FAQ about CDC connectors in Realtime Compute for Apache Flink, covering MySQL CDC, MongoDB CDC, and PostgreSQL CDC.
Quick index
Find your issue by symptom:
| Symptom | Section |
|---|---|
| Connector stops after full data, never switches to incremental | MySQL CDC: full-to-incremental transition |
| Incremental data missing for a specific table | MySQL CDC: incremental data not syncing |
| Timestamp fields show an 8-hour offset | MySQL CDC: timestamp offset |
| High database load from multiple CDC deployments | MySQL CDC: high DB load |
| Unexpectedly high bandwidth from a small update | MySQL CDC: high bandwidth |
| Deployment fails on restart; binlog purged | Error: binlog no longer available |
| Deployment fails on restart; SSL error | Error: SSL peer shut down |
| WAL logs not released; high disk usage | PostgreSQL CDC: WAL disk usage |
| TOAST data missing from updates | PostgreSQL CDC: TOAST data missing |
| MongoDB connector cannot resume after restart | MongoDB CDC: checkpoint resume |
| Authentication fails with correct credentials | MongoDB CDC: auth failure |
| Replication slot still active after deployment ends | Error: replication slot active |
before field is null in UPDATE/DELETE events |
Error: before field null |
General
Can I configure the deployment to cancel instead of restart on failure?
Set a restart strategy in the deployment configuration. The following example limits restarts to two attempts with a 10-second interval, then cancels the deployment if both attempts fail.
restart-strategy: fixed-delay
restart-strategy.fixed-delay.attempts: 2
restart-strategy.fixed-delay.delay: 10 sMySQL CDC source tables and Hologres CDC source tables don't support window functions. How do I implement minute-level aggregation?
Use DATE_FORMAT to convert timestamps into minute-level strings, then GROUP BY on those strings. The following example computes per-store order counts and revenue every minute:
SELECT
shop_id,
DATE_FORMAT(order_ts, 'yyyy-MM-dd HH:mm') AS window,
COUNT(*) AS order_count,
SUM(price) AS amount
FROM order_mysql_cdc
GROUP BY shop_id, windowCan a MySQL CDC table be used as a dimension table or sink table?
No. A MySQL CDC table can only be used as a source table — it reads full and incremental data from MySQL. Use a regular MySQL table (not CDC) for dimension or sink use cases.
MySQL CDC
Why does the MySQL CDC connector stop after reading full data and never switch to incremental mode?
This usually has one of four causes:
-
Secondary or read-only ApsaraDB RDS for MySQL V5.6 instances: These instances do not write data to binary log files, so the connector has no incremental data to read. Use a write-capable instance or upgrade to a version later than V5.6.
-
Binary log transaction compression enabled: MySQL CDC source tables do not support binary log transaction compression. Disable this feature on self-managed MySQL clusters.
-
Out-of-memory (OOM) during full data reading: If the last shard is too large, an OOM error causes the deployment to suspend after failover. Increase parallelism to speed up full data reading.
-
Checkpoint interval too long: After all parallel subtasks finish full data reading, the connector waits for one checkpoint before switching to incremental mode. A 20-minute checkpoint interval means a 20-minute delay. Set a shorter checkpointing interval based on your requirements.
How do I confirm that full data synchronization is complete?
Two methods:
-
`currentEmitEventTimeLag` metric: On the Metrics tab of the Deployments page, check this metric. A value ≤ 0 means full sync is still in progress; a value > 0 means the connector has finished full sync and started reading binary log data.
