Creates a materialized view that supports optional partitioning, clustering, and scheduled refresh.
Background information
A view is a stored query that runs against source tables every time you access it. A materialized view is a physical table that stores precomputed query results. It occupies real storage but delivers faster query performance by eliminating repeated JOIN and aggregate operations.
| Traditional query | Query with a materialized view | |
|---|---|---|
| Query statements | SQL queries run against source tables each time. | Query runs against the precomputed materialized view. If query rewrite is enabled, MaxCompute automatically redirects matching queries to the materialized view — no code changes required. |
| Query characteristics | Involves table scans, JOINs, and filters on every execution. Slow for large datasets. | Involves table scans and filters only. JOIN results are already stored. MaxCompute selects the most efficient materialized view automatically. |
When to use a materialized view
Materialized views are suitable for the following queries:
Queries that run in a fixed pattern and execute frequently.
Queries that involve time-consuming operations such as JOINs or aggregations.
Queries that read only a small portion of a large table.
If none of these conditions apply — for example, the query pattern changes often or the dataset is small — a regular view or direct query may be more appropriate.
Billing
Materialized views incur costs in two categories:
Storage
Materialized views occupy physical storage. Charges are based on the storage space used. For pricing details, see Storage pricing (pay-as-you-go).Materialized views occupy physical storage space. You are charged for the physical storage space that is occupied by materialized views. For more information about storage pricing, see Storage pricing (pay-as-you-go).
Computing
Computing costs apply when you create, refresh, or query a materialized view (including query rewrite operations when the view is valid).
Subscription projects: No extra computing costs are generated.
Pay-as-you-go projects: Fees are calculated based on SQL complexity and the amount of input data scanned. For details, see the "Billing for standard SQL jobs" section in Computing pricing.Computing pricing
Additional billing notes for pay-as-you-go projects:
Refreshes: The SQL used to refresh a materialized view is the same as the SQL used to create it. If the project is bound to a subscription resource group, no additional fees apply. If bound to a pay-as-you-go resource group, fees vary based on input data volume and SQL complexity. Storage fees apply after each refresh based on the storage space used.
Query rewrite (valid materialized view): Input data is read from the materialized view, not the source table. Costs depend on the size of the materialized view.
Query rewrite (invalid materialized view): Query rewrite cannot be performed. Data is read from the source table, and costs depend on the source table size.
Data bloat: When a materialized view is built from multiple joined tables, the stored result may be larger than the source tables. MaxCompute cannot guarantee that reading from a materialized view costs less than reading from source tables.
Limitations
The following are current limitations. Some may be relaxed or removed in future versions.
Unsupported functions:
Window functions are not supported.
User-defined table-valued functions (UDTFs) are not supported.
Non-deterministic functions — including user-defined functions (UDFs) and user-defined aggregate functions (UDAFs) — are not supported by default. To enable them, run the following command before executing your query:
set odps.sql.materialized.view.support.nondeterministic.function=true;
Usage notes:
If the query statement used to define the materialized view fails to execute, the materialized view cannot be created.
Partition key columns must be derived from a source table. The column sequence and count must match the source table exactly. Column names may differ.
Comments are required for all columns, including partition key columns. Specifying comments for only some columns returns an error.
You can specify both partitioning and clustering attributes for the same materialized view. In that case, each partition has the specified clustering attribute applied.
If the query statement references operators not supported for query rewrite, an error is returned when creating the materialized view. For supported operators, see Query rewrite.
If a source table contains an empty partition, refreshing the materialized view generates a corresponding empty partition in the materialized view.
Syntax
CREATE MATERIALIZED VIEW [IF NOT EXISTS] [project_name.]<mv_name>
[LIFECYCLE <days>] -- Lifecycle of the materialized view, in days.
[BUILD DEFERRED] -- Create schema only; do not populate data.
[(<col_name> [COMMENT <col_comment>], ...)] -- Column comments.
[DISABLE REWRITE] -- Disable query rewrite for this materialized view.
[COMMENT 'table_comment'] -- Comment for the materialized view.
[PARTITIONED BY (<col_name> [, <col_name>, ...])]
[CLUSTERED BY | RANGE CLUSTERED BY (<col_name> [, <col_name>, ...])
[SORTED BY (<col_name> [ASC | DESC] [, <col_name> [ASC | DESC] ...])]
