Stream log data from Simple Log Service (SLS) into Hologres for real-time analysis and queries. This topic covers two integration methods: Flink and DataWorks data integration.
Choose an integration method
| Flink | DataWorks data integration | |
|---|---|---|
| Setup complexity | Higher — requires writing Flink SQL jobs | Lower — visual field mapping, no code required |
| Flexibility | High — parse or transform JSON in flight | Standard — maps fields as-is |
| Best for | Teams already using Realtime Compute for Apache Flink, or needing to transform data before ingestion | Teams using DataWorks, or needing a quick setup without custom logic |
If you are already running Realtime Compute for Apache Flink, use the Flink method. Otherwise, start with DataWorks data integration for a faster setup.
How it works
SLS collects and stores logs, metrics, and traces. Hologres is a real-time data warehouse that supports sub-second interactive queries on large datasets. By connecting the two, you can ingest SLS data as it arrives and query it immediately in Hologres.
The data flow for each method:
Flink: SLS Logstore → Flink source table → Flink SQL transformation → Hologres sink table
DataWorks: SLS Loghub data source → real-time sync task → Hologres data source
Prerequisites
Before you begin, ensure that you have:
An SLS project and a Logstore. See Use Logtail to collect and analyze text logs from an ECS instance.
A Hologres instance connected to a development tool. See Hologres usage process.
(Flink method only) Realtime Compute for Apache Flink activated and a project created. See Activate fully managed Flink and Create and manage projects.
(DataWorks method only) DataWorks activated and a workspace created. See Purchase guide and Create a workspace.
Prepare SLS data
Both methods use the same SLS data source. This example uses simulated game logon and consumption logs from the SLS platform. If you have business data, use it directly.
Log on to the Simple Log Service console.
In the Data Ingestion section, click Simulate Data.
On the Simulate Data tab, click Simulate under Game Operation Logs.
On the Select Log Space page, select a Project and a Logstore, then click Next.
On the Simulate Data page, set the scope and frequency, then click Start Import.
The content field is of the JSON type. The simulated fields and sample data look like this:
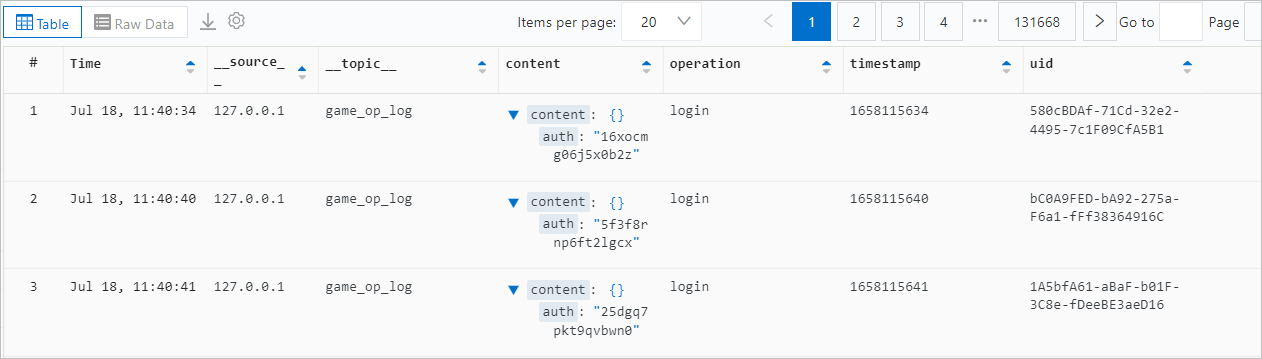
For more information about querying this data in SLS, see Quick start for query and analysis.
Write SLS data to Hologres using Flink
Step 1: Create a Hologres table
Create a destination table in Hologres. Add indexes for fields you plan to query frequently to improve performance. For full Data Definition Language (DDL) options, see Create a table.
CREATE TABLE sls_flink_holo (
content JSONB,
operation TEXT,
uid TEXT,
topic TEXT,
source TEXT,
c__timestamp TIMESTAMPTZ,
receive_time BIGINT,
PRIMARY KEY (uid)
);Step 2: Write data using Flink
Create a Flink SQL job with an SLS source table and a Hologres sink table, then insert data between them.
