The Tasks panel gives you a real-time view of instance change tasks and data migration tasks for your Elasticsearch cluster. It shows the current in-progress change and the most recently completed change task.
Limitations
The following features are not available for Elasticsearch V7.16 instances or any instances in the China (Chengdu) and China (Guangzhou) regions:
-
Viewing the stage of a change task, the progress details for each stage, and change records.
-
Viewing data migration progress.
Open the Tasks panel
-
Log on to the Alibaba Cloud Elasticsearch console.
-
In the left navigation pane, click Elasticsearch Clusters.
-
In the top menu bar, select a resource group and a region.
-
On the Elasticsearch Clusters page, click the ID of the target instance.
-
In the upper-right corner, click the
 icon to open the Tasks panel.
icon to open the Tasks panel.
View instance change progress
Click the Change Progress tab to view details about the current or most recently completed change task. The task list updates approximately 10 seconds after a change is triggered.
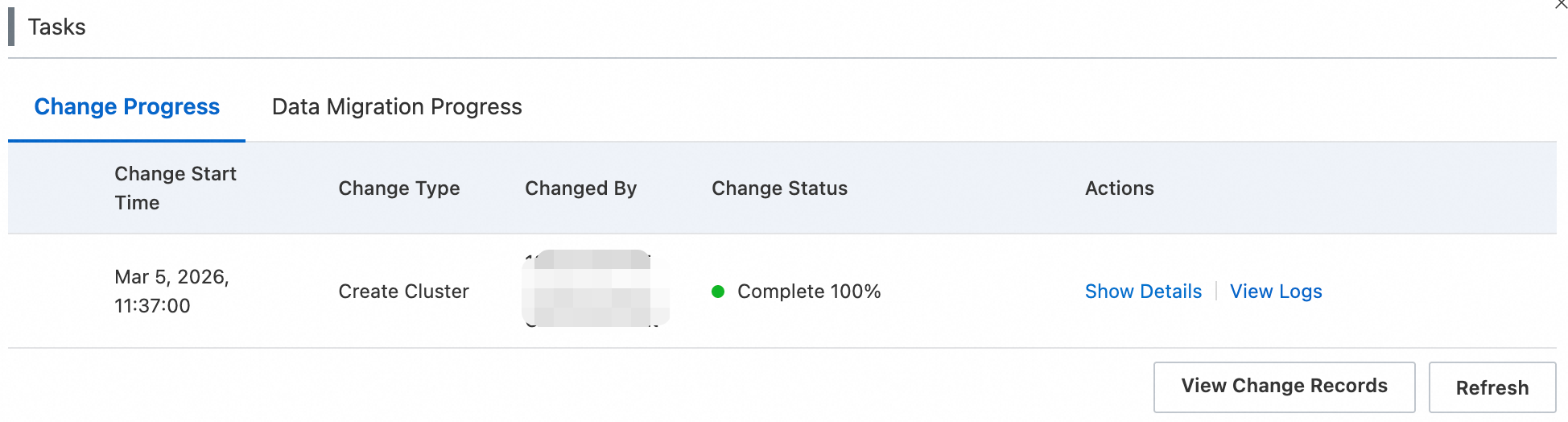
Each row in the table answers four questions about a change:
|
Parameter/Operation |
Description |
|
Change Start Time |
When did the change start? Shows the timestamp when the instance change was triggered. |
|
Change Type |
What changed? Shows the type of change, such as instance creation, instance restart, or cluster configuration change. |
|
Changed By |
Who triggered it? Shows the ID of the Alibaba Cloud account or Resource Access Management (RAM) user that initiated the change. |
|
Change Status |
What is the outcome? The status can be In Progress, Complete, Interrupt Change, or Change is blocked. If the status is Change is blocked, click View Reason to see the blocking details. |
|
Actions |
Operation buttons. For more information, see the description below. |
|
View Change Records |
Click View Change Records to go to the Change Records page and view historical change records. For more information, see View change progress and change records. |
|
Refresh |
Click Refresh to get the latest status of the instance change. |
View change stage details
Click the  icon to the left of a change task to expand the stage breakdown:
icon to the left of a change task to expand the stage breakdown:
-
Each stage shows its current progress and elapsed time. Completed stages show their completion time.
-
The Updating Nodes stage performs a rolling update on each node through five sub-stages in sequence: Waiting for Cluster Status, Changing Node Specifications, Preparing Node Configuration, Launching Service, and Waiting for Process Health.