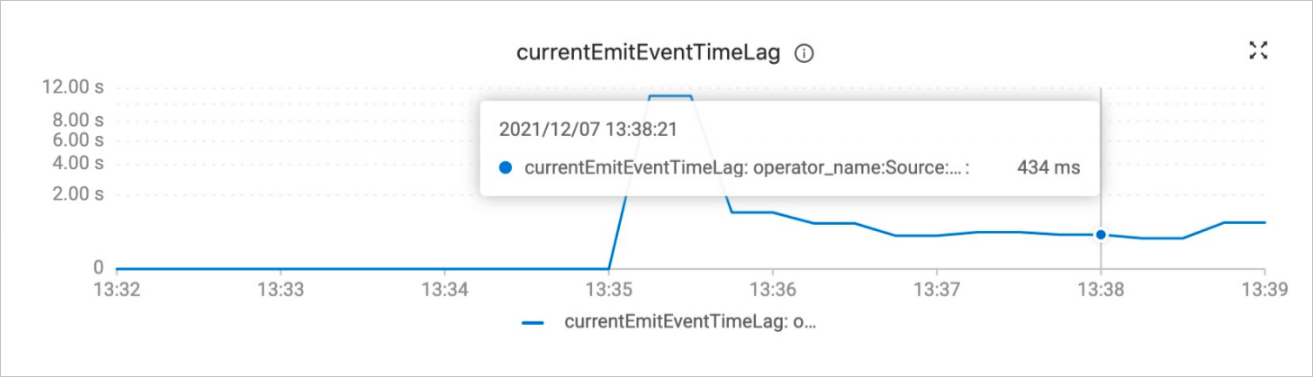
-
TaskManager log: Search for
BinlogSplitReader is createdin the TaskManager logs. This message confirms that full data reading is complete.4123 2022-01-12 05:12:52,157 [pool-6757-thread-1] INFO io.debezium.jdbc.JdbcConnection [] - Connection gracefully close... 4124 2022-01-12 05:12:52,158 [Source: TableSourceScan(table=[[vvp, default, ods_ex_trade_detail_spot_mysql_cdc ... with job vertex id 6698b6cdb93164bb0e3bb97f2a17fcd7 (1/4)#0] INFO org.apache.flink.connector.base.source.reader.SourceReaderBase [] - Adding split(s) to reader: [MySqlBinlogSplit{splitId='binlog-split', offset={ts_sec=0, file=mysql-bin.008066, pos=459422339, gtids=c32c3579-5c0d-11ec-889a-00163e368abf:1-311125098, row=0, event=0}, endOffset={ts_sec=0, file=, pos=-9223372036854775808, row=0, event=0}}] 4125 2022-01-12 05:12:52,158 [Source Data Fetcher for Source: TableSourceScan(table=[[vvp, default, ods_ex_trade_detail_spot_mysql_cdc ... with job vertex id 6698b6cdb93164bb0e3bb97f2a17fcd7 (1/4)#0] INFO org.apache.flink.connector.base.source.reader.fetcher.SplitFetcher [] - Starting split fetcher_138? 4126 2022-01-12 05:12:52,159 [Source Data Fetcher for Source: TableSourceScan(table=[[vvp, default, ods_ex_trade_detail_spot_mysql_cdc ... with job vertex id 6698b6cdb93164bb0e3bb97f2a17fcd7 (1/4)#0] INFO com.ververica.cdc.connectors.mysql.source.reader.MySqlSplitReader [] - BinlogSplitReader is created. 4127 2022-01-12 05:12:56,853 [Source Data Fetcher for Source: TableSourceScan(table=[[vvp, default, ods_ex_trade_detail_spot_mysql_cdc ... with job vertex id 6698b6cdb93164bb0e3bb97f2a17fcd7 (1/4)#0] WARN io.debezium.relational.history.DatabaseHistoryMetrics [] - Unable to register the MBean 'debezium.mysql:type=connector-metrics,context=schema-history,server=mysql_binlog_source': debezium.mysql:type=connector-metrics, context=schema-history,server=mysql_binlog_source 4128 2022-01-12 05:12:56,860 [Source Data Fetcher for Source: TableSourceScan(table=[[vvp, default, ods_ex_trade_detail_spot_mysql_cdc ... with jobLine 4126 shows
BinlogSplitReader is created, which indicates that full data reading is complete and the deployment has entered incremental binary log reading. The WARN log on line 4127 (Unable to register the MBean) is normal and does not affect data synchronization.
Does the starting position change when I restart a deployment?
