PyODPS FAQ
This topic answers frequently asked questions (FAQs) about PyODPS.
Error during installation: "Warning: XXX not installed"
Cause: This error indicates that a required component is missing.
Solution: Identify the name of the missing component from the XXX placeholder in the error message and install it by using the pip command.
Error during installation: "Project Not Found"
This error occurs for one of the following reasons:
Incorrect endpoint configuration: The endpoint is configured incorrectly. Use the endpoint for the destination project. For more information about endpoints, see Endpoints.
Incorrect parameter position: The parameters for the MaxCompute entry object are specified in the wrong positions. Verify that the parameters are entered correctly. For more information about the parameters for a MaxCompute entry object, see Migrate PyODPS nodes from DataWorks to an on-premises environment.
Error during installation: "Syntax Error"
This error occurs because the Python version is too old. PyODPS requires Python 2.6, 2.7.6 or later, or 3.3 or later. Python 2.5 and earlier versions are not supported.
Installation error on macOS: "Permission Denied"
Run the following command to install PyODPS: sudo pip install pyodps.
Installation error on macOS: "Operation Not Permitted"
This error is caused by System Integrity Protection (SIP). To fix this, restart your device and press ⌘+R during startup to enter Recovery Mode. Then, open the Terminal and run the following commands.
csrutil disable
reboot For more information, see Operation Not Permitted when on root - El Capitan (rootless disabled).
Import error: "No Module Named ODPS"
This error indicates that the ODPS package cannot be loaded. Possible causes include:
Cause 1: Name conflict in the search path
The search path, which is typically the current directory, contains a file named
odps.pyorinit.py, or a directory named odps. This conflicts with the installed PyODPS package.
Solution:If there is a directory with a conflicting name, rename it.
If you previously installed a different Python package named odps, uninstall it by running
sudo pip uninstall odps.
Cause 2: Multiple Python versions are installed
You may be running your script in a Python environment where PyODPS is not installed.
Solution: Ensure that you are using the correct Python interpreter where PyODPS is installed, or install PyODPS for the version you are currently using.Cause 3: PyODPS is not installed
The package was never installed in the current Python environment.
Solution: Install PyODPS. For more information, see Install PyODPS.
Import error: "Cannot Import Name ODPS"
Check if a file named odps.py exists in your current working directory. If it does, rename it before running the import statement again.
Import error: "Cannot Import Module odps"
This error usually indicates a dependency issue with your PyODPS installation. Click this link to join the PyODPS technical support DingTalk group and contact the group administrator for assistance.
"ImportError" in IPython or Jupyter
Try adding from odps import errors to the beginning of your code. If the problem persists, it may be due to a missing IPython dependency. Run sudo pip install -U jupyter to resolve the issue.
The size attribute
The size attribute represents the physical size of the table.
How to set a Tunnel endpoint?
Use options.tunnel.endpoint to set the tunnel endpoint. For more information, see the aliyun-odps-python-sdk options documentation.
Use CPython third-party packages
We recommend packaging them in the Wheel format. For more information, see How to create a crcmod package that can be used in MaxCompute.
Data processing limit of DataFrame
A PyODPS DataFrame has no limit on the data it can process because operations are translated into MaxCompute jobs. However, a local pandas DataFrame is limited by your machine's available memory.
How to use max_pt in a DataFrame?
Use the odps.df.func module to call MaxCompute built-in functions.
from odps.df import func
df = o.get_table('your_table').to_df()
df[df.ds == func.max_pt('your_project.your_table')] # ds is a partition column. What is the difference between open_writer() and write_table()?
Each time you call write_table(), MaxCompute creates a new file on the server, which has significant time overhead. Creating too many small files can also degrade the performance of subsequent queries and may lead to out-of-memory errors on the server. Therefore, when you use the write_table() method, we recommend writing multiple batches of data at once or passing a generator object. For an example of how to use the write_table() method, see Write data to a table.
By contrast, open_writer() creates a session that allows you to write data in blocks, which is more efficient for streaming or iterative data uploads.
