You can use a solution in which Lindorm is used together with ApsaraDB for RDS for low storage costs, convenient O&M, and elastic scaling. This topic describes the architecture and benefits of the solution.
Only Lindorm Tunnel Service (LTS) instances that are purchased before March 10, 2023 can be used in this solution.
Background information
In mobile Internet scenarios, large amounts of business data is generated each day. With the growth of your business, the amount of generated data significantly increases. At the same time, the frequency at which historical data is queried decreases over time. If all data is stored in relational databases, various issues may occur.
Challenges
Growth of storage costs: Storage costs are proportional to data volumes. The exponential increase of data volumes causes the exponential increase of storage costs.
Decrease of query performance: If more than 1 TB of data is stored in a single instance, the query performance of the instance decreases.
Complex O&M: If you shard databases and tables to mitigate performance degradation caused by the increased data volume, the O&M costs and development costs increase.
Requirements
Low storage costs: The storage costs of historical data are one-tenth the storage costs of online data.
Auto scaling: The computing and storage capabilities of the database can automatically scale out to eliminate the O&M difficulties in sharded databases and tables.
Low costs for schema modification: The schemas of databases can be quickly modified or the databases support dynamic schemas. This way, the period of time that is required to modify the schemas of archive databases is reduced.
Low costs for code modification: SQL statements can be used to query data.
Real-time query: In scenarios in which bills or chat records are queried, the response time (RT) of querying historical data is similar to the RT of querying real-time data.
Data analysis: Historical data is queried at a low frequency. In some scenarios, you need to mine and analyze full data. For example, Alipay annual bills are generated based on full data.
Lindorm can meet various requirements, such as requirements for low storage costs, convenient O&M, elastic scaling, and stable performance. Lindorm can be used together with relational databases to provide an optimal real-time archive database service at low costs.
Architecture
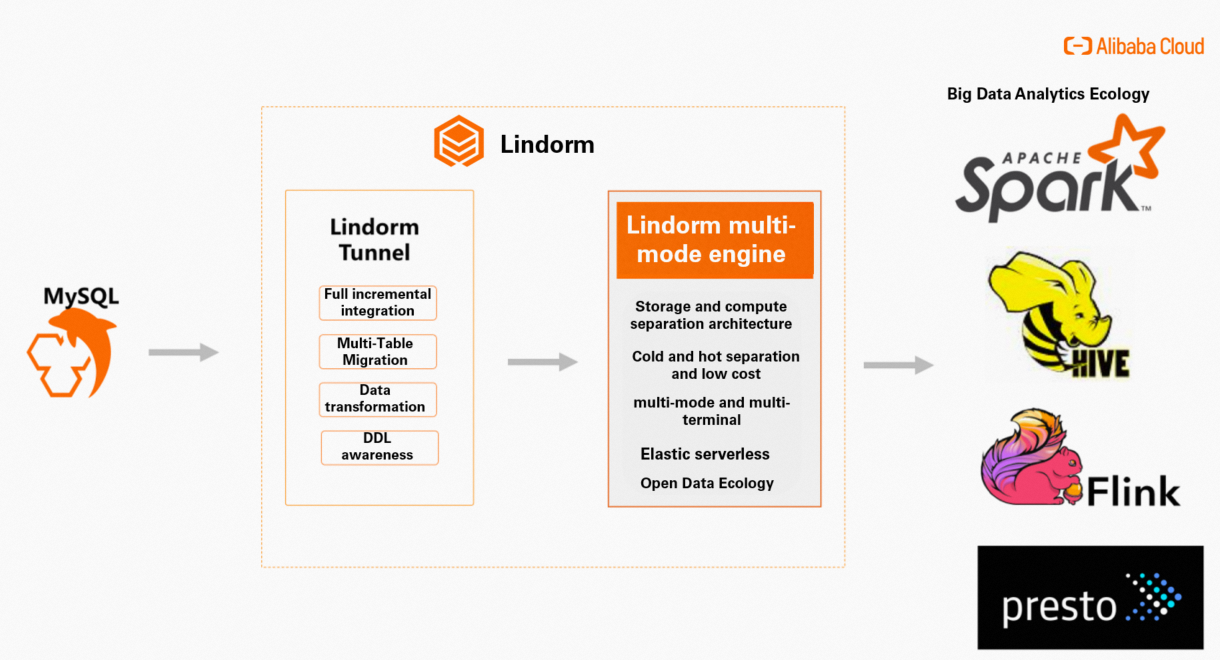
LTS allows you to import full data and incremental data from relational databases such as ApsaraDB RDS for MySQL databases. LTS also provides capabilities for enterprises to perform data migration. For example, you can migrate data between tables, modify data during migration, and execute DDL statements. LTS helps you migrate data in an efficient manner.
Lindorm can store large amounts of data at a price as low as USD 0.019/GB/Month. It also provides the automatic scaling feature and supports the pay-as-you-go billing method. Lindorm allows you to use various engines to process multi-model data. This meets your data storage requirements in various scenarios. Lindorm can also seamlessly connect to open source analytical services, such as Apache Spark, Apache Hive, Apache Flink, and Presto, to meet your requirements for complex data analysis and explore the value of data.