It depends on the Starting Strategy you select in the Deployment Starting Configuration dialog box:
-
NONE: The connector re-reads from the configured start position.
-
Latest State: The connector resumes from the binary log position where the deployment was last canceled.
For example, if the deployment was configured to start at {file=mysql-bin.01, position=40} but was canceled at position 210, Latest State resumes at 210 and NONE restarts from 40.
Make sure the required binary log file still exists on the server before restarting. If it has expired and been deleted, the restart fails.
How does the MySQL CDC connector work, and how does it affect the database?
When scan.startup.mode is set to initial (the default), the connector:
-
Connects via JDBC and runs a
SELECTstatement to read full data, recording the current binary log position. -
After full data reading, switches to the binlog client to read incremental changes from the recorded position.
Full data reading increases query load because of the SELECT statement. During incremental reading, each source table holds one binlog connection. If you have many source tables, check the connection limit:
show variables like '%max_connections%';How do I skip the snapshot phase and read only change data?
Set scan.startup.mode in the WITH clause to one of: earliest-offset, latest-offset, specific-offset, or timestamp. For details, see the "Parameters in the WITH clause" section in Create a MySQL CDC source table.
How does MySQL CDC locate the binlog position when scan.startup.mode = timestamp?
With the timestamp startup mode, MySQL CDC determines the initial consumption position as follows:
-
Scan all binlog files and find the first file whose last-modified time is greater than or equal to the specified timestamp.
-
Read binlog events from the beginning of that file.
-
Skip events whose timestamp is earlier than the specified timestamp.
-
Start consuming from the first event whose timestamp is greater than or equal to the specified timestamp.
Boundary cases:
-
If the specified timestamp is in the future, consumption starts from the latest available position, equivalent to
latest-offset. -
If the binlog corresponding to the specified timestamp has already been purged, consumption starts from the earliest available position, equivalent to
earliest-offset.
How does the connector handle sharded MySQL tables?
Use the table-name parameter with a regular expression to match all shards. For example, to monitor all tables with the prefix user_:
'table-name' = 'user_.*'If all tables across shards have the same schema, use database-name with a regex instead.
What do I do if commas in the table-name regex cause parsing errors?
Debezium uses commas as delimiters, so a pattern like t_process_wi_history_\d{1,2} fails.
13-vvr-4.0.13-1-SNAPSHOT.jar:1.13-vvr-4.0.13-1-SNAPSHOT]
Caused by: java.util.regex.PatternSyntaxException: Unclosed counted closure near index 35
zhangtest.t_process_wi_history_\d{1
at java.util.regex.Pattern.error(Pattern.java:1969) ~[?:1.8.0_302]
at java.util.regex.Pattern.closure(Pattern.java:3155) ~[?:1.8.0_302]Use alternation instead:
'table-name' = '(t_process_wi_history_\d{1}|t_process_wi_history_\d{2})'Multiple MySQL CDC deployments are causing high database load. What can I do?
Two approaches:
-
Offload to Kafka: Sync the MySQL CDC source table to an ApsaraMQ for Kafka sink table. Other deployments then consume from Kafka instead of reading binary logs directly. See Synchronize data from all tables in a MySQL database to Kafka.
-
Merge deployments with shared server ID: If multiple
CREATE TABLE ASdeployments share the same configuration, assign the same server ID to reuse the data source. See Example 4: execution of multiple CREATE TABLE AS statements.
A small update causes unusually high bandwidth usage. Why?
Binary log files contain changes for all databases and tables in the MySQL instance — not just the ones your deployment monitors. If your instance has three tables, the binary log carries changes from all three even if your deployment only tracks one.
Fix this by reusing the MySQL CDC source table so that multiple deployments share a single binlog connection. See the "Enabling of the reuse of a MySQL CDC source table" section in MySQL connector.
Timestamp fields show an 8-hour offset compared to the MySQL server timezone. Why?
