation translated_df = llm.translate( df["english_column"], source_language="english", target_language="Chinese", examples=[("Hello", "你好"), ("Goodbye", "再见")], ) translated_df.execute()
Typical use cases
GU quota
GU quota scenarios
Language translation
Scenario: A multinational corporation needs to translate 100,000 English contracts into Chinese and annotate key clauses.
import os
import maxframe.dataframe as md
from maxframe import new_session
from maxframe.config import options
from maxframe.udf import with_running_options
from odps import ODPS
options.dag.settings = {
"engine_order": ["DPE", "MCSQL"]
}
o = ODPS(
os.getenv('ALIBABA_CLOUD_ACCESS_KEY_ID'),
os.getenv('ALIBABA_CLOUD_ACCESS_KEY_SECRET'),
project='your-default-project',
endpoint='your-end-point',
)
# Initialize the MaxFrame session
session = new_session(o)
# Print the Logview URL for the job
print(session.get_logview_address())
# 1. Use GU Quota compute resources
options.session.gu_quota_name = "mf_gu_quota"
# 2. Use the Qwen3-1.7B model
from maxframe.learn.contrib.llm.models.managed import ManagedTextLLM
llm = ManagedTextLLM(name="Qwen3-1.7B")
# 3. Prepare the data. You can skip this step if you already have data.
# o.execute_sql("""
# CREATE TABLE IF NOT EXISTS raw_contracts (
# en STRING
# );
# """)
#
# o.execute_sql("""
# INSERT INTO raw_contracts VALUES
# ('This agreement is governed by the laws of the State of California.'),
# ('The tenant shall pay rent on the first day of each month.'),
# ('Either party may terminate this contract with 30 days written notice.'),
# ('All intellectual property rights shall remain with the original owner.'),
# ('The warranty period for this product is twelve months from the date of purchase.');
# """)
df = md.read_odps_table("raw_contracts")
# 4. Define the prompt template
messages = [
{
"role": "system",
"content": "You are a document translation expert who can fluently translate the user's English text into Chinese.",
},
{
"role": "user",
"content": "Please translate the following English text into Chinese. Output only the translated text, with no other content.\n\n Example:\nInput: Hi\nOutput: 你好。\n\n Text to translate:\n\n{en}",
},
]
# 5. Call the `generate` interface, define the prompt, and reference the corresponding data column.
result_df = llm.generate(
df,
prompt_template=messages,
params={
"temperature": 0.7,
"top_p": 0.8,
},
).execute()
# 6. Write the results to a MaxCompute table
result_df.to_odps_table("raw_contracts_result")Keyword extraction
Scenario: This use case demonstrates how MaxFrame AI Function processes unstructured data. A large portion of unstructured data consists of text and images, which pose significant challenges for big data analytics. The following example shows how to use AI Function to simplify this process.
The following code demonstrates how to use AI Function to extract a candidate's work experience from resumes. The example uses randomly generated resume text for the input data. For detailed best practices and demos, see AI Function on GU Development Practices.
import maxframe.dataframe as md
from maxframe import new_session
from maxframe.config import options
from maxframe.udf import with_running_options
from odps import ODPS
options.dag.settings = {
"engine_order": ["DPE", "MCSQL"]
}
o = ODPS(
os.getenv('ALIBABA_CLOUD_ACCESS_KEY_ID'),
os.getenv('ALIBABA_CLOUD_ACCESS_KEY_SECRET'),
project='your-default-project',
endpoint='your-end-point',
)
# Initialize the MaxFrame session
session = new_session(o)
# Print the Logview URL for the job
print(session.get_logview_address())
# 1. Use GU Quota compute resources
options.session.gu_quota_name = "mf_gu_quota"
# 2. Use the Qwen3 4B model
from maxframe.learn.contrib.llm.models.managed import ManagedTextLLM
llm = ManagedTextLLM(name="Qwen3-4B-Instruct-2507-FP8")
df = md.read_odps_table("traditional_chinese_medicine", index_col="index")
# Specify four concurrent partitions
parallel_partitions = 4
df = df.mf.rebalance(num_partitions=parallel_partitions)
# 3. Use the preset `extract` task interface
result_df = llm.extract(
df["text"],
description="Please extract structured data from the following medical record in order. Return the final output in strict JSON format according to the schema.",
schema=MedicalRecord,
examples=[(example_input, example_output)],
)
result_df.execute()
Inference Quota resource scenarios (Token-based billing)
Inference Quota resource scenarios
Text vectorization: text-embedding-v4
Scenario description: Use the Model Studio (Bailian) commercial model text-embedding-v4 to perform vectorization tasks. Billing is based on token consumption, which eliminates the need to manage underlying computing resources. This scenario is suitable for complex text analysis and high-quality inference tasks that require large models or commercial large language models (LLMs) from Model Studio (Bailian).
VL multimodal image understanding: Qwen3.6-Plus
Scenario description: This scenario is suitable for high-quality inference and complex text analysis or multimodal data processing tasks that require large models or commercial LLMs from Model Studio (Bailian). Resources are consumed on demand, keeping costs controllable.
Performance optimization
Parallel inference
MaxFrame uses parallel computing for large-scale offline inference:
Data sharding: The
rebalanceAPI distributes the input data table evenly across multiple worker nodes based on a specified number of partitions (num_partitions).Parallel model loading: Each worker loads and pre-warms the model independently. This avoids the cold start latency caused by model loading.
Result aggregation: Output results are written to a MaxCompute table by partition. This supports later data analysis.
Common performance tuning recommendations
Switching heterogeneous computing resources
CPU inference is inefficient for large models, such as 8B and larger models. Switch to GU Quota or Token Quota computing resources for inference.
Parallel processing of data partitions
For large-scale offline inference jobs, use the
rebalanceAPI to shard data for parallel processing.