For background on the connectors used here:
SLS source table connector: SLS source table
Hologres sink table connector: Hologres sink table
Because Flink does not have a native JSON type, the content field uses VARCHAR as a substitute. The JSON data is written directly to Hologres, which stores it as JSONB. Alternatively, parse the JSON in Flink before writing.Define the SLS source table:
CREATE TEMPORARY TABLE sls_input (
content STRING,
operation STRING,
uid STRING,
`__topic__` STRING METADATA VIRTUAL,
`__source__` STRING METADATA VIRTUAL,
`__timestamp__` BIGINT METADATA VIRTUAL,
`__tag__` MAP<VARCHAR, VARCHAR> METADATA VIRTUAL
)
WITH (
'connector' = 'sls',
'endpoint' = '<sls-private-endpoint>', -- Private endpoint of the SLS project
'accessid' = '<your-access-key-id>', -- AccessKey ID
'accesskey' = '<your-access-key-secret>', -- AccessKey secret
'starttime' = '2024-08-30 00:00:00', -- Start time to consume logs
'project' = '<your-sls-project>', -- SLS project name
'logstore' = '<your-logstore>' -- Logstore name
);Define the Hologres sink table:
CREATE TEMPORARY TABLE hologres_sink (
content VARCHAR,
operation VARCHAR,
uid VARCHAR,
topic STRING,
source STRING,
c__timestamp TIMESTAMP,
receive_time BIGINT
)
WITH (
'connector' = 'hologres',
'dbname' = '<your-holo-database>', -- Hologres database name
'tablename' = '<your-holo-table>', -- Hologres destination table name
'username' = '<your-access-key-id>', -- AccessKey ID
'password' = '<your-access-key-secret>', -- AccessKey secret
'endpoint' = '<your-holo-vpc-endpoint>' -- VPC endpoint of the Hologres instance
);Insert data:
All metadata fields from the SLS source (__topic__, __source__, __timestamp__, __tag__) are mapped to the corresponding Hologres columns. The __timestamp__ Unix timestamp is cast to TIMESTAMP, and __receive_time__ is extracted from the tag map and cast to BIGINT.
INSERT INTO hologres_sink
SELECT
content,
operation,
uid,
`__topic__`,
`__source__`,
CAST(FROM_UNIXTIME(`__timestamp__`) AS TIMESTAMP),
CAST(__tag__['__receive_time__'] AS BIGINT) AS receive_time
FROM
sls_input;For steps on developing and running SQL jobs in Flink, see Job development map and Start a job.
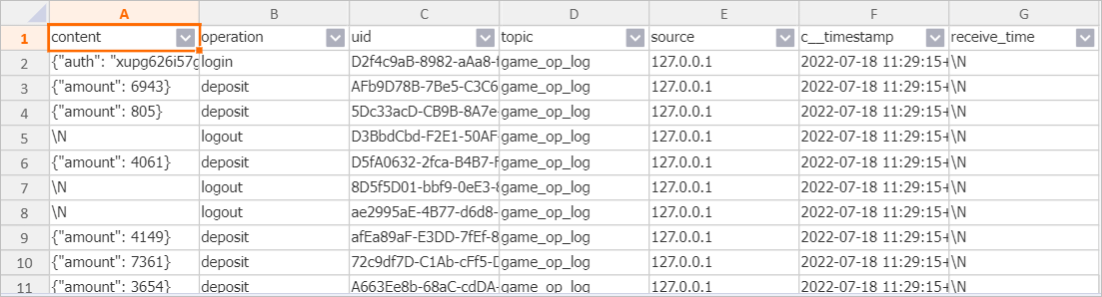
Step 3: Verify data in Hologres
After the Flink job starts, query the destination table to confirm data is flowing in:
Write SLS data to Hologres using DataWorks data integration
Step 1: Create a Hologres table
Create a destination table in Hologres. In this example, uid is the primary key (ensures row uniqueness) and the distribution key (routes rows with the same uid to the same shard, improving query performance). The timestamp field is set as the event time column.
BEGIN;
CREATE TABLE sls_dw_holo (
content JSONB,
operation TEXT,
uid TEXT,
C_Topic TEXT,
C_Source TEXT,
timestamp BIGINT,
PRIMARY KEY (uid)
);
CALL set_table_property('sls_dw_holo', 'distribution_key', 'uid');
CALL set_table_property('sls_dw_holo', 'event_time_column', 'timestamp');
COMMIT;For more DDL options, see Create a table.
Step 2: Configure data sources
Add both data sources to your DataWorks workspace before creating a sync task.
SLS: Add a LogHub data source. See Configure a LogHub (SLS) data source.
Hologres: Add a Hologres data source. See Configure a Hologres data source.
