Realtime Compute for Apache Flink stores intermediate calculation results from an SQL deployment as state data, including checkpoints and savepoints. When you modify a deployment and restart it using existing state data, the deployment may become incompatible with that state data.
Starting from engine version vvr-4.0.11-flink-1.13, Realtime Compute for Apache Flink provides two capabilities to address this:
-
State data compatibility check: Detects whether existing state data is compatible with the updated deployment before you restart.
-
State data migration: Adapts incompatible state data to the new deployment so you can maximize reuse of existing state.
Compatibility check
When you select Resume Mode in the Start Job panel, the system automatically detects changes to SQL statements, runtime parameters, and the engine version. If changes are detected, click Click to detect next to State Compatibility to run a compatibility check before starting the deployment.
Always check state compatibility before starting a modified deployment in Resume Mode. Only proceed if the result confirms compatibility.
Check results
The check returns one of four results:
| Result | What it means | What to do |
|---|---|---|
| Fully compatible | The deployment produces the same results as it would from historical data | Start the deployment |
| Partially compatible | Only specific columns have matching state data; the rest have no state, causing partial inconsistency | Start based on other states or without states |
| Incompatible | High probability of startup failure or unexpected results | Start based on other states or without states |
| Compatibility to be determined after a restart (compatibility unknown) | The deployment may fail to start or produce unexpected results | Proceed with caution |
State data migration
When state data is not fully compatible, Realtime Compute for Apache Flink migrates the state data to fit the updated deployment. The migration behavior differs between the two supported state backends: RocksDB and Gemini.
RocksDB
RocksDB uses eager migration: all state data is migrated when the deployment starts.
-
The deployment enters the RUNNING state immediately after startup.
-
Operators with state to migrate are in the INITIALIZING state — they cannot consume or process data during this phase.
-
After migration completes, the operators enter the RUNNING state and begin processing data.
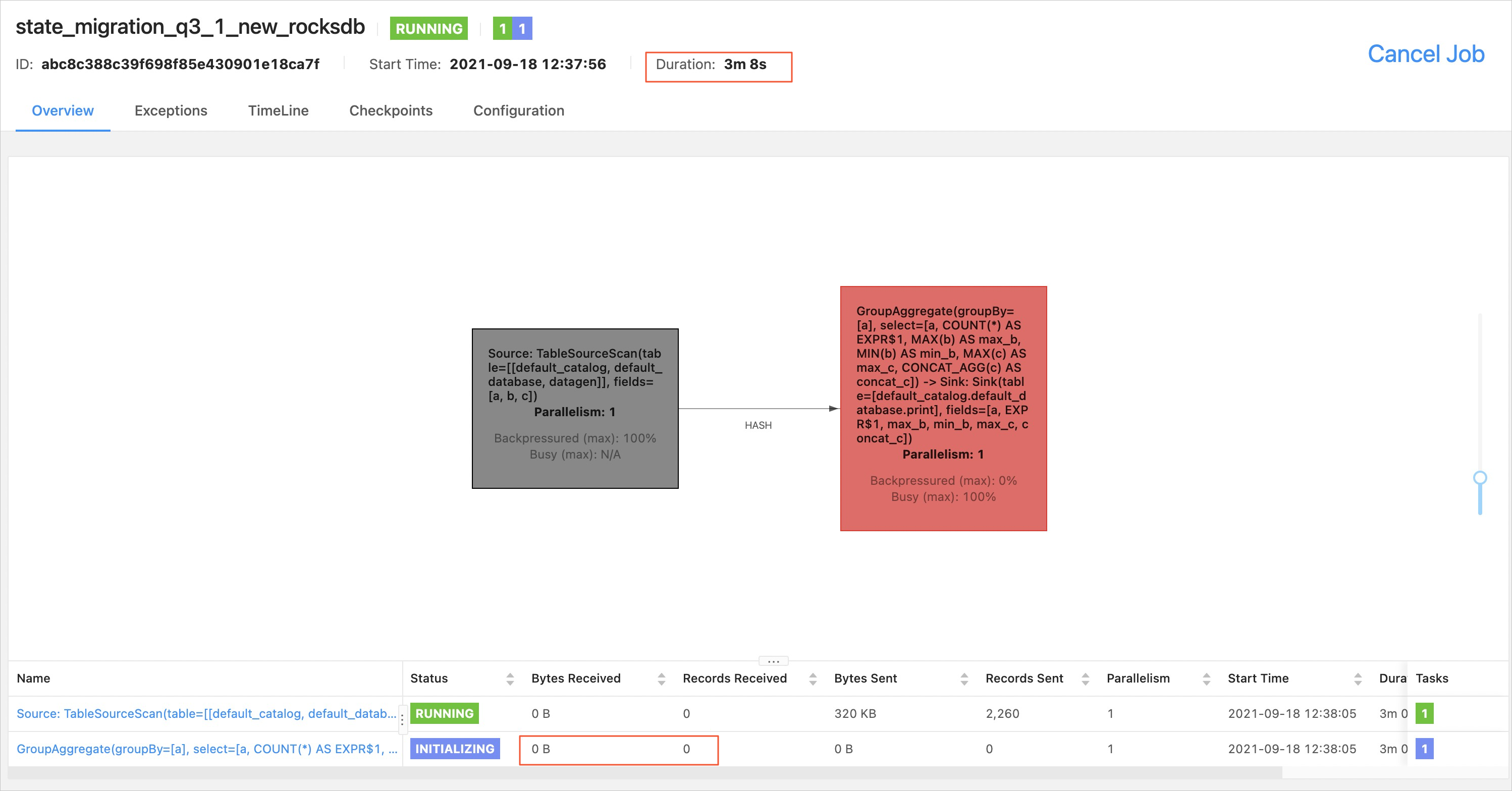
In this example, an aggregate function was modified, so RocksDB migrates all state data at startup. The GroupAggregate operator remains in INITIALIZING until migration finishes.
