Elasticsearch clusters handle both indexing and search on the same nodes, which forces you to size your cluster for peak write throughput even when write traffic is bursty or unpredictable. Alibaba Cloud Elasticsearch Kernel-enhanced Edition clusters with Indexing Service offload all write operations to a managed cloud service, freeing your cluster resources for search. Based on a read/write splitting architecture, Indexing Service delivers high-throughput, low-latency indexing at a fraction of the cost of running write-heavy workloads on a standard cluster.
Indexing Service is available in the China (Hong Kong) region. Stay tuned for availability in other regions.
Use cases
Indexing Service is designed for time series data analysis with high write transactions per second (TPS), significant write traffic fluctuations, and low queries per second (QPS). Typical workloads include:
-
Log retrieval and analysis
-
Metric monitoring and analysis
-
Intelligent Internet of Things (IoT) hardware data collection, monitoring, and analysis
Data synchronization between a Kernel-enhanced Edition cluster with Indexing Service enabled and your cluster depends on the apack/cube/metadata/sync task. Run GET _cat/tasks?v to check the task status. Do not manually clear this task. If the task is cleared, run POST /_cube/meta/sync to restore it immediately to avoid disrupting data writes.
How it works
Traditional Elasticsearch clusters handle both indexing and search on the same nodes, tightly coupling write throughput with cluster capacity. When write traffic spikes, the entire cluster suffers — including search latency.
Indexing Service separates these concerns:
-
Write path: Indexing Service receives all write traffic and processes indexing in a dedicated write-hosting environment.
-
Read path: Your cluster handles search queries against data that has been replicated from the write-hosting environment.
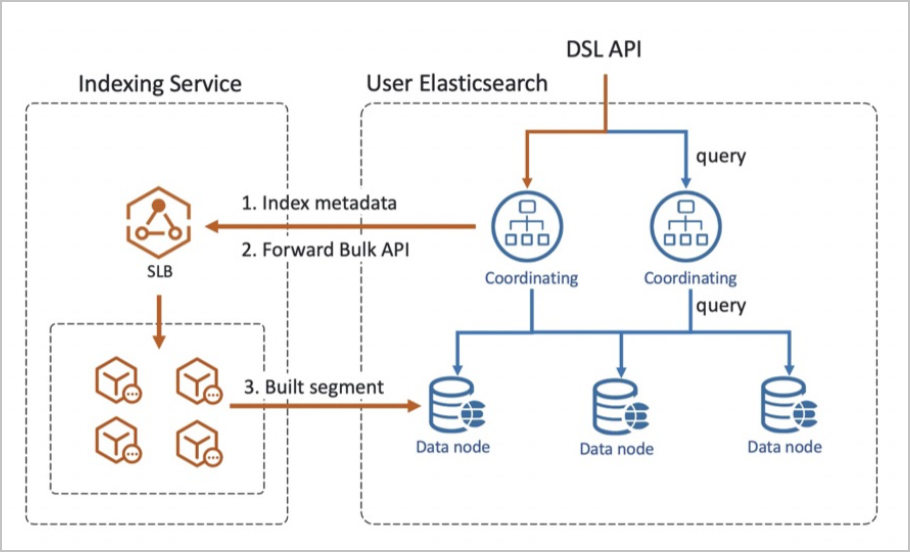
This architecture eliminates the need to size your cluster for peak write throughput. Indexing Service provisions and scales write resources in the background, while your cluster focuses on search performance.
Three key technologies power the write-hosting environment:
| Technology | Description |
|---|---|
| Physical replication of indexes | Replicates data at the segment level across clusters in real time, keeping the write-hosting cluster and your cluster in sync. |
| Separation of compute and storage | Decouples write compute from storage, enabling independent scaling of each tier. |
| faster-bulk | Alibaba Cloud's kernel optimization that significantly accelerates bulk indexing throughput. |
Benefits
| Benefit | Details |
|---|---|
| Low cost | Computing resources for write operations are reduced by an average of 60%. Pay for actual write volume, not peak capacity. |
| Elastic scaling | Write resources scale automatically with traffic fluctuations. No data migration is required. |
| No operations and maintenance (O&M) | Indexing Service manages all write operations in the cloud, eliminating write-related cluster management overhead. |
| High performance | Professional-grade write optimization through physical replication, compute-storage separation, and faster-bulk. |
| Low latency | Segment-level cross-cluster physical replication keeps data latency under saturated write conditions in the range of hundreds of milliseconds. |
| High availability | Geo-disaster recovery support through multi-cluster backup across regions. If a cluster fails, transfer the index to another functioning cluster for hosting. |
Billing
Indexing Service charges write hosting fees, which consist of:
-
Write traffic fees: Based on the volume of write traffic to the write-hosting environment.
