This topic describes how to import data from a partitioned MaxCompute table to a partitioned Hologres table.
Prerequisites
A Hologres instance is purchased. For more information, see Purchase a Hologres instance.
MaxCompute is activated. A MaxCompute project is created. For more information about how to activate MaxCompute, see Activate MaxCompute and DataWorks.
DataWorks is activated. A DataWorks workspace is created. For more information about how to create a DataWorks workspace, see Create a workspace.
Background information
Foreign tables in Hologres are widely used to import data from MaxCompute to Hologres. Data import is often required in daily work. In this case, you can use the powerful scheduling and job orchestration capabilities of DataWorks to implement periodic scheduling and configure an auto triggered workflow to import data. For more information, see Sample DataWorks workflow.
The workflow is complex. Therefore, you can use the Migration Assistant service of DataWorks to import the package of the sample DataWorks workflow to your workspace to create a workflow. Then, you can modify some parameters or scripts based on your business requirements. For more information, see Use the Migration Assistant service to import a DataWorks workflow.
Precautions
Temporary tables are used to ensure the atomicity of operations. Temporary tables are attached to a partitioned table only after the table data is imported. In this case, you do not need to delete the tables if the data fails to be imported.
In the scenario in which the data in an existing child partitioned table is to be updated, you must place the deletion of the child partitioned table and the attachment of a temporary table in a transaction to ensure the atomicity, consistency, isolation, durability (ACID) properties of the transaction.
Prerequisites for using the Migration Assistant service to import a DataWorks workflow:
DataWorks Standard Edition or a more advanced edition is activated. For more information, see Differences among DataWorks editions.
MaxCompute and Hologres data sources are added to the DataWorks workspace. For more information, see Create and manage workspaces.
Procedure
Prepare MaxCompute data.
Log on to the MaxCompute console.
In the left-side navigation pane, click Data Analytics.
On the SQL Query page, enter the following SQL statements and click the Run icon to create a partitioned table:
DROP TABLE IF EXISTS odps_sale_detail; -- Create a partitioned table named odps_sale_detail. CREATE TABLE IF NOT EXISTS odps_sale_detail ( shop_name STRING ,customer_id STRING ,total_price DOUBLE ) PARTITIONED BY ( sale_date STRING ) ;On the SQL Query page, enter the following SQL statements and click the Run icon to import data to the partitioned table:
-- Create the 20210815 partition in the partitioned table. ALTER TABLE odps_sale_detail ADD IF NOT EXISTS PARTITION(sale_date='20210815') ; -- Import data to the 20210815 partition. INSERT OVERWRITE TABLE odps_sale_detail PARTITION(sale_date='20210815') VALUES ('s1','c1',100.1), ('s2','c2',100.2), ('s3','c3',100.3) ; -- Create the 20210816 partition in the partitioned table. ALTER TABLE odps_sale_detail ADD IF NOT EXISTS PARTITION(sale_date='20210816') ; -- Import data to the 20210815 partition. INSERT OVERWRITE TABLE odps_sale_detail PARTITION(sale_date='20210816') VALUES ('s1','c1',100.1), ('s2','c2',100.2), ('s3','c3',100.3) ; -- Create the 20210817 partition in the partitioned table. ALTER TABLE odps_sale_detail ADD IF NOT EXISTS PARTITION(sale_date='20210817') ; -- Import data to the 20210815 partition. INSERT OVERWRITE TABLE odps_sale_detail PARTITION(sale_date='20210817') VALUES ('s1','c1',100.1), ('s2','c2',100.2), ('s3','c3',100.3) ; -- Create the 20210818 partition in the partitioned table. ALTER TABLE odps_sale_detail ADD IF NOT EXISTS PARTITION(sale_date='20210818') ; -- Import data to the 20210815 partition. INSERT OVERWRITE TABLE odps_sale_detail PARTITION(sale_date='20210818') VALUES ('s1','c1',100.1), ('s2','c2',100.2), ('s3','c3',100.3) ;
Create tables in Hologres.
Create a foreign table.