Benefits
Ease of use
Lindorm allows you to configure data migration tasks in a visualized manner in a few minutes.
Lindorm provides an integrated solution for the migration of full data and incremental data. This helps you minimize data migration costs.
Lindorm provides various capabilities for data migration. For example, you can migrate data between tables and modify the data during migration. You can also merge tables and change the combination of columns in an efficient manner.
Lindorm provides a comprehensive monitoring and alerting feature to help you ensure the stability of data migration tasks.
Cost-effectiveness
Lindorm provides capacity-optimized disks for storage at a price as low as CNY 0.12/GB/Month. The built-in buffer layer can accelerate queries to ensure the performance of real-time queries. This way, Lindorm provides an optimal solution for archive databases.
The Lindorm wide table engine (LindormTable) optimizes the throughput and latency based on various dimensions to improve performance. The benchmark performance of LindormTable is seven times the benchmark performance of the open source HBase service. For more information, see Test results. The Lindorm time series engine (LindormTSDB) integrates various innovative architecture designs to provide high performance. The benchmark performance of LimdormTSDB is ranked the first in the list released by the China Academy of Information and Communications Technology.
Lindorm supports hot and cold data separation. In scenarios where hot data is converted to cold data over time, such as monitoring data, historical chat data, and data of transaction bills, Lindorm automatically identifies cold data and separates cold data from hot data, and then archives cold data in cold storage. This way, hot data is stored in high-performance storage media and cold data is stored in low-cost storage media. The difference between the prices of the two types of storage media can be up to 10:1. You do not need to modify the code of your business application to perform read operations or write operations on tables in which cold data is separated from hot data. In addition, queries performed on hot data are accelerated to improve query performance.
Lindorm supports adaptive compression. The system automatically selects a compression algorithm based on the types and characteristics of data. The supported compression algorithms include dictionary encoding, prefix encoding, delta encoding, and entropy encoding. Compared with common algorithms in the industry, the adaptive compression feature provided by Lindorm improves the compression ratio by 10 percent to 30 percent.
Cloud native architecture that supports auto scaling
Lindorm decouples computing and storage resources. This way, computing resources and storage resources can be separately scaled. This helps you maximize resource utilization.
Lindorm Serverless enables instant scaling and uses the pay-as-you-go billing method. Lindorm Serverless is built based on multi-tenant data isolation, intelligent scheduling, and the Infrastructure as a Service (IaaS) architecture that can be scaled. Lindorm Serverless provides a service level agreement (SLA) that meets the availability requirements of most enterprises. Lindorm Serverless also reduce the O&M workloads for capacity management and eliminate the stability risks that occur due to traffic fluctuations.
Multi-model capabilities and data retrieval
Lindorm is compatible with major open source standard APIs, including the Apache HBase API, Apache Phoenix API for SQL, and Cassandra API for Cassandra Query Language (CQL). This helps you reduce labor costs and resource costs. Lindorm provides various features, including global secondary indexes, multi-dimensional queries, dynamic columns, and the time-to-live (TTL) feature for data. Lindorm is suitable for various scenarios. For example, you can use Lindorm to store metadata and data of orders, bills, images, chat records, feed streams, and logs.
Lindorm provides a search engine service called LindormSearch that is compatible with the open source standard Solr APIs. You can activate LindormSearch for your Lindorm instance, and then use LindormSearch to perform full-text searches, aggregate values, and perform complex multi-dimensional queries. LindormSearch accelerates data queries and can be used to retrieve data for complex real-time data analysis.
Compatibility with big data ecosystems
Lindorm can be used together with open source engines for big data analysis. The supported engines include Apache Spark, Apache Hive, Apache Flink, and Presto. Lindorm supports multiple types of operations on big data. For example, you can call APIs to perform operations and query data from a file system. Lindorm can also help you analyze large amounts of data in an efficient manner.
Common scenarios
Your business application writes data of transaction records to a MySQL database. LTS synchronizes the transaction data from the MySQL database to a Lindorm instance in real time. The MySQL database stores data of transaction records that were generated in the previous three months, and the Lindorm instance that uses capacity-optimized disks stores the historical transaction data that was generated before the previous three months. This reduces storage costs by more than 90 percent.
In specific scenarios, you can specify complex conditions when you perform queries. For example, if you want to query information about a transaction, you can combine query conditions, such as the point in time when the transaction was generated, the location of the customer, the transaction price, and the remarks for the transaction. You can use LindormSearch to perform full-text searches, aggregate values, and perform complex multi-dimensional queries. You can perform these operations based on your business requirements without the need to modify the code of your business application.
LTS can synchronize data of bills from Lindorm to an offline computing platform such as Apache Spark or MaxCompute for computing. Operations reports that are generated are analyzed based on your business requirements. Then, data is returned to Lindorm for real-time queries.