This topic compares the data compression performance of Lindorm against open source HBase, MySQL, and MongoDB across four real-world datasets: orders, Internet of Vehicles (IoV), logs, and user behaviors.
Test environment
Lindorm is a multi-model hyper-converged database service that uses the zstd compression algorithm by default and supports dictionary-based compression, which improves the compression ratio by optimizing dictionary sampling during data encoding.
The following table shows the database versions and compression configurations used in this test.
| Database | Version | Default compression | Notes |
|---|---|---|---|
| Lindorm | Latest | zstd (optimized) | Dictionary-based compression available |
| Open source HBase | 2.3.4 | Snappy | zstd is supported with later Hadoop versions but prone to stability issues and core dumps; most deployments use Snappy |
| Open source MySQL | 8.0 | None (disabled) | zlib is available but significantly degrades query performance when enabled |
| Open source MongoDB | 5.0 | Snappy | zstd is available as an alternative |
This test follows only parts of the TPC benchmark specifications. Results are not equivalent to or comparable with results from tests that fully follow TPC benchmark specifications.
Each scenario tests and compares the following configurations:
Lindorm with zstd (default)
Lindorm with dictionary-based compression enabled
Open source HBase with Snappy
Open source MySQL with compression disabled
Open source MongoDB with Snappy
Open source MongoDB with zstd
When to use dictionary-based compression
zstd vs. dictionary-based compression:
| Algorithm | Benefit | Best for |
|---|---|---|
| zstd (default) | Significant storage reduction with no additional configuration | All data types |
| Dictionary-based compression | Further reduction beyond zstd, at the cost of a dictionary training step during data ingestion | Datasets with high row-to-row repetition |
Data that benefits most from dictionary-based compression: datasets with repetitive structure across rows, such as log entries, IoV telemetry fields, and behavioral event records.
For consolidated results across all scenarios, see Summary.
Orders
Dataset
This scenario uses the TPC-H benchmark dataset, defined by the Transaction Processing Performance Council (TPC) to evaluate analytical query performance.
