Range queries on large tables can be slow when Hologres must scan every file in a shard. Configuring an event time column (event_time_column) tells Hologres how to sort and group data files during periodic merges. Queries with a range filter on that column skip files whose value range does not overlap with the filter — scanning only what is necessary instead of everything.
In Hologres V0.9, the property was renamed fromsegment_keytoevent_time_column. Both names refer to the same property.segment_keyremains usable in V0.9 and earlier.
How it works
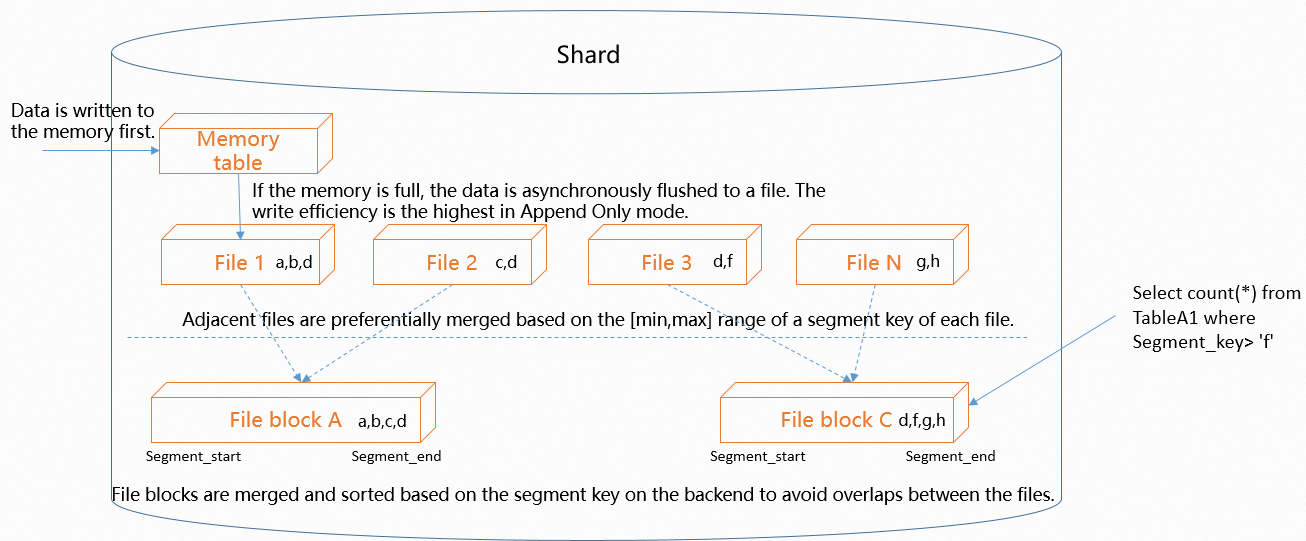
Data in a shard goes through three stages:
-
Write to memory table. Incoming data is appended to an in-memory table in append-only mode to maximize write throughput. When the memory table is full, Hologres asynchronously flushes its contents to disk as a new file.
-
Files accumulate over time. Because writes are append-only, the number of files grows as data flows in. Hologres periodically merges these files in the background.
-
Merge with range sorting. If
event_time_columnis set, Hologres sorts files by the value range of the configured column before merging. Files with adjacent ranges are merged together. After merging, each file covers a compact, non-overlapping range of values. When a query arrives with a range filter on the event time column, Hologres compares the filter range against each file's min/max statistics and skips files that do not overlap. The more compact the value ranges, the more files Hologres can skip.
How UPDATE operations benefit
In Hologres, UPDATE is implemented as DELETE + INSERT. When you run UPDATE or INSERT ON CONFLICT on a table with a primary key, Hologres needs to find the existing row to mark it as deleted before inserting the new version.
With event_time_column configured, Hologres first looks up the event time column value for the target primary key, then uses that value to locate the specific file containing the row. Without it, Hologres must scan all files to find the row — increasing I/O and CPU load as the table grows.
Use cases
event_time_column accelerates two types of operations:
-
Range filter queries, including equality conditions on the event time column
-
Primary key UPDATE operations (via
UPDATEorINSERT ON CONFLICT)
Configure the event time column
Set event_time_column when creating the table. The property cannot be changed after the table is created — to change it, recreate the table.