Log on to the database.
On the Database Authorization page of the HoloWeb console, click Metadata Management in the top navigation bar.
On the Metadata Management tab, find the created database in the left-side navigation pane and double-click the database name. In the dialog box that appears, click OK.
Create a foreign table.
In the upper-left corner of the SQL Editor tab, click the
 icon.
icon. On the Ad-hoc Query tab, select an instance from the Instance drop-down list and a database from the Database drop-down list, enter the following sample statements in the SQL editor, and then click Run:
DROP FOREIGN TABLE IF EXISTS odps_sale_detail; -- Create a foreign table. IMPORT FOREIGN SCHEMA maxcompute_project LIMIT to ( odps_sale_detail ) FROM SERVER odps_server INTO public OPTIONS(if_table_exist 'error',if_unsupported_type 'error');
Create an internal partitioned table.
Log on to the database.
On the Database Authorization page of the HoloWeb console, click Metadata Management in the top navigation bar.
On the Metadata Management tab, find the created database in the left-side navigation pane and double-click the database name. In the dialog box that appears, click OK.
Create a partitioned table.
In the upper-left corner of the SQL Editor tab, click the
icon. On the Ad-hoc Query tab, select an instance from the Instance drop-down list and a database from the Database drop-down list, enter the following sample statements in the SQL editor, and then click Run:
DROP TABLE IF EXISTS holo_sale_detail; -- Create an internal partitioned table in Hologres. BEGIN ; CREATE TABLE IF NOT EXISTS holo_sale_detail ( shop_name TEXT ,customer_id TEXT ,total_price FLOAT8 ,sale_date TEXT ) PARTITION BY LIST(sale_date); COMMIT;
Import data from a partition to a Hologres temporary table.
On the Ad-hoc Query tab, enter the following sample statements in the SQL editor and click Run.
The following SQL statements are used to import the data of the 20210816 partition of the partitioned table odps_sale_detail in the MaxCompute project hologres_test to the 20210816 partition of the partitioned table holo_sale_detail in Hologres:
NoteHologres V2.1.17 and later support the Serverless Computing feature. The Serverless Computing feature is suitable for scenarios in which you want to import a large amount of data offline, run large-scale extract, transform, and load (ETL) jobs, or query a large amount of data from foreign tables. You can use the Serverless Computing feature to perform the preceding operations based on additional serverless computing resources. This can eliminate the need to reserve additional computing resources for the instances. This improves instance stability and reduces the occurrences of out of memory (OOM) errors. You are charged only for the additional serverless computing resources used by tasks. For more information about the Serverless Computing feature, see Overview of Serverless Computing. For more information about how to use the Serverless Computing feature, see User guide on Serverless Computing.
-- Drop an existing temporary table. BEGIN ; DROP TABLE IF EXISTS holo_sale_detail_tmp_20210816; COMMIT ; -- Create a temporary table. SET hg_experimental_enable_create_table_like_properties=on; BEGIN ; CALL HG_CREATE_TABLE_LIKE ('holo_sale_detail_tmp_20210816', 'select * from holo_sale_detail'); COMMIT; -- Optional. We recommend that you use the Serverless Computing feature to import a large amount of data offline and run ETL jobs. SET hg_computing_resource = 'serverless'; -- Insert data into the temporary table. INSERT INTO holo_sale_detail_tmp_20210816 SELECT * FROM public.odps_sale_detail WHERE sale_date='20210816'; -- Reset the configurations. This ensures that serverless computing resources are not used for subsequent SQL statements. RESET hg_computing_resource;Attach the temporary table to the partitioned Hologres table.
On the Ad-hoc Query tab, enter the following sample statements in the SQL editor and click Run.
If a child table that corresponds to a specific partition exists, delete the existing child table before you attach the temporary table to the Hologres partitioned table.
