JindoFS is a cloud-native file system for E-MapReduce (EMR) that uses Object Storage Service (OSS) as its storage backend, combined with local disk caching and a dedicated metadata service. Use JindoFS when you need HDFS-level metadata performance and elastic storage that scales independently of your compute cluster.
This topic covers EMR V3.20.0 to V3.22.0 (V3.22.0 excluded). For EMR V3.22.0 and later, see Use JindoFS in EMR V3.22.0 to V3.26.3.
How it works
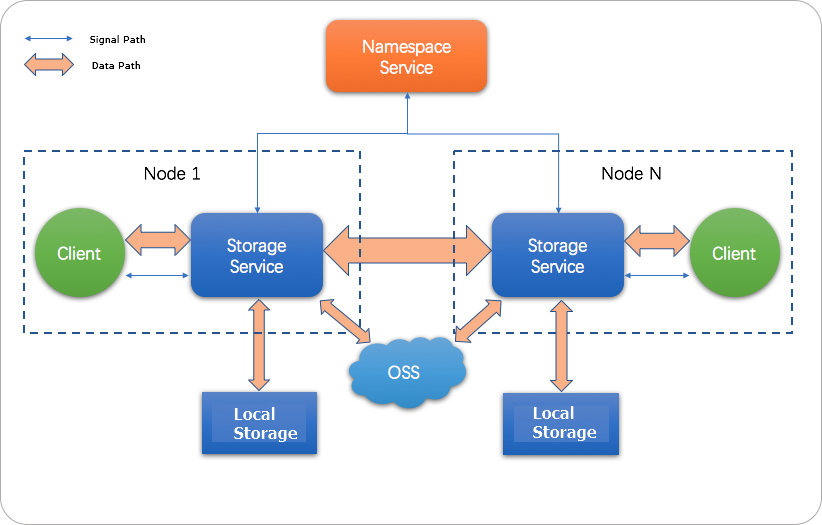
JindoFS uses two internal services to separate storage from metadata:
-
Storage Service writes data to OSS, ensuring high reliability through OSS's built-in redundancy. Frequently accessed data is also cached on local cluster disks to accelerate reads.
-
Namespace Service manages file metadata locally. Metadata queries go to Namespace Service instead of OSS, giving JindoFS metadata query performance similar to Hadoop Distributed File System (HDFS).
JindoFS supports two storage modes: block storage mode and cache mode. This topic covers block storage mode.
Choose a storage system
EMR provides three storage systems: OssFileSystem, HDFS, and JindoFS. OssFileSystem and JindoFS both use OSS as the storage backend.
| Feature | Hadoop OSS | EMR OssFileSystem | EMR HDFS | EMR JindoFS |
|---|---|---|---|---|
| Storage capacity | Tremendous | Tremendous | Depends on cluster scale | Tremendous |
| Reliability | High | High | High | High |
| Throughput factor | Server | Disk I/O of caches | Disk I/O | Disk I/O |
| Metadata query efficiency | Low | Medium | High | High |
| Scale-out | Easy | Easy | Easy | Easy |
| Scale-in | Easy | Easy | Node decommission required | Easy |
| Data locality | None | Weak | Strong | Medium |
When to use JindoFS (block storage mode):
-
High metadata query volume: JindoFS delivers HDFS-level metadata performance, making it suitable for workloads that list, stat, or rename files frequently.
-
Large-scale data with elastic clusters: Storage scales independently of the cluster. Scale the cluster in or out without decommissioning nodes or migrating data.
-
Write Once Read Many (WORM) workloads: Local disk caching accelerates repeated reads on a fixed dataset.
-
Data locality matters: JindoFS stores local backups on the nodes that originally wrote the data, reducing network I/O during subsequent reads.
Prerequisites
Before you begin, ensure that you have:
-
An EMR cluster running V3.20.0 to V3.22.0 (V3.22.0 excluded), with SmartData and Bigboot selected during cluster creation. For instructions, see Create a cluster.
-
An OSS bucket. Store the bucket in the same region as your EMR cluster to ensure high performance and stability, and to enable password-free access without configuring an AccessKey pair.
Bigboot provides distributed data management and component management services. SmartData builds on Bigboot to expose JindoFS to the application layer.
Configure JindoFS
Two configuration methods are available. Use the post-creation method if the cluster already exists, or the pre-creation method to automate configuration at cluster startup.
Configure after cluster creation
-
In the EMR console, go to the Bigboot configuration page for your cluster.
-
Set the following parameters. Parameters framed in red in the console are required.