INTO <number_of_buckets> BUCKETS]
[REFRESH EVERY <num> MINUTES | HOURS | DAYS]
[TBLPROPERTIES (
"compressionstrategy" = "normal | high | extreme",
"enable_auto_substitute" = "true", -- Fall through to source table when partition is missing.
"enable_auto_refresh" = "true", -- Enable scheduled refresh.
"refresh_interval_minutes" = "120", -- Refresh interval in minutes.
"only_refresh_max_pt" = "true" -- Refresh only the latest partition from the source table.
)]
AS <select_statement>;Parameters
| Parameter | Required | Description |
|---|---|---|
IF NOT EXISTS | No | Skips creation if the materialized view already exists. Without this clause, an error is returned if the view already exists. |
project_name | No | The MaxCompute project that owns the materialized view. Defaults to the current project. To find the project name, log on to the MaxCompute console, select a region, and check the Projects page. |
mv_name | Yes | Name of the materialized view to create. |
days | No | Lifecycle of the materialized view. Unit: days. Valid values: 1–37231. |
BUILD DEFERRED | No | Creates the schema only. Data is not populated at creation time. |
col_name | No | Column name in the materialized view. |
col_comment | No | Comment for the column. |
DISABLE REWRITE | No | Disables query rewrite for this materialized view. Query rewrite is enabled by default. To change this after creation, use ALTER MATERIALIZED VIEW [project_name.]<mv_name> DISABLE REWRITE or ENABLE REWRITE. |
PARTITIONED BY | No | Partition key columns for the materialized view. Required when creating a partitioned materialized view. |
CLUSTERED BY | RANGE CLUSTERED BY | No | Shuffle attribute of the materialized view. Required when creating a clustered materialized view. |
SORTED BY | No | Sort attribute within each bucket. Required when creating a clustered materialized view. |
REFRESH EVERY | No | Scheduled refresh interval. Units: MINUTES, HOURS, or DAYS. |
number_of_buckets | No | Number of buckets. Required when creating a clustered materialized view. |
select_statement | Yes | The SELECT statement that defines the materialized view. For syntax details, see SELECT syntax. |
TBLPROPERTIES sub-parameters:
| Sub-parameter | Required | Values | Description |
|---|---|---|---|
compressionstrategy | No | normal, high, extreme | Compression policy for stored data. |
enable_auto_substitute | No | true | false | When true, falls through to the source table for partitions not present in the materialized view. For details, see Query and rewrite for the materialized view. |
enable_auto_refresh | No | true | false | When true, the system automatically refreshes data on a schedule. |
refresh_interval_minutes | Conditional | Integer | Required when enable_auto_refresh is true. Refresh interval in minutes. |
only_refresh_max_pt | No | true | false | Valid for partitioned materialized views. When true, only the latest partition from the source table is refreshed into the materialized view. |
Examples
Create a materialized view
The following examples use two partitioned source tables: mf_t and mf_t1.
Step 1: Create the source tables and insert data.
CREATE TABLE IF NOT EXISTS mf_t(
id bigint,
value bigint,
name string)
PARTITIONED BY (ds STRING);
ALTER TABLE mf_t ADD PARTITION (ds='1');
INSERT INTO mf_t PARTITION (ds='1') VALUES (1,10,'kyle'), (2,20,'xia');
SELECT * FROM mf_t WHERE ds='1';
-- Result:
-- +------------+------------+------------+------------+
-- | id | value | name | ds |
-- +------------+------------+------------+------------+
-- | 1 | 10 | kyle | 1 |
-- | 2 | 20 | xia | 1 |
-- +------------+------------+------------+------------+
CREATE TABLE IF NOT EXISTS mf_t1(
id bigint,
value bigint,
name string)
PARTITIONED BY (ds STRING);
ALTER TABLE mf_t1 ADD PARTITION (ds='1');
INSERT INTO mf_t1 PARTITION (ds='1') VALUES (1,10,'kyle'), (3,20,'john');
SELECT * FROM mf_t1 WHERE ds='1';
-- Result:
-- +------------+------------+------------+------------+
-- | id | value | name | ds |
-- +------------+------------+------------+------------+
-- | 1 | 10 | kyle | 1 |
-- | 3 | 20 | john | 1 |
-- +------------+------------+------------+------------+Step 2: Create a materialized view. The following examples show three common configurations.