Data discrepancy between DataWorks and local script
By default, Instance Tunnel is disabled on DataWorks. This means that instance.open_reader uses the Result API, which is limited to 10,000 records.
After you enable Instance Tunnel, you can use reader.count to get the total number of records. To iterate through all the data, you must disable the limit by setting options.tunnel.limit_instance_tunnel = False.
How to get the actual count from a DataFrame?
After you install PyODPS, run the following command in your Python environment to create a DataFrame from a MaxCompute table.
iris = DataFrame(o.get_table('pyodps_iris'))Call the
count()method on the DataFrame to get the total number of rows.iris.count()Operations on a DataFrame are lazily executed. They do not run until you explicitly call an action method like
execute(). To force thecount()operation to run immediately, chain it with theexecute()method.df.count().execute()
For more information about methods that return actual values, see Aggregate operations. For more information about lazy execution in PyODPS, see Execution.
"sourceIP is not in the white list" error
This error indicates that the MaxCompute project you are trying to access is protected by an IP whitelist. Contact the project owner to add your machine's IP address to the project's IP whitelist. For more information, see Manage an IP whitelist.
options.sql.settings fails to set environment
Symptom
Before you run a SQL query by using PyODPS, you use the following code to configure the MaxCompute runtime environment.
from odps import options options.sql.settings = {'odps.sql.mapper.split.size': 32}After you run the task, only six mappers are started, which indicates that the setting did not take effect. When you run
set odps.stage.mapper.split.size=32in the client, the task completes within a minute.Cause
The parameter name used in PyODPS is different from the one used in the client. The client parameter is
odps.stage.mapper.split.size, while the PyODPS parameter isodps.sql.mapper.split.size.Solution
Change the parameter name in your code to
odps.stage.mapper.split.size.
"IndexError" when calling head()
Because list[index] does not exist or list[index] is out of range.
Error when uploading a pandas DataFrame to MaxCompute: "ODPSError"
Symptom
When you upload a pandas DataFrame to MaxCompute, the following error is returned.
ODPSError: ODPS entrance should be provided.Cause
A global MaxCompute object entry point is missing.
Solution
Use the Room mechanism
%enter, which configures a global entry point.Call the
to_global()method on your MaxCompute object entry point.Pass the ODPS object directly as a parameter:
DataFrame(pd_df).persist('your_table', odps=odps).
"lifecycle is not specified" error
Symptom
When you write data to a table by using a DataFrame, the following error is returned.
table lifecycle is not specified in mandatory modeCause
The destination project requires that a lifecycle is specified for all tables, but you have not specified one.
Solution
Specify the table lifecycle in your script before you perform the write operation.
from odps import options options.lifecycle = 7 # Specify the lifecycle value. The value is an integer in days.
"datastream from server is crushed" error
This error is typically caused by dirty data. Verify that your data has the same number of columns as the destination table.
"Project is protected" error
This error indicates that a security policy on the project prevents you from reading data from the table. To access the full dataset, you can use one of the following methods:
Contact the project owner to add an exception rule for your access.
Use DataWorks or another tool to desensitize the data, export it to a non-protected project, and then read it from there.
If you only need to view a subset of the data, you can use one of the following methods, which may be subject to a 10,000-record limit:
Use the execute_sql method:
o.execute_sql('select * from <table_name>').open_reader().Convert the table to a DataFrame:
o.get_table('<table_name>').to_df().
Intermittent "ConnectionError: timed out" failure
This error can have the following causes:
Connection timeout: The default connection timeout for PyODPS is 5 seconds. If the network is unstable, the connection may fail. You can use one of the following solutions:
Increase the timeout interval by adding the following code to the beginning of your script.
# Workaround to increase timeout from odps import options options.connect_timeout = 30Implement a retry mechanism in your code to handle the exception.
Sandbox restrictions: Sandbox environments may have network access restrictions. To resolve this, we recommend that you use an exclusive scheduling resource group to run the task.
"is not defined" error for get_sql_task_cost()
Symptom
When you run the get_sql_task_cost function, the following error is returned.