Download the TPC-H tool: TPC-H_Tools_v3.0.0.zip
Generate 10 GB of test data:
# Unzip and build the data generator
unzip TPC-H_Tools_v3.0.0.zip
cd TPC-H_Tools_v3.0.0/dbgen
cp makefile.suite makefile
# Edit makefile: set the following fields
# CC = gcc
# DATABASE = ORACLE
# MACHINE = LINUX
# WORKLOAD = TPCH
make
# Generate 10 GB of test data
./dbgen -s 10This generates eight .tbl files. This test uses ORDERS.tbl: 15 million rows, 1.76 GB.
| Field | Type |
|---|---|
| O_ORDERKEY | INT |
| O_CUSTKEY | INT |
| O_ORDERSTATUS | CHAR(1) |
| O_TOTALPRICE | DECIMAL(15,2) |
| O_ORDERDATE | DATE |
| O_ORDERPRIORITY | CHAR(15) |
| O_CLERK | CHAR(15) |
| O_SHIPPRIORITY | INT |
| O_COMMENT | VARCHAR(79) |
Create test tables
HBase
create 'ORDERS', {NAME => 'f', DATA_BLOCK_ENCODING => 'DIFF', COMPRESSION => 'SNAPPY', BLOCKSIZE => '32768}MySQL
CREATE TABLE ORDERS (
O_ORDERKEY INTEGER NOT NULL,
O_CUSTKEY INTEGER NOT NULL,
O_ORDERSTATUS CHAR(1) NOT NULL,
O_TOTALPRICE DECIMAL(15,2) NOT NULL,
O_ORDERDATE DATE NOT NULL,
O_ORDERPRIORITY CHAR(15) NOT NULL,
O_CLERK CHAR(15) NOT NULL,
O_SHIPPRIORITY INTEGER NOT NULL,
O_COMMENT VARCHAR(79) NOT NULL
);MongoDB
db.createCollection("ORDERS")Lindorm
-- lindorm-cli
CREATE TABLE ORDERS (
O_ORDERKEY INTEGER NOT NULL,
O_CUSTKEY INTEGER NOT NULL,
O_ORDERSTATUS CHAR(1) NOT NULL,
O_TOTALPRICE DECIMAL(15,2) NOT NULL,
O_ORDERDATE DATE NOT NULL,
O_ORDERPRIORITY CHAR(15) NOT NULL,
O_CLERK CHAR(15) NOT NULL,
O_SHIPPRIORITY INTEGER NOT NULL,
O_COMMENT VARCHAR(79) NOT NULL,
PRIMARY KEY(O_ORDERKEY)
);Compression results
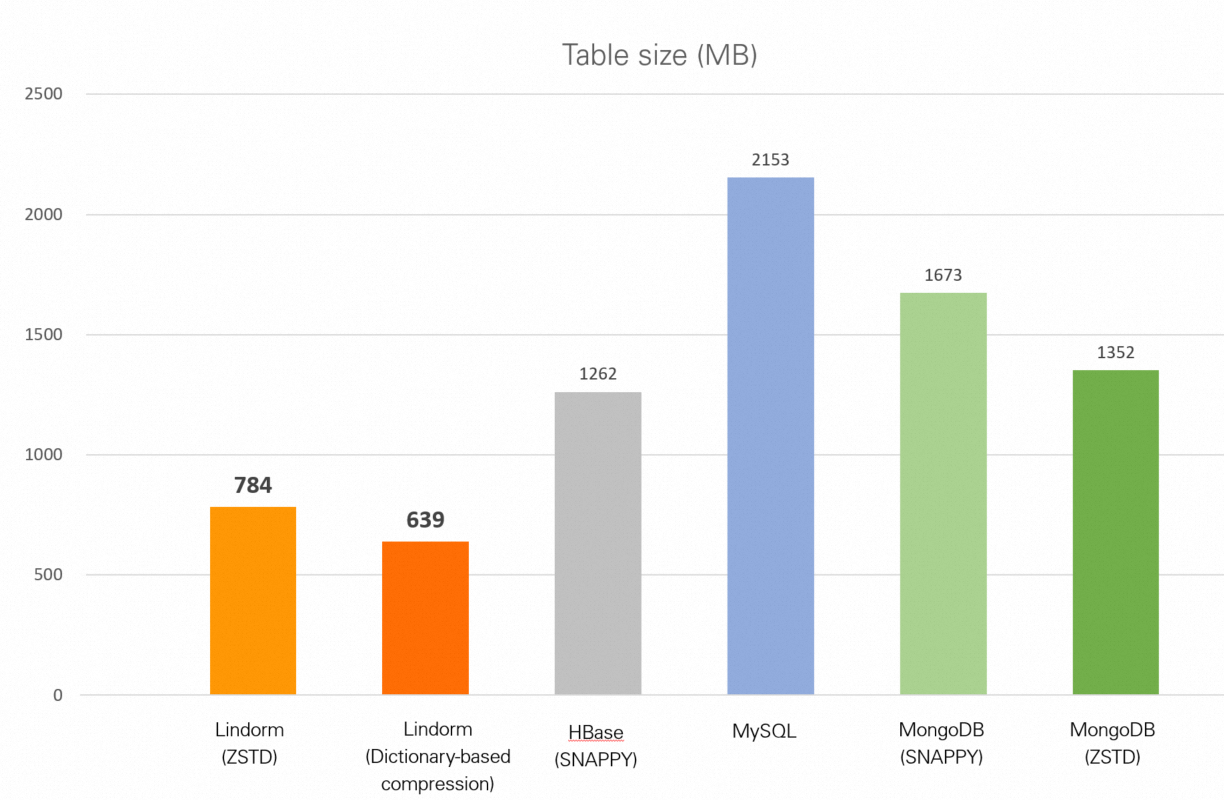
| Database | Table size |
|---|---|
| Lindorm (zstd) | 784 MB |
| Lindorm (dictionary-based compression) | 639 MB |
| HBase (Snappy) | 1.23 GB |
| MySQL (no compression) | 2.10 GB |
| MongoDB (Snappy) | 1.63 GB |
| MongoDB (zstd) | 1.32 GB |
IoV
Dataset
This scenario uses the NGSIM (Next Generation Simulation) dataset, collected by the U.S. Federal Highway Administration from vehicle trajectories on U.S. Route 101. NGSIM is widely used in driving behavior research, traffic flow analysis, vehicle trajectory prediction, and autonomous driving decision planning.
Download NGSIM_Data.csv: 11.85 million rows, 1.54 GB, 25 columns per row.