Syntax for Hologres V2.1 and later:
CREATE TABLE <table_name> (...) WITH (event_time_column = '[<columnName>[,...]]');Syntax for all Hologres versions:
BEGIN;
CREATE TABLE <table_name> (...);
CALL set_table_property('<table_name>', 'event_time_column', '[<columnName> [,...]]');
COMMIT;| Parameter | Description |
|---|---|
table_name |
The name of the table to configure |
columnName |
The column (or columns) to use as the event time column |
Choose the right column
The effectiveness of event_time_column depends on the column you choose. Evaluate candidates in the following order:
1. Use columns with monotonically increasing or decreasing values.
Timestamp columns that track when a record was created or last updated work best. Because new data always has a higher timestamp, successive files naturally cover non-overlapping ranges — the merge step produces compact, well-separated file ranges that are easy to prune.
Log ingestion timestamps, traffic event times, and similar time-series columns are good fits for the same reason.
2. If no suitable column exists, add one.
Add an update_time column and populate it with the current time on every UPSERT operation. This creates a monotonically increasing column that gives Hologres a reliable range to sort on.
3. Limit event time columns to one or two.
Files are sorted by the leftmost column first, then by subsequent columns within the same range. Queries hit the event time column only when the filter starts from the leftmost configured column (the leftmost matching principle).
Given columns a, b, c configured in that order:
| Query filter | Hits event time column? |
|---|---|
WHERE a = ... |
Yes — a is the leftmost column |
WHERE a = ... AND b = ... |
Yes — starts from a |
WHERE a = ... AND c = ... |
Partially — only a hits |
WHERE b = ... |
No — skips a |
WHERE b = ... AND c = ... |
No — skips a |
Because queries that skip the leftmost column get no benefit, adding more than two columns rarely improves filtering and can complicate query planning.
Limitations
-
NOT NULL required. Event time columns must not contain null values. In Hologres V1.3.28 and later, specifying a nullable column as an event time column is blocked by default. If your business requires it, you can override the restriction before the
CREATE TABLEstatement:SET hg_experimental_enable_nullable_segment_key = true;To check whether any existing event time columns contain null values, run:
WITH t_base AS ( SELECT * FROM hologres.hg_table_info WHERE collect_time::date = CURRENT_DATE ), t1 AS ( SELECT db_name, schema_name, table_name, jsonb_array_elements(table_meta::jsonb -> 'columns') cols FROM t_base ), t2 AS ( SELECT db_name, schema_name, table_name, cols ->> 'name' col_name FROM t1 WHERE cols -> 'nullable' = 'true'::jsonb ), t3 AS ( SELECT db_name, schema_name, table_name, regexp_replace(regexp_split_to_table(table_meta::jsonb ->> 'segment_key', ','), ':asc|:desc$', '') segment_key_col FROM t_base WHERE table_meta::jsonb -> 'segment_key' IS NOT NULL ) SELECT CURRENT_DATE, t3.db_name, t3.schema_name, t3.table_name, jsonb_build_object('nullable_segment_key_column', string_agg(t3.segment_key_col, ',')) AS nullable_segment_key_column FROM t2, t3 WHERE t3.db_name = t2.db_name AND t3.schema_name = t2.schema_name AND t3.table_name = t2.table_name AND t2.col_name = t3.segment_key_col GROUP BY t3.db_name, t3.schema_name, t3.table_name;In Hologres V1.3.20 to V1.3.27, nullable columns can be set as event time columns without the override flag.
-
Immutable after creation. The
event_time_columnproperty cannot be modified once the table is created. To change it, create a new table. -
Column-oriented tables only. Row-oriented tables do not support
event_time_column. -
Unsupported data types. The following data types cannot be used as event time columns: DECIMAL, NUMERIC, FLOAT, DOUBLE, ARRAY, JSON, JSONB, BIT, MONEY, and other complex data types.
-
Default behavior for column-oriented tables. If you do not set
event_time_column, Hologres applies a default:-
The first non-null column of type TIMESTAMP or TIMESTAMPTZ is used.
-
If no such column exists, the first non-null column of type DATE is used.
-
In versions earlier than V0.9, no default is applied.
