Hologres data lake acceleration, built on Alibaba Cloud Data Lake Formation (DLF) and Object Storage Service (OSS), provides flexible data access and analysis capabilities and efficient data processing. This significantly speeds up queries and analysis of data in OSS data lakes. This topic describes how to read from and write to OSS data using DLF 1.0 in Hologres.
Prerequisites
DLF 1.0 is activated. For more information, see Quick Start. For a list of regions where DLF is available, see Supported regions and endpoints.
OSS is activated and your data is ready. For more information, see Get started with OSS.
You have configured OSS authorization. To access OSS data through foreign tables, the account used must have the required OSS access permissions. Otherwise, even if the foreign table is created successfully, you cannot query the data. For details on OSS authorization, see Bucket Policy (Java SDK V1).
(Optional) If you plan to use OSS-HDFS, you must first enable the OSS-HDFS service. For more information, see Enable OSS-HDFS.
Usage notes
When exporting Hologres data to OSS, only the
INSERT INTOcommand is supported. Commands such asINSERT ON CONFLICT,UPDATE, orDELETEare not supported.Only Hologres V1.3 or later supports writing data back to OSS, and only files in ORC, Parquet, CSV, or SequenceFile format are supported.
Data lake acceleration is not supported for read-only secondary instances.
The
IMPORT FOREIGN SCHEMAstatement supports importing partitioned tables stored in OSS. Hologres currently supports querying up to 512 partitions at a time. Add partition filter conditions to ensure each query involves no more than 512 partitions.Lake data queries work by loading specific query partitions of foreign table data into Hologres memory and cache at runtime for computation. To maintain query performance, Hologres limits the data volume per query to 200 GB (the amount of data hit after partition filtering).
You cannot run
UPDATE,DELETE, orTRUNCATEcommands on foreign tables.The new version of DLF does not support OSS data lake acceleration. Only DLF 1.0 (DLF-Legacy) supports this acceleration feature.
Procedures
Environment configuration
Enable DLF_FDW backend configuration for your Hologres instance.
In the Hologres console, go to the Instances or Instance Details page. In the Actions column for the target instance, click Data Lake Acceleration and confirm the operation. The system automatically configures DLF_FDW and restarts the instance in the background. After the instance restarts, you can use the service.
NoteHologres is rolling out self-service configuration for the DLF_FDW backend in the console. If you do not see the Data Lake Acceleration button, follow the instructions in Common upgrade preparation errors or join the Hologres DingTalk group for support. For more information, see How to obtain online support?.
After enabling DLF_FDW, the system uses default resources (currently 1 core and 4 GB memory). No additional resources need to be purchased.
Create an extension.
A Superuser must run the following statement in the database to create the extension, which enables reading OSS data through DLF 1.0. This operation applies to the entire database and needs to be performed only once per database.
CREATE EXTENSION IF NOT EXISTS dlf_fdw;You can create an external server.
ImportantYou must use a Superuser account to create the foreign server. Otherwise, permission errors will occur.
Hologres supports the DLF 1.0 multi-catalog feature. If you have only one EMR cluster, use the DLF 1.0 default catalog. If you have multiple EMR clusters, use a custom catalog to control which EMR cluster your Hologres instance connects to. You can also choose native OSS or OSS-HDFS as your data source. Configure as follows:
Create a server using the DLF 1.0 default catalog and native OSS storage. Example syntax:
-- View existing servers. The meta_warehouse_server and odps_server servers are built-in system servers and cannot be modified or deleted. SELECT * FROM pg_foreign_server; -- Delete an existing server. DROP SERVER SERVER_NAME CASCADE; -- Create a server. CREATE SERVER IF NOT EXISTS SERVER_NAME FOREIGN DATA WRAPPER dlf_fdw OPTIONS ( dlf_region '<span class="var-span" contenteditable="true" data-var="REGION_ID">REGION_ID</span>', dlf_endpoint 'dlf-share.<span class="var-span" contenteditable="true" data-var="REGION_ID">REGION_ID</span>.aliyuncs.com', oss_endpoint 'oss-<span class="var-span" contenteditable="true" data-var="REGION_ID">REGION_ID</span>-internal.aliyuncs.com' );Use OSS-HDFS as your data lake storage.
Determine the OSS-HDFS endpoint (region node).
To access data stored in OSS-HDFS through DLF_FDW, configure the OSS-HDFS service domain name. You can find this domain name on the Overview page of your OSS-HDFS-enabled bucket in the OSS console.
