The OpenStore intelligent hybrid storage engine is an elastic, efficient, and low-cost log storage engine developed by the Alibaba Cloud Elasticsearch team for log scenarios. It uses a pay-as-you-go billing method based on the actual amount of data you store, which eliminates the need to reserve storage capacity for your cluster in advance and provides a truly serverless storage experience. The engine improves upon traditional hot and cold data separation architectures by reducing the complexity of cluster data ingestion and lowering the storage cost for large amounts of data on the cloud. This topic describes the scenarios, architecture, advantages, and performance metrics of the OpenStore intelligent hybrid storage engine.
This feature is currently available in the China (Hong Kong) region. Support for other regions will be available soon.
Background information
In comprehensive log observation scenarios, data often needs to be stored for long periods or archived for auditing because of business or regulatory requirements. When you use open source Elasticsearch, you must separate hot and cold data in your cluster. Data older than 30 days is typically stored on other storage media, such as Object Storage Service (OSS), using cluster snapshots. This method is used to archive log data for the long term. However, you cannot query the data directly after it is archived. Before you can query the data, you must call an API to restore the snapshot to the cluster and wait for the indexes in the snapshot to initialize. This process is complex and results in high long-term storage costs.
The OpenStore storage engine is an important feature of the enhanced edition of Alibaba Cloud Elasticsearch 7.10. It works with the Indexing Service managed write service to meet the requirements for low-cost, high-concurrency writes and long-term data storage in log scenarios. You can create an instance of the enhanced edition of version 7.10 as needed and enable the OpenStore intelligent hybrid storage feature.
On the Basic Information page of the instance, go to the Node Visualization section. In this section, you can check whether the OpenStore feature is enabled, enable the feature, and view OpenStore storage information. For more information, see View cluster status and node information.
Indexing Service instances with OpenStore enabled use an underlying storage service that ensures high data availability for the cluster. These instances do not support automatic backup.
Advantages
Massive storage: Provides pay-as-you-go serverless storage. You do not need to plan or purchase storage capacity in advance. Storage usage is calculated hourly, which achieves 100% storage resource utilization.
Low cost: Supports real-time modifications and write updates. You do not need to configure complex index lifecycles. Data is automatically tiered, which makes the engine easy to use. The unit price for data storage is 60% lower than local SATA disks and 70% lower than ultra disks.
High availability: The storage-compute disaggregation architecture allows multiple replicas to share a single copy of data without increasing storage costs. The underlying storage service ensures high data availability for the cluster and provides 99.9999999999% (twelve 9s) data durability.
Improved query performance: For common query analysis in typical log scenarios, performance is 100% better than local SATA disks and is comparable to ultra disks or PL0 Enterprise SSDs (ESSDs).
Limits
The following limits apply when you purchase and use OpenStore storage.
Category | Limitations |
Region | Currently available only in the following regions (subject to what is shown in the console):
|
Instance version | Only version 7.10 instances support the OpenStore intelligent hybrid storage feature. |
Instance type | Only the OpenStore storage-optimized 8-core 64 GB and 16-core 64 GB instance types are supported. |
Instance storage capacity | The maximum storage capacity for a single node is 30 TB. Note If you require a larger storage capacity for a single node, submit a ticket to request it. A maximum of 50 TB is supported. |
Number of shard replicas | When OpenStore intelligent hybrid storage is enabled, the number of shard replicas must be 1 or more. Warning Multiple replicas share one copy of data without increasing storage costs. Multiple replicas ensure the reliability of accelerated writes to local storage. If you do not configure multiple replicas, some real-time write data may be lost. Lost data cannot be recovered. |
Index template |
Note When you manually delete an OpenStore storage index, you must delete both the index and its corresponding alias to successfully delete the index. |
Index lifecycle configuration | Customizing the freeze action in the index lifecycle is not supported. |
Query limits |
|
Cluster shard limit | Fewer than 80,000 is recommended. |
Node shard limit | Fewer than 3,000 is recommended. |
Single shard size | Less than 40 GB is recommended. |
Data disk write throughput | 300 MB/s if the data disk usage is below 85%. 100 MB/s if the data disk usage is above 85%. |
Scenarios
The OpenStore storage engine, developed by Alibaba Cloud Elasticsearch, is suitable for scenarios such as log retrieval and metric analysis that require large-volume data writes and long-term storage, and can tolerate low query QPS and relatively high query latency.
The intelligent hybrid storage engine is suitable for business scenarios that require real-time data updates and do not have a strict separation between hot and cold data.