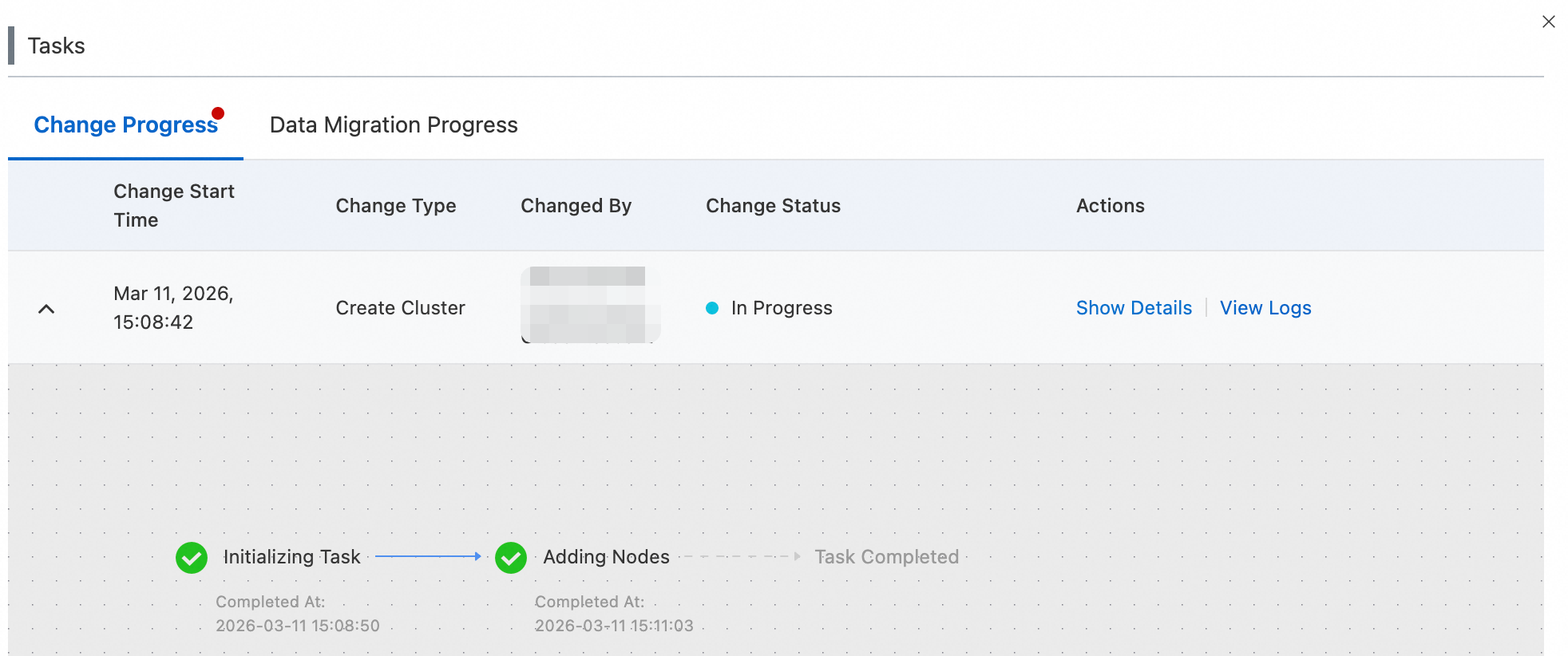
If the cluster is unstable or unhealthy, the change process may stay in the Waiting for Cluster Status or Waiting for Process Health stage for an extended period. To keep the change moving, reduce business read and write operations.
Operations
The Actions column provides the following operations:
-
Show Details: View the configuration details for this change.
-
View Logs: Go to the View Logs page to view the instance's operation logs. For more information, see Query logs.
-
Pause Change / Resume Change: Available for instances with a change in progress. Click Pause Change to interrupt the change task. After the task is interrupted, click Resume Change to continue.
Important-
Change interruption is supported only for instances deployed in Basic Control Architecture (v2) mode. It is not supported for Cloud-native Control Architecture (v3) mode. Check the Control Architecture Type section on the Basic Information page to confirm the deployment mode.
-
If an instance is in the Interrupt Change state, cluster services may be affected. Resume the change by performing a secondary change or a manual operation. Secondary changes support cluster upgrades and plugin management.
-
After you trigger Resume Change, the entire restart process resumes, causing the cluster nodes to restart.
-
-
Cancel Change: When a plugin is being installed or uninstalled, cancel the current change as needed.