Example 1: Partitioned materialized view
Creates a materialized view with a partition key column ds, a 7-day lifecycle, and column comments.
CREATE MATERIALIZED VIEW mf_mv LIFECYCLE 7
(
key COMMENT 'unique id',
value COMMENT 'input value',
ds COMMENT 'partition'
)
PARTITIONED BY (ds)
AS SELECT t1.id AS key, t1.value AS value, t1.ds AS ds
FROM mf_t AS t1 JOIN mf_t1 AS t2
ON t1.id = t2.id AND t1.ds = t2.ds AND t1.ds = '1';
-- Query the materialized view:
SELECT * FROM mf_mv WHERE ds=1;
-- Result:
-- +------------+------------+------------+
-- | key | value | ds |
-- +------------+------------+------------+
-- | 1 | 10 | 1 |
-- +------------+------------+------------+Example 2: Non-partitioned clustered materialized view
CREATE MATERIALIZED VIEW mf_mv2 LIFECYCLE 7
CLUSTERED BY (key) SORTED BY (value) INTO 1024 BUCKETS
AS SELECT t1.id AS key, t1.value AS value, t1.ds AS ds
FROM mf_t AS t1 JOIN mf_t1 AS t2
ON t1.id = t2.id AND t1.ds = t2.ds AND t1.ds = '1';Example 3: Partitioned and clustered materialized view
Combines partitioning and clustering. Data within each partition is distributed into buckets.
CREATE MATERIALIZED VIEW mf_mv3 LIFECYCLE 7
PARTITIONED BY (ds)
CLUSTERED BY (key) SORTED BY (value) INTO 1024 BUCKETS
AS SELECT t1.id AS key, t1.value AS value, t1.ds AS ds
FROM mf_t AS t1 JOIN mf_t1 AS t2
ON t1.id = t2.id AND t1.ds = t2.ds AND t1.ds = '1';Use query rewrite to accelerate queries
This example uses a page access table visit_records that logs page_id, user_id, and visit_time. Traffic analysis queries that count visits per page run frequently.
Step 1: Create a materialized view that precomputes per-page visit counts.
CREATE MATERIALIZED VIEW count_mv
AS SELECT page_id, count(*) FROM visit_records GROUP BY page_id;Step 2: Enable query rewrite and run the original query.
SET odps.sql.materialized.view.enable.auto.rewriting=true;
SELECT page_id, count(*) FROM visit_records GROUP BY page_id;MaxCompute automatically matches the query to count_mv and reads aggregated results from it instead of scanning visit_records.
Step 3: Verify that the query is rewritten using EXPLAIN.
EXPLAIN SELECT page_id, count(*) FROM visit_records GROUP BY page_id;Expected output:
job0 is root job
In Job job0:
root Tasks: M1
In Task M1:
Data source: doc_test_dev.count_mv
TS: doc_test_dev.count_mv
FS: output: Screen
schema:
page_id (string)
_c1 (bigint)
OKThe Data source field confirms that the query reads from count_mv in the doc_test_dev project, not from the original visit_records table.
Configure refresh strategies
The three examples below demonstrate different ways to keep a materialized view current.
Manual refresh only (default)
No refresh clause is specified. Refresh the view explicitly using ALTER MATERIALIZED VIEW.
CREATE MATERIALIZED VIEW sales_mv
AS SELECT region, sum(amount) AS total FROM sales GROUP BY region;Scheduled refresh using `REFRESH EVERY`
Refreshes the view automatically every 2 hours.
CREATE MATERIALIZED VIEW sales_mv
REFRESH EVERY 2 HOURS
AS SELECT region, sum(amount) AS total FROM sales GROUP BY region;Scheduled refresh using `TBLPROPERTIES`
Sets a 120-minute refresh interval and automatically refreshes only the latest partition from the source table.
CREATE MATERIALIZED VIEW sales_mv LIFECYCLE 7
PARTITIONED BY (ds)
TBLPROPERTIES (
"enable_auto_refresh" = "true",
"refresh_interval_minutes" = "120",
"only_refresh_max_pt" = "true"
)
AS SELECT region, ds, sum(amount) AS total FROM sales GROUP BY region, ds;Query rewrite
Query rewrite automatically redirects queries to a matching materialized view, eliminating redundant computation on source tables. To enable query rewrite, prepend the following command to your query:
SET odps.sql.materialized.view.enable.auto.rewriting=true;If the materialized view is invalid, query rewrite cannot be performed and MaxCompute falls back to querying the source table.