NameError: name 'get_task_cost' is not defined.Cause
The function name is incorrect.
Solution
Use execute_sql_cost instead of get_sql_task_cost.
How to display Chinese characters correctly in PyODPS logs?
You can resolve this by using a print format string, for example, print ("My name is %s" % ('abc')). This issue typically occurs only in Python 2.
DATETIME becomes STRING when instance tunnel is disabled
When Open_Reader is called, PyODPS uses the legacy Result interface by default. As a result, the data returned from the server is in CSV format, and all DATETIME values are of the STRING type.
To resolve this, enable Instance Tunnel by setting options.tunnel.use_instance_tunnel = True. This makes PyODPS use the Instance Tunnel service, which preserves the original data types.
Implement advanced features with Python
Write reusable Python functions
You can define a series of functions for common calculations, such as calculating the distance between two points by using different methods like Euclidean or Manhattan distance. You can then call the appropriate function as needed.
def euclidean_distance(from_x, from_y, to_x, to_y): return ((from_x - to_x) ** 2 + (from_y - to_y) ** 2).sqrt() def manhattan_distance(from_x, from_y, to_x, to_y): return (from_x - to_x).abs() + (from_y - to_y).abs()Example call:
In [42]: df from_x from_y to_x to_y 0 0.393094 0.427736 0.463035 0.105007 1 0.629571 0.364047 0.972390 0.081533 2 0.460626 0.530383 0.443177 0.706774 3 0.647776 0.192169 0.244621 0.447979 4 0.846044 0.153819 0.873813 0.257627 5 0.702269 0.363977 0.440960 0.639756 6 0.596976 0.978124 0.669283 0.936233 7 0.376831 0.461660 0.707208 0.216863 8 0.632239 0.519418 0.881574 0.972641 9 0.071466 0.294414 0.012949 0.368514 In [43]: euclidean_distance(df.from_x, df.from_y, df.to_x, df.to_y).rename('distance') distance 0 0.330221 1 0.444229 2 0.177253 3 0.477465 4 0.107458 5 0.379916 6 0.083565 7 0.411187 8 0.517280 9 0.094420 In [44]: manhattan_distance(df.from_x, df.from_y, df.to_x, df.to_y).rename('distance') distance 0 0.392670 1 0.625334 2 0.193841 3 0.658966 4 0.131577 5 0.537088 6 0.114198 7 0.575175 8 0.702558 9 0.132617Use Python's conditional and loop statements
If you need to process table fields based on a configuration and then perform a UNION or JOIN operation across all tables, using SQL can be complex. However, this is straightforward with a PyODPS DataFrame.
For example, to combine 30 tables into a single table, you would need to write a SQL query with 30 UNION ALL clauses. With PyODPS, you can achieve the same result with the following code.
table_names = ['table1', ..., 'tableN'] dfs = [o.get_table(tn).to_df() for tn in table_names] reduce(lambda x, y: x.union(y), dfs) # The reduce statement is equivalent to the following code. df = dfs[0] for other_df in dfs[1:]: df = df.union(other_df)
How to debug locally by using the pandas backend?
You can perform local debugging in one of the following two ways. The initialization method is different, but the subsequent code is the same:
A PyODPS DataFrame created from a pandas DataFrame can perform local computations by using pandas.
A DataFrame created from a MaxCompute table runs on MaxCompute.
The following sample code shows how to switch between local debugging and full execution on MaxCompute.
df = o.get_table('movielens_ratings').to_df()
DEBUG = True
if DEBUG:
# Use a small subset of data for local debugging
df = df[:100].to_pandas(wrap=True) When you finish writing your code, you can test it locally with high speed. After testing is complete, change the DEBUG value to False to run the full computation on MaxCompute.
We recommend using MaxCompute Studio to debug local PyODPS programs.
How to avoid slow execution in nested loops?
To optimize performance, we recommend collecting the loop results in a Python dict or list and then creating the DataFrame object outside the loop. If you place the DataFrame creation code such as df=XXX inside the outer loop, a new DataFrame object is generated in each iteration, which significantly slows down the overall execution speed.