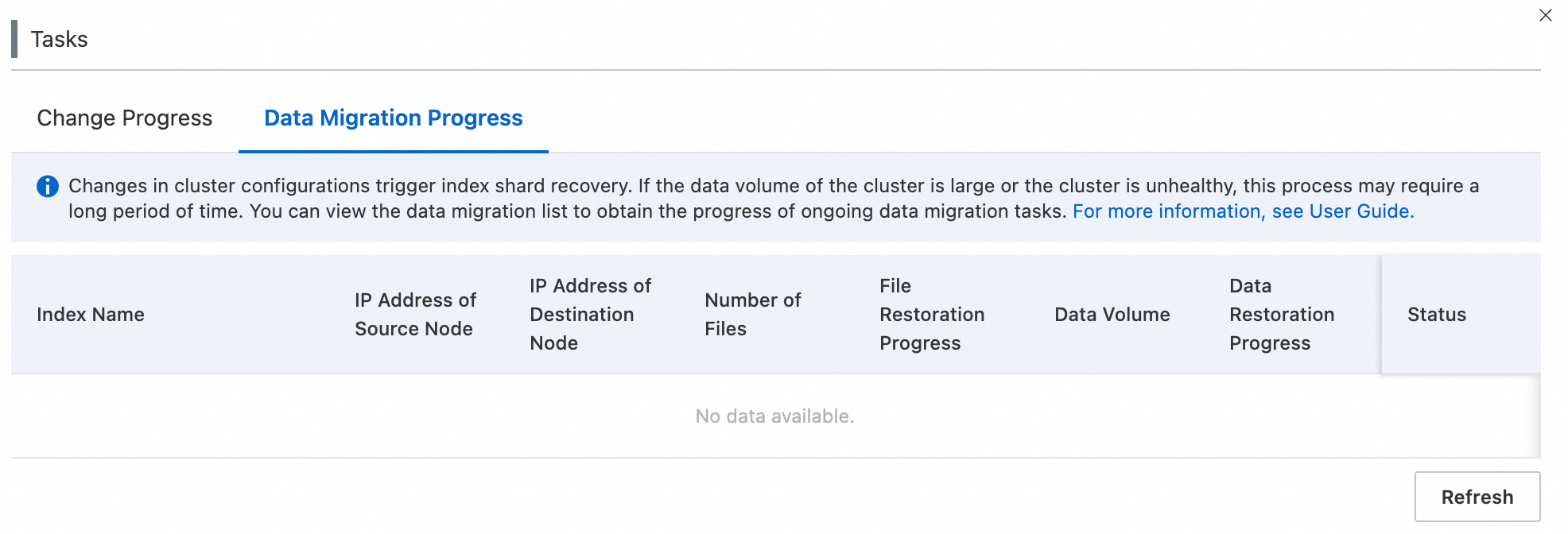
View data migration progress
Click the Data Migration Progress tab to view the migration task details.
-
A red dot appears in the upper-right corner of the Data Migration Progress tab when a migration task is running.
-
Migration task details appear only when a cluster configuration change triggers a cluster rolling update that includes a user data migration task.
-
The migration progress shown in the console is not real-time and may lag behind the actual state. For precise progress, run
GET _cat/recovery.
Adjust migration parameters
When a migration task is running, click Adjust Migration Progress on the Data Migration Progress tab to tune the migration parameters.
-
Parameter adjustments are temporary and apply only during the change process. The backend restores default values based on cluster status after the change completes.
-
These are dynamic Elasticsearch cluster parameters. Adjust them to speed up migration when you have large data volumes or slow recovery speeds. Adjust with caution — frequent changes or values that exceed the cluster's scheduling capacity can cause excessive load on cluster nodes.
For scenarios with many shards:
|
Parameter |
Native configuration key |
Description |
|
Primary Shards Restored in Parallel |
cluster.routing.allocation.node_initial_primaries_recoveries |
Number of primary shards recovered simultaneously when a node restarts. Increase this value if the node has multiple disks and I/O pressure is low. |
|
Data Balancing Tasks Run in Parallel |
cluster.routing.allocation.cluster_concurrent_rebalance |
Number of data rebalance tasks running simultaneously across the cluster. Suitable when nodes are added or removed and cluster load is not high. |
|
Data Restoration Tasks Run in Parallel |
cluster.routing.allocation.node_concurrent_recoveries |
Number of data recovery tasks running simultaneously, excluding primary shard restart recovery. |
|
Shards Restored to Node in Parallel |
cluster.routing.allocation.node_concurrent_incoming_recoveries |
Maximum number of concurrent shard recoveries a node can accept — typically shards being recovered to this node from other nodes. |
For scenarios with large data volumes:
|
Parameter |
Native configuration key |
Description |
|
Data Transmission Bandwidth |
indices.recovery.max_bytes_per_sec |
Maximum bandwidth for data transfer during recovery on each node, for example, |