-
Examples
Single event time column
Hologres V2.1 and later:
CREATE TABLE tbl_segment_test (
a int NOT NULL,
b timestamptz NOT NULL
)
WITH (
event_time_column = 'b'
);
INSERT INTO tbl_segment_test VALUES
(1,'2022-09-05 10:23:54+08'),
(2,'2022-09-05 10:24:54+08'),
(3,'2022-09-05 10:25:54+08'),
(4,'2022-09-05 10:26:54+08');
EXPLAIN SELECT * FROM tbl_segment_test WHERE b > '2022-09-05 10:24:54+08';All Hologres versions:
BEGIN;
CREATE TABLE tbl_segment_test (
a int NOT NULL,
b timestamptz NOT NULL
);
CALL set_table_property('tbl_segment_test', 'event_time_column', 'b');
COMMIT;
INSERT INTO tbl_segment_test VALUES
(1,'2022-09-05 10:23:54+08'),
(2,'2022-09-05 10:24:54+08'),
(3,'2022-09-05 10:25:54+08'),
(4,'2022-09-05 10:26:54+08');
EXPLAIN SELECT * FROM tbl_segment_test WHERE b > '2022-09-05 10:24:54+08';Multiple event time columns
Hologres V2.1 and later:
CREATE TABLE tbl_segment_test_2 (
a int NOT NULL,
b timestamptz NOT NULL
)
WITH (
event_time_column = 'a,b'
);
INSERT INTO tbl_segment_test_2 VALUES
(1,'2022-09-05 10:23:54+08'),
(2,'2022-09-05 10:24:54+08'),
(3,'2022-09-05 10:25:54+08'),
(4,'2022-09-05 10:26:54+08');
-- Does not hit the event time column (skips a, starts from b)
SELECT * FROM tbl_segment_test_2 WHERE b > '2022-09-05 10:24:54+08';
-- Hits the event time column (starts from a)
SELECT * FROM tbl_segment_test_2 WHERE a = 3 AND b > '2022-09-05 10:24:54+08';
SELECT * FROM tbl_segment_test_2 WHERE a > 3 AND b < '2022-09-05 10:26:54+08';
SELECT * FROM tbl_segment_test_2 WHERE a > 3 AND b > '2022-09-05 10:24:54+08';All Hologres versions:
BEGIN;
CREATE TABLE tbl_segment_test_2 (
a int NOT NULL,
b timestamptz NOT NULL
);
CALL set_table_property('tbl_segment_test_2', 'event_time_column', 'a,b');
COMMIT;
INSERT INTO tbl_segment_test_2 VALUES
(1,'2022-09-05 10:23:54+08'),
(2,'2022-09-05 10:24:54+08'),
(3,'2022-09-05 10:25:54+08'),
(4,'2022-09-05 10:26:54+08');
-- Does not hit the event time column (skips a, starts from b)
SELECT * FROM tbl_segment_test_2 WHERE b > '2022-09-05 10:24:54+08';
-- Hits the event time column (starts from a)
SELECT * FROM tbl_segment_test_2 WHERE a = 3 AND b > '2022-09-05 10:24:54+08';
SELECT * FROM tbl_segment_test_2 WHERE a > 3 AND b < '2022-09-05 10:26:54+08';
SELECT * FROM tbl_segment_test_2 WHERE a > 3 AND b > '2022-09-05 10:24:54+08';Verify that queries use the event time column
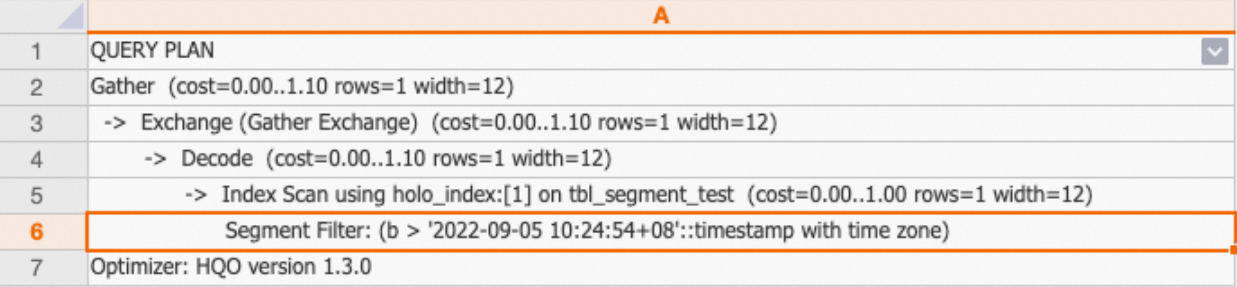
Run EXPLAIN on your query. If the execution plan includes Segment Filter, the query is using the event time column to prune files — meaning Hologres compared the filter range against file-level min/max statistics and skipped files outside the range.
What's next
-
Guide on scenario-specific table creation and tuning — choose the right table properties for your query patterns