The following SQL statements are used to delete the existing child partitioned table holo_sale_detail_20210816 and attach the temporary table holo_sale_detail_tmp_20210816 to the 20210816 partition of the partitioned table holo_sale_detail:
-- If a child partitioned table that corresponds to a specific partition exists, replace the child partitioned table. BEGIN ; -- Drop the existing child partitioned table. DROP TABLE IF EXISTS holo_sale_detail_20210816; -- Rename the temporary table. ALTER TABLE holo_sale_detail_tmp_20210816 RENAME TO holo_sale_detail_20210816; -- Attach the temporary table to the partitioned Hologres table. ALTER TABLE holo_sale_detail ATTACH PARTITION holo_sale_detail_20210816 FOR VALUES IN ('20210816') ; COMMIT ;If no child partitioned table that corresponds to a specific partition exists, attach the temporary table to the Hologres partitioned table.
The following SQL statements are used to attach the temporary table holo_sale_detail_tmp_20210816 to the 20210816 partition of the partitioned table holo_sale_detail:
BEGIN ; -- Rename the temporary table. ALTER TABLE holo_sale_detail_tmp_20210816 RENAME TO holo_sale_detail_20210816; -- Attach the temporary table to the partitioned Hologres table. ALTER TABLE holo_sale_detail ATTACH PARTITION holo_sale_detail_20210816 FOR VALUES IN ('20210816'); COMMIT ;
Collect statistics on the partitioned Hologres table.
On the Ad-hoc Query tab, enter the following sample statements in the SQL editor and click Run.
The following SQL statement is used to collect statistics on the partitioned table holo_sale_detail and verify the execution plan of the partitioned table. You need to collect statistics only on the parent partitioned table.
-- Collect statistics on the parent partitioned table after a large amount of data is imported. ANALYZE holo_sale_detail;Optional. Delete the child partitioned tables that correspond to expired partitions.
In the production environment, data has a time-to-live (TTL) period. You must delete the child partitioned tables that correspond to expired partitions.
On the Ad-hoc Query tab, enter the following sample statements in the SQL editor and click Run.
The following SQL statement is used to delete the child partitioned table that corresponds to the 20210631 partition:
DROP TABLE IF EXISTS holo_sale_detail_20210631;
Sample DataWorks workflow
In daily work, you need to periodically execute the preceding SQL statements. In this case, you can use the powerful scheduling and job orchestration capabilities of DataWorks to implement periodic scheduling and configure an auto triggered workflow to import data. The following content can help you modify some parameters or scripts based on your business requirements when you use the Migration Assistant service to import a DataWorks workflow.
Nodes in the workflow
Basic parameters
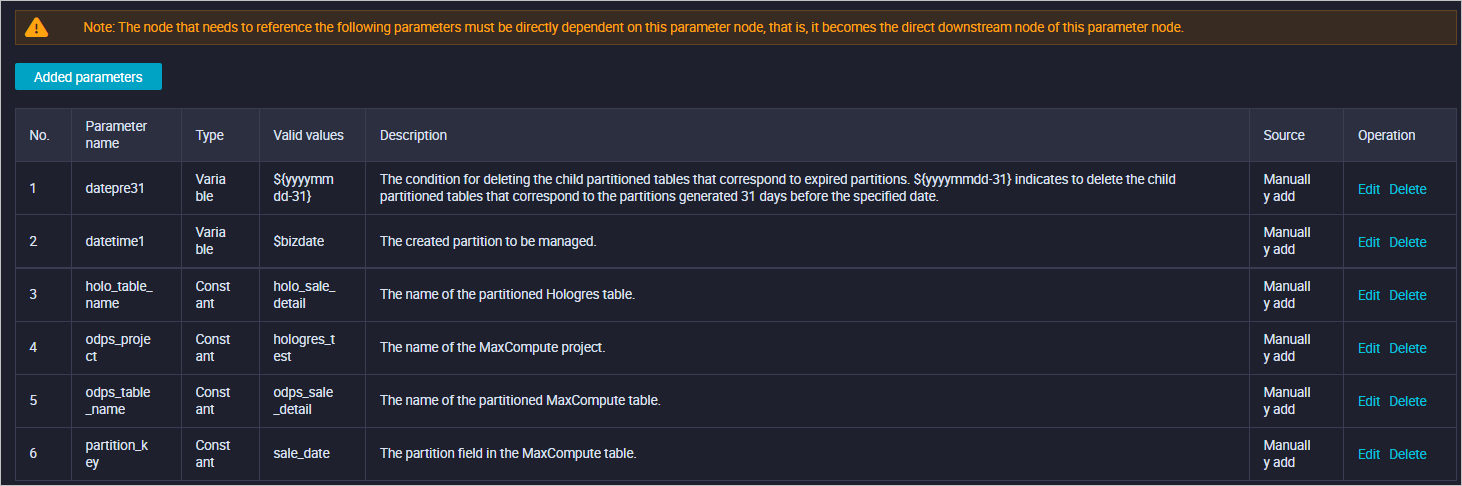
Basic parameters are used to manage all parameters used in the entire workflow. The following table describes the basic parameters.