By default, a project can only use its own materialized views for query rewrite. To allow query rewrite using materialized views from other projects, prepend the following command and specify the allowed projects:
SET odps.sql.materialized.view.source.project.white.list=<project_name1>,<project_name2>,<project_name3>;Supported operators for query rewrite
| Operator type | Classification | MaxCompute | BigQuery | Amazon Redshift | Hive |
|---|---|---|---|---|---|
| FILTER | Expression full match | Supported | Supported | Supported | Supported |
| FILTER | Expression partial match | Supported | Supported | Supported | Supported |
| AGGREGATE | Single aggregate | Supported | Supported | Supported | Supported |
| AGGREGATE | Multiple aggregates | Not supported | Not supported | Not supported | Not supported |
| JOIN | Join type | INNER JOIN | Not supported | INNER JOIN | INNER JOIN |
| JOIN | Single JOIN | Supported | Not supported | Supported | Supported |
| JOIN | Multiple JOINs | Supported | Not supported | Supported | Supported |
| AGGREGATE + JOIN | — | Supported | Not supported | Supported | Supported |
For query rewrite to succeed, all columns needed by the query — output columns, filter columns, aggregate function columns, and JOIN columns — must be present in the materialized view.
Rewrite queries with filter conditions
All examples in this section use the following materialized view:
CREATE MATERIALIZED VIEW mv AS SELECT a, b, c FROM src WHERE a > 5;| Original query | Rewritten query |
|---|---|
SELECT a, b FROM src WHERE a > 5; | SELECT a, b FROM mv; |
SELECT a, b FROM src WHERE a = 10; | SELECT a, b FROM mv WHERE a = 10; |
SELECT a, b FROM src WHERE a = 10 AND b = 3; | SELECT a, b FROM mv WHERE a = 10 AND b = 3; |
SELECT a, b FROM src WHERE a > 3; | (SELECT a, b FROM src WHERE a > 3 AND a <= 5) UNION (SELECT a, b FROM mv); |
SELECT a, b FROM src WHERE a = 10 AND d = 4; | Rewriting failed — mv does not have column d. |
SELECT d, e FROM src WHERE a = 10; | Rewriting failed — mv does not have columns d and e. |
SELECT a, b FROM src WHERE a = 1; | Rewriting failed — mv does not have data where a = 1. |
Rewrite queries with aggregate functions
When aggregation keys match the materialized view, rewriting is supported for all aggregate functions. When aggregation keys differ, only SUM, MIN, and MAX are supported.
All examples use:
CREATE MATERIALIZED VIEW mv AS
SELECT a, b, sum(c) AS sum, count(d) AS cnt FROM src GROUP BY a, b;| Original query | Rewritten query |
|---|---|
SELECT a, sum(c) FROM src GROUP BY a; | SELECT a, sum(sum) FROM mv GROUP BY a; |
SELECT a, count(d) FROM src GROUP BY a, b; | SELECT a, cnt FROM mv; |
SELECT a, count(b) FROM (SELECT a, b FROM src GROUP BY a, b) GROUP BY a; | SELECT a, count(b) FROM mv GROUP BY a; |
SELECT a, count(b) FROM mv GROUP BY a; | Rewriting failed — mv has already aggregated a and b; b cannot be aggregated again. |
SELECT a, count(c) FROM src GROUP BY a; | Rewriting failed — re-aggregation of COUNT is not supported. |
When `DISTINCT` is used, rewriting is supported only when aggregation keys match the materialized view exactly.
All examples use:
CREATE MATERIALIZED VIEW mv AS
SELECT a, b, sum(DISTINCT c) AS sum, count(DISTINCT d) AS cnt FROM src GROUP BY a, b;| Original query | Rewritten query |
|---|---|
SELECT a, count(DISTINCT d) FROM src GROUP BY a, b; | SELECT a, cnt FROM mv; |
SELECT a, count(c) FROM src GROUP BY a, b; | Rewriting failed — re-aggregation of COUNT is not supported. |
SELECT a, count(DISTINCT c) FROM src GROUP BY a; | Rewriting failed — additional aggregation on a is required. |
Rewrite queries with JOIN
Rewrite JOIN inputs
When a query's JOIN inputs match a materialized view's definition, MaxCompute replaces those inputs with the materialized view.