How to avoid downloading data to your local machine?
For more information, see Use a PyODPS node to avoid downloading data to a local machine.
When to download data for local processing
You can download PyODPS data for local processing in the following scenarios:
The amount of data is small and can fit into your local machine's memory.
You need to perform row-by-row operations that expand one row into multiple rows, or apply a complex Python function to each row. A PyODPS DataFrame can handle this efficiently by leveraging the parallel computing capabilities of MaxCompute.
For example, if you have a column containing JSON strings and you want to expand each JSON object into multiple rows based on its key-value pairs, you can use the following code.
In [12]: df json 0 {"a": 1, "b": 2} 1 {"c": 4, "b": 3} In [14]: from odps.df import output In [16]: @output(['k', 'v'], ['string', 'int']) ...: def h(row): ...: import json ...: for k, v in json.loads(row.json).items(): ...: yield k, v ...: In [21]: df.apply(h, axis=1) k v 0 a 1 1 b 2 2 c 4 3 b 3
How to retrieve more than 10,000 records with open_reader?
Use CREATE TABLE ... AS SELECT ... to save the result of a SQL query to a new table, and then use table.open_reader to read the full data from that table.
Built-in operators vs. UDFs
A user-defined function (UDF) is much slower than a built-in operator. Therefore, use a built-in operator whenever possible.
In a test on a one-million-row dataset, applying a UDF to each row increased execution time from 7 to 27 seconds.
Empty partition value from DataFrame schema
This occurs because a DataFrame treats partition columns and regular columns the same way. As a result, schema.partitions on a DataFrame object does not provide information about the underlying table's partition columns. You can filter the data by using the partition column as a regular column.
df = o.get_table('your_table').to_df()
print(df[df.ds == 'your_partition_value'].execute())To work with partition metadata, we recommend using the methods provided by the table object. For more information, see Tables.
How to perform a Cartesian product with a PyODPS DataFrame?
For more information, see How to handle a Cartesian product in a PyODPS DataFrame.
How to implement Jieba Chinese word segmentation in PyODPS?
For more information, see Use a PyODPS node to perform Chinese word segmentation with Jieba.
How to download full datasets by using PyODPS?
By default, PyODPS does not limit the amount of data read from an Instance. However, for protected MaxCompute projects, data downloads through Tunnel are restricted. In this case, if options.tunnel.limit_instance_tunnel is not set, a data size limit is automatically enabled. The number of downloadable records is then limited by the MaxCompute configuration, which is typically 10,000 records. If you need to iteratively retrieve all data, you must disable the limit. You can use the following statement to globally enable Instance Tunnel and disable the limit.
options.tunnel.use_instance_tunnel = True
options.tunnel.limit_instance_tunnel = False # Disable the limit to read all data.
with instance.open_reader() as reader:
# You can read the full dataset through the Instance Tunnel.execute_sql vs. DataFrame for null rate calculation
A DataFrame provides better performance for aggregations. We recommend using a DataFrame to perform aggregation operations.
How to configure data types in PyODPS?
If you use PyODPS, you can use one of the following methods to enable new data types:
To enable new data types by using the
execute_sqlmethod, runo.execute_sql('set odps.sql.type.system.odps2=true;query_sql', hints={"odps.sql.submit.mode" : "script"}).To enable new data types for DataFrame operations such as
persist,execute, orto_pandas, you can use thehintsparameter. The settings specified in this way are effective only for a single job.from odps.df import DataFrame users = DataFrame(o.get_table('odps2_test')) users.persist('copy_test',hints={'odps.sql.type.system.odps2':'true'})To enable the settings globally for all DataFrame operations, set the option parameter
options.sql.use_odps2_extension = True.
"ValueError" with Decimal type
You can resolve this issue in one of the following ways:
Upgrade the SDK to V0.8.4 or later.
Add the following statements to your code:
from odps.types import Decimal Decimal._max_precision=38
How to troubleshoot slow SQL execution in PyODPS?