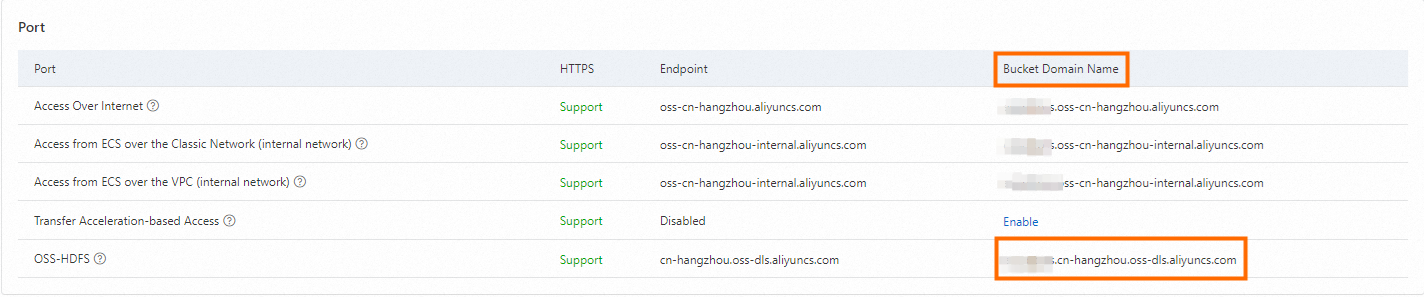
Create a foreign server and configure the endpoint.
After confirming the bucket domain name, configure the DLF_FDW OSS_Endpoint option in Hologres. Example syntax:
CREATE EXTENSION IF NOT EXISTS dlf_fdw; CREATE SERVER IF NOT EXISTS SERVER_NAME FOREIGN DATA WRAPPER dlf_fdw OPTIONS ( dlf_region '<span class="var-span" contenteditable="true" data-var="REGION_ID">REGION_ID</span>', dlf_endpoint 'dlf-share.<span class="var-span" contenteditable="true" data-var="REGION_ID">REGION_ID</span>.aliyuncs.com', oss_endpoint '<span class="var-span" contenteditable="true" data-var="BUCKET_NAME">BUCKET_NAME</span>.<span class="var-span" contenteditable="true" data-var="REGION_ID">REGION_ID</span>.oss-dls.aliyuncs.com' -- Domain name of the OSS-HDFS bucket endpoint node );Parameter descriptions.
Parameter
Description
Example
SERVER_NAME
Custom server name.
dlf_server
dlf_region
Region where DLF 1.0 is located. Select based on your region:
China (Beijing):
cn-beijing.China (Hangzhou):
cn-hangzhou.China (Shanghai):
cn-shanghai.China (Shenzhen):
cn-shenzhen.China (Zhangjiakou):
cn-zhangjiakou.Singapore:
ap-southeast-1.Germany (Frankfurt):
eu-central-1.US (Virginia):
us-east-1.Indonesia (Jakarta):
ap-southeast-5.
cn-hangzhou
dlf_endpoint
Use the internal DLF 1.0 service endpoint for better access performance.
China (Beijing):
dlf-share.cn-beijing.aliyuncs.com.China (Hangzhou):
dlf-share.cn-hangzhou.aliyuncs.comChina (Shanghai):
dlf-share.cn-shanghai.aliyuncs.com.China (Shenzhen):
dlf-share.cn-shenzhen.aliyuncs.com.China (Zhangjiakou):
dlf-share.cn-zhangjiakou.aliyuncs.com.Singapore:
dlf-share.ap-southeast-1.aliyuncs.com.Germany (Frankfurt):
dlf-share.eu-central-1.aliyuncs.com.US (Virginia):
dlf-share.us-east-1.aliyuncs.com.Indonesia (Jakarta):
dlf-share.ap-southeast-5.aliyuncs.com.
dlf-share.cn-shanghai.aliyuncs.comoss_endpoint
For native OSS storage, use the OSS internal endpoint for better access performance.
OSS-HDFS supports only internal network access.
OSS
oss-cn-shanghai-internal.aliyuncs.comOSS-HDFS
cn-hangzhou.oss-dls.aliyuncs.com
(Optional) Create a user mapping.
Hologres supports using the
CREATE USER MAPPINGcommand to specify another user identity for accessing DLF 1.0 and OSS. For example, the owner of a foreign server can useCREATE USER MAPPINGto let RAM user 123xxx access OSS external data.Ensure the specified account has query permissions for the corresponding external data. For details, see postgres create user mapping.