Create test tables
HBase
create 'NGSIM', {NAME => 'f', DATA_BLOCK_ENCODING => 'DIFF', COMPRESSION => 'SNAPPY', BLOCKSIZE => '32768}MySQL
CREATE TABLE NGSIM (
ID INTEGER NOT NULL,
Vehicle_ID INTEGER NOT NULL,
Frame_ID INTEGER NOT NULL,
Total_Frames INTEGER NOT NULL,
Global_Time BIGINT NOT NULL,
Local_X DECIMAL(10,3) NOT NULL,
Local_Y DECIMAL(10,3) NOT NULL,
Global_X DECIMAL(15,3) NOT NULL,
Global_Y DECIMAL(15,3) NOT NULL,
v_length DECIMAL(10,3) NOT NULL,
v_Width DECIMAL(10,3) NOT NULL,
v_Class INTEGER NOT NULL,
v_Vel DECIMAL(10,3) NOT NULL,
v_Acc DECIMAL(10,3) NOT NULL,
Lane_ID INTEGER NOT NULL,
O_Zone CHAR(10),
D_Zone CHAR(10),
Int_ID CHAR(10),
Section_ID CHAR(10),
Direction CHAR(10),
Movement CHAR(10),
Preceding INTEGER NOT NULL,
Following INTEGER NOT NULL,
Space_Headway DECIMAL(10,3) NOT NULL,
Time_Headway DECIMAL(10,3) NOT NULL,
Location CHAR(10) NOT NULL,
PRIMARY KEY(ID)
);MongoDB
db.createCollection("NGSIM")Lindorm
-- lindorm-cli
CREATE TABLE NGSIM (
ID INTEGER NOT NULL,
Vehicle_ID INTEGER NOT NULL,
Frame_ID INTEGER NOT NULL,
Total_Frames INTEGER NOT NULL,
Global_Time BIGINT NOT NULL,
Local_X DECIMAL(10,3) NOT NULL,
Local_Y DECIMAL(10,3) NOT NULL,
Global_X DECIMAL(15,3) NOT NULL,
Global_Y DECIMAL(15,3) NOT NULL,
v_length DECIMAL(10,3) NOT NULL,
v_Width DECIMAL(10,3) NOT NULL,
v_Class INTEGER NOT NULL,
v_Vel DECIMAL(10,3) NOT NULL,
v_Acc DECIMAL(10,3) NOT NULL,
Lane_ID INTEGER NOT NULL,
O_Zone CHAR(10),
D_Zone CHAR(10),
Int_ID CHAR(10),
Section_ID CHAR(10),
Direction CHAR(10),
Movement CHAR(10),
Preceding INTEGER NOT NULL,
