To view and analyze Apache log data, you can use Filebeat to collect the log data. Then, you can use Alibaba Cloud Logstash to filter the collected data and send it to an Elasticsearch instance for analysis. This topic describes how to collect Apache log data using Filebeat.
Procedure
Step 1: Preparations
Create an Alibaba Cloud Elasticsearch instance and a Logstash instance. The instances must have the same version and be in the same virtual private cloud (VPC).
For more information, see Create an Alibaba Cloud Elasticsearch instance and Create an Alibaba Cloud Logstash instance.
Enable the automatic index creation feature for the Alibaba Cloud Elasticsearch instance.
For security reasons, Alibaba Cloud Elasticsearch does not allow automatic index creation by default. However, Beats depends on this feature. If you set the collector output to an Elasticsearch instance, you must enable automatic index creation. For more information, see Configure YML parameters.
Create an Alibaba Cloud ECS instance. The ECS instance must be in the same VPC as the Alibaba Cloud Elasticsearch and Logstash instances.
For more information, see Create an instance using the wizard.
ImportantBeats currently supports only Alibaba Cloud Linux, Red Hat, and CentOS operating systems.
Alibaba Cloud Filebeat only supports collecting logs from ECS instances that are in the same region and VPC as the Alibaba Cloud Elasticsearch or Logstash instance. It does not support collecting logs from the Internet.
Set up an httpd service on the ECS instance.
To simplify the analysis and display of logs using visualization tools, define the Apache log format as JSON in the httpd.conf file. For more information, see Manually build a Magento 2 e-commerce website (Ubuntu). The following configuration is used as an example in this topic.
LogFormat "{\"@timestamp\":\"%{%Y-%m-%dT%H:%M:%S%z}t\",\"client_ip\":\"%{X-Forwa rded-For}i\",\"direct_ip\": \"%a\",\"request_time\":%T,\"status\":%>s,\"url\":\"%U%q\",\"method\":\"%m\",\"http_host\":\"%{Host}i\",\"server_ip\":\"%A\",\"http_referer\":\"%{Referer}i\",\"http_user_agent\":\"%{User-agent}i\",\"body_bytes_sent\":\"%B\",\"total_bytes_sent\":\"%O\"}" access_log_json # Comment out the original CustomLog and change it to CustomLog "logs/access_log" access_log_jsonInstall Cloud Assistant and the Docker service on the target ECS instance.
For more information, see Install the Cloud Assistant Agent and Install and use Docker and Docker Compose.
Step 2: Configure and install the Filebeat collector
Log on to the Alibaba Cloud Elasticsearch console.
Navigate to the Beats Data Shippers page.
In the top navigation bar, select a region.
In the left-side navigation pane, click Beats Data Shippers.
Optional: If this is the first time you go to the Beats Data Shippers page, view the information displayed in the message that appears and click OK to authorize the system to create a service-linked role for your account.
NoteWhen Beats collects data from various data sources, Beats depends on the service-linked role and the rules specified for the role. Do not delete the service-linked role. Otherwise, the use of Beats is affected. For more information, see Elasticsearch service-linked roles.
In the Create Shipper area, click ECS Logs.
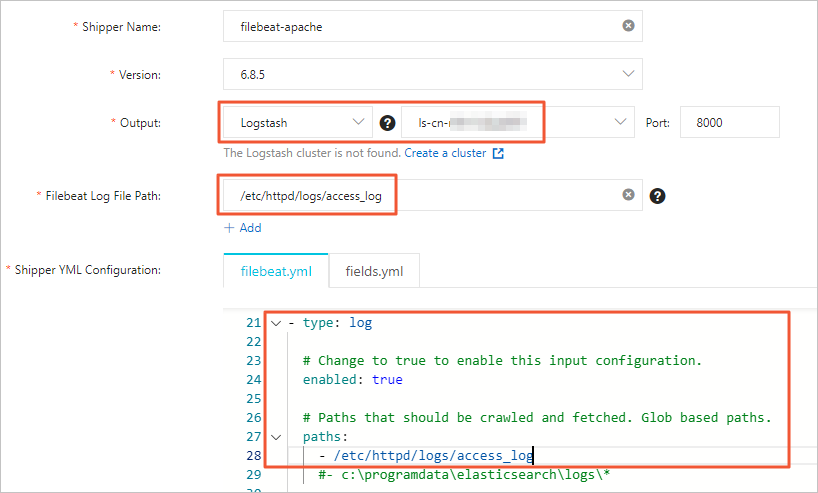
Configure and install the collector.
For more information, see Collect ECS service logs and Collector YML configuration. This topic uses the configuration shown in the following figure.
 Note
NoteSet the collector Output to the instance ID of the target Alibaba Cloud Logstash instance. You do not need to specify the Output parameter again in the YML configuration.
For the Filebeat file directory, enter the path to the directory where the data source is located. You must also enable log data collection and configure the log path in the YML configuration.
Click Next.
In the Install Shipper configuration wizard, select the ECS instance where you want to install the collector.
NoteSelect the ECS instance that you created and configured in the "Step 1: Preparations" section.
Start the collector and check its installation status.
Click Start.
After the collector starts, the Start Shipper dialog box is displayed.
Click Back to Beats Shippers. You are redirected to the Beats Data Shippers page. In the Manage Shippers section, view the Filebeat collector that you started.