CREATE USER MAPPING FOR ACCOUNT_UID SERVER SERVER_NAME OPTIONS ( dlf_access_id 'YOUR_ACCESS_KEY', dlf_access_key 'YOUR_ACCESS_SECRET', oss_access_id 'YOUR_ACCESS_KEY', oss_access_key 'YOUR_ACCESS_SECRET' );Examples:
-- Create a user mapping for the current user CREATE USER MAPPING FOR current_user SERVER SERVER_NAME OPTIONS ( dlf_access_id 'YOUR_ACCESS_KEY', dlf_access_key 'YOUR_ACCESS_SECRET', oss_access_id 'YOUR_ACCESS_KEY', oss_access_key 'YOUR_ACCESS_SECRET' ); -- Create a user mapping for RAM user 123xxx CREATE USER MAPPING FOR "p4_123xxx" SERVER SERVER_NAME OPTIONS ( dlf_access_id 'YOUR_ACCESS_KEY', dlf_access_key 'YOUR_ACCESS_SECRET', oss_access_id 'YOUR_ACCESS_KEY', oss_access_key 'YOUR_ACCESS_SECRET' ); -- Delete user mappings DROP USER MAPPING FOR current_user SERVER SERVER_NAME; DROP USER MAPPING FOR "p4_123xxx" SERVER SERVER_NAME;
Read OSS lake data
Use DLF 1.0 as the data source. First, create a metadata table in DLF 1.0 and ensure that data has been extracted. Then, follow these steps to access OSS data through DLF 1.0 in Hologres using foreign tables:
Create foreign tables in your Hologres instance.
After creating the server, use CREATE FOREIGN TABLE to create a single foreign table or IMPORT FOREIGN SCHEMA to create foreign tables individually or in bulk for reading OSS data extracted by DLF 1.0.
NoteIf an OSS foreign table has the same name as an existing Hologres internal table, IMPORT FOREIGN SCHEMA skips creating that foreign table. Use CREATE FOREIGN TABLE to define a non-duplicate table name.
Hologres supports reading partitioned tables in OSS. Supported data types for partition keys are TEXT, VARCHAR, and INT. With CREATE FOREIGN TABLE, which only performs field mapping without storing data, create partition fields as regular fields. With IMPORT FOREIGN SCHEMA, field mapping is handled automatically—no manual field configuration is needed.
Syntax examples
-- Method 1 CREATE FOREIGN TABLE [ IF NOT EXISTS ] oss_table_name ( [ { column_name data_type } [, ... ] ] ) SERVER SERVER_NAME OPTIONS ( schema_name 'DLF_DATABASE_NAME', table_name 'DLF_TABLE_NAME' ); -- Method 2 IMPORT FOREIGN SCHEMA schema_name [ { limit to | except } ( table_name [, ...] ) ] from server SERVER_NAME into local_schema [ options ( option 'value' [, ... ] ) ]Parameter descriptions
Parameter
Description
schema_name
Name of the metadatabase created in DLF 1.0.
table_name
Name of the metadata table created in DLF 1.0.
SERVER_NAME
Name of the server created in Hologres.
local_schema
Schema name in Hologres.
options
Option parameter values for IMPORT FOREIGN SCHEMA. For more information, see IMPORT FOREIGN SCHEMA.
Examples.
Create individually.
Create a foreign table that maps data from the metadata table dlf_oss_test in the DLF 1.0 metadatabase dlfpro. The table resides in the public schema in Hologres. Check if the foreign table already exists and update it if it does.
-- Method 1 CREATE FOREIGN TABLE dlf_oss_test_ext ( id text, pt text ) SERVER SERVER_NAME OPTIONS ( schema_name 'dlfpro', table_name 'dlf_oss_test' ); -- Method 2 IMPORT FOREIGN SCHEMA dlfpro LIMIT TO ( dlf_oss_test ) FROM SERVER SERVER_NAME INTO public options (if_table_exist 'update');Create multiple instances at once.
Map all tables from the DLF 1.0 metadatabase dlfpro to the public schema in Hologres. This creates multiple foreign tables in Hologres with the same names as those in dlfpro.
Import entire database.
IMPORT FOREIGN SCHEMA dlfpro FROM SERVER SERVER_NAME INTO public options (if_table_exist 'update');Import multiple tables.
IMPORT FOREIGN SCHEMA dlfpro ( table1, table2, tablen ) FROM SERVER SERVER_NAME INTO public options (if_table_exist 'update');
Query data.
After successfully creating foreign tables, query them directly to read data from OSS.
Non-partitioned table
SELECT * FROM dlf_oss_test;Partitioned table
SELECT * FROM partition_table WHERE dt = '2013';
What to do next
To import OSS data into a Hologres internal table for direct querying and better performance, see Import data from a data lake using SQL.
To write data from a Hologres internal table back to an OSS data lake and query it using an external engine, see Export to a data lake.
FAQ
When creating a DLF 1.0 foreign table, you receive the error: ERROR: babysitter not ready,req:name:"HiveAccess".
Cause.
No backend configuration has been added.
Solution.
In the console, go to the Instances page and click Data Lake Acceleration to enable backend configuration.