Two possible causes:
-
The
server-time-zoneparameter in the CDC deployment does not match the actual MySQL server timezone. Updateserver-time-zoneto match. -
A custom deserializer (
MyDeserializer implements DebeziumDeserializationSchema) does not setserverTimeZone. SetserverTimeZonebased on howRowDataDebeziumDeserializeSchemaparsesTIMESTAMPdata:private TimestampData convertToTimestamp(Object dbzObj, Schema schema) { if (dbzObj instanceof Long) { switch (schema.name()) { case Timestamp.SCHEMA_NAME: return TimestampData.fromEpochMillis((Long) dbzObj); case MicroTimestamp.SCHEMA_NAME: long micro = (long) dbzObj; return TimestampData.fromEpochMillis(micro / 1000, (int) (micro % 1000 * 1000)); case NanoTimestamp.SCHEMA_NAME: long nano = (long) dbzObj; return TimestampData.fromEpochMillis(nano / 1000_000, (int) (nano % 1000_000)); } } LocalDateTime localDateTime = TemporalConversions.toLocalDateTime(dbzObj, serverTimeZone); return TimestampData.fromLocalDateTime(localDateTime); }
Can the MySQL CDC connector listen to secondary databases?
Yes. Add the following to the secondary database configuration so that data synced from the primary is written to the secondary's binary log:
log-slave-updates = 1If Global Transaction Identifier (GTID) mode is enabled on the primary, also enable it on the secondary:
gtid_mode = on
enforce_gtid_consistency = onHow do I capture DDL events?
Use the DataStream API with MySqlSource and set includeSchemaChanges(true):
MySqlSource<xxx> mySqlSource =
MySqlSource.<xxx>builder()
.hostname(...)
.port(...)
.databaseList("<databaseName>")
.tableList("<databaseName>.<tableName>")
.username(...)
.password(...)
.serverId(...)
.deserializer(...)
.includeSchemaChanges(true) // Capture DDL events
.build();
// Add downstream processing logicDoes MySQL CDC support syncing all tables in a database at once?
Yes. Use the CREATE TABLE AS or CREATE DATABASE AS statement. See CREATE TABLE AS statement or CREATE DATABASE AS statement.
ApsaraDB RDS for MySQL V5.6 instances do not write incremental changes to binary log files, so the connector cannot read incremental data from those instances.
Incremental data from a specific table is not being synchronized. Why?
A binary log filter on the MySQL server may be excluding that database. Run the following command to check:
show master status;Check the Binlog_Ignore_DB and Binlog_Do_DB columns in the output:
+------------------+----------+--------------+------------------+----------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+------------------+----------+--------------+------------------+----------------------+
| mysql-bin.000006 | 4594 | | | xxx:1-15 |
+------------------+----------+--------------+------------------+----------------------+How do I configure tableList when using the DataStream API for MySQL CDC?
The tableList value must include both the database name and table name, in the format yourDatabaseName.yourTableName.
MongoDB CDC
Can the connector resume from a checkpoint if the deployment fails during full data reading?
Yes. Set 'scan.incremental.snapshot.enabled' = 'true' in the WITH clause to enable checkpoint-based recovery during full data reading.
Does MongoDB CDC support reading incremental data only?
By default, the connector reads both full and incremental data. To skip full data and read only incremental changes, set 'scan.startup.mode' = 'latest-offset' in the WITH clause.
Can I subscribe to only specific collections?
No. The connector subscribes at the database level. Set 'database' = 'mgdb' and 'collection' = '' in the WITH clause to subscribe to all collections in the database.
Does MongoDB CDC support concurrent reading?
Yes, during the initial snapshot phase. Set scan.incremental.snapshot.enabled to true to enable concurrent reading.
Which MongoDB versions are supported?
MongoDB 3.6 and later (change streams were introduced in 3.6). MongoDB 4.0 or later is recommended. On versions earlier than 3.6, the connector returns the error "Unrecognized pipeline stage name: '$changeStream'".
Which MongoDB architectures are supported?