Step 3: Create a real-time sync task
Create and run a real-time sync task in DataWorks data integration. Set the input to the LogHub data source and the output to the Hologres data source. Configure field mapping as shown below:
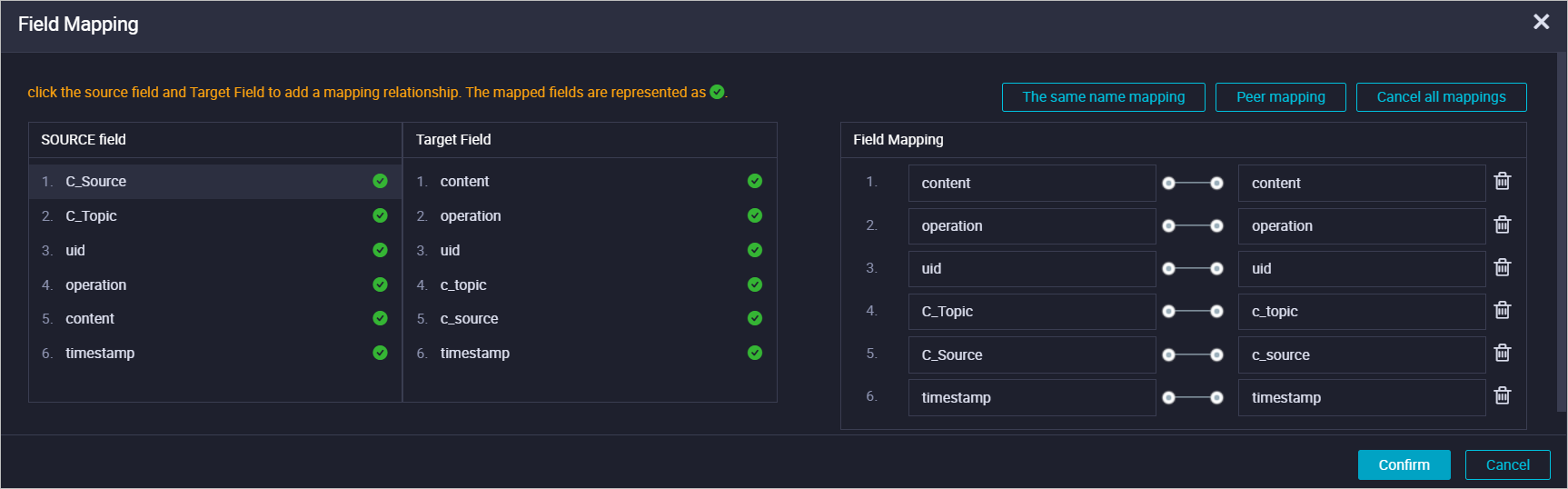
For detailed steps, see Configure a real-time synchronization task for incremental data in a single table.
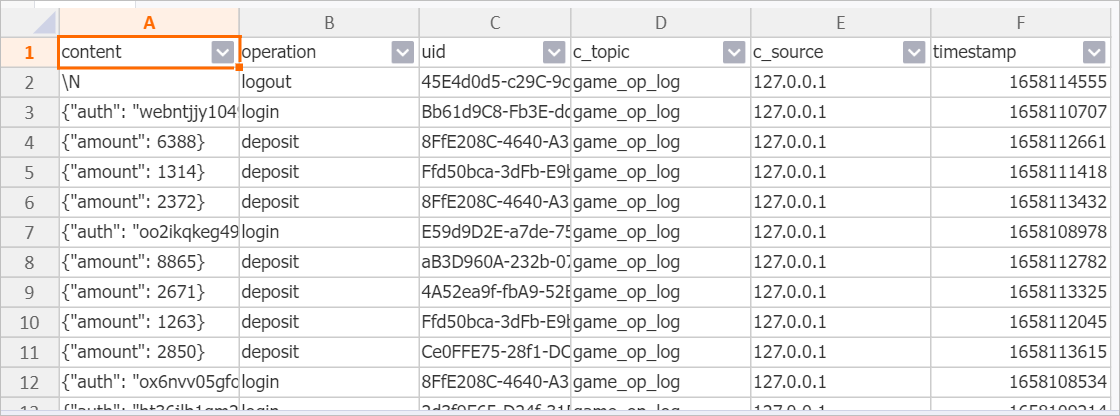
Step 4: Verify data in Hologres
After the sync task starts, query the destination table to confirm data is flowing in:
Troubleshoot common issues
| Symptom | Likely cause | Resolution |
|---|---|---|
| Flink job fails to start | Incorrect endpoint or credentials in the connector WITH clause | Verify the SLS private endpoint, AccessKey ID, and AccessKey secret. Check that the Hologres VPC endpoint matches the instance region. |
| No data appears in the Hologres table | Flink job is running but the starttime is set too early or too late | Adjust starttime in the SLS source table definition to align with when logs were written. |
Type conversion error on __timestamp__ | FROM_UNIXTIME returns TIMESTAMP without timezone; destination column is TIMESTAMPTZ | Cast the result to TIMESTAMPTZ instead of TIMESTAMP, or change the destination column type. |
| DataWorks sync task reports field mismatch | Source and destination field names or types do not match | In the sync task field mapping configuration, manually align source and destination fields. |
What's next
To optimize query performance in Hologres, consider adding bitmap indexes or configuring clustering keys on your destination table. See Create a table.
To monitor your Flink job, use the Flink console job monitoring dashboard.
To monitor your DataWorks sync task, see O&M for real-time sync tasks.