-
Storage fees: Based on the storage space used for hosting.
Write hosting fees apply regardless of whether your cluster uses subscription or pay-as-you-go billing. For pricing details, see Elasticsearch billing.
Indexing Service reduces the resources required to handle write operations in your cluster, lowering overall cluster costs.
Limits
Indexing Service imposes limits on write throughput, document count, and index configuration.
Cluster-level limits
These are hard limits. Exceeding them returns HTTP 429.
| Item | Limit | Error when exceeded |
|---|---|---|
| Write traffic | 200 MB/s | Inflow Quota Exceed. To request a higher limit, submit a ticketsubmit a ticket. |
| Written documents per second | 200,000 docs/s | Write QPS Exceed. To request a higher limit, submit a ticketsubmit a ticket. |
| Put Mapping requests | 50 TPS | PutMappingRequest blocked. |
Frequent Put Mapping requests consume significant compute resources and can affect hosting service stability. Define an index template before writing data to minimize Put Mapping operations.
Shard-level limits
These are soft limits. If a limit is reached, the service continues but quality cannot be guaranteed.
| Item | Soft limit | Error code |
|---|---|---|
| Write traffic (without primary keys) | 10 MB/s per shard | write_size blocked |
| Write traffic (with primary keys) | 5 MB/s per shard | write_size blocked |
| Written documents per second | 5,000 docs/s per shard | — |
| Shards per index | 300 shards | — |
Configuration limits
Indexing Service automatically manages the following parameters. Client-side configurations for these parameters do not take effect.
| Parameter | Default value | Notes |
|---|---|---|
index.refresh_interval |
30s |
Auto-configured by Indexing Service. |
index.translog.durability |
async |
Set to async to enable asynchronous translog writes. |
index.merge.policy.max_merged_segment |
1024mb |
Auto-configured. |
index.translog.flush_threshold_size |
2gb |
Auto-configured. |
index.translog.sync_interval |
100s |
Auto-configured. |
Index-level limits
| Item | Limit |
|---|---|
Lifecycle freeze parameter |
Cannot be modified within the index lifecycle. |
| Shrink operation | A hosted index is incompatible with the shrink operation in Index Lifecycle Management (ILM). Perform the shrink operation only when the index is not hosted. See Shrink. |
| Hosting auto-cancellation | Hosting is automatically disabled 3 days after an index is hosted. Change this duration to match your data lifecycle requirements. |
| Ingest Node preprocessing | When using an Ingest Node to preprocess documents before indexing, preprocessing runs on your cluster, not the hosting environment. Avoid highly complex processing logic in this configuration. For details, see Ingest Node. |
Performance testing
The following results compare write performance between Kernel-enhanced Edition with Indexing Service and Standard Edition clusters under identical hardware specifications.
These results are based on the test environment and dataset described below. Actual performance depends on your data characteristics, index configuration, and workload patterns.
Test environment
Test results
| Specifications (3 data nodes) | Cluster edition | Write TPS | Write visibility delay |
|---|---|---|---|
| 2 cores, 8 GB | Standard Edition | 24,883 | 5 seconds |
| 2 cores, 8 GB | Kernel-enhanced Edition with Indexing Service | 226,649 | 6 seconds |
| 4 cores, 16 GB | Standard Edition | 52,372 | 5 seconds |
| 4 cores, 16 GB | Kernel-enhanced Edition with Indexing Service | 419,574 | 6 seconds |
| 8 cores, 32 GB | Standard Edition | 110,277 | 5 seconds |
| 8 cores, 32 GB | Kernel-enhanced Edition with Indexing Service | 804,010 | 6 seconds |
Performance improvement vs Standard Edition
| Specifications (3 nodes) | Write TPS improvement |
|---|---|
| 2 cores, 8 GB | 910% |
| 4 cores, 16 GB | 801% |
| 8 cores, 32 GB | 729% |