PyODPS does not perform intensive operations before it submits a SQL task. In most cases, slow SQL execution is not related to PyODPS. You can follow these steps to identify the cause:
Check for network and server latency
Check for latency in the proxy server or network link that the task submission passes through.
Check for server-side issues, such as task queuing delays.
Evaluate data read efficiency
If your SQL execution involves reading a large amount of data, check whether the read speed is slow due to a large data volume or an excessive number of data shards. Perform the following steps:
You can try to separate the task submission from the data reading. To do this, submit the task by using run_sql, wait for the task to complete by using instance.wait_for_success, and then read the data by using instance.open_reader to determine the latency caused by each statement. The following is an example of this separation:
Before separation:
with o.execute_sql('select * from your_table').open_reader() as reader: for row in reader: print(row)After separation:
inst = o.run_sql('select * from your_table') inst.wait_for_success() with inst.open_reader() as reader: for row in reader: print(row)
Verify DataWorks job status (if applicable)
For jobs submitted in DataWorks, check for any SQL tasks that were submitted successfully but failed to generate a Logview, especially when the PyODPS version is lower than 0.11.6. These tasks are typically submitted by using the execute_sql or run_sql methods.
Analyze local environment factors
To determine whether the issue is related to your local environment, we recommend enabling debug logging. PyODPS prints all requests and responses, which allows you to identify the location of the delay.
Example:
import datetime import logging from odps import ODPS logging.basicConfig(level=logging.DEBUG, format='%(asctime)s - %(name)s - %(levelname)s - %(message)s') o = ODPS(...) # Enter your credentials here. Ignore this if a MaxCompute entry is already provided in the environment. # Print the local time to determine when the local operation was initiated. print("Check time:", datetime.datetime.now()) # Submit the task. inst = o.run_sql("select * from your_table")The standard output should be similar to the following result:
Check time: 2025-01-24 15:34:21.531330 2025-01-24 15:34:21,532 - odps.rest - DEBUG - Start request. 2025-01-24 15:34:21,532 - odps.rest - DEBUG - POST: http://service.<region>.maxcompute.aliyun.com/api/projects/<project>/instances 2025-01-24 15:34:21,532 - odps.rest - DEBUG - data: b'<?xml version="1.0" encoding="utf-8"?>\n<Instance>\n <Job>\n <Priority>9</Priority>\n <Tasks>\n <SQL>\n .... 2025-01-24 15:34:21,532 - odps.rest - DEBUG - headers: {'Content-Type': 'application/xml'} 2025-01-24 15:34:21,533 - odps.rest - DEBUG - request url + params /api/projects/<project>/instances?curr_project=<project> 2025-01-24 15:34:21,533 - odps.accounts - DEBUG - headers before signing: {'Content-Type': 'application/xml', 'User-Agent': 'pyodps/0.12.2 CPython/3.7.12', 'Content-Length': '736'} 2025-01-24 15:34:21,533 - odps.accounts - DEBUG - headers to sign: OrderedDict([('content-md5', ''), ('content-type', 'application/xml'), ('date', 'Fri, 24 Jan 2025 07:34:21 GMT')]) 2025-01-24 15:34:21,533 - odps.accounts - DEBUG - canonical string: POST application/xml Fri, 24 Jan 2025 07:34:21 GMT /projects/maxframe_ci_cd/instances?curr_project=maxframe_ci_cd 2025-01-24 15:34:21,533 - odps.accounts - DEBUG - headers after signing: {'Content-Type': 'application/xml', 'User-Agent': 'pyodps/0.12.2 CPython/3.7.12', 'Content-Length': '736', .... 2025-01-24 15:34:21,533 - urllib3.connectionpool - DEBUG - Resetting dropped connection: service.<region>.maxcompute.aliyun.com 2025-01-24 15:34:22,027 - urllib3.connectionpool - DEBUG - http://service.<region>.maxcompute.aliyun.com:80 "POST /api/projects/<project>/instances?curr_project=<project> HTTP/1.1" 201 0 2025-01-24 15:34:22,027 - odps.rest - DEBUG - response.status_code 201 2025-01-24 15:34:22,027 - odps.rest - DEBUG - response.headers: {'Server': '<Server>', 'Date': 'Fri, 24 Jan 2025 07:34:22 GMT', 'Content-Type': 'text/plain;charset=utf-8', 'Content-Length': '0', 'Connection': 'close', 'Location': .... 2025-01-24 15:34:22,027 - odps.rest - DEBUG - response.content: b''This output shows the time when the code initiates the task (2025-01-24 15:34:21.531), the time when the request is sent (2025-01-24 15:34:21.533), and the time when the server returns a response (2025-01-24 15:34:22.027). This allows you to determine the time cost of each stage.