Following INTEGER NOT NULL,
Space_Headway DECIMAL(10,3) NOT NULL,
Time_Headway DECIMAL(10,3) NOT NULL,
Location CHAR(10) NOT NULL,
PRIMARY KEY(ID)
);Compression results
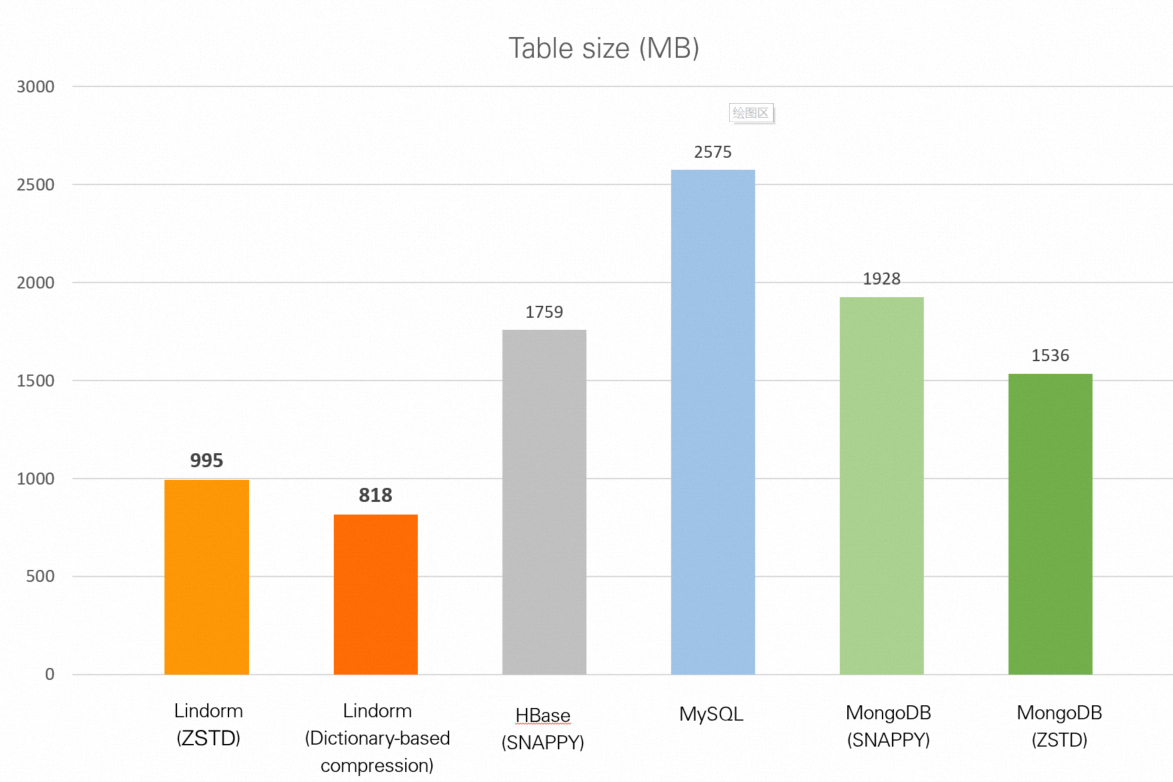
| Database | Table size |
|---|---|
| Lindorm (zstd) | 995 MB |
| Lindorm (dictionary-based compression) | 818 MB |
| HBase (Snappy) | 1.72 GB |
| MySQL (no compression) | 2.51 GB |
| MongoDB (Snappy) | 1.88 GB |
| MongoDB (zstd) | 1.50 GB |
Logs
Dataset
This scenario uses the Online Shopping Store - Web Server Logs dataset (Zaker, Farzin, 2019, Harvard Dataverse, V1).
Download access.log: 10.36 million rows, 3.51 GB. Each row is a single log entry. Example:
54.36.149.41 - - [22/Jan/2019:03:56:14 +0330] "GET /filter/27|13%20%D9%85%DA%AF%D8%A7%D9%BE%DB%8C%DA%A9%D8%B3%D9%84,27|%DA%A9%D9%85%D8%AA%D8%B1%20%D8%A7%D8%B2%205%20%D9%85%DA%AF%D8%A7%D9%BE%DB%8C%DA%A9%D8%B3%D9%84,p53 HTTP/1.1" 200 30577 "-" "Mozilla/5.0 (compatible; AhrefsBot/6.1; +http://ahrefs.com/robot/)" "-"Log data is structurally repetitive across rows, which is why this scenario shows the highest compression gains from dictionary-based compression.
Create test tables
HBase
create 'ACCESS_LOG', {NAME => 'f', DATA_BLOCK_ENCODING => 'DIFF', COMPRESSION => 'SNAPPY', BLOCKSIZE => '32768}MySQL
CREATE TABLE ACCESS_LOG (
ID INTEGER NOT NULL,
CONTENT VARCHAR(10000),
PRIMARY KEY(ID)
);MongoDB
db.createCollection("ACCESS_LOG")Lindorm
-- lindorm-cli
CREATE TABLE ACCESS_LOG (
ID INTEGER NOT NULL,
CONTENT VARCHAR(10000),
PRIMARY KEY(ID)
);Compression results
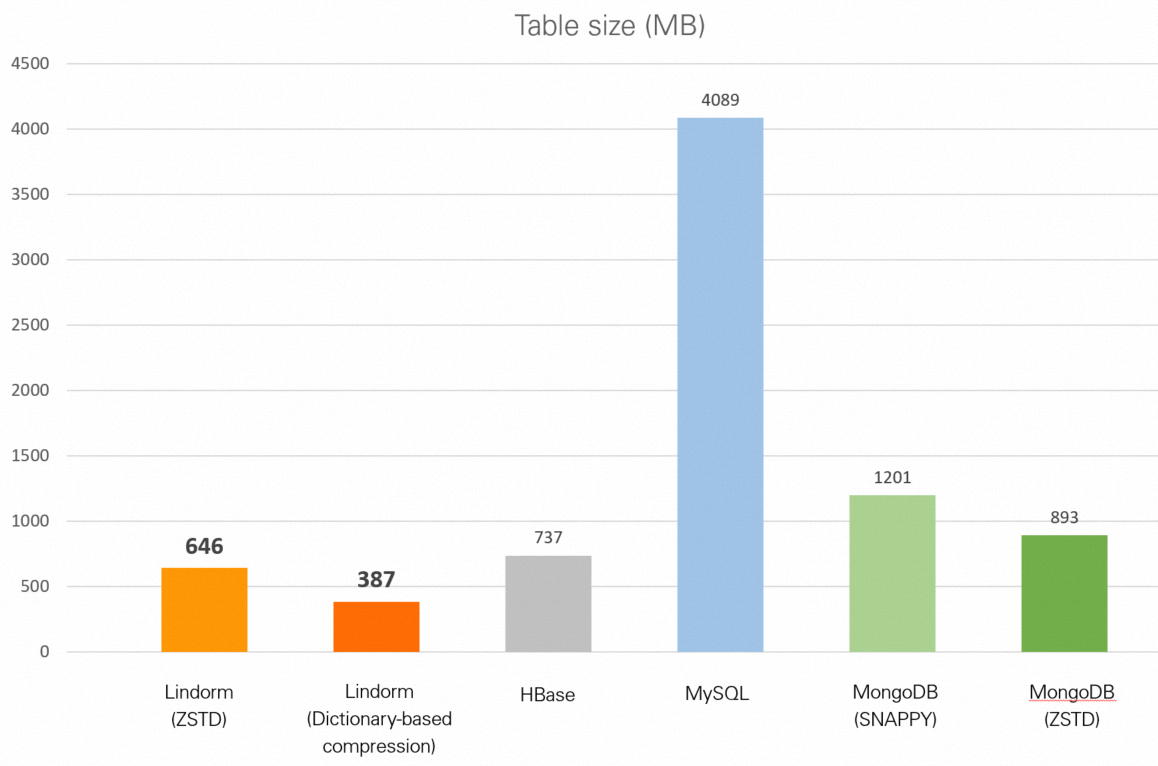
