The namespace clone feature lets you quickly copy entities and configurations from a source namespace to a target namespace within the same region. This reduces repetitive development work, improves resource utilization, and provides a cold backup for disaster recovery. This topic covers the use cases, procedure, and important considerations for cloning a namespace.
Use cases
Category | Use case | Recommendation |
Data backup |
|
|
Resource cloning and sharing |
|
|
Storage and data migration |
| Storage permissions: To clone from OSS storage to fully managed storage, you must grant read-only permissions (including the ListObject action) on the namespace's associated bucket to the fully managed account |
Limitations
Region restriction: Cloning is supported only for namespaces within the same region. Cross-region operations are not supported.
Cloning scope: You can only clone namespaces, not entire workspaces.
Excluded content: Task orchestration, queues, permissions, and alert configurations are not cloned.
Version policy: Only the latest draft from the development environment and the deployment from the operations environment are cloned. Historical versions of drafts are ignored.
Concurrent operations: You cannot clone one source namespace to multiple targets, or multiple source namespaces to one target, simultaneously.
Storage compatibility: If the source workspace uses fully managed storage, the target workspace must also. You cannot select a workspace that uses OSS as the target.
Architecture compatibility: Cloning is supported only between namespaces with the same architecture. Cross-architecture cloning between x86 and ARM is not supported.
Stateful cloning: Cloning with state (a checkpoint or savepoint) is supported only for engine versions VVR 6.0.2 and later.
Considerations
Permissions
To initiate a clone, you must have the Editor role for both the source and target namespaces. The system uses this user's identity for end-to-end authentication. For more information, see Authorize users in the development console.
Cloning restrictions
Resource lock: You cannot change resource configurations during the cloning process.
Irreversible operation: The clone operation cannot be undone. If you stop the process, you must manually delete any resources that have already been cloned.
Avoid duplication: Cloning to the same target namespace multiple times results in duplicate resources.
Storage permissions: To clone from OSS storage to fully managed storage, you must grant read-only permissions (including the ListObject action) on the namespace's associated bucket to the fully managed account
arn:sts::1060219998962774:assumed-role/aliyunstreamasidefaultrole/refresh_token. For more information, see Set a bucket policy.
Cloned job status
When you choose to clone with state:
For completed or stopped streaming jobs, the system clones the latest snapshot or system checkpoint.
For running or transitioning streaming jobs, if you select the Do not skip policy, the system automatically creates a snapshot before cloning. However, because the job continues to run, it may generate a newer system checkpoint, so the cloned snapshot is not guaranteed to be the latest state.
Check streaming job status
In migration scenarios, stop the source job before cloning to prevent data inconsistencies from newly generated state.
Running the source job and its cloned copy simultaneously can disrupt your business logic. Ensure there is no impact before you start the cloned job.
A successful system checkpoint indicates that the cloned job is functioning correctly. Monitor its status closely.
Handle naming conflicts
The system automatically renames any entity in the target namespace that has the same name as a cloned entity. You can view a list of renamed items in the Details page of the cloning history.
Manually update configurations
Catalog names that are configured or referenced in a job are not automatically updated. You must manually modify them in the job's code and configuration to prevent failures.
Debug jobs
After cloning is complete, all cloned jobs and the session cluster are in a stopped state. A cloned job may not run correctly without adjustments, for example, if dependency configurations are missing. You can perform the following actions:
Debug the job draft.
Check if dependency files are as expected.
Adjust the job's dependency configurations.
Procedure
Prepare the source namespace, the target workspace, and the target namespace. For more information, see Activate Realtime Compute for Apache Flink or Manage namespaces.
Clone the entities and configuration information of the namespace.
Log on to the Realtime Compute for Apache Flink console.
In the More column for the workspace that contains the source namespace, select .
Configure the cloning settings.
Select the source and target namespaces.
Select the objects to clone.
You can select objects to clone as needed, such as drafts, deployments, file resources, custom catalogs, UDFs, connectors, data formats, and variable configurations.