The connector requires a replica set or sharded cluster — change streams only work in these modes. For local testing, convert MongoDB to a single-node replica set using rs.initiate(). Without this, the connector returns "The $changestage is only supported on replica sets".
Does MongoDB CDC support Debezium parameters?
No. The MongoDB CDC connector is independently developed in Flink CDC and does not depend on Debezium.
Authentication fails even though the credentials are correct. Why?
The user credentials are scoped to a specific database. Add 'connection.options' = 'authSource=<database_the_user_belongs_to>' to the WITH clause.
Can the connector resume from a checkpoint after a deployment restart?
Yes. Checkpoints store resume tokens for change streams. When the deployment restarts, the connector reads the resume token and continues from the corresponding position in the oplog.rs collection.
If the resume token no longer exists in oplog.rs — a fixed-capacity collection that rotates when full — increase the oplog size to prevent premature rotation. See Change the Oplog Size of Self-Managed Replica Set Members.
Does MongoDB CDC support UPDATE_BEFORE messages (pre-update images)?
It depends on the MongoDB version:
-
MongoDB 6.0 and later with pre-image/post-image enabled: Set
'scan.full-changelog' = 'true'.MongoDBSourcegeneratesUPDATE_BEFOREmessages directly. -
MongoDB earlier than 6.0: The
oplog.rscollection includesINSERT,UPDATE,REPLACE, andDELETEtypes but notUPDATE_BEFORE. When usingMongoDBTableSourcewith SQL mode, the Flink planner automatically applies theChangelogNormalizeoperator to generateUPDATE_BEFOREmessages — but this operator stores all key states and adds overhead. If you use the DataStream API withMongoDBSource(without the Flink planner optimization),ChangelogNormalizeis not applied automatically. Either manage the state yourself, or useMongoDBTableSourceand convert to a changelog stream:tEnv.executeSql("CREATE TABLE orders ( ... ) WITH ( 'connector'='mongodb-cdc', ... )"); Table table = tEnv.from("orders").select($("*")); tEnv.toChangelogStream(table) .print() .setParallelism(1); env.execute();
PostgreSQL CDC
How do I filter out invalid date values?
Add one of the following to the WITH clause:
-
'debezium.event.deserialization.failure.handling.mode' = 'warn': Skip invalid records and log them as warnings. -
'debezium.event.deserialization.failure.handling.mode' = 'ignore': Skip invalid records silently.
TOAST data is missing from updates. Why?
The behavior depends on the table's REPLICA IDENTITY setting:
-
`REPLICA IDENTITY FULL`: TOAST column values appear in both the
beforeandafterfields of change events, just like any other column. -
`REPLICA IDENTITY DEFAULT` (the default): Unchanged TOAST columns are omitted from
UPDATEevents. When'debezium.schema.refresh.mode' = 'columns_diff_exclude_unchanged_toast'is used, thewal2jsonplugin omits unchanged TOAST data — so those columns only appear in WAL logs when replica identity isFULL.
To fix missing TOAST data, set replica identity to FULL:
ALTER TABLE your_table_name REPLICA IDENTITY FULL;WAL logs are not being released and disk usage is high. Why?
The PostgreSQL CDC connector updates the log sequence number (LSN) in replication slots only when a Flink checkpoint completes. If disk usage is high, check:
-
Whether checkpointing is enabled for the deployment.
-
Whether any replication slot is unused or has a large synchronization lag.
What happens when DECIMAL precision exceeds the declared column precision?
The value is returned as null. To preserve the original value, set 'debezium.decimal.handling.mode' = 'string' to read DECIMAL data as strings instead.
How do I configure tableList when using the DataStream API for PostgreSQL CDC?
The tableList value must include both the schema name and table name, in the format my_schema.my_table.
Packages and dependencies
Why can't I download flink-sql-connector-mysql-cdc-2.2-SNAPSHOT.jar?
SNAPSHOT versions correspond to development branches and are not published to the Maven central repository. Compile from source to use a SNAPSHOT version, or use a stable release such as flink-sql-connector-mysql-cdc-2.1.0.jar, which is available in the Maven central repository.