No.
Parameter
Type
Valid value
Description
1
datepre31
Variable
${yyyymmdd-31}
The condition for deleting the child partitioned tables that correspond to expired partitions. ${yyyymmdd-31} indicates to delete the child partitioned tables that correspond to the partitions generated 31 days before the specified date.
2
datetime1
Variable
$bizdate
The created partition to be managed.
3
holo_table_name
Constant
holo_sale_detail
The name of the partitioned Hologres table.
4
odps_project
Constant
hologres_test
The name of the MaxCompute project.
5
odps_table_name
Constant
odps_sale_detail
The name of the partitioned MaxCompute table.
6
partition_key
Constant
sale_date
The partition field in the MaxCompute table.
The following figure shows the system configuration of the basic parameters.
Import the data of a specific partition to a temporary table.
This is a Hologres SQL node, which contains the following SQL statements:
NoteHologres V2.1.17 and later support the Serverless Computing feature. The Serverless Computing feature is suitable for scenarios in which you want to import a large amount of data offline, run large-scale extract, transform, and load (ETL) jobs, or query a large amount of data from foreign tables. You can use the Serverless Computing feature to perform the preceding operations based on additional serverless computing resources. This can eliminate the need to reserve additional computing resources for the instances. This improves instance stability and reduces the occurrences of out of memory (OOM) errors. You are charged only for the additional serverless computing resources used by tasks. For more information about the Serverless Computing feature, see Overview of Serverless Computing. For more information about how to use the Serverless Computing feature, see User guide on Serverless Computing.
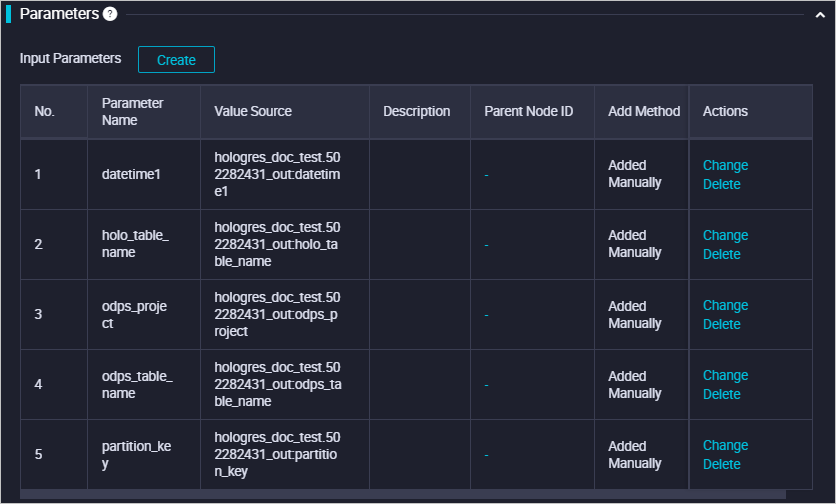
-- Drop an existing temporary table. BEGIN ; DROP TABLE IF EXISTS ${holo_table_name}_tmp_${datetime1}; COMMIT ; -- Create a temporary table. SET hg_experimental_enable_create_table_like_properties=on; BEGIN ; CALL HG_CREATE_TABLE_LIKE ('${holo_table_name}_tmp_${datetime1}', 'select * from ${holo_table_name}'); COMMIT; -- Insert data into the temporary table. -- Optional. We recommend that you use the Serverless Computing feature to import a large amount of data offline and run ETL jobs. SET hg_computing_resource = 'serverless'; INSERT INTO ${holo_table_name}_tmp_${datetime1} SELECT * FROM public.${odps_table_name} WHERE ${partition_key}='${datetime1}'; -- Reset the configurations. This ensures that serverless computing resources are not used for subsequent SQL statements. RESET hg_computing_resource;Associate the basic parameters with the ancestor node of this node to control the variables in the basic parameters. The following figure shows the system configuration.