Gemini
Gemini uses lazy migration: state data is migrated on demand as the deployment runs.
-
A specific state data record is migrated only when it is first accessed.
-
After startup, operators quickly transition from INITIALIZING to RUNNING and begin processing data.
-
Migration completes progressively in the background. Watch the transactions per second (TPS) metric — when TPS returns to its normal level, all state data has been migrated.
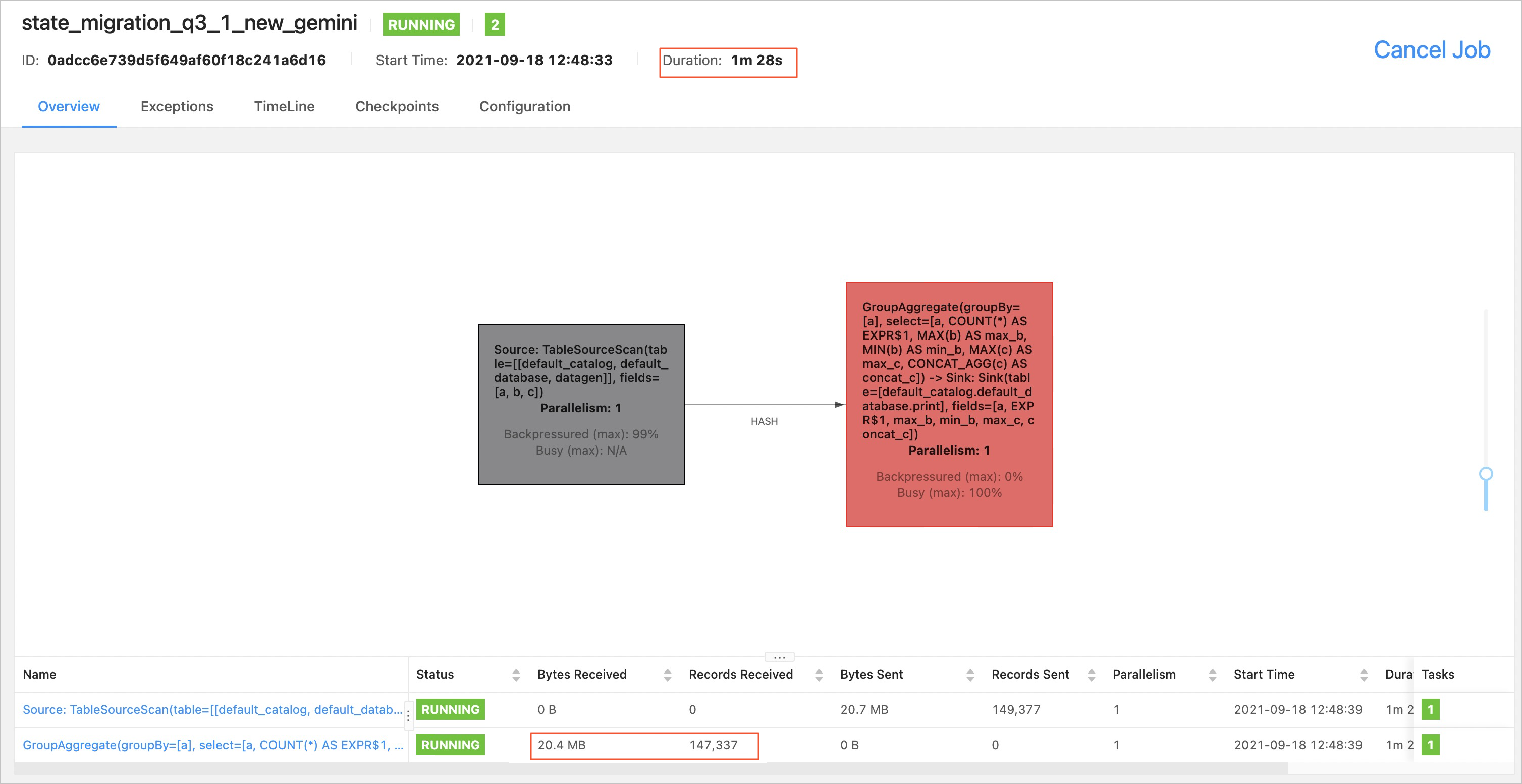
When migrating the same SQL deployment, Gemini reaches the RUNNING state faster than RocksDB. The INITIALIZING state indicates that the operator is loading data.
Comparison
| Aspect | RocksDB | Gemini |
|---|---|---|
| Migration timing | All state migrated at startup (eager) | State migrated on first access (lazy) |
| Time to start processing data | Longer — operators stay in INITIALIZING until migration is complete | Shorter — operators move to RUNNING quickly |
| Migration completion signal | Operators enter RUNNING state | TPS returns to the normal level |