How to get file count and last modified time of a MaxCompute table by using PyODPS?
Problem description
When running DESC EXTENDED table_name or DESC EXTENDED table_name PARTITION (xxx='xxx') through the MaxCompute client (odpscmd) or a DataWorks MaxCompute SQL node, the output includes detailed table metadata such as file count(file_num), physical size, and last modified time.
However, running DESC EXTENDED through the PyODPS run_sql() or execute_sql() method does not return complete extended information (such as the file_num field), making it impossible to extract key metrics in a structured way.

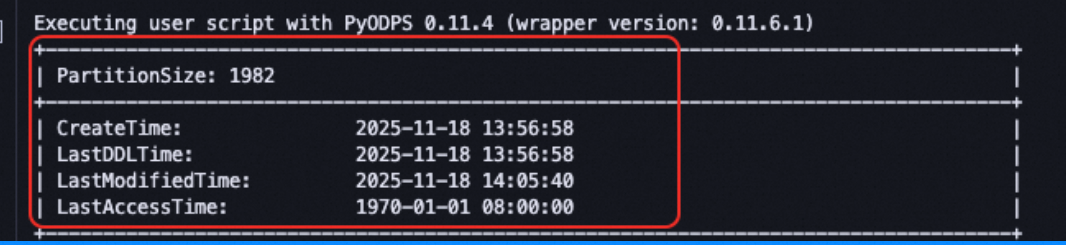
Solution
Use PyODPS native SDK interfaces such as table.reload_extend_info() or partition.reload() to obtain these statistics. Click the link to view the source code.
The following example shows how to obtain the file count of each partition:
from odps.models import Partition # Replace with the actual table name table_name = 'your_real_table_name' # ========== 1. Get the table object ========== try: # Assume that o is an initialized ODPS object # In a DataWorks PyODPS node, uncomment the following line # o = odps table = o.get_table(table_name) print(f"Table object obtained: {table_name}") except Exception as e: print(f"Error: Failed to obtain table '{table_name}'. Cause: {str(e)}") raise # ========== 2. Check whether the table is partitioned ========== if not table.table_schema.partitions: print(f"Table '{table_name}' is not a partitioned table. Partition query is not supported.") else: print(f"Table '{table_name}' is a partitioned table. Iterating over all partitions...") print("=" * 60) # ========== 3. Iterate over partitions by using table.partitions ========== partition_count = 0 try: for partition in table.partitions: try: part_spec = partition.spec if not part_spec: part_spec = 'Unknown partition' # partition.reload() loads detailed partition metadata # This triggers one or more API calls to MaxCompute Metastore partition.reload() print(f"Partition Spec: {part_spec}") print(f" - Creation Time : {partition.creation_time}") print(f" - Last Modified Time : {partition.last_data_modified_time}") print(f" - Physical Size : {partition.physical_size} bytes") print(f" - File Count : {partition.file_num}") print(f" - Is Archived : {partition.is_archived}") print("-" * 60) partition_count += 1 except Exception as e_inner: print(f"Warning: Failed to load details for partition {partition.spec or ''}. Cause: {str(e_inner)}") print("-" * 60) continue print(f"Iteration complete: {partition_count} partitions processed.") except Exception as e_outer: print(f"Fatal error during partition iteration. Cause: {str(e_outer)}")