| Database | Table size |
|---|---|
| Lindorm (zstd) | 646 MB |
| Lindorm (dictionary-based compression) | 387 MB |
| HBase (Snappy) | 737 MB |
| MySQL (no compression) | 3.99 GB |
| MongoDB (Snappy) | 1.17 GB |
| MongoDB (zstd) | 893 MB |
User behaviors
Dataset
This scenario uses the Shop Info and User Behavior data from IJCAI-15 dataset from Alibaba Cloud Tianchi.
Download data_format1.zip and use user_log_format1.csv: 54.92 million rows, 1.91 GB.
| Column | Sample values |
|---|---|
| user_id | 328862 |
| item_id | 323294, 844400, 575153 |
| cat_id | 833, 1271 |
| seller_id | 2882 |
| brand_id | 2661 |
| time_stamp | 829 |
| action_type | 0 |
Create test tables
HBase
create 'USER_LOG', {NAME => 'f', DATA_BLOCK_ENCODING => 'DIFF', COMPRESSION => 'SNAPPY', BLOCKSIZE => '32768}MySQL
CREATE TABLE USER_LOG (
ID INTEGER NOT NULL,
USER_ID INTEGER NOT NULL,
ITEM_ID INTEGER NOT NULL,
CAT_ID INTEGER NOT NULL,
SELLER_ID INTEGER NOT NULL,
BRAND_ID INTEGER,
TIME_STAMP CHAR(4) NOT NULL,
ACTION_TYPE CHAR(1) NOT NULL,
PRIMARY KEY(ID)
);MongoDB
db.createCollection("USER_LOG")Lindorm
-- lindorm-cli
CREATE TABLE USER_LOG (
ID INTEGER NOT NULL,
USER_ID INTEGER NOT NULL,
ITEM_ID INTEGER NOT NULL,
CAT_ID INTEGER NOT NULL,
SELLER_ID INTEGER NOT NULL,
BRAND_ID INTEGER,
TIME_STAMP CHAR(4) NOT NULL,
ACTION_TYPE CHAR(1) NOT NULL,
PRIMARY KEY(ID)
);Compression results
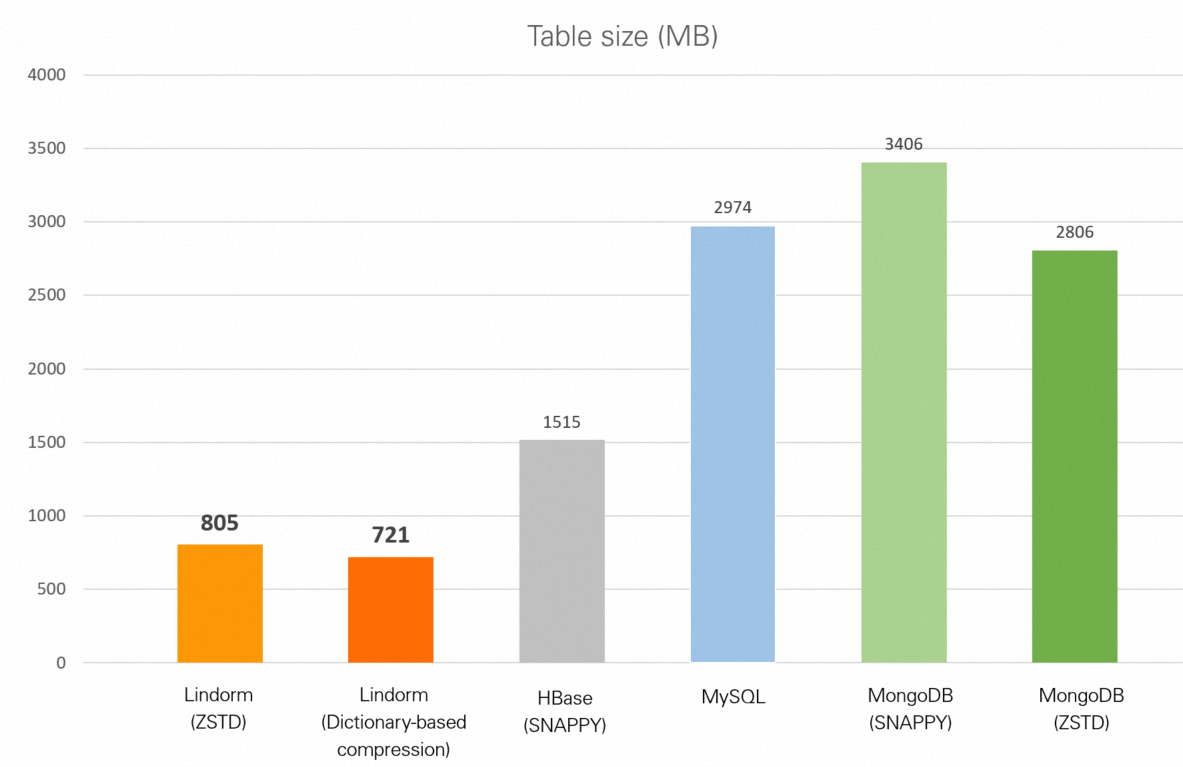
| Database | Table size |
|---|---|
| Lindorm (zstd) | 805 MB |
| Lindorm (dictionary-based compression) | 721 MB |
| HBase (Snappy) | 1.48 GB |