Replace the child partitioned table that corresponds to a specific partition.
This is a Hologres SQL node used to update data if a child partitioned table that corresponds to the partition exists. Place the replacement of the child partitioned table in a transaction to ensure the ACID properties of the transaction. The node contains the following SQL statements:
-- If a child partitioned table that corresponds to a specific partition exists, replace the child partitioned table. BEGIN ; -- Drop the existing child partitioned table. DROP TABLE IF EXISTS ${holo_table_name}_${datetime1}; -- Rename the temporary table. ALTER TABLE ${holo_table_name}_tmp_${datetime1} RENAME TO ${holo_table_name}_${datetime1}; -- Attach the temporary table to the partitioned Hologres table. ALTER TABLE ${holo_table_name} ATTACH PARTITION ${holo_table_name}_${datetime1} FOR VALUES IN ('${datetime1}'); COMMIT ;Associate the basic parameters with the ancestor node of this node to control the variables in the basic parameters. The following figure shows the system configuration.
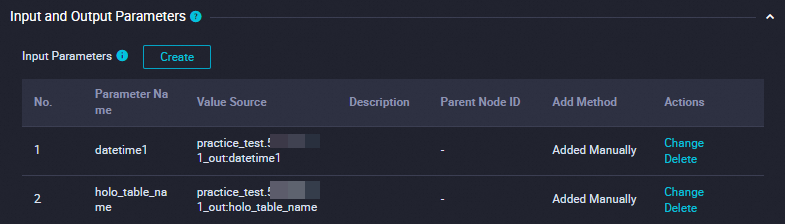
Collect statistics on the partitioned table.
This is a Hologres SQL node used to collect statistics on the parent partitioned table. The node contains the following SQL statements:
-- Collect statistics on the parent partitioned table after a large amount of data is imported. ANALYZE ${holo_table_name};Associate the basic parameters with the ancestor node of this node to control the variables in the basic parameters. The following figure shows the system configuration.
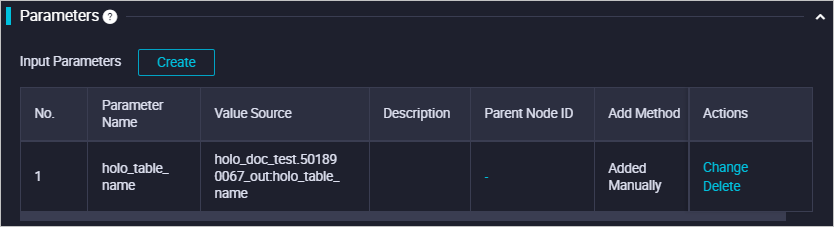
Drop the child partitioned tables that correspond to expired partitions.
In the production environment, data has a TTL period. You must delete the child partitioned tables that correspond to expired partitions.
For example, you want to store the child partitioned tables that correspond to the partitions generated only in the last 31 days in Hologres, and the datepre31 parameter is set to ${yyyymmdd-31}. In this case, the node used to delete the child partitioned tables that correspond to expired partitions contains the following SQL statements:
-- Drop the child partitioned tables that correspond to expired partitions. BEGIN ; DROP TABLE IF EXISTS ${holo_table_name}_${datepre31}; COMMIT ;When the workflow is running, if the value of the bizdate parameter is 20200309, the value of the datepre31 parameter is 20200207. In this case, the child partitioned tables that correspond to the partitions generated before February 7, 2020 are deleted.