Create materialized views:
CREATE MATERIALIZED VIEW mv1 AS SELECT a, b FROM j1 WHERE b > 10;
CREATE MATERIALIZED VIEW mv2 AS SELECT a, b FROM j2 WHERE b > 10;| Original query | Rewritten query |
|---|---|
SELECT j1.a, j1.b, j2.a FROM (SELECT a, b FROM j1 WHERE b > 10) j1 JOIN j2 ON j1.a = j2.a; | SELECT mv1.a, mv1.b, j2.a FROM mv1 JOIN j2 ON mv1.a = j2.a; |
SELECT j1.a, j1.b, j2.a FROM (SELECT a, b FROM j1 WHERE b > 10) j1 JOIN (SELECT a, b FROM j2 WHERE b > 10) j2 ON j1.a = j2.a; | SELECT mv1.a, mv1.b, mv2.a FROM mv1 JOIN mv2 ON mv1.a = mv2.a; |
JOIN with filter conditions
Create materialized views:
-- Non-partitioned
CREATE MATERIALIZED VIEW mv1 AS SELECT j1.a, j1.b FROM j1 JOIN j2 ON j1.a = j2.a;
CREATE MATERIALIZED VIEW mv2 AS SELECT j1.a, j1.b FROM j1 JOIN j2 ON j1.a = j2.a WHERE j1.a > 10;
-- Partitioned
CREATE MATERIALIZED VIEW mv LIFECYCLE 7 PARTITIONED BY (ds)
AS SELECT t1.id, t1.ds AS ds FROM t1 JOIN t2 ON t1.id = t2.id;| Original query | Rewritten query |
|---|---|
SELECT j1.a, j1.b FROM j1 JOIN j2 ON j1.a = j2.a WHERE j1.a = 4; | SELECT a, b FROM mv1 WHERE a = 4; |
SELECT j1.a, j1.b FROM j1 JOIN j2 ON j1.a = j2.a WHERE j1.a > 20; | SELECT a, b FROM mv2 WHERE a > 20; |
SELECT j1.a, j1.b FROM j1 JOIN j2 ON j1.a = j2.a WHERE j1.a > 5; | (SELECT j1.a, j1.b FROM j1 JOIN j2 ON j1.a = j2.a WHERE j1.a > 5 AND j1.a <= 10) UNION SELECT * FROM mv2; |
SELECT key FROM t1 JOIN t2 ON t1.id = t2.id WHERE t1.ds = '20210306'; | SELECT key FROM mv WHERE ds = '20210306'; |
SELECT key FROM t1 JOIN t2 ON t1.id = t2.id WHERE t1.ds >= '20210306'; | SELECT key FROM mv WHERE ds >= '20210306'; |
SELECT j1.a, j1.b FROM j1 JOIN j2 ON j1.a = j2.a WHERE j2.a = 4; | Rewriting failed — mv does not have column j2.a. |
JOIN with additional tables
Create materialized view:
CREATE MATERIALIZED VIEW mv AS SELECT j1.a, j1.b FROM j1 JOIN j2 ON j1.a = j2.a;| Original query | Rewritten query |
|---|---|
SELECT j1.a, j1.b FROM j1 JOIN j2 JOIN j3 ON j1.a = j2.a AND j1.a = j3.a; | SELECT mv.a, mv.b FROM mv JOIN j3 ON mv.a = j3.a; |
SELECT j1.a, j1.b FROM j1 JOIN j2 JOIN j3 ON j1.a = j2.a AND j2.a = j3.a; | SELECT mv.a, mv.b FROM mv JOIN j3 ON mv.a = j3.a; |
The three JOIN rewrite types can be combined. If a query meets the conditions for multiple rewrite rules, MaxCompute selects the most efficient execution plan. If the rewritten plan does not outperform the original, the rewrite is not applied.