What is the difference between flink-sql-connector-xxx.jar and flink-connector-xxx.jar?
-
`flink-sql-connector-xxx`: A fat JAR that includes the connector code and all shaded dependencies. Add it to the
libdirectory for SQL deployments. -
`flink-connector-xxx`: Contains only the connector code, without dependencies. Use it for DataStream deployments and manage third-party dependencies yourself, including resolving conflicts with
excludeandshadeoperations.
Why can't I find a Flink CDC 2.x connector package in the Maven repository?
Starting from Flink CDC 2.0.0, the group ID changed from com.alibaba.ververica to com.ververica. The Maven path for 2.x packages is /com/ververica/.
Numeric fields are returned as strings when using JsonDebeziumDeserializationSchema. How do I fix this?
Configure Debezium's numeric handling properties when building the source:
Properties properties = new Properties();
properties.setProperty("bigint.unsigned.handling.mode", "long");
properties.setProperty("decimal.handling.mode", "double");
MySqlSource.<String>builder()
.hostname(config.getHostname())
// ...
.debeziumProperties(properties);For details on how Debezium converts numeric types, see Debezium connector for MySQL.
Error messages
"Replication slot 'xxxx' is active"
After a PostgreSQL CDC deployment ends, its replication slot may not be released automatically. Release it manually:
select pg_drop_replication_slot('rep_slot');If the slot is held by an active process, terminate the process first:
select pg_terminate_backend(162564);
select pg_drop_replication_slot('rep_slot');Alternatively, add 'debezium.slot.drop.on.stop' = 'true' to the PostgreSQL source configuration to drop the slot automatically when the deployment is canceled.
Enabling automatic slot cleanup causes WAL logs to be reclaimed. When the deployment restarts, data is lost and at-least-once semantics cannot be ensured.
"binlog probably contains events generated with statement or mixed based replication format"
MySQL CDC source tables only support binary logs in ROW format. If the format is STATEMENT or MIXED, the connector fails.
-
Check the current format:
show variables like "binlog_format"; -- To check the global setting: show global variables like "binlog_format"; -
Change the format to ROW. See Setting the binary log format.
-
Restart the deployment.
"Encountered change event for table xxx.xxx whose schema isn't known to this connector"
Three common causes:
-
Missing permissions: The account does not have access to all databases used in the deployment. Grant the required permissions. See Configure a MySQL database.
-
`debezium.snapshot.mode` set to `never`: Reading from the start of binary logs means the table schema recorded there may not match the current schema. Avoid this setting. To tolerate schema mismatches, add
'debezium.inconsistent.schema.handling.mode' = 'warn'. -
Unsupported DDL syntax: Debezium cannot interpret certain expressions such as
DEFAULT (now()). Check theio.debezium.connector.mysql.MySqlSchemaWARN log to identify the problematic statement.
"The connector is trying to read binlog starting at GTIDs ..., but this is no longer available on the server"
The binary log file the connector needs has been deleted. Common causes and fixes:
<table> <thead> <tr> <th><b>Cause</b></th> <th><b>Fix</b></th> </tr> </thead> <tbody> <tr> <td>Binary log retention period too short</td> <td>Increase the retention period, e.g., to 7 days: <code>set global expire_logs_days=7;</code></td> </tr> <tr> <td>Deployment consuming binlogs too slowly (backpressure at a downstream operator)</td> <td>Optimize resource configuration to reduce backpressure</td> </tr> <tr> <td>ApsaraDB RDS for MySQL: logs retained for at most 18 hours and up to 30% of storage</td> <td>Adjust the binary log expiration policy for RDS</td> </tr> <tr> <td>Read-only ApsaraDB RDS for MySQL instance: local binlog retained for a minimum of 10 seconds before upload to Object Storage Service (OSS)</td> <td>Avoid using read-only instances (hostname starts with <code>rr</code>) for CDC; use regular instances (hostname starts with <code>rm</code>)</td> </tr> <tr> <td>Internal data migration on the RDS instance</td> <td>Restart the deployment to re-read data</td> </tr> </tbody> </table>
"EventDataDeserializationException: Failed to deserialize data of EventHeaderV4"
The MySQL server closed an idle binlog connection. The net_write_timeout parameter controls this timeout (default: 60 seconds). Connections that are inactive due to backpressure or network issues get disconnected.