Wait for the Shipper Status to change to Enabled. Then, click View Instances in the Actions column.
On the View Instances page, check the Installed Shippers. If the status is Normal Heartbeat, the collector has been installed successfully.
Step 3: Configure a Logstash pipeline to filter and sync data
In the navigation pane on the left of the Alibaba Cloud Elasticsearch console, click Logstash Clusters.
In the Actions column of the target Logstash instance, click Manage Pipeline.
On the Pipelines page, click Create Pipeline.
Configure the pipeline.
Configure the pipeline based on the following example. For detailed configuration instructions, see Manage pipelines with configuration files.
input { beats { port => 8000 } } filter { json { source => "message" remove_field => "@version" remove_field => "prospector" remove_field => "beat" remove_field => "source" remove_field => "input" remove_field => "offset" remove_field => "fields" remove_field => "host" remove_field => "message" } } output { elasticsearch { hosts => ["http://es-cn-mp91cbxsm00******.elasticsearch.aliyuncs.com:9200"] user => "elastic" password => "<YOUR_PASSWORD>" index => "<YOUR_INDEX>" } }Parameter
Description
input
Receives data collected by Beats.
filter
Filters the collected data. The JSON plugin decodes the message data, and remove_field deletes the specified fields.
NoteThe filter configuration in this topic applies only to this test scenario. It may not be suitable for all business scenarios. Modify the filter configuration as needed. For information about the plugins supported by filter and how to use them, see filter plugin.
output
Sends data to the Alibaba Cloud Elasticsearch instance. The parameters are described as follows:
hosts: Replace this with the endpoint of your Alibaba Cloud Elasticsearch instance. You can obtain the endpoint from the Basic Information page of the instance. For more information, see View the basic information of an instance.
<YOUR_PASSWORD>: Replace this with the password for your Alibaba Cloud Elasticsearch instance.
<YOUR_INDEX>: Replace this with the name of the index you defined.
Step 4: View the data collection results
Log on to the Kibana console of your Elasticsearch cluster and go to the homepage of the Kibana console as prompted.
For more information about how to log on to the Kibana console, see Log on to the Kibana console.
NoteIn this example, an Elasticsearch V6.7.0 cluster is used. Operations on clusters of other versions may differ. The actual operations in the console prevail.
In the left-side navigation pane of the page that appears, click Dev Tools.
In the Console, run the following command to view the collected data.
GET <YOUR_INDEX>/_searchNoteReplace <YOUR_INDEX> with the index name that you defined in the output section of the Alibaba Cloud Logstash instance pipeline configuration.
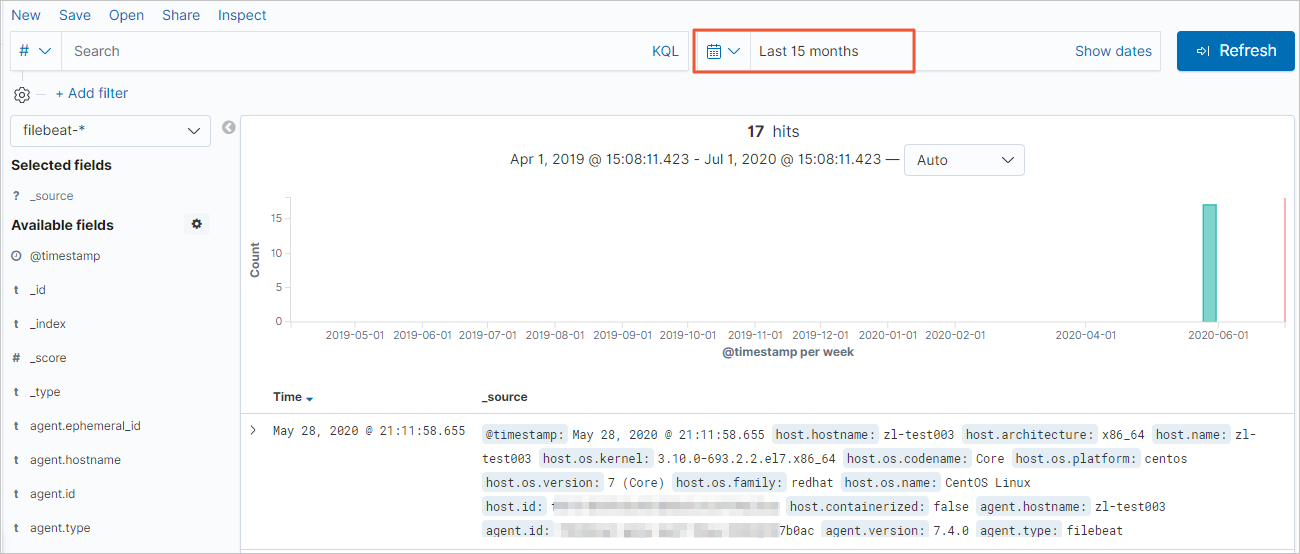
In the navigation pane on the left, click Discover. Then, select a time range to view the details of the collected data.
 Note
NoteBefore you run the query, make sure that you have created an index pattern for <YOUR_INDEX>. If not, in the Kibana console, click Management. In the Kibana section, choose and follow the prompts to create an index pattern.