When you clone deployments, all jobs in the current namespace are selected by default. You can filter the list to select specific jobs. Filtering is supported by job name, job type, engine version, run status, and last clone completion time.
Configure cloning policies.
Configuration
Option
Description
Streaming job state cloning policy
With state
Clones the latest snapshot or system checkpoint to prevent reprocessing of already processed data.
Stateless
Clones only the job configuration and code, without any snapshot or system checkpoint.
Running streaming job cloning policy
Skip
Skips running streaming jobs to prevent data interference from new state generated by the source job. Recommended for migrations.
Do not skip
Creates a snapshot of running streaming jobs before cloning to ensure the latest state is captured. Recommended for backups.
Error handling policy
Skip and continue
If an entity fails to clone, the failure is logged and the process continues with the remaining entities.
Stop cloning
If any entity fails to clone, the entire cloning task is immediately stopped. Data that was successfully cloned is retained.
Allow stateless cloning
If cloning with state fails, the process automatically falls back to stateless cloning and continues.
Click Start cloning.
View the cloning progress and results.
During cloning
Shortly after you click Start cloning, a notification appears. Click View cloning progress to monitor the task, which you can let run in the background.
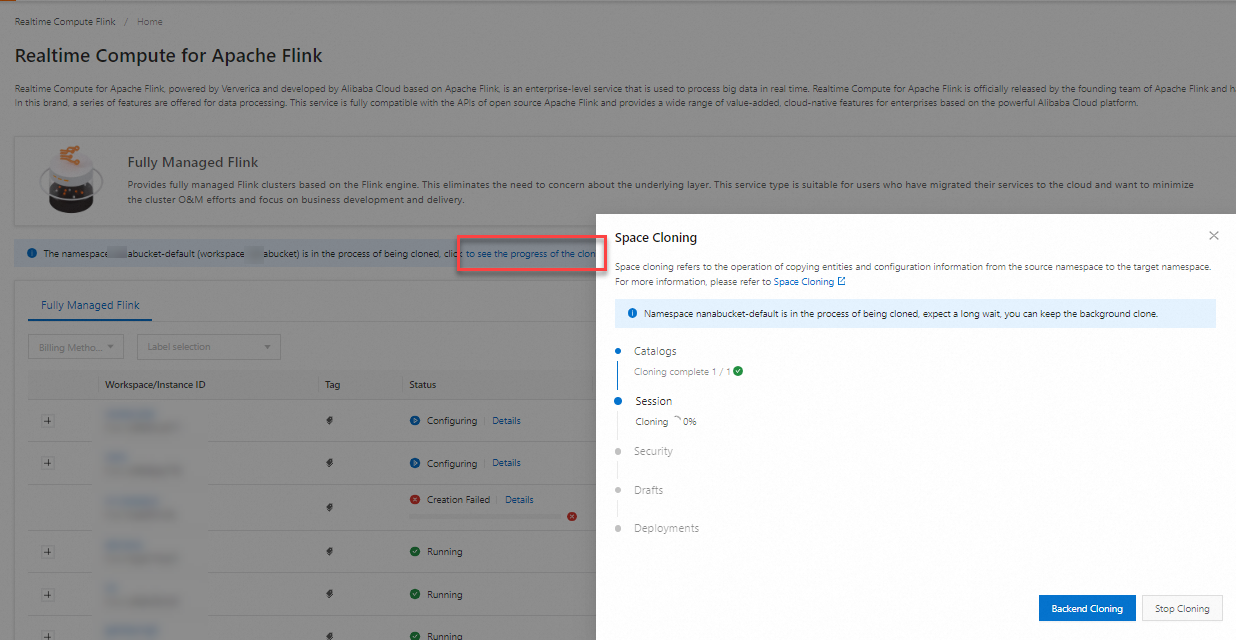
After cloning is complete
In the More column for the target workspace, select , and then click Details. You can view the categories, total count, and failure count of cloned entities. A list of renamed entities is also displayed.
Related documentation
To learn how to back up SQL and DataStream jobs, see Back up and deploy a job.