Rewrite queries with LEFT JOIN
Create materialized view:
CREATE MATERIALIZED VIEW mv LIFECYCLE 7 (
user_id,
job,
total_amount
)
AS SELECT t1.user_id, t1.job, sum(t2.order_amount) AS total_amount
FROM user_info AS t1 LEFT JOIN sale_order AS t2 ON t1.user_id = t2.user_id
GROUP BY t1.user_id;| Original query | Rewritten query |
|---|---|
SELECT t1.user_id, sum(t2.order_amount) AS total_amount FROM user_info AS t1 LEFT JOIN sale_order AS t2 ON t1.user_id = t2.user_id GROUP BY t1.user_id; | SELECT user_id, total_amount FROM mv; |
Rewrite queries with UNION ALL
Create materialized view:
CREATE MATERIALIZED VIEW mv LIFECYCLE 7 (
user_id,
tran_amount,
tran_date
)
AS SELECT user_id, tran_amount, tran_date FROM alipay_tran
UNION ALL
SELECT user_id, tran_amount, tran_date FROM unionpay_tran;| Original query | Rewritten query |
|---|---|
SELECT user_id, tran_amount FROM alipay_tran UNION ALL SELECT user_id, tran_amount FROM unionpay_tran; | SELECT user_id, tran_amount FROM mv; |
Penetration query
When a partitioned materialized view does not contain all partitions from its source table — for example, when only the latest partition is refreshed — queries for missing partitions fall through to the source table automatically. This is called a penetration query.
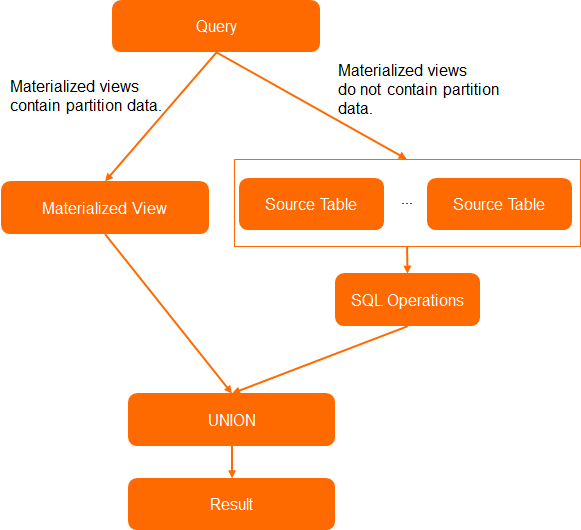
To enable penetration queries, set "enable_auto_substitute"="true" in TBLPROPERTIES when creating the materialized view.
The following example demonstrates how penetration queries work.
Step 1: Create a partitioned materialized view with penetration query enabled.
-- Create source table.
CREATE TABLE src (id bigint, name string) PARTITIONED BY (dt string);
-- Insert data into two partitions.
INSERT INTO src PARTITION(dt='20210101') VALUES (1, 'Alex');
INSERT INTO src PARTITION(dt='20210102') VALUES (2, 'Flink');
-- Create a partitioned materialized view with penetration query enabled.
CREATE MATERIALIZED VIEW IF NOT EXISTS mv LIFECYCLE 7
PARTITIONED BY (dt)
TBLPROPERTIES ("enable_auto_substitute" = "true")
AS SELECT id, name, dt FROM src;Step 2: Query the 20210101 partition. This partition exists in mv, so data is read from the materialized view.
SELECT * FROM mv WHERE dt = '20210101';Step 3: Query the 20210102 partition. This partition does not exist in mv, so a penetration query retrieves the data from src.
SELECT * FROM mv WHERE dt = '20210102';
-- Equivalent to:
SELECT * FROM (SELECT id, name, dt FROM src WHERE dt = '20210102') t;Step 4: Query a range of partitions spanning both available and missing data. MaxCompute performs a penetration query for the missing partitions and combines the results using UNION ALL.
SELECT * FROM mv WHERE dt >= '20201230' AND dt <= '20210102' AND id = '5';
-- Equivalent to:
SELECT * FROM (
SELECT id, name, dt FROM src WHERE dt = '20211231' OR dt = '20210102'
UNION ALL
SELECT * FROM mv WHERE dt = '20210101'
) t WHERE id = '5';What's next
ALTER MATERIALIZED VIEW: Refresh a materialized view, change its lifecycle, enable or disable the lifecycle feature, or drop partitions.
DESC TABLE/VIEW: View detailed information about a materialized view.
SELECT MATERIALIZED VIEW: Check the status of a materialized view.
DROP MATERIALIZED VIEW: Drop a materialized view.