NoteJindoFS supports multiple namespaces. The examples in this topic use a namespace named
test.Parameter Description Example oss.access.bucketName of the OSS bucket used as the JindoFS storage backend. my-emr-bucketoss.data-dirDirectory within the bucket where JindoFS stores data. Created automatically on first write — do not create it in advance. jindoFS-1oss.access.endpointEndpoint of the region where the OSS bucket resides. oss-cn-hangzhou-internal.aliyuncs.comoss.access.keyAccessKey ID for OSS access. Omit if the bucket is in the same region as the cluster (password-free access). — oss.access.secretAccessKey secret for OSS access. Omit if the bucket is in the same region as the cluster (password-free access). — 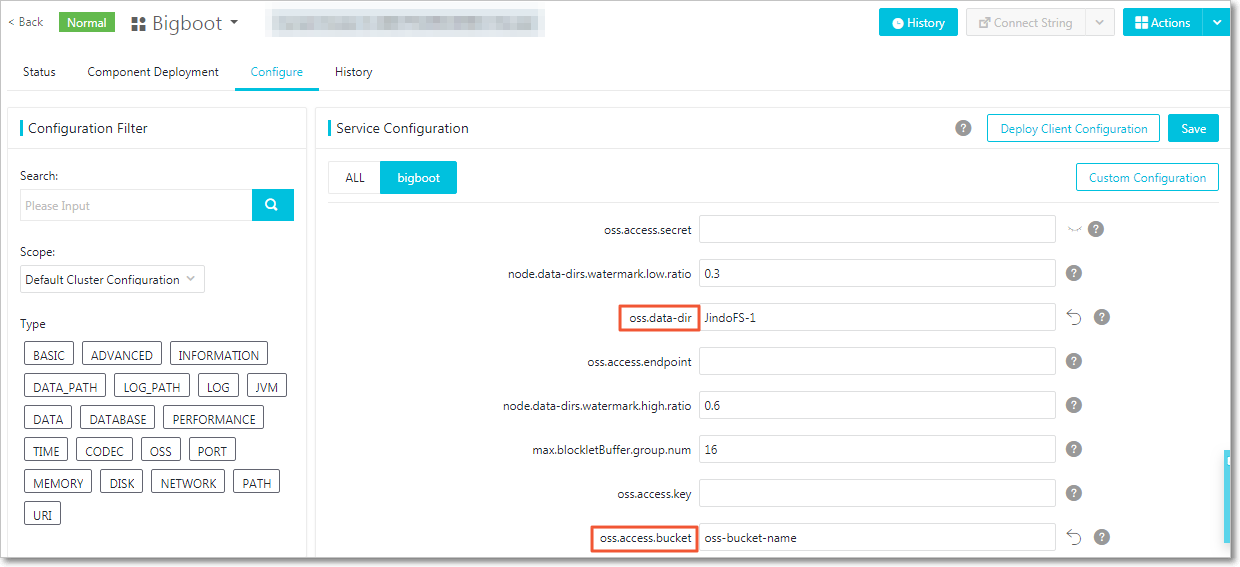
-
Save and deploy the configuration.
-
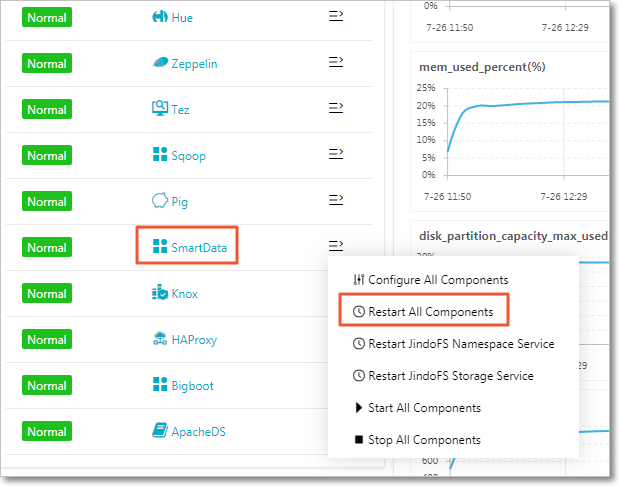
Restart all SmartData components for the changes to take effect.


Configure at cluster creation
Pass Bigboot parameters as custom configurations when creating the cluster. The cluster automatically applies the settings after startup.
-
On the cluster creation page, enable Custom Software Settings.
-
In the Advanced Settings section, add the following JSON. Replace the values with your OSS bucket name and data directory.
