This topic provides answers to some frequently asked questions about open source Elasticsearch.
Overview
When I query an index, the "statusCode: 500" error message is displayed. What do I do?
How do I change the value of the auto_create_index parameter?
How long is required to create a snapshot that will be stored in OSS?
How do I specify the number of shards when I create an index?
How do I change the time zone for data visualization in the Kibana console?
What type of data can I perform Elasticsearch term queries on?
What are the precautions for using aliases in Elasticsearch?
What do I do if the too_many_buckets_exception error message is returned during a query?
Can I change the value of the script.painless.regex.enabled parameter?
What do I do if I want or I do not want a specific field to be aggregated?
How do I configure the thread pool size for indexes?
In the YML configuration file of your Elasticsearch cluster, specify the thread_pool.write.queue_size parameter to configure the thread pool size. For more information, see Configure the YML file.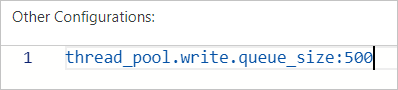
For Elasticsearch clusters of a version earlier than 6.X, use the thread_pool.index.queue_size parameter to configure the thread pool size.
What do I do if OOM occurs?
Run the following command to clear the cache. Then, analyze the cause, and upgrade the configuration of your Elasticsearch cluster or adjust your business. For more information about how to upgrade the cluster configuration, see Upgrade the configuration of a cluster.
curl -u elastic:<password> -XPOST "localhost:9200/<index_name>/_cache/clear?pretty"Parameter | Description |
| The password that is used to access your Elasticsearch cluster. The password is specified when you create the cluster or initialize Kibana. |
| The name of the index. |
How do I manually manage a shard?
Use the reroute API or Cerebro. For more information, see Cluster reroute API and Cerebro.
What are the cache clearing policies for Elasticsearch?
Elasticsearch supports the following cache clearing policies:
Clear the cache of all indexes
curl localhost:9200/_cache/clear?prettyClear the cache of a specific index
curl localhost:9200/<index_name>/_cache/clear?prettyClear the cache of multiple indexes
curl localhost:9200/<index_name1>,<index_name2>,<index_name3>/_cache/clear?pretty
How do I reroute index shards?
If some shards are lost or inappropriately allocated, you can run the following command to reroute the shards:
curl -XPOST 'localhost:9200/_cluster/reroute' -d '{
"commands" : [ {
"move" :
{
"index" : "test", "shard" : 0,
"from_node" : "node1", "to_node" : "node2"
}
},
{
"allocate" : {
"index" : "test", "shard" : 1, "node" : "node3"
}
}
]
}'When I query an index, the "statusCode: 500" error message is displayed. What do I do?
We recommend that you use a third-party plug-in, such as Cerebro, to query the index.
If the query succeeds, the issue is caused by an invalid index name. In this case, change the index name. An index name can contain only letters, underscores (_), and digits.
If the query fails, the issue is caused by an error in the index or your cluster. In this case, check whether your cluster stores the index and runs in a normal state.
How do I change the value of the auto_create_index parameter?
Run the following command:
PUT /_cluster/settings
{
"persistent" : {
"action": {
"auto_create_index": "false"
}
}
}The default value of the auto_create_index parameter is false. This value indicates that the system does not automatically create indexes. In most cases, we recommend that you do not change the value of this parameter. Otherwise, excessive indexes are created, and the mappings or settings of the indexes do not meet your expectations.
How long is required to create a snapshot that will be stored in OSS?
If the number of shards, memory usage, disk usage, and CPU utilization of your cluster are normal, about 30 minutes are required to create a snapshot for 80 GB of index data.
How do I specify the number of shards when I create an index?
You can divide the total data size by the data size of each shard to obtain the number of shards. We recommend that you limit the data size of each shard to 30 GB. If the data size of each shard exceeds 50 GB, query performance is severely affected.
You can appropriately increase the number of shards to speed up index creation. The query performance is affected no matter whether the number of shards is small or large.
Shards are stored on different nodes. If the number of shards is set to a large value, more files need to be opened, and more interactions are required among the nodes. This decreases query performance.
If the number of shards is set to a small value, each shard stores more data. This also decreases query performance.
When I use the elasticsearch-repository-oss plug-in to migrate data from a self-managed Elasticsearch cluster, the following error message is displayed. What do I do?
Error message: ERROR: This plugin was built with an older plugin structure. Contact the plugin author to remove the intermediate "elasticsearch" directory within the plugin zip.
Solution: Change the name of the ZIP plug-in package from elasticsearch to elasticsearch-repository-oss, and copy the package to the plugins directory.
How do I change the time zone for data visualization in the Kibana console?
You can change the time zone in the Kibana console. In this example, an Elasticsearch 6.7.0 cluster is used.  The following figure shows the selected time zone.
The following figure shows the selected time zone.