| MySQL (no compression) | 2.90 GB |
| MongoDB (Snappy) | 3.33 GB |
| MongoDB (zstd) | 2.74 GB |
Summary
Lindorm achieves a higher compression ratio than open source databases even without dictionary-based compression enabled. With dictionary-based compression, Lindorm achieves the highest compression ratio across all four scenarios. Compared to the defaults used by each open source database, Lindorm with dictionary-based compression reduces stored data size by:
1–2x more than open source HBase (Snappy)
2–4x more than open source MongoDB (Snappy or zstd)
3–10x more than open source MySQL (uncompressed)
The following table consolidates all test results.
| Dataset | Original size | Lindorm (zstd) | Lindorm (dictionary) | HBase (Snappy) | MySQL | MongoDB (Snappy) | MongoDB (zstd) |
|---|---|---|---|---|---|---|---|
| Order data (TPC-H) | 1.76 GB | 784 MB | 639 MB | 1.23 GB | 2.10 GB | 1.63 GB | 1.32 GB |
| IoV data (NGSIM) | 1.54 GB | 995 MB | 818 MB | 1.72 GB | 2.51 GB | 1.88 GB | 1.50 GB |
| Log data (web server) | 3.51 GB | 646 MB | 387 MB | 737 MB | 3.99 GB | 1.17 GB | 893 MB |
| User behavior (IJCAI-15) | 1.91 GB | 805 MB | 721 MB | 1.48 GB | 2.90 GB | 3.33 GB | 2.74 GB |
Choosing between zstd and dictionary-based compression: zstd is enabled by default and reduces storage costs across all data types with no additional configuration. Dictionary-based compression provides a further reduction—most pronounced for log data (387 MB vs. 646 MB) and most modest for numeric-heavy IoV data—at the cost of a dictionary training step during data ingestion.