Associate the basic parameters with the ancestor node of this node to control the variables in the basic parameters. The following figure shows the system configuration.
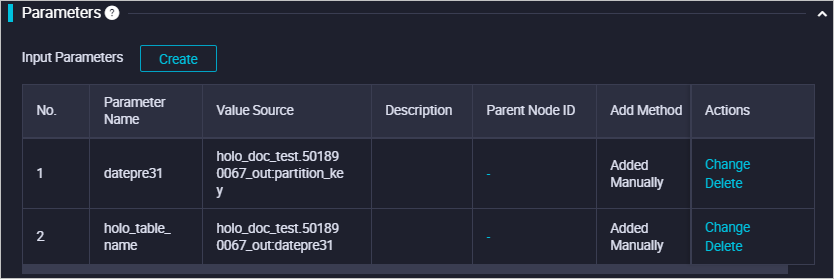
Use the Migration Assistant service to import a DataWorks workflow
The preceding DataWorks workflow is complex. Therefore, you can use the Migration Assistant service of DataWorks to import the package of the sample DataWorks workflow into your project to obtain the sample DataWorks workflow. Then, you can modify some parameters or scripts based on your business requirements.
Before you perform the following steps, download the package of the sample DataWorks workflow.
Go to the Migration Assistant homepage in DataWorks. For more information, see Go to the Migration Assistant page.
In the left-side navigation pane of the Migration Assistant page, choose .
In the upper-right corner of the DataWorks import page, click Create Import Task.
In the Create Import Task dialog box, configure the parameters.
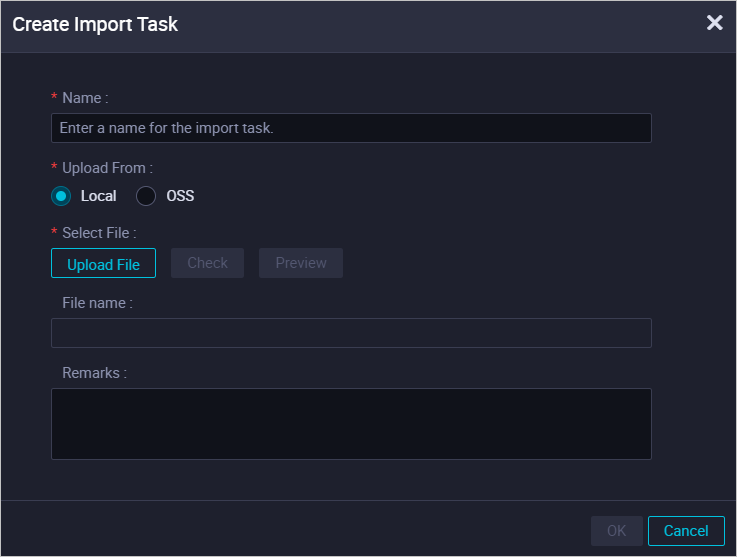
Parameter
Description
Name
Specify a custom name. The name can contain letters, digits, underscores (_), and periods (.).
Upload From
The source of the package that you want to upload.
Local: Upload the package from your computer to the DataWorks workspace if the package is less than or equal to 30 MB in size.
OSS: Upload the package to Object Storage Service (OSS) and specify the OSS URL of the package if the package exceeds 30 MB in size. You can copy the OSS URL in the View Details panel of the package in the OSS console and specify the obtained OSS URL to upload the package to the DataWorks workspace. For more information about how to upload objects to OSS, see Upload objects. For more information about how to obtain the OSS URL of an object, see Share objects.
Remarks
The description of the import task.
Click OK. On the Import Task Settings page, configure mappings.
Click Import in the upper-right corner. In the Confirm message, click OK.
After the package is imported, the preceding auto triggered workflow appears in DataStudio.
Relevant DDL statements appear in the manually triggered workflow.