What type of data can I perform Elasticsearch term queries on?
Term queries are word-level queries that can be performed on structured data, such as numbers, dates, and keywords other than text.
When you perform a full-text query, the system splits words in the text. When you perform a word-level query, the system directly searches the inverted indexes that contain the related fields. Word-level queries are generally performed on fields of a numeric or date data type.
What are the precautions for using aliases in Elasticsearch?
The total number of shards for indexes that have the same alias must be less than 1,024.
What do I do if the too_many_buckets_exception error message is returned during a query?
Error message: "type": "too_many_buckets_exception", "reason": "Trying to create too many buckets. Must be less than or equal to: [10000] but was [10001].
Solution: You can change the value of the size parameter for bucket aggregations. For more information, see Limit the number of buckets that can be created in an aggregation. You can also resolve this issue based on the instructions provided in Increasing max_buckets for specific Visualizations.
How do I delete multiple indexes at a time?
By default, Elasticsearch does not allow you to delete multiple indexes at a time. You can run the following command to enable the deletion. Then, use a wildcard to delete multiple indexes at a time.
PUT /_cluster/settings
{
"persistent": {
"action.destructive_requires_name": false
}
}Can I change the value of the script.painless.regex.enabled parameter?
In most cases, the default value false is used for the script.painless.regex.enabled parameter, and we recommend that you do not change the value. If you want to use a regular expression in a Painless script, you can set the script.painless.regex.enabled parameter to true in the elasticsearch.yml configuration file. Regular expressions consume a large amount of resources. In open source Elasticsearch, the value true is not recommended for the script.painless.regex.enabled parameter. Therefore, we recommend that you do not set the parameter to true if unnecessary.
How do I change the mapping configurations, number of primary shards, and number of replica shards for an index in an Elasticsearch cluster?
If you want to modify the mapping configurations for an existing index, we recommend that you reindex data.
NoteFor information about the field types that are supported in the mapping configurations, see Data field type.
You cannot change the number of primary shards for an existing index. If the number of primary shards cannot meet your business requirements, you can call the reindex API to reindex data.
NoteTo prevent adjustments after an index is created, we recommend that you plan the number of primary shards and replica shards before you create the index.
If you want to change the number of replica shards for each primary shard in an existing index, you can run the following command:
PUT test/_settings { "number_of_replicas": 0 }
What do I do if I want to store the values of a field?
By default, Elasticsearch does not store values for fields, except the _source field. If you want to store values for a field, you can set the store property in the mappings configuration of the related index to true for the field.
The _source field contains the original JSON document and allows you to search for any field from the document. To reduce disk space that is used, we recommend that you do not enable storage for field values.
The following code provides an example on how to store the values of the my_field field:
PUT / my_index {
"mappings": {
"properties": {
"my_field": {
"type": "text",
"store": true
}
}
}
}What do I do if I want or I do not want a specific field to be aggregated?
Whether a field can be aggregated depends on the data type of the field and whether related field data (doc_values or fielddata) exists.
By default, fields of the numeric, date, or keyword type can be aggregated based on doc_values.
Notedoc_values indicates the column-oriented storage model, which is optimized for sorting, aggregation, and script operations.
By default, fields of the text type cannot be aggregated. If you need to aggregate such fields, you must enable fielddata in the mappings configuration.
NoteAfter fielddata is enabled, all text data is loaded into memory. This significantly increases memory usage.
PUT /my_index{ "mappings": { "properties": { "my_text_field": { "type": "text", "fielddata": true } } } }If you do not want a field to be aggregated, you can use one of the following methods to implement this. You can select a method based on your application logic.
Set the enabled property to false for the field.
Exclude the field from the related document.
What do I do if the "Unknown char_filter type [stop] for **" error message is displayed when I configure Elasticsearch?
If the "Unknown char_filter type [stop] for ** " error message is displayed when you configure Elasticsearch, the stop type is specified in the char_filter part. However, a filter of the stop type is a token filter rather than a character filter.
Solution:
Correct the configuration location: If you want to use a stopword filter, move the stop configuration from
char_filterto the filter part of the analyzer configuration. A stopword filter is used to remove specified stopwords from a token stream.Example:
"settings": { "analysis": { "analyzer": { "my_custom_analyzer": { "type": "custom", "tokenizer": "standard", "filter": [ // Specify the filter type in the filter array. "lowercase", "stop" // Use a token filter of the stop type. ] } }, "filter": { // Define configurations for the token filter of the stop type if necessary. "stop": { "type": "stop", "stopwords": "_english_" // Define stopwords based on your business requirements. } } } }Check the filter type name: Check whether valid filter type names are specified in configurations such as
tokenizerandchar_filter.You can modify configurations based on your business requirements to ensure that valid component types are specified in the
char_filter,tokenizer, andfilterconfigurations.