-
Add
'debezium.connect.keep.alive.interval.ms' = '40000'to the MySQL CDC source table configuration, or increasenet_write_timeouton the database. See Optimize instance parameters. -
If the error is caused by backpressure, tune the deployment's resource configuration.
-
Ververica Runtime (VVR) 8.0.7 and later automatically retries on errors caused by backpressure.
"The slave is connecting using CHANGE MASTER TO MASTER_AUTO_POSITION = 1, but the master has purged binary logs"
Full data reading took so long that the GTID position recorded at the start of full sync was deleted from the server by the time the connector switched to incremental reading.
Increase the binary log retention period or maximum file size:
mysql> show variables like 'expire_logs_days';
mysql> set global expire_logs_days=7;"The 'before' field of UPDATE/DELETE message is null"
The PostgreSQL table's REPLICA IDENTITY is not set to FULL. Run:
ALTER TABLE yourTableName REPLICA IDENTITY FULL;If the error persists after restarting the deployment, add the statement to the deployment code.
"Can't find any matched tables, please check your configured database-name and table-name"
Two possible causes:
-
The table name does not exist in the database. Verify the configured table name.
-
The account lacks permissions on specific databases in the deployment. Grant the required permissions on all databases.
"The primary key is necessary when enable 'scan.incremental.snapshot.enabled'"
This error occurs in VVR 4.0.x when a MySQL CDC source table is created without a primary key in the DDL WITH clause. Add the primary key definition to the DDL statement.
"java.io.EOFException: SSL peer shut down incorrectly" {#javaioeofe-xception-ssl-peer-shut-down-incorrectly}
MySQL 8.0.27 enables SSL connections by default, but the JDBC driver cannot connect over SSL with the default configuration.
If using VVR 6.0.2 or later, add
'jdbc.properties.useSSL' = 'false'to theWITHclause.If the table is used only as a dimension table, set the connector to
rdsand addcharacterEncoding=utf-8&useSSL=falseto the URL:'url' = 'jdbc:mysql://***.***.***.***:3306/test?characterEncoding=utf-8&useSSL=false'
"A slave with the same server_uuid/server_id as this slave has connected to the master"
Each parallel subtask of a MySQL CDC source table must have a unique server ID. If parallel subtasks across the same deployment — or across multiple deployments — share the same server ID, this error occurs.
Specify a globally unique server ID for each parallel subtask. For details, see the "Precautions" section in Create a MySQL CDC source table.
"NullPointerException" after adding a column during full data reading
The deployment records the table schema at startup and stores it in checkpoints. Adding a column while full data reading is in progress causes a schema mismatch, which triggers a NullPointerException.
Cancel the deployment, delete the downstream table, and restart the deployment without states.
"Mysql8.0 Public Key Retrieval is not allowed"
The MySQL user is configured with SHA256 password authentication, which requires TLS. Switch the user to native password authentication:
ALTER USER 'username'@'localhost' IDENTIFIED WITH mysql_native_password BY 'password';
FLUSH PRIVILEGES;"sub account not auth permission"
When using ApsaraDB RDS for MySQL as a CDC source, the RAM user does not have permission to download binary log files from Object Storage Service (OSS). Grant the necessary permissions. See Authorize a RAM user with read-only permissions to download backup files.
"DELETE command denied to user 'userName'@'\*.\*.\*.\*' for table 'table_name'"
When a WHERE clause filters CDC data streams, Realtime Compute for Apache Flink emits both a BEFORE UPDATE and an AFTER UPDATE record for each UPDATE operation. The downstream sink treats the BEFORE UPDATE record as a DELETE. Grant the DELETE permission to the database user performing operations on the result table.