Hybrid storage architecture
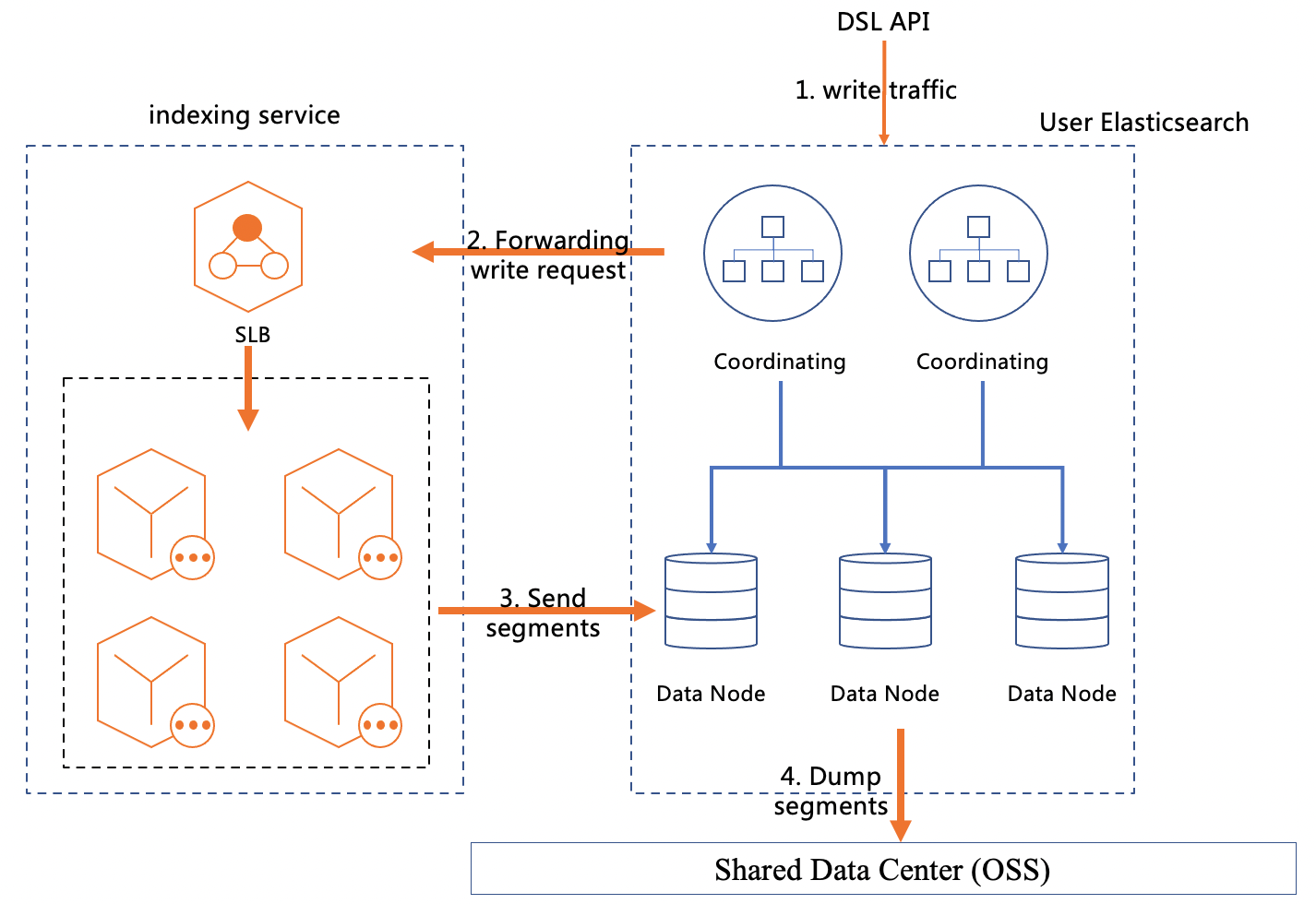
This architecture has the following advantages:
Storage-compute disaggregation: Compared to hot and cold data separation architectures, this architecture further decouples compute and storage resources. This eliminates the need to manage storage capacity. It provides elastic storage and pay-as-you-go billing. It also leverages cloud-native principles to optimize cluster extensibility. This greatly improves the speed of index migration and recovery, making it suitable for large-scale data scenarios.
Ease of use: Provides fully automated index lifecycle management. You only need to configure a simple index lifecycle. The engine manages the entire process of hot and cold data separation and data migration to OpenStore storage.
Data consistency: The intelligent hybrid storage engine uses a Raft-based hybrid storage consistency protocol to ensure data consistency across different storage media. It automatically performs data tiering and cache acceleration without user intervention and supports real-time data updates.
Performance testing
Test environment
Dataset: A dataset from a log scenario.
Cluster configuration: The same configuration was used for a typical log scenario:
Number of nodes: 10
Number of shards: 108
Query conditions:
Query type: sort
Number of documents: 3,800,000,000
Test results
Storage class
Query time
Local SATA disk
More than 30 seconds
Ultra disk
12.229 seconds
OpenStore storage
15.841 seconds
Test conclusion:
With the same cluster configuration, the query time for log data stored in OpenStore is significantly lower than that for data on local SATA disks. The query time is nearly the same as that for ultra disks. In terms of price, the unit price of OpenStore storage is approximately 60% lower than that of ultra disks. It also uses a pay-as-you-go billing method, so you do not need to purchase storage capacity in advance. Using OpenStore storage can help you significantly reduce costs.
Related metrics
Metric | Data |
Access latency (local cache hit) | 0.2 ms |
Access latency (local cache miss) | 50 ms to 400 ms |
Access throughput (local cache hit) | 1 GB/s |
Access throughput (local cache miss) | 750 MB/s |
Scenarios | Infrequently accessed data such as monitoring logs, historical orders, and archived data |