[ { "ServiceName": "BIGBOOT", "FileName": "bigboot", "ConfigKey": "oss.data-dir", "ConfigValue": "jindoFS-1" }, { "ServiceName": "BIGBOOT", "FileName": "bigboot", "ConfigKey": "oss.access.bucket", "ConfigValue": "oss-bucket-name" } ]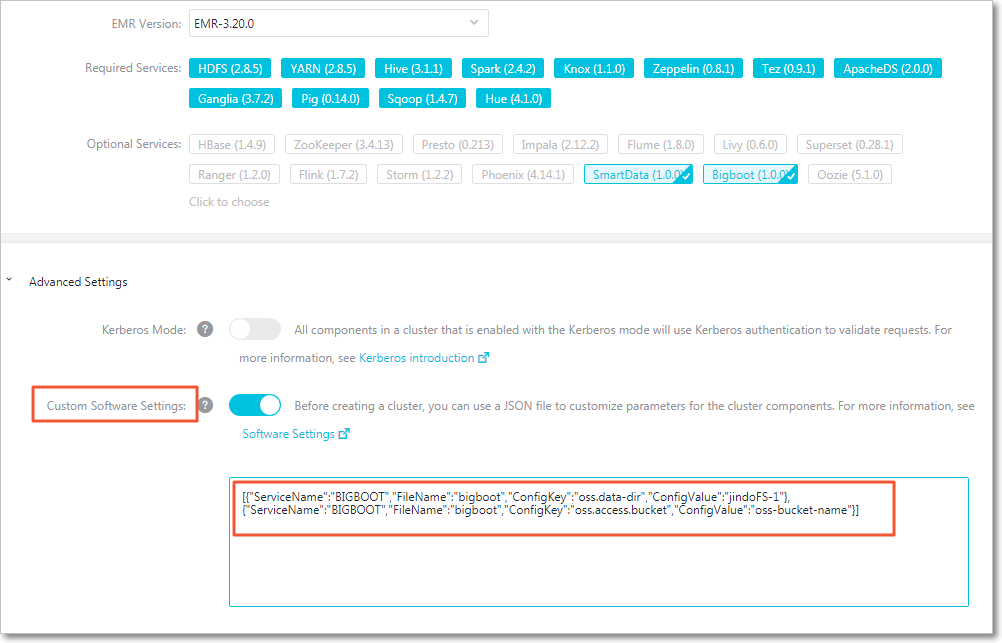
-
Complete cluster creation. SmartData restarts automatically and applies the configuration.

Use JindoFS
JindoFS uses the jfs:// URI prefix, with the same command syntax as HDFS.
List a directory:
hadoop fs -ls jfs:///Create a directory:
hadoop fs -mkdir jfs:///test-dirUpload a file:
hadoop fs -put test.log jfs:///test-dir/Data can be read from JindoFS only when Hadoop, Hive, and Spark jobs are running in the EMR cluster.
Manage disk space
JindoFS caches data on local disks to accelerate reads. Because local disk capacity is finite, JindoFS automatically evicts cold data using a high-watermark/low-watermark mechanism.
Configure the watermark parameters in Bigboot:
| Parameter | Description |
|---|---|
node.data-dirs.watermark.high.ratio |
Upper limit of disk space usage per data disk (0–1). When usage reaches this ratio, JindoFS starts evicting the least recently accessed local blocks. |
node.data-dirs.watermark.low.ratio |
Lower limit of disk space usage per data disk (0–1). Eviction continues until usage drops to this ratio. |
By default, JindoFS uses the total capacity of all data disks. Set the high ratio above the low ratio — reversed values cause configuration errors.
Configure storage policies
JindoFS provides four storage policies that control how many copies of a file are kept in OSS and on local disks. The default policy is WARM.
| Policy | OSS backup | Local backups | Best for |
|---|---|---|---|
| COLD | Yes | None | Archival data accessed rarely |
| WARM | Yes | 1 | General-purpose workloads (default) |
| HOT | Yes | Multiple | Frequently read hot data |
| TEMP | No | 1 | Temporary data; faster I/O, lower reliability |
New files inherit the storage policy of their parent directory.
Set a storage policy:
jindo dfsadmin -R -setStoragePolicy <path> <policy>-
<path>: Target directory. -
<policy>: One ofCOLD,WARM,HOT, orTEMP. -
-R: Applies the policy recursively to all subdirectories.
Get the current storage policy:
jindo dfsadmin -getStoragePolicy <path>Archive cold data (evict local blocks):
Use the archive command to explicitly evict local blocks while retaining the OSS copy. This is useful for partitioned tables where older partitions are no longer accessed frequently.
jindo dfsadmin -archive <path>For example, if Hive partitions a table by day, run archive weekly on directories older than seven days